-
数据增强(Data Augmentation)是在不实质性的增加数据的情况下,从原始数据加工出更多的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值。
-
其原理是,通过对原始数据融入先验知识,加工出更多数据的表示,有助于模型判别数据中统计噪声,加强本体特征的学习,减少模型过拟合,提升泛化能力。
-
机器学习或深度学习模型的训练的目标是成为“通用”模型。这就需要模型没有过度拟合训练数据集,或者换句话说,我们的模型对看不见的数据有很好的了解。数据增强也是避免过度拟合的众多方法之一。
-
如经典的机器学习例子–哈士奇误分类为狼:通过可解释性方法,可发现错误分类是由于图像上的雪造成的。通常狗对比狼的图像里面雪地背景比较少,分类器学会使用雪作为一个特征来将图像分类为狼还是狗,而忽略了动物本体的特征。此时,可以通过数据增强的方法,增加变换后的数据(如背景换色、加入噪声等方式)来训练模型,帮助模型学习到本体的特征,提高泛化能力。图像本身的变化将有助于模型对未见数据的泛化,从而不会对数据进行过拟合。
-
需要关注的是,数据增强样本也有可能是引入片面噪声,导致过拟合。此时需要考虑的是调整数据增强方法,或者通过算法(可借鉴Pu-Learning思路)选择增强数据的最佳子集,以提高模型的泛化能力。
-
PU Learning(Positive-unlabeled learning)是半监督学习的一个研究方向,指在只有正类和无标记数据的情况下,训练二分类器。
-
启发式地从未标注样本里找到可靠的负样本,以此训练二分类器,该方法问题是分类效果严重依赖先验知识。
-
将未标注样本作为负样本训练分类器,由于负样本中含有正样本,错误的标签指定导致分类错误。
-
-
-
单样本增强
-
单(图像)样本增强主要有几何操作、颜色变换、随机擦除、添加噪声等方法。在计算机视觉中,典型的数据增强方法有翻转(Flip),旋转(Rotat ),缩放(Scale),随机裁剪或补零(Random Crop or Pad),色彩抖动(Color jittering),加噪声(Noise)
-
imgaug是一款非常有用的python图像增强库,非常值得推荐应用于深度学习图像增强。其包含许多增强技术,支持图像分类,目标检测,语义分割,热图、关键点检测等一系列任务的图像增强。
-
-
多样本数据增强方法
- 多样本增强是通过先验知识组合及转换多个样本,主要有Smote、SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值。
-
Transforms 是常用的图像数据增强模块。可以使用 Compose 将它们链接在一起。
-
可视化数据增强:
-
import PIL.Image as Image import torch from torchvision import transforms import matplotlib.pyplot as plt import numpy as np import warnings plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文 plt.rcParams['axes.unicode_minus'] = False # 显示负号 def imshow(img_path, transform): """ Function to show data augmentation Param img_path: path of the image Param transform: data augmentation technique to apply """ img = Image.open(img_path) fig, ax = plt.subplots(1, 2, figsize=(10, 4)) ax[0].set_title(f'原图 {img.size}') ax[0].imshow(img) img = transform(img) ax[1].set_title(f'变换后 {img.size}') ax[1].imshow(img) plt.show() path = 'imgs/000000000049.jpg'-
Resize/Rescale:用于将图像的高度和宽度调整为我们想要的特定大小。
-
transform = transforms.Resize((640, 640)) imshow(path, transform) -

-
Cropping:将要选择的图像的一部分应用于新图像。例如,使用 CenterCrop 来返回一个中心裁剪的图像。
-
transform = transforms.CenterCrop((640, 640)) -

-
RandomResizedCrop:这种方法同时结合了裁剪和调整大小。
-
transform = transforms.RandomResizedCrop((640, 640)) -

-
Flipping:水平或垂直翻转图像
-
transform = transforms.RandomHorizontalFlip() -

-
Padding:填充包括在图像的所有边缘上按指定的数量填充。
-
transform = transforms.Pad((50,50,50,50)) -

-
Rotation:对图像随机施加旋转角度。
-
transform = transforms.RandomRotation(45) -

-
Random Affine:对图像进行仿射变换,仿射变换是 2 维的线性变换,由 5 种基本操作组成,分别是旋转、平移、缩放、错切和翻转。RandomAffine — Torchvision main documentation (pytorch.org)
-
transform = transforms.RandomAffine(1, translate=(0.5, 0.5), scale=(1, 1), shear=(1,1), fillcolor=(256,256,256)) -

-
Gaussian Blur:图像将使用高斯模糊进行模糊处理。
-
transform = transforms.GaussianBlur(7, 3) -

-
Grayscale:将彩色图像转换为灰度。
-
transform = transforms.Grayscale(num_output_channels=3) -

-
Brightness:改变图像的亮度当与原始图像对比时,生成的图像变暗或变亮。
-
transform = transforms.ColorJitter(brightness=2) -

-
Contrast:图像最暗和最亮部分之间的区别程度被称为对比度。图像的对比度也可以作为增强进行调整。
-
transform = transforms.ColorJitter(contrast=2) -

-
Saturation:图片中颜色的分离被定义为饱和度。
-
transform = transforms.ColorJitter(saturation=20) -

-
Hue:色调被定义为图片中颜色的深浅。
-
transform = transforms.ColorJitter(hue=0.4) #hue:[-0.5,0.5] -

-
-
图像本身的变化将有助于模型对未见数据的泛化,从而不会对数据进行过拟合。以上整理的都是我们常见的数据增强技术,torchvision中还包含了很多方法,可以在他的文档中找到:https://pytorch.org/vision/stable/transforms.html
-
tencorp:FiveCrop在图像的上下左右以及中心裁剪出尺寸为 size 的 5 张图片。Tencrop对这 5 张图片进行水平或者垂直镜像获得 10 张图片。
-
def transform_invert(img_, transform_train): """ 将data 进行反transfrom操作 :param img_: tensor :param transform_train: torchvision.transforms :return: PIL image """ # 如果有标准化操作 if 'Normalize' in str(transform_train): # 取出标准化的 transform norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms)) # 取出均值 mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device) # 取出标准差 std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device) # 乘以标准差,加上均值 img_.mul_(std[:, None, None]).add_(mean[:, None, None]) # 把 C*H*W 变为 H*W*C img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C # 把 0~1 的值变为 0~255 img_ = np.array(img_) * 255 # 如果是 RGB 图 if img_.shape[2] == 3: img_ = Image.fromarray(img_.astype('uint8')).convert('RGB') # 如果是灰度图 elif img_.shape[2] == 1: img_ = Image.fromarray(img_.astype('uint8').squeeze()) else: raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) ) return img_ img = Image.open(path) transform = Compose([ TenCrop(224, vertical_flip=True), # this is a list of PIL Images Lambda(lambda crops: torch.stack([ToTensor()(crop) for crop in crops])) # returns a 4D tensor ]) img_tensor = transform(img) b,c,h,w=img_tensor.shape plt.figure(figsize=(15,4)) for i in range(b): img = transform_invert(img_tensor[i], transform) plt.subplot(2, 5, i+1) plt.imshow(img) plt.show() -

-
RandomErasing:对图像进行随机遮挡。这个操作接收的输入是 tensor。
-
transform = Compose([ transforms.ToTensor(), transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(100/255, 0, 0)), ]) img_tensor = transform(img) convert_img=transform_invert(img_tensor, transform) plt.subplot(1, 2, 1) plt.imshow(img) plt.subplot(1, 2, 2) plt.imshow(convert_img) plt.show() -

-
-
transforms.RandomChoice:从一系列 transforms 方法中随机选择一个
-
torchvision.transforms.RandomChoice([transforms1, transforms2, transforms3])
-
-
transforms.RandomApply:根据概率执行一组 transforms 操作,要么全部执行,要么全部不执行。
-
torchvision.transforms.RandomApply([transforms1, transforms2, transforms3], p=0.5)
-
-
transforms.RandomOrder:对一组 transforms 操作打乱顺序
-
transforms.RandomOrder([transforms1, transforms2, transforms3])
-
数据增强,扩充了数据集,增加了模型的泛化能力
news2026/3/29 2:49:13
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/371699.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
【NFC音乐相册】简易制作
欢迎来到 Claffic 的博客 💞💞💞 前言: NFC音乐相册在前段时间火了一把,想必大家都听过了,最近我刷到了这个东西,闲来无事就弄了几个,这篇博客就记录下制作工序。 注:我所…
keepalive + nginx 来实现 对于nginx的高可用, 以及如何搭建主备模式
keepalive nginx 来实现 对于nginx的高可用, 以及如何搭建主备模式。
keeplived简介
Keepalived是用纯ANSI/ISO C编写的。该软件围绕一个中央I/O多路复用器进行连接,以提供实时网络设计。
1.1 Keepalived进程被分为3个不同进程
A.一个极简的父进程,…

SpringBoot-运维实用篇
SpringBoot运维实用篇
1.SpringBoot程序的打包与运行
刚开始做开发学习的小伙伴可能在有一个知识上面有错误的认知,我们天天写程序是在Idea下写的,运行也是在Idea下运行的。 但是实际开发完成后,我们的项目是不可能运行在自己的电脑上…
图解LeetCode——剑指 Offer 46. 把数字翻译成字符串
一、题目
给定一个数字,我们按照如下规则把它翻译为字符串:0 翻译成 “a” ,1 翻译成 “b”,……,11 翻译成 “l”,……,25 翻译成 “z”。一个数字可能有多个翻译。请编程实现一个函数&#x…
spring boot3 一、 spring alibaba cloud 整合 网关 nacos config
jm-apis服务jm-user-api用户服务jm-apis-common公共模块jm-apis-common-bean公共beanjm-apis-common-conf公共配置jm-apis-common-tool公共工具jm-dubbo-apisRPC服务jm-dubbo-user-api用户RPC服务
jianmu-springboot3-springalibabacloud pom.xml
<?xml version"1.0&…

如何定制一个智能洒水装置(养狗/养花人士请进)
目录
如何用智能地教狗狗上厕所如何定制一个智能洒水装置
背景
上一篇文章中提到了,我实现了一个自动检测狗狗有没有进厕所的功能。现在我们家的狗狗用它那不算大的小脑瓜,已经百分百学会(但是!也不知道它是不是聪明过头了&…
非常好看的html网页个人简历
一. 前言
文末获取gitee链接
在前几天逛b站的时候,发现了个比较实用的东西-----个人简介网页版,相当于网页版的个人简历,相较于PDF形式的,网页版所能呈现内容更加丰富,而且更加美观,在BOOS上被HR小姐姐要…
FL Studio21MAC电脑中文升级版安装图文教程
FL Studio版本有很多,每个版本各有优点。除了最新版本外,还有历史经典版本,用户可以根据自己的需求进行下载,FL Studio21是一款功能十分丰富和强大的音乐编辑软件,能够帮助用户进行编曲、剪辑、录音、混音等操作,让用户能够全面地调整音频,软…

2288hv5超融合服务器 数码管报888
【问题现象】
2288hv5超融合服务器,前面板数码管报888,电源灯黄灯闪烁,开不了机,ibmc网络是通的,但是web网页打不开
【问题原因】
iBMC的版本过低,iBMC在智能诊断数据库保护机制存在异常,导…

【算法笔记】前缀和与差分
第一课前缀和与差分
算法是解决问题的方法与步骤。
在看一个算法是否优秀时,我们一般都要考虑一个算法的时间复杂度和空间复杂度。
现在随着空间越来越大,时间复杂度成为了一个算法的重要指标,那么如何估计一个算法的时间复杂度呢…
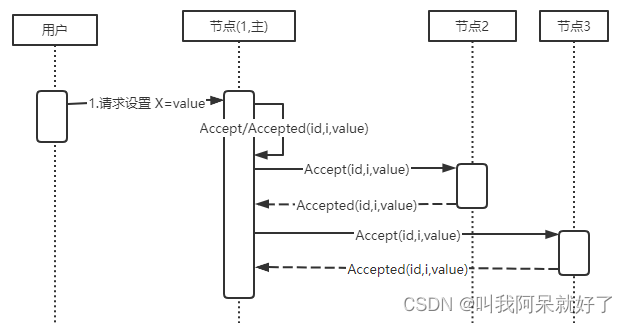
数据库浅谈之共识算法
数据库浅谈之共识算法
HELLO,各位博友好,我是阿呆 🙈🙈🙈
这里是数据库浅谈系列,收录在专栏 DATABASE 中 😜😜😜
本系列阿呆将记录一些数据库领域相关的知识 …

Linux SELinux讲解
目录
SELinux概念
SELinux配置文件
SELINUX 工作模式
SELINUX TYPE策略类型
配置安全上下文
查看安全上下文
修改安全上下文
修改默认的安全上下文
配置策略规则
查看策略规则
修改策略规则状态 SELinux概念 为什么提出SELinux 之前学习的权限,都是基于用…
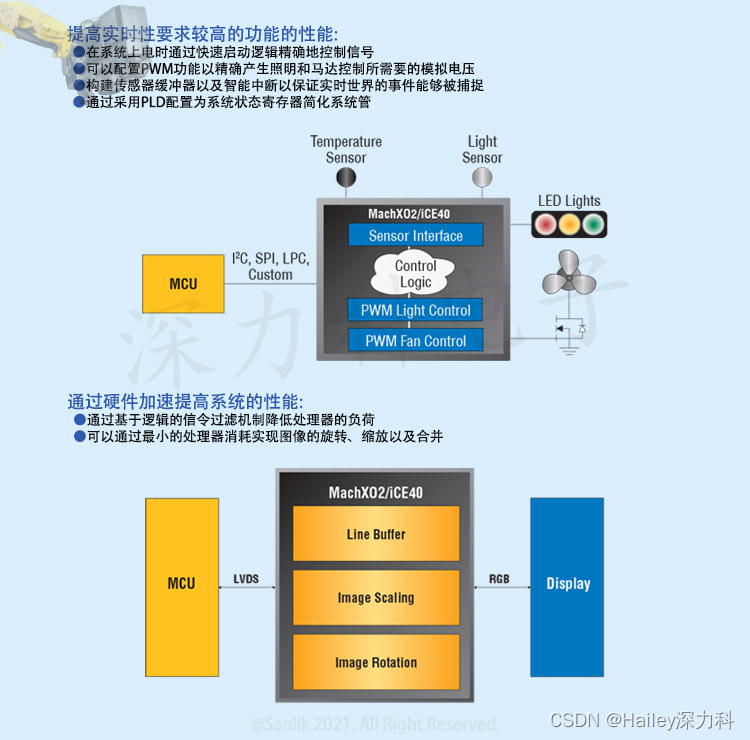
深力科电子-MachXO2系列 前所未有的灵活桥接和I/O扩展功能 LCMXO2-256HC-4TG100C FPGA现场可编程门阵列
lattice莱迪斯MachXO2系列超低密度FPGA现场可编程门阵列,适用于低成本的复杂系统控制和视频接口设计开发,满足了通信、计算、工业、消费电子和医疗市场所需的系统控制和接口应用。
瞬时启动,迅速实现控制——启动时间小于1mS,在上…
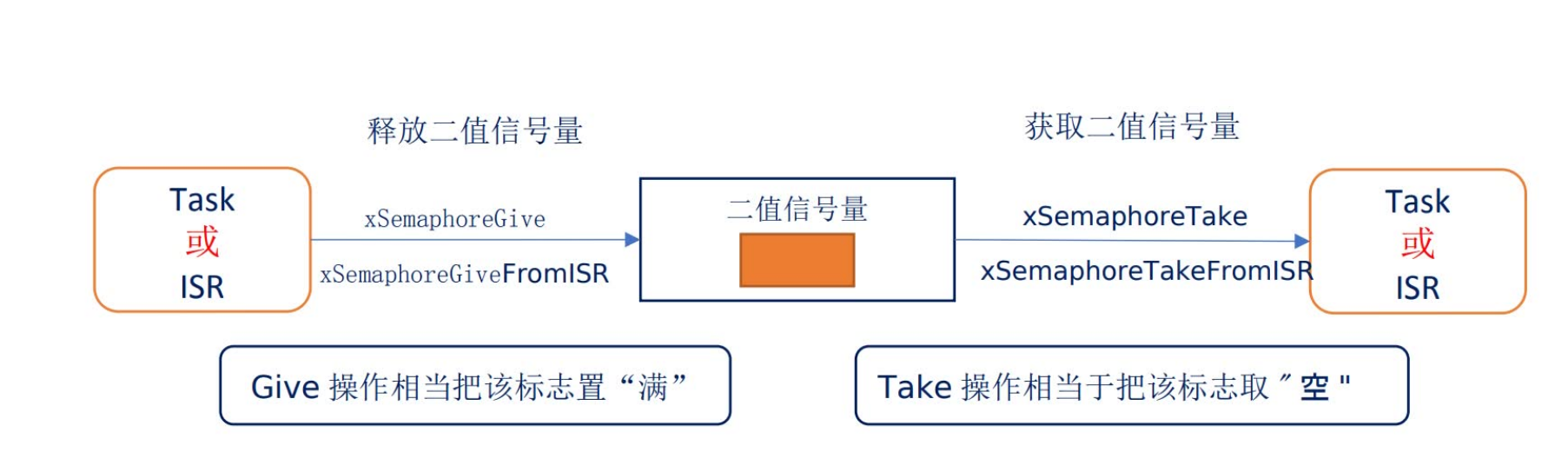
FreeRTOS信号量
前面介绍过,队列(queue)可以用于传输数据:在任务之间,任务和中断之间。消息队列用于传输多个数据,但是有时候我们只需要传递一个状态,这个状态值需要用一个数值表示,比如:…

Android运行时权限Runtime Permission源码分析
Runtime Permission源码跟踪
Android 8.1.0
请求权限时弹窗代码
应用使用requestPermissions申请权限时,系统会弹出一个选择窗口,可进行允许。
源码在packages/apps/PackageInstaller/文件下 GrantPermissionsActivity.java是进行权限分配的弹出窗口…

分布式之PBFT算法
写在前面
在分布式之拜占庭问题 一文中我们分析了拜占庭问题,并一起看了支持拜占庭容错的口信消息性和签名消息性算法,但是这两种算法都有一个非常严重的问题,就是消息数量太多,通信的成本太大,消息数量复杂度为O(n ^…

CentOS 环境 OpneSIPS 3.1 版本安装及使用
文章目录1. OpenSIPS 源码下载2. 工具准备3. 编译安装4. opensips-cli 工具安装5. 启动 OpenSIPS 实例1. OpenSIPS 源码下载
使用以下命令即可下载 OpenSIPS 的源码,笔者下载的是比较稳定的 3.1 版本,读者有兴趣也可前往 官方传送门 sudo git clone htt…
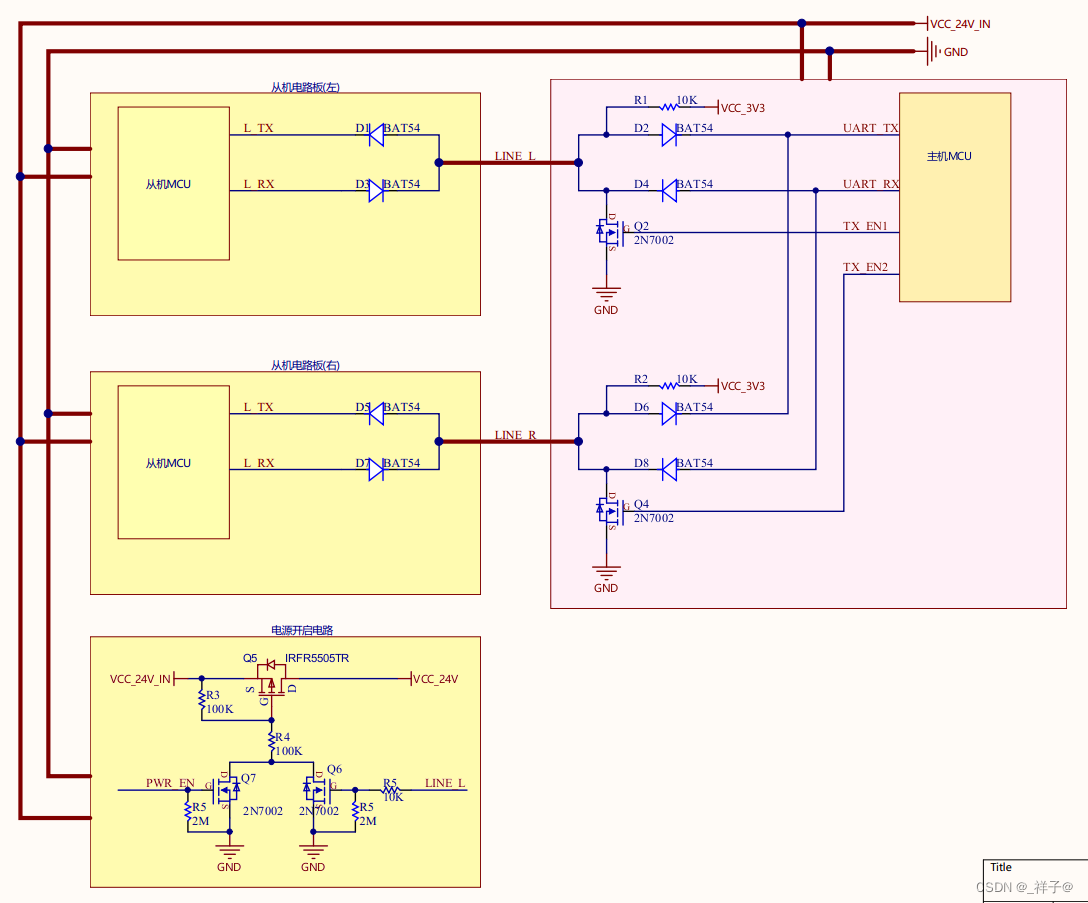
1个串口用1根线实现多机半双工通信+开机控制电路
功能需求: 主机使用一个串口,与两个从机进行双向通信,主机向从机发送数据,从机能够返回数据,由于结构限制,主机与从机之间只有3根线(电源、地、数据线),并且从机上没有设…