数据库浅谈之共识算法
HELLO,各位博友好,我是阿呆 🙈🙈🙈
这里是数据库浅谈系列,收录在专栏 DATABASE 中 😜😜😜
本系列阿呆将记录一些数据库领域相关的知识 🏃🏃🏃
OK,兄弟们,废话不多直接开冲 🌞🌞🌞
一 🏠 概述
CAP 理论
在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼
一致性(C):所有数据备份,同一时刻是否同样(所有节点访问同一份最新数据副本)
可用性(A):保证每个请求不管成功或者失败都有响应
分区容忍性(P):系统中任意信息的丢失不会影响系统继续运作
共识算法背景
问题 ① :有一份随时变动的数据,确保它正确存储在网络中几台不同机器上,怎么处理 ?
在分布式系统中,必须考虑动态数据如何在不可靠网络通讯条件下,依然能在各节点之间正确复制
数据同步 (状态转移(State Transfer)) 性能损耗
每当数据有变化,就把变化情况在各个节点之间的复制看成是一种事务性的操作,只有系统的每一台机器都反馈成功完成磁盘写入后,数据变化才能宣布成功。以同步为代表的数据复制方法,叫做状态转移(State Transfer)
这类方法属于比较直观,但通常要牺牲可用性
问题 ② :有一份随时变动的数据,确保它正确存储在几台不同机器上,且尽可能保证数据随时可用,怎么做 ?
共识算法 :这个让系统各节点不受局部网络分区、机器崩溃、执行性能或者其它因素影响,能最终表现出整体一致的过程,就是各个节点的协商共识(Consensus)
两个目标 : ① 让分布式系统内部暂时容忍存在不同状态,但最终保证大多数节点状态一致 ② 分布式系统在外部看来,始终表现整体一致
共识(Consensus)与一致性(Consistency)的区别 :一致性指的是数据不同副本之间的差异,而共识是指达成一致性的方法与过程
状态机 + 操作转移
系统 高可用 和 高可靠 之间的矛盾,是由于增加机器数量反而降低了可用性导致的
为缓解这个矛盾,在分布式系统里主流的数据复制方法,是以操作转移为基础的,比如 ( x = x + 1 )
使用确定操作,使状态间产生确定转移结果的计算模型,被称为状态机
状态机的特性:任何初始状态一样的状态机,如果执行命令序列一样,那么最终达到状态也一样。多台机器的最终状态一致,只要确保它们的初始状态和接收到的操作指令都是完全一致的就可以
广播指令与指令执行期间,允许系统内部状态存在不一致的情况,也就是不要求所有节点的每一条指令都是同时开始、同步完成的,只要求在此期间的内部状态不能被外部观察到,且当操作指令序列执行完成的时候,所有节点的最终的状态是一致的,这种模型,就是状态机复制
Quorum 机制
在分布式环境下,考虑到网络分区现象不可能消除,且不必追求所有节点任何情况下数据状态一致,所以采用 少数服从多数 原则。即系统中超过半数节点完成状态转换,就认为数据变化已被正确地存储在了系统中。
容忍少数(通常是不超过半数)节点失联,使增加机器数量可提升系统整体可用性
分布式共识基础
分布式共识是什么
在多个节点均可独自操作或记录的情况下,使得所有节点针对某个状态达成一致的过程,本质是 求同存异
一致性和共识的区别是什么
一致性指的是数据不同副本之间的差异,而共识是指达成一致性的方法与过程
分布式共识的两个关键点是什么
1、获得记账权
2、所有节点达成一致
二 🏠 核心
Paxos 算法
要求
① 为了有明确的多数,决策节点数量应被设为奇数
② 系统初始化时,网络中每个节点都知道整个网络所有决策节点的数量、地址等信息
主要概念
提案节点:Proposer,提出对某个值设置节点,设置值这个行为就是提案 (Proposal) ,值一旦设置成功,不会丢失也不可改变
决策节点:Acceptor,应答提案节点,决定该提案是否可以被投票、是否可以被接受
提案一旦得到半数决策节点接受,即被批准(Accept)。该值将不能更改,也不会丢失,且最终所有节点都会接受它
记录节点:Learner,不参与提案,也不参与决策,单纯从提案、决策节点中学习已达成共识的提案。少数节点刚从网络分区中恢复时,将会进入这种状态
分布式并发操作下的共享数据
假设有一个变量 i 当前在系统中存储的数值为 2,同时有外部请求 A、B 分别对系统发送操作指令,把 i 的值加 1 和 把 i 的值乘 3。没有并发控制,将可能得到 (2+1)×3=9 和 2×3+1=7 这两种结果。因此,对同一个变量的并发修改,必须先加锁后操作,不能让 A、B 的请求被交替处理
但是在分布式系统中,通讯故障可能在任何时刻出现。如果一个节点在取得锁后、在释放锁前发生崩溃失联,就会导致整个操作被无限期等待所阻塞
解决方案
主要包括 准备(Prepare)和 批准(Accept)两个阶段
准备(Prepare)阶段,相当于抢锁过程。如果发起提案,那必须先向所有决策节点广播一个申请 ( 称为 Prepare请求 ) 。提案节点的 Prepare 请求中会携带一个全局唯一的数字 N 作为提案 ID,决策节点收到后,会给出两个承诺和一个应答
两个承诺 :① 不会再接受提案 ID 小于或等于 N 的 Prepare 请求 ② 不会再接受提案 ID 小于 N 的 Accept 请求
一个应答 :不违背以前承诺前提下,回复已经批准过提案中 ID 最大的那个提案所设定的值和提案 ID。如果该值没有被任何提案设定过,则返回空值。如果违反此前承诺,即收到的提案 ID 不是最大的,可直接不理会请求
批准(Accept) 当提案节点收到了多数派决策节点应答后,开始第二阶段 批准 过程
此时有两种可能:
① 如果提案节点发现所有响应的决策节点此前都没有批准过这个值(即为空),就说明它是第一个设置值的节点,那就可以随意决定要设置的值;并将自己选定的值与提案 ID。构成一个二元组(ID,VALUE),再次广播给全部决策节点
② 如果提案节点发现响应的决策节点中,已经有至少一个节点的应答中包含有值了,那就必须从应答中找到提案ID 最大的那个值并接受,构成一个二元组(ID,maxAcceptValue),然后再次广播给全部的决策节点
每个决策节点收到 Accept 请求时,都会在不违背以前承诺前提下,接受并持久化当前提案 ID 和携带数值。但如果收到的提案 ID 并不是收到过的最大的,那对 Accept 请求将不理会
记录节点:
当提案节点收到了多数派决策节点的应答后,协商结束,共识决议形成,将决议发送给所有记录节点进行学习
Basic Paxos 协商过程-时序图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WhWOpRne-1677313281975)(E:\2022年MD文档\2023 年 MD文档\二月\数据库浅谈\数据库浅谈之共识算法.assets\1677219209295.png)]](https://img-blog.csdnimg.cn/53fc564e9a30460a834147a8bae8d987.png)
典型场景
背景:假设一个分布式系统中有五个节点:S1、S2、S3、S4、S5;此时有两个并发的请求希望将同一个值分别设置为 X 和 Y;P 表示准备阶段,A 表示批准阶段
场景一: 在协商过程中,谁先获得了多数节点支持(先在Promise中返回决议值),谁就是本次决议的最终值,在协商结束之前,无论有多少次新的提案都不在进行处理
S1 选定的提案 ID 是 3.1(全局唯一 ID 3 加上节点标号 1),先取得了多数派决策节点的 Promise 和 Accept 应答;此时 S5 的提案 ID 是 4.5,发起 Prepare 请求,收到的多数派应答中至少会包含一个此前应答过 S1 的决策接节点,假设是 S3
那么 S3 提供的 Premise 中必定将 S1 已经决议好的值 X,S5 就必须无条件的使用 X 而不是 Y 作为自己的提案值。(即使S5的提案ID更大,但是已经有了Accept)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y1Nx4ydI-1677313281976)(E:\2022年MD文档\2023 年 MD文档\二月\数据库浅谈\数据库浅谈之共识算法.assets\1677221185874.png)]](https://img-blog.csdnimg.cn/239e2cb0167b4ad286f2044308c919ed.png)
场景二:X 被选定不一定是要多数派共同批准,只取决于 S5 提案时 Promise 应答中是否已经包含了批准过 X 决策节点,如下图,S5 发起提案 Prepars 请求时,X 并未获取多数派批准,但由于 S3 已经批准的原因,最终共识的结果依然是 X
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ECpKxOev-1677313281977)(E:\2022年MD文档\2023 年 MD文档\二月\数据库浅谈\数据库浅谈之共识算法.assets\1677221671266.png)]](https://img-blog.csdnimg.cn/b17df9c7953d4266908a6150c8164175.png)
场景三:S5 在提案的时候 Promise 应答中并没有包含批准过 X 的决策节点。比如,应答 S5 提案时,节点 S1已经批准了 X,节点 S2、S3 并未批准但是返回了 Promise 应答,那此时 S5 以更大的提案 ID 获得了 S3、S4、S5 的Promise
这三个节点均为批准过任何值,那么 S3 将不会再接受来自 S1 的 Accept 请求,因为它的提案 ID 已经不是最大的。所以这三个节点将批准Y的取值,整个系统将会对取值为Y达成一致
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XoxlVNvE-1677313281977)(E:\2022年MD文档\2023 年 MD文档\二月\数据库浅谈\数据库浅谈之共识算法.assets\1677221898253.png)]](https://img-blog.csdnimg.cn/43f5e62cad7e4a228cd7999d086c17ae.png)
场景四:如果两个提案节点交替使用最大的提案ID,使得准备阶段成功,但是批准阶段失败的话,那这个过程理论上可以无限延续下去,形成活锁(Live Lock),实际算法中会引入随机超时时间来避免活锁产生
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9tZrnLht-1677313281978)(E:\2022年MD文档\2023 年 MD文档\二月\数据库浅谈\数据库浅谈之共识算法.assets\1677222350732.png)]](https://img-blog.csdnimg.cn/dc654f5d219a492f869790b0c6c55654.png)
Multi Paxos (Raft)
活锁问题 :两个提案节点互不相让提出自己的提案,抢占同一个值修改权限,导致整个系统再持续的反复横跳,从外部来看就像是被锁住了
活锁问题和许多 BasicPaxos 异常场景中 (网络不可靠、请求并发) 所遇到的麻烦,源于任何一个提案节点能完全平等的与其他节点并发的提出提案而带来的问题,MultiPaxos 对 BasicPaxos 核心改进是选择
选主
提案节点通过心跳,确定当前网络中所有节点里是否存在一个主提案节点
一旦发现没有主节点,节点就会在心跳超时后 ( 不存在主节点 ) 使用 BasicPaxos 中定义的准备、批准的两轮网络过程,向所有其他节点广播自己 竞选主节点的请求,希望整个分布式系统对 由我做主节点 协商达成一致共识
如果得到了决策结点中多数派的批准,便宣告竞选成功
选主完成后,只有主节点本身才能提出提案。此时,无论是哪个提案节点接收到客户端的请求操作,都会将请求转发给主节点完成提案,而主节点提案无需经过准备过程,因为经过选举时那次准备后,后续提案都是对相同提案 ID 的一连串批准过程
可以理解为 :选主后,不会有其它节点与主节点竞争,相当于处于无并发环境的有序操作,所以此时系统中要对某个值达成一致,只进行一次批准交互即可
注 :主提案节点竞选类似于 BasicPaxos 过程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JkeKfprt-1677313281979)(E:\2022年MD文档\2023 年 MD文档\二月\数据库浅谈\数据库浅谈之共识算法.assets\1677222984563.png)]](https://img-blog.csdnimg.cn/baee884510314f54a53b0cffde80cb5f.png)
任期和分区
原本(id,value)二元组变成了三元组(id,i,value),给主节点增加一个 单调递增 的任期编号,应对主节点陷入网络分区后重新恢复,但系统已完成了重新选主过程,此时必须以任期编号大的节点为准
我们假设网络恢复正常,如下图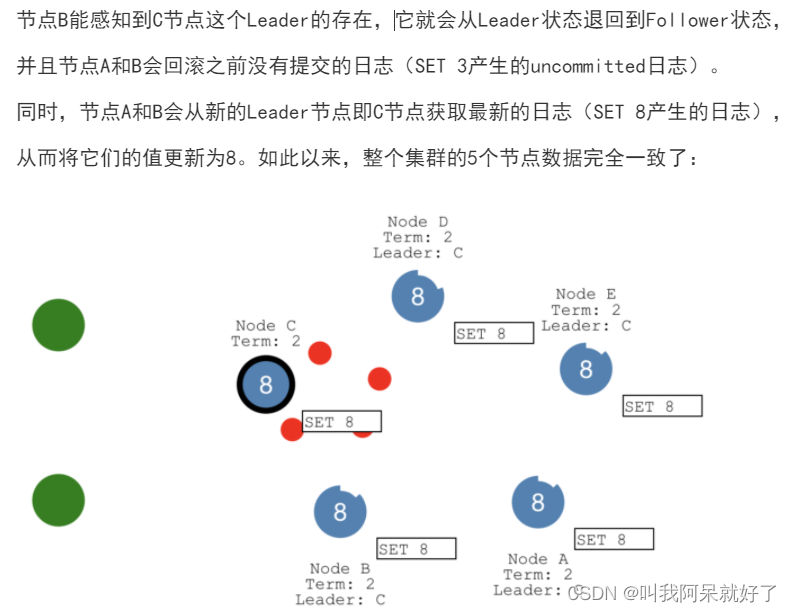
网络分区 raft 算法 对于 双主问题 解决方案
从整体来看,当节点有了选主机制后,可以进一步简化为 主节点(Leader)和从节点(Follower),不必区分提案节点、决策节点和记录节点了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8oeX548m-1677313281981)(E:\2022年MD文档\2023 年 MD文档\二月\数据库浅谈\数据库浅谈之共识算法.assets\1677223442955.png)]](https://img-blog.csdnimg.cn/9818589124f6474d95e12f85f53ba05c.png)
结点状态与竞选 leader
每个节点有三种状态:follower,candidate,leader,状态之间是互相转换的
主节点,主节点负责与客户端通讯,给follower发心跳,同步日志与提交命令给 从节点
从节点,每一个有一个倒计时器,时间随机,倒计时结束后自动转换成 candidate,结点初始状态都是 follower
candidate 向其它结点发送投票请求,收到半数以上票时,candidate 成为 leader,并向其它 follower 发送心跳。如果再给其它 follower 发心跳同时收到了其它 candidate 的心跳说明同时当选 leader,则本轮竞选无效,再通过重置倒计时器重新竞选
倒计时器 当受到 candidate 投票请求,与 leader 心跳,倒计时器重新刷新倒计时
如何保证数据一致
客户端向服务端发送存储数据的请求,
- leader 记日志,把消息分发 follower 记日志
- leader 提交响应客户端提交成功
- 然后通知 follower 提交
发生网络分区时,两个分区分别选举 leader,出现脑裂,那么超过半数结点的分区 leader 可以继续对外服务,另一个分区 leader 无法提交
恢复网络正常后,小于半数结点的分区 leader 重新变成 follower,同时该分区的结点通过主节点日志追加丢失的数据
三 🏠 结语
身处于这个浮躁的社会,却有耐心看到这里,你一定是个很厉害的人吧 👍👍👍
各位博友觉得文章有帮助的话,别忘了点赞 + 关注哦,你们的鼓励就是我最大的动力
博主还会不断更新更优质的内容,加油吧!技术人! 💪💪💪