文章目录
- 零、绪论和IDE安装
- int取值范围
- 常犯的编程小错误
- 一、枚举和模拟 (暴力求解)
- (一) 枚举
- 1.Reverse函数 求 反序数
- 2.程序出错的原因
- 1.编译错误 (compile):基本语法错误
- 2.链接错误 (link):函数名写错了
- 3.运行错误 (run):结果与预期不符,断点调试 [打断点,看监视]
- 3.编程规范
- 1.判断时,固定值写左边
- 2.不要省略大括号
- 4.命名规范
- 1.变量命名规范
- (二) 模拟
- Ⅰ.图案问题:二维数组 + 找数字规律
- 1.不确定数量的输入 while(scanf("%d",&n) != EOF){ }
- 2.作用域
- 3.机试对字符串的处理
- 1.处理输入、输出:C风格字符串(字符数组):char str[1000]
- 2.处理更复杂问题:C++风格字符串:string
- 4.二维数组
- 5.OJ问题
- Ⅱ.日期问题
- 1.闰年问题
- 2.用空间换时间
- 3.打印日期用printf,比cout方便
- 4.map 映射
- Ⅲ.其他模拟问题
- 二、排序与查找
- (一) 排序
- 1.sort函数:sort(first,last,comp)
- 2.C语言数组
- 3.设计排序的规则:设计比较和交换的条件
- 4.C++函数重载:同一个函数名,有不同的参数列表
- 5.机试考试最重要的事情:能把你曾经做过的题目,满分地做出来
- (二) 查找
- 1.顺序查找(Liner Search)
- 时间复杂度、空间复杂度
- 2.二分查找(Binary Search)
- 3.用map解决查找问题
- 指针迭代器 iterator
- 三、字符串
- C字符数组:char arr[100] —— 输入输出
- C++字符串:string —— 其他复杂操作
- 四、线性数据结构
- 1.向量 vector
- 2.队列 queue
- 3.栈 stack
- 五、递归与分治
- 递归与分治的关系
- (一)、递归
- 函数
- 递归
- (二)、分治
- 六、非线性数据结构
- 内存空间
- 栈
- 堆 (自由存储区)
- 指针和引用
- 指针(间接访问 值传递)
- 引用(引用传递)
- 1.二叉树
- 二叉树的遍历
- 层次遍历:队列
- 递归遍历:前中后序遍历
- 重建二叉树,并遍历
- 2.二叉排序树 BST
- 3.优先队列 priority_queue(堆 heap)
- 堆
- 优先队列模板 STL-priority_queue
- 优先队列的应用
- 1.顺序问题
- 运算符重载
- 2.哈夫曼树
- 4.散列表 map
- 映射 map
- unorder_map
- 七、搜索
- BFS 广度优先搜索
- 打表
- DFS 深度优先搜索
- 剪枝算法
零、绪论和IDE安装
1.安装IDE:clion或vs
新手不要直接在clion上写代码,要在强大的IDE(集成开发环境)中练习,能方便的找出低级错误。
在IDE上通过后,再把代码复制到OJ中。
2.OJ的运行原理:OJ不会直接评判代码,而是用测试用例来测试你的输出结果是否与它的答案相符。如此便能在某些情况下“作弊”。
若OJ中某个测试用例超时,可以提前准备好答案,以便通过用例。例如,“打表”。
3.机试需要的函数:输入(scanf 或 cin)、输出(printf 或 cout)、读取一行(fgets 或 cin.getline)
机试考察的数据结构:数组、链表、二叉树
机试需要的算法:枚举、模拟、递归、分治、搜索



会50%、会70%和会90%都是零分。要会,就要100%会。要么满分,要么零分!
练精一道题,胜于浅尝辄止10道题!
int取值范围
int的取值范围为:-231 -231-1 ,即:-2147483648 - 2147483647
注意题目要求的n的范围,判断f(n)是否会超过int的取值范围。若超过,则需要换成float或double或long long int或unsigned int。
常犯的编程小错误
1.问题:等价条件判断是 == ,写成了 =
情况:不好定位。段错误,且半天没看出问题,逻辑都是对的。最后找助教才帮忙看出来,花了十几分钟。尴尬。
解决:遵守编程规范,在写等价判断时,值写在左边,变量写在右边。 这样即使把==写成了=,也会是编译错误,直接报语法错误,好定位。
一、枚举和模拟 (暴力求解)
(一) 枚举
循环 + if + printf
1.Reverse函数 求 反序数
int Reverse(int n){ //求反序数的Reverse函数
int remain;//每次的余数
int reverse = 0;
while(n != 0){
remain = n%10;
n = n/10;
reverse = reverse*10 + remain;
}
return reverse;
}
2.程序出错的原因
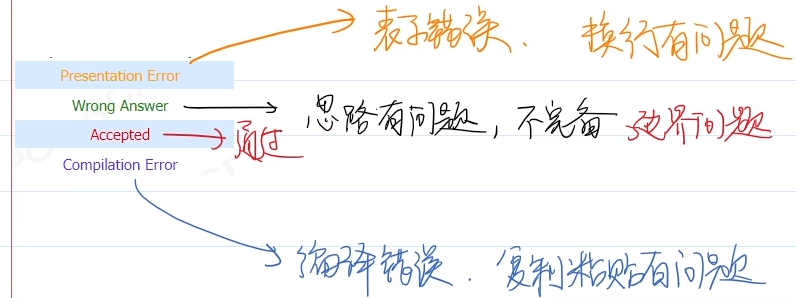
前两步统称构建(build)
1.编译错误 (compile):基本语法错误
1.定位第一个编译错误,根据行号、列号、提示,去解决第一个编译错误。
编译错误只看第一个错误。因为解决一个问题可能就会解决一片编译错误。
2.链接错误 (link):函数名写错了
编译通过,说明基本的语法没有错误。
链接错误,并不提示链接错误的位置。一般就是函数名字写错了。
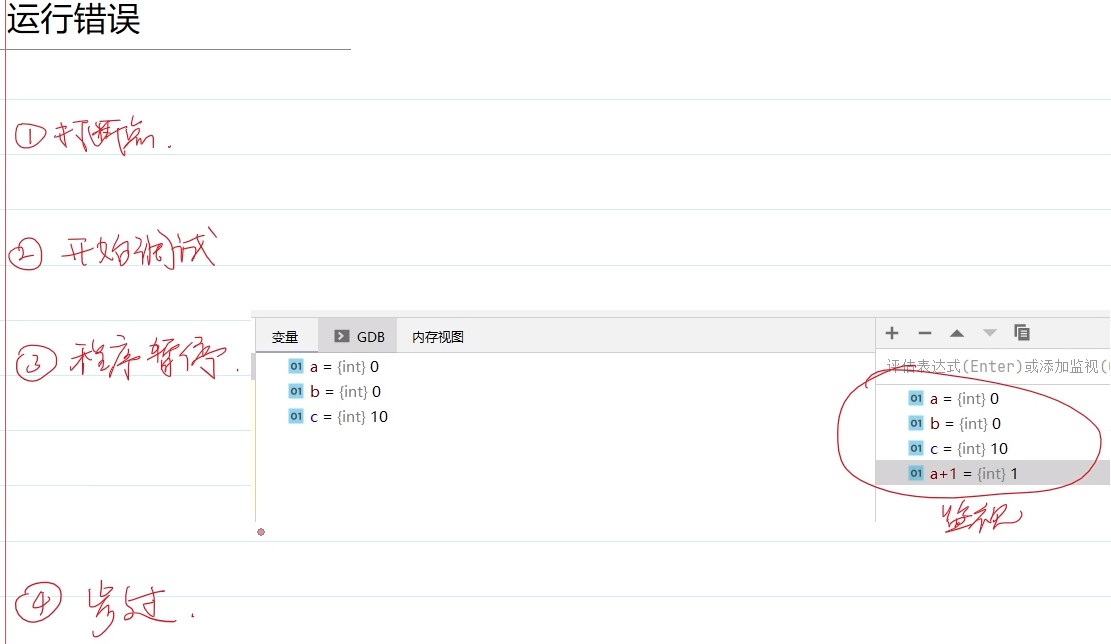
3.运行错误 (run):结果与预期不符,断点调试 [打断点,看监视]
运行时错误,构建(build)成功,即编译、链接都通过,但结果与预期不符。
运行错误也不会提示哪里有问题,这就需要通过打断点来进行断点调试了。
3.编程规范
1.判断时,固定值写左边
防止 if(n==0) 漏写为 if(n=0),导致死循环。而且这不是编译错误,检查不出来。
要写成if(0 == n),把固定值写左边。这样,如果漏写为 if( 0 =n)是不符合语法的,将错误提前到了编译阶段。
最简单的错误就是编译错误(语法错误)

2.不要省略大括号
虽然有些if里面只有一句话,可以省略花括号。但是对于企业级的项目来说,if里经常可能会添加新语句,而忘记花括号。对于这种经常变动的代码,务必全都加上大括号(即使只有一行),以防日后又增又删的调试。
即使你自己注意到了,难免后续接手的程序员不会忘记if里又加了几行时忘记使用花括号,而且这里加了没有调试,最终bug,花了半天时间才找到是因为这里if忘记加花括号了。
同时,维护别人写的代码时也要注意,在向单行循环体里加语句时,检查它是否有大括号。
4.命名规范
1.变量命名规范
①外层循环使用不常见的变量名,减少内外层冲突的可能性

②类名的首字母大写。(类包括struct、class)
(二) 模拟
Ⅰ.图案问题:二维数组 + 找数字规律

1.不确定数量的输入 while(scanf(“%d”,&n) != EOF){ }
//输入n,然后输入n个数
int n;
int arr[101];
while (scanf("%d",&n) != EOF){
for(int i=0;i<n;++i){
scanf("%d",&arr[i]);
}
}
注意:输入一串数据后,要先按Enter换行,再按Crtl+D。不换行则这一行数据没有输入缓冲区。
输入EOF:
①clion/gcc/clung:crtl+d
②vs:crtl+c
2.作用域
放在花括号内部的变量,生命周期只能在花括号里。
有时候有的变量需要设在全局,或者函数外部,才能被调用。
3.机试对字符串的处理
1.处理输入、输出:C风格字符串(字符数组):char str[1000]
C风格的字符串,本质是字符数组,以\0结尾。
char str[1000];//初始化
scanf("%s",str);//输入(字符串的输出不需要加&)
printf("%s\n",str);//输出
易错,%c注意要空格

2.处理更复杂问题:C++风格字符串:string
#include <string>
using namespace std;
①初始化:string str1 = "hello";
②连接:str1 = str1 + "world";
③下标访问:str1[0] //为h
④求长度:str1.length()
⑤判断相等:str1 == "hello"
⑥比较字典序:str1 > "abandon"
⑦从C++风格字符串转到C风格字符串:str1.c_str()
⑧删除最后一个字符:pop_back()
4.二维数组
char pat[80][80]={0};//定义二维数组并初始化,长度固定
5.OJ问题
Ⅱ.日期问题
1.闰年问题
bool isLeap = (year%400==0) || (year%100!=0 && year%4==0);//true是闰年
2.用空间换时间
辅助数组
int mday[13] = {0,31,28,31,30,31,30,31,31,30,31,30,31};
3.打印日期用printf,比cout方便
%d:打印数字
%4d:打印数字,至少4个位置宽,不足则用空格填充
%04d:打印数字,至少4个位置宽,不足则用0填充

cout的运行效率、格式控制,不如printf
4.map 映射
#include <map>
using namespace std;
map举例:
#include <cstdio>
#include <string>
#include <map>
using namespace std;
int main(){
//键 key --> 值 value
//<键的类型,值的类型>
map<string,string> myMap = {
{"Caixukun","ikun"},
{"Wuyifan","meigeni"}
};
char str[1000];
scanf("%s",&str);
string name = str;
printf("%s的粉丝被称为%s",name.c_str(),myMap[name].c_str());
}
Ⅲ.其他模拟问题
1.剩余的树
2.手机键盘
二、排序与查找
(一) 排序
1.sort函数:sort(first,last,comp)
C++引入了基于快速排序的排序函数:sort()
sort(first,last,comp)函数的三个参数:①first为待排序序列起始地址 ②last为结束地址 ③comp为排序方式,不填写默认为升序排序。
#include <algorithm>
using namespace std;
左闭右开 [arr,arr+n),尾后
例1:对n个数进行排序
样例输入:
4
1 4 3 2
样例输出:
1 2 3 4
#include <cstdio>
#include <algorithm>
using namespace std;
int main(){
int n;
int arr[101];
scanf("%d",&n);
for(int i=0;i<n;++i){
scanf("%d",&arr[i]);//&arr[i] 和 arr+i 等价
}
sort(arr,arr+n);//排序
for(int i=0;i<n;++i){
printf("%d ",arr[i]);
}
printf("\n");
}
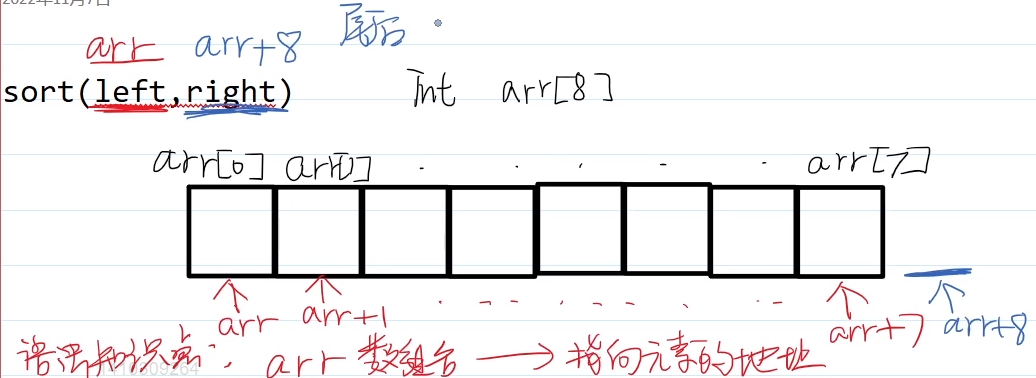
2.C语言数组
1.arr[i]是元素
2.arr是0号元素的地址。arr+i是i号元素的地址。
即,C语言数组的数组名,可以当地址/指针来使用。&arr[i] 和 arr+i 等价
3.设计排序的规则:设计比较和交换的条件
不发生交换,返回真
4.C++函数重载:同一个函数名,有不同的参数列表
比较的题目,重点就是设计bool comp(int lhs,int rhs)函数。//不发生交换时为真
5.机试考试最重要的事情:能把你曾经做过的题目,满分地做出来
最重要的不是把所有题目都写了个差不多,没用,差一点就是零分。要么满分要么零分。
最重要的是,把你曾经做过的题目,满分地做出来。
泥鳅老师:你就算是天纵奇才,也不可能在机试的时候把你从来没做过的题目做出来。就是一个熟练度的问题。
(二) 查找
1.顺序查找(Liner Search)
顺序查找的问题:效率不够高。
n个元素,顺序查找,时间复杂度为O(n²)。若数据量规模n在105,则会OJ超时。需要采取一些策略降低时间复杂度。
时间复杂度、空间复杂度
0.O()计数法:忽略常系数、忽略低阶项
1.时间复杂度:指令执行次数
2.空间复杂度:额外内存空间
2.二分查找(Binary Search)
要求先排序。数组有序后,才可使用二分查找。
基于比较的排序,时间复杂度最好为O(nlogn)

二分查找(需要排序)适用于:给定一份数据,要查很多次。
若每查一次,数据都改,那就用顺序查找,不需要排序。
mid = (left + right)/2;
left = mid + 1; /收缩区间,注意 +1 -1,避免二分查找死循环。
right = mid - 1;
3.用map解决查找问题
map的底层:二叉搜索树(BST)。
①在Windows下,会进一步优化为:平衡二叉树(AVL树)
②在Linux下,会进一步优化为:红黑树

指针迭代器 iterator
findIndex.begin():第一个元素的指针
findIndex.end():最后一个元素的后面一个位置的指针,尾后指针
findIndex.find():查找某个元素的指针
if(findIndex.find(findNum) == findIndex.end()) /说明没有找到
三、字符串
C字符数组:char arr[100] —— 输入输出
1.字符数组
以 \0 作为正文结束的标志,也占一个空间
2.输入输出效率
printf和scanf的效率要优于cin和cout
3.读取一整行
fgets(字符数组名,sizeof(字符数组名),stdin)
fgets最后会读入换行符\n ,占一个空间(字符数组转string后,考虑用pop_back()干掉回车)

getchar()吃掉回车
C++字符串:string —— 其他复杂操作
1.头文件
#include <string>
using namespace std;
2.获取长度/大小:
string str;
str.length();
str.size();
printf("length of str = %u\n",str.size());
3.下标访问元素
str[i](i从0开始)
for(unsigned int i = 0;i < str.size(); ++i){
printf("%c\n",str[i]);
}

4.(字符串的)迭代器访问元素
for(string::iterator it = str.beign(); it != str.end(); ++it){
//++it 更改迭代器的指向,到下一个元素
printf("%c\n", *it); // &取地址, *取内容
}

5.连接:字符串连接/拼接
+ (只针对C++风格字符串string类型,C风格字符数组禁止相加)
string str = buf;
str = str + "world";
6.删除 erase(下标)
str.erase(str.size()-1); //删除最后一个元素,即\n
7.清空 clear()
str.clear();
8.查询字符或字符子串的下标 .find(内容)
①find("字符串")
②find(变量名)


9.取字串 .substr(起始下标,长度)
若要切到尾为止,则只写一个参数:起始下标,不用写长度。
10.删除最后一个字符:pop_back()
四、线性数据结构
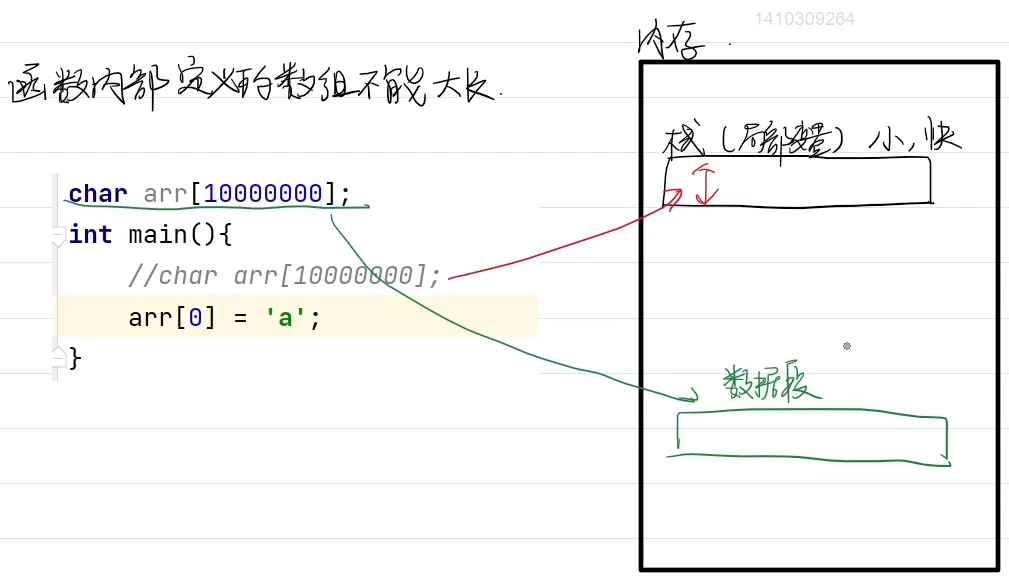
1.当定义的数组特别大,达到1千万时,不能定义在函数内部,会崩溃。栈比较小,但快。
要定义在全局位置,数据段中。
【局部大数组会崩溃,全局大数组不会崩溃】
2.标准模板库STL
1.向量 vector
vector是动态数组,长度可改变。 vector<int> vec;//创建空向量,长度为0
普通静态数组长度是固定不变的。int arr[100];//创建长度为100的静态数组
1.头文件
#include <vector>
using namespace std;
2.声明向量
vector<int> vec;//长度为0
3.赋初值
vector<int> vec2 {1,2,3};
4.申请一定空间的向量,所有元素初值默认为0
vector<int> vec3(10000);
※5.尾部插入:尾部扩容 push_back(元素) 。效率最高,插入n个为O(n),插入1个为O(1)。
vec.push_back(1);//vec[0]=1
vec.push_back(3);//vec[1]=3
※6.尾部删除:弹出尾部元素 pop_back()
vec.pop_back();
※7.下标访问
vec[i] //下标>=n时,数组越界
8.长度计算
vec.size();
9.两种遍历方法
①下标遍历
for(unsigned int i = 0; i < vec.size(); ++i){
printf("vec[%d] = %d\n",i,vec[i]);
}
②迭代器遍历
for(vector<int>::iterator it = vec.begin(); it != vec.end(); ++it){
printf("vec[] = %d\n",*it);
}
10.随机位置的插入:insert(位置,元素)
vector<int>::iterator it1 = vec.begin()+1;//迭代器指针指向vector的第二个位置
vec.insert(it1,3);//在vector第二个位置插入元素3
11.随机位置的删除:erase(位置);
vec.erase(vec.begin());//删除vector的第一个位置的元素
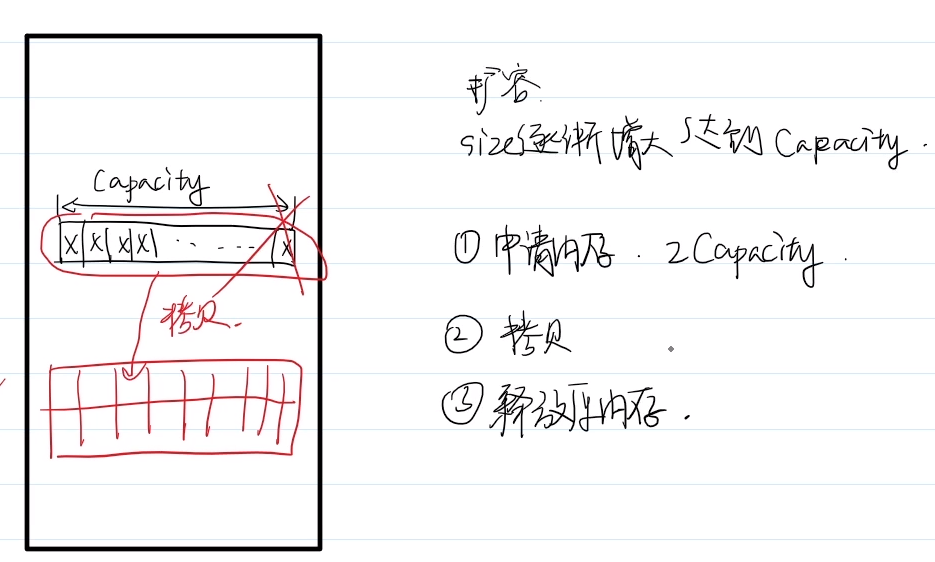
12.vector的实现原理
(1)vector的组成、申请空间(堆上)
vector是类类型,包括size容量、capacity内存大小、ptr首地址
首地址存放在栈上,但vector申请的内存空间在堆区上,堆区比栈区大,因此vector可申请空间比静态数组在栈上申请的空间可以大很多。【静态数组 - 栈 - 小空间。 vector - 堆- 大空间】
(2)vector的扩容机制
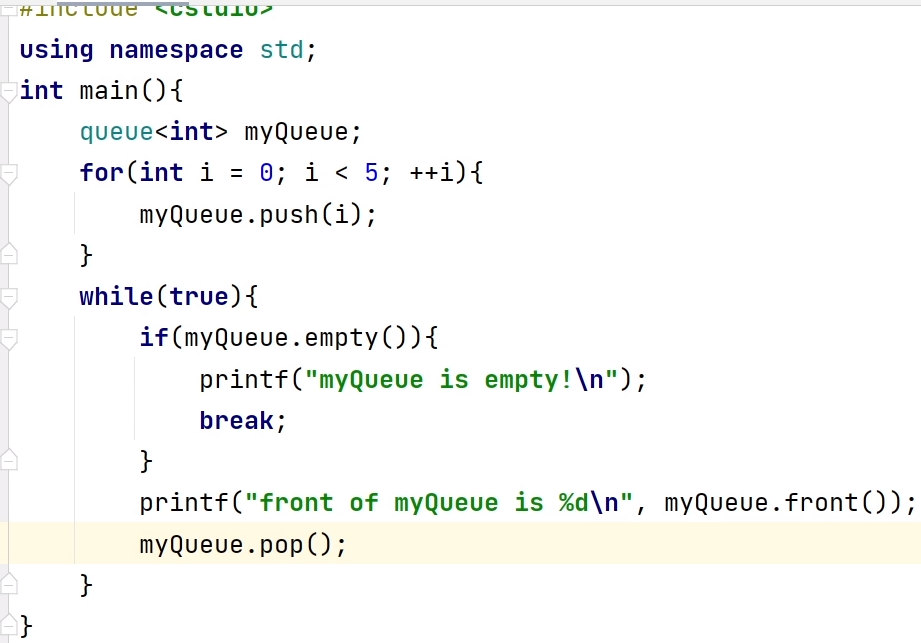
2.队列 queue
队列queue是受限制的线性表。只能在队尾加入,从队头入队。
1.头文件
#include <queue>
using namespace std;
queue<int> myQueue;
2.队尾入队 .push(变量名)
for(int i = 0;i <= 5;++i){
myQueue.push(i);
}
3.队头出队 .pop()
4.判空 .empty()
5.队首元素 .front()
3.栈 stack
操作受限的线性表,只能一端进出。
栈,禁止操作的一端称为盲端。允许元素插入和删除的一端称为栈顶。
1.头文件
#include <stack>
using namespace std;
stack<typename> myStack//定义
2.方法
.size():栈大小
.push():压栈,将元素加入栈中
.top():获取栈顶内容
.pop():弹栈
.empty():判断栈是否为空
3.栈的应用
(1)逆序输出
(2)括号匹配
(3)表达式求值
五、递归与分治
递归与分治的关系
分治是一种思想,分而治之;递归是一种实现方法,函数调用自己。
分治思想可用递归来实现,也可以用其他方法来实现。递归作为一种方法,不止可以用于实现递归思想,也可以用来实现其他思想。
但总的来说,一般都用递归方法来实现分治的思想。故两者本不是同一纬度的概念,但是经常放在一起谈论。
常见的分治:求斐波那契数列、快速排序
常见的递归:求n的阶乘
(一)、递归
从函数到递归
①大问题→小问题,等价条件
②确定最小问题,即递归出口
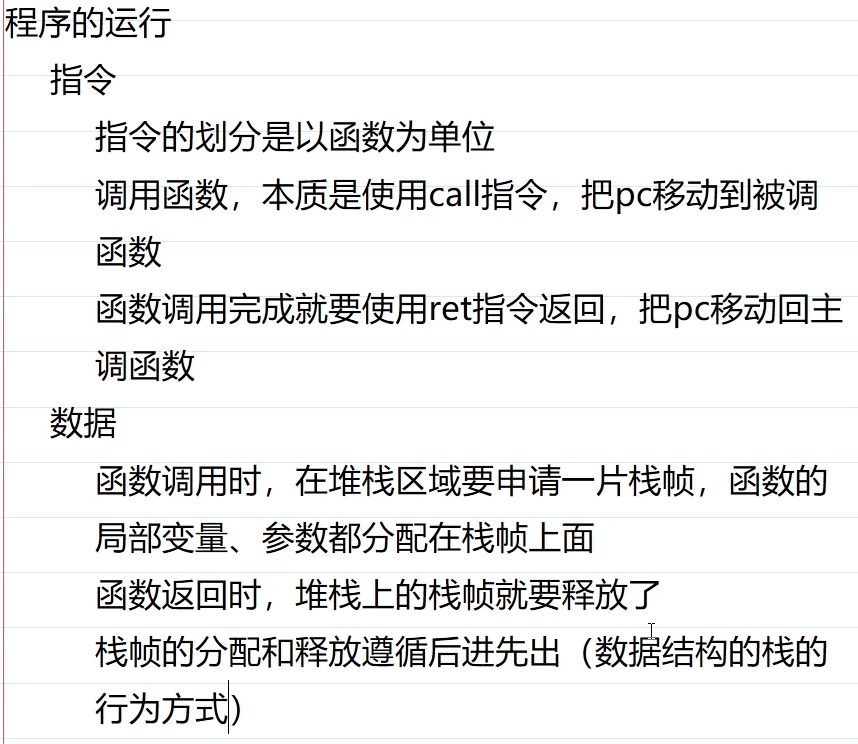
函数
C语言编写的代码,以函数定义为单位。
call:把PC移到被调函数
ret:把PC移回主调函数
递归
1.在函数定义中调用本函数,叫做递归。
2.递归关注的两个点:
①大问题转化为小问题:规模n→规模n-1
②最小问题:递归出口
例题1:n的阶乘
例题2:汉诺塔
(二)、分治
①分解:大问题拆成小问题
②治理:找到等价条件,解决递归出口(最小问题)
③合并

例题1:斐波那契数列
例题网址:http://t.cn/Ai0K3tU5
题解:
#include <cstdio>
int Fabonacci(int n){
if(0==n || 1==n){
return n;
}else{
return Fabonacci(n-1)+ Fabonacci(n-2);
}
}
int main(){
int n;
while(scanf("%d",&n) != EOF){//注意,输入多个数据后,要先Enter换行,再按crtl+D
if(n>=0){
printf("%d\n",Fabonacci(n));
}else{
printf("error: n must >= 0\n");
}
}
}
例题2:二叉树
提交网址:http://t.cn/Ai0Ke6I0
#include <cstdio>
int binaryTree(int m,int n){
if(m>n){
return 0;
}else{
return binaryTree(2*m,n) + binaryTree(2*m+1,n) + 1;
}
}
int main(){
int m,n;
while(scanf("%d %d",&m,&n) != EOF){
if(m<=0 && n<=0){
break;
}
printf("%d\n",binaryTree(m,n));
}
}
六、非线性数据结构
内存空间
栈
栈帧。当被调函数执行结束,栈帧上的变量也会被自动回收。
堆 (自由存储区)
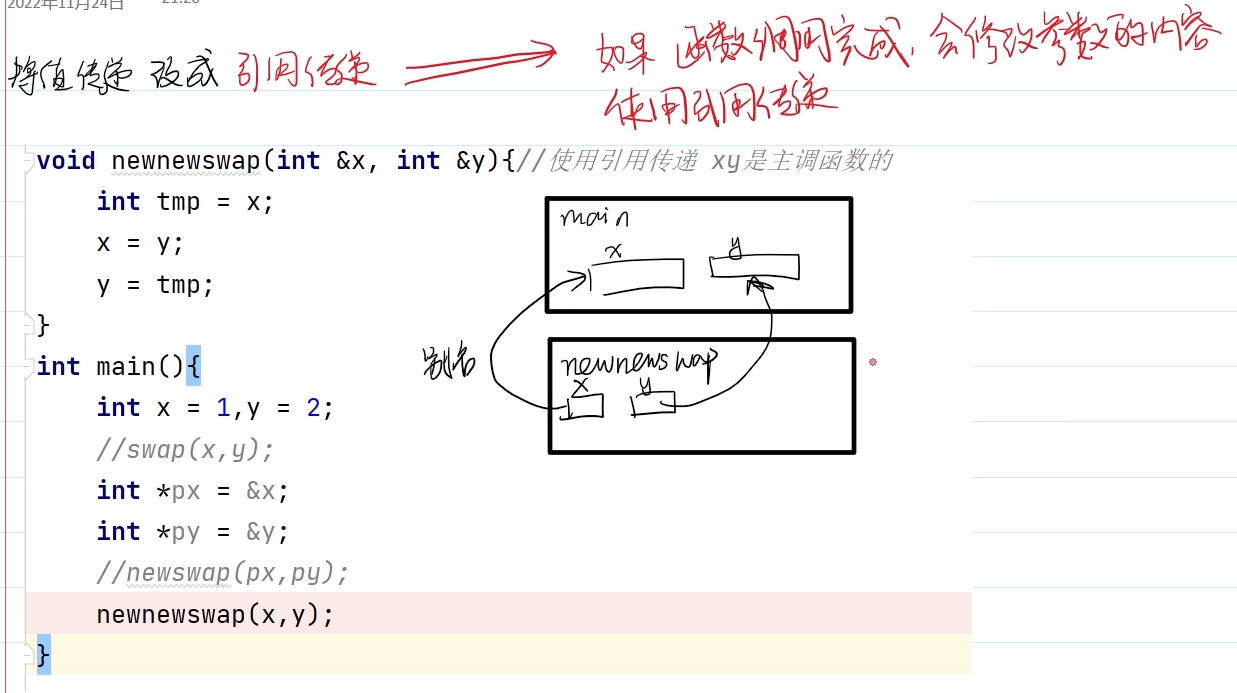
new出来的,不会自动销毁。需要手动回收,否则会发生内存泄漏。

指针和引用
指针(间接访问 值传递)
1.* 取内容(间接访问)

2. &取地址
3.->运算符
若p为指针,则(*p).member与p->member等价

引用(引用传递)
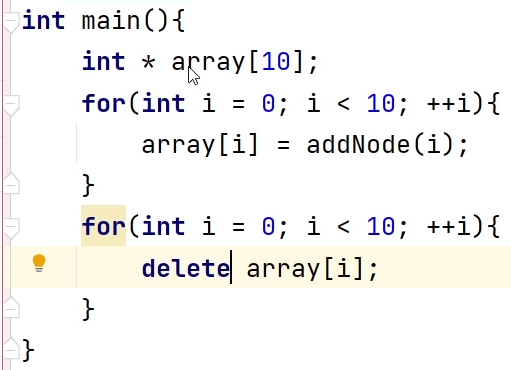
引用,&x,&y就是给变量x,y起了个别名,并没有新开辟内存存储空间。这样,被调函数的参数列表(int &x, int &y)就可以直接引用传递给主函数中的变量x,y。因为&x &y与x y 享有同一个内存地址,会直接修改。
C++的两种传递方式:值传递、引用传递
例1:变量名-直接访问-值传递:在被调函数中无法修改主调函数中参数的内容。尽管变量名相同,但不是同一个地址
#include <cstdio>
void swap1(int x,int y){
int temp = x;
x = y;
y = temp;
}
int main(){
int x = 1 ,y = 2;
swap1(x,y);
}
结果是,在swap1中x与y的值互换了,但main中的x与y的值不变。因为swap1中和main中的x、y的地址不同。
例2:指针-间接访问-值传递
在被调函数里改变主调函数中变量的内容:传指针(间接访问)
在普通函数中想要改变main函数中的值,要传指针。值才能透出去。
#include <cstdio>
void swap2(int *px,int *py){
int temp = *px;
*px = *py;
*py = temp;
}
int main(){
int x = 1 ,y = 2;
int *px = &x;
int *py = &y;
swap2(px,py);
}
例3:引用-引用传递
对比例1,只修改了被调函数的参数列表,将int x,int y改为 int &x,int &y
#include <cstdio>
void swap3(int &x,int &y){
int temp = x;
x = y;
y = temp;
}
int main(){
int x = 1 ,y = 2;
swap3(x,y);
}
1.二叉树
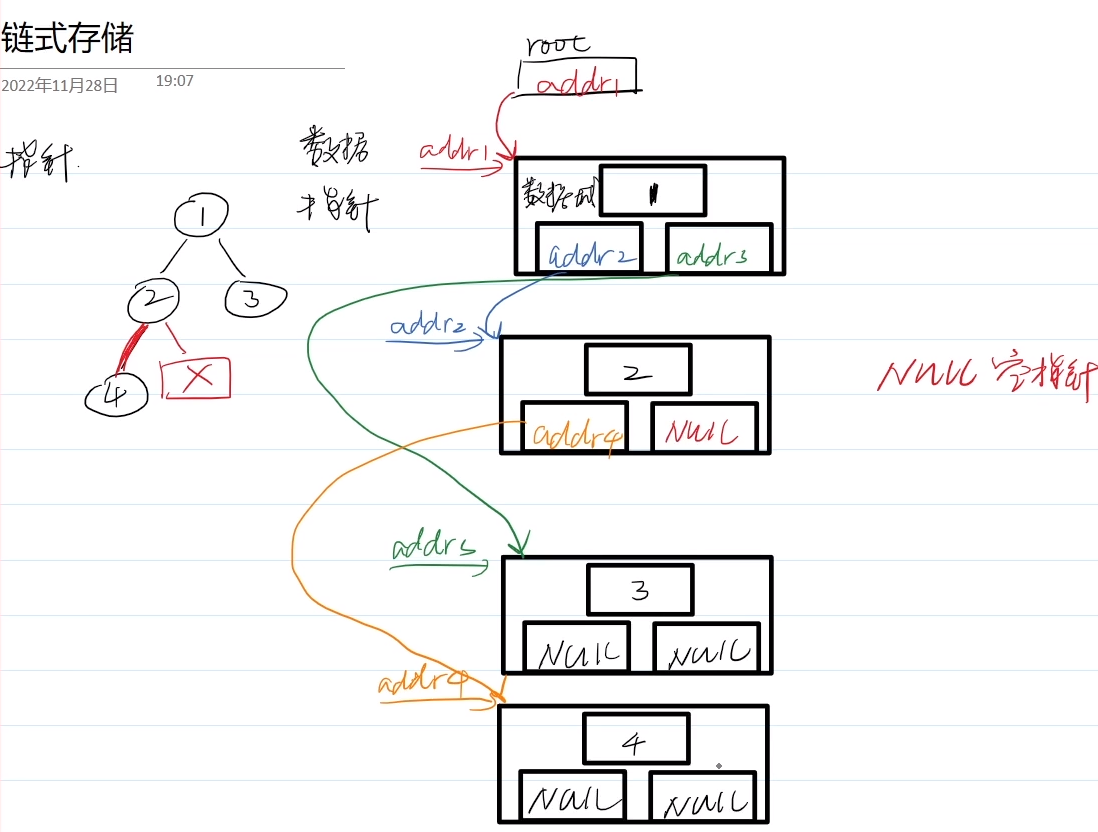
二叉树的遍历
层次遍历:队列
递归遍历:前中后序遍历
重建二叉树,并遍历
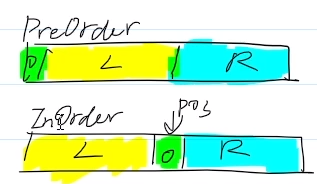
例1:通过先序序列和中序序列建立二叉树,再输出后序遍历序列(华科复试上机真题)
提交网址:http://t.cn/AiKgDfLU
#include <cstdio>
#include <string>
using namespace std;
struct TreeNode{
char data;
TreeNode * leftChild;
TreeNode * rightChild;
};
TreeNode *rebuild(string preOrder,string inOrder){ //返回值为子树根结点的地址
if(preOrder.size() == 0){
return NULL;
}else{
//从先序遍历确定根
char rootdata = preOrder[0];
TreeNode *pNewNode = new TreeNode;//二叉树结点指针
pNewNode->data = rootdata;
//用根位置切割中序
int pos = inOrder.find(rootdata);//pos是根在中序序列中出现的下标
pNewNode->leftChild = rebuild(preOrder.substr(1,pos),inOrder.substr(0,pos));
pNewNode->rightChild = rebuild(preOrder.substr(pos+1),inOrder.substr(pos+1));
return pNewNode;
}
}
void PostOrder(TreeNode * root){
if(root == NULL){
return;
}
PostOrder(root->leftChild);
PostOrder(root->rightChild);
printf("%c",root->data);
return;
}
int main(){
char preOrder[30];
char inOrder[30];
while(scanf("%s%s",preOrder,inOrder) != EOF){
TreeNode * root = rebuild(preOrder,inOrder);
PostOrder(root);
printf("\n");
}
}
例2:根据有#的先序遍历序列,构建二叉树,并输出中序遍历序列 (清华复试上机真题)
哈哈哈
2.二叉排序树 BST
二叉排序树(二叉搜索树,二叉查找树 BST) 的建立
#include <cstdio>
struct TreeNode{ //类类型/结构体类型
int data; //数据域
TreeNode * leftChild; //左孩子指针
TreeNode * rightChild;//右孩子指针
};
void insertBST(TreeNode * &root,int data){//根,数据域
TreeNode *pNewNode = new TreeNode;//申请一个空结点 pNewNode
pNewNode->data = data;//主函数传进来的data,赋值给结点的数据域 pNewNode->data
pNewNode->leftChild = NULL;//左孩子置为空
pNewNode->rightChild = NULL;//右孩子置为空
if(NULL == root){
root = pNewNode; //若根结点为空,则让当前结点TreeNode * pNewNode 作为根结点 TreeNode * root
}
else{
TreeNode * pPre = root;
TreeNode * pCur;
while(true){
if(data < pPre->data){//新数据比根结点小,作为左孩子
pCur = pPre->leftChild;
if( NULL == pCur ){//左孩子为空 //判断条件是 == ,写成一个 = 了
pPre->leftChild = pNewNode;
break;
}else{//左孩子结点不为空
pPre = pCur;//当前结点作为新的根结点
}
}else{//新数据比根结点大,作为右孩子
pCur = pPre->rightChild;
if( NULL == pCur ){ //判断条件是 == ,写成一个 = 了
pPre->rightChild = pNewNode;
break;
}else{
pPre = pCur;
}
}
}
}
}
int main(){
TreeNode * root = NULL;
int array[] = {2,3,5,1,4};
for(int i = 0;i < 5; ++i){
insertBST(root,array[i]);
}
}
例题1:华科 KY207 二叉排序树
提交网址:http://t.cn/Ai9PAkkv
#include <cstdio>
struct TreeNode{ //类类型/结构体类型
int data; //数据域
TreeNode * leftChild; //左孩子指针
TreeNode * rightChild;//右孩子指针
};
void insertBST(TreeNode * &root,int data){//根,数据域
TreeNode *pNewNode = new TreeNode;//申请一个空结点 pNewNode
pNewNode->data = data;//主函数传进来的data,赋值给结点的数据域 pNewNode->data
pNewNode->leftChild = NULL;//左孩子置为空
pNewNode->rightChild = NULL;//右孩子置为空
if(NULL == root){
root = pNewNode; //若根结点为空,则让当前结点TreeNode * pNewNode 作为根结点 TreeNode * root
printf("-1\n");
}
else{
TreeNode * pPre = root;
TreeNode * pCur;
while(true){
if(data < pPre->data){//新数据比根结点小,作为左孩子
pCur = pPre->leftChild;
if( NULL == pCur ){//左孩子为空 //判断条件是 == ,写成一个 = 了
pPre->leftChild = pNewNode;
printf("%d\n",pPre->data);
break;
}else{//左孩子结点不为空
pPre = pCur;//当前结点作为新的根结点
}
}else{//新数据比根结点大,作为右孩子
pCur = pPre->rightChild;
if( NULL == pCur ){ //判断条件是 == ,写成一个 = 了
pPre->rightChild = pNewNode;
printf("%d\n",pPre->data);
break;
}else{
pPre = pCur;//当前结点作为新的根结点
}
}
}
}
}
int main(){
TreeNode * root = NULL;
int n;
scanf("%d",&n);
for(int i = 0;i < n; ++i){
int num;
scanf("%d",&num);
insertBST(root,num);
}
return 0;
}
例题2:浙大 判断是否为同一个二叉搜索树序列
提交网址:http://t.cn/Ai9PUJtK
在这里插入代码片
3.优先队列 priority_queue(堆 heap)
堆
1.堆
优先队列不是队列(queue)而是堆(heap),是二叉堆(大根堆、小根堆),结构是完全二叉树,用数组保存。
2.大根堆
优先队列默认为大根堆。
priority_queue<typename>name;
3.小根堆 (重新定义优先队列)
priority_queue<typename,vector<typename>,greater<typename>>name
优先队列模板 STL-priority_queue
1.定义
#include <queue>
using namespace std;
priority_queue<typename>name;
2.状态
①队空:是否为空 empty()
②队长:元素个数 size()
3.增删元素
①出队:插入元素 push()
②入队:删除元素 pop()
4.元素访问
队首:只能访问优先级最高的元素 top()
优先队列的应用
1.顺序问题
运算符重载
重载小于运算符:operator <
2.哈夫曼树
1.求WPL(带权路径和)
①构建哈夫曼树,再求WPL:已掌握
②迭代式求WPL

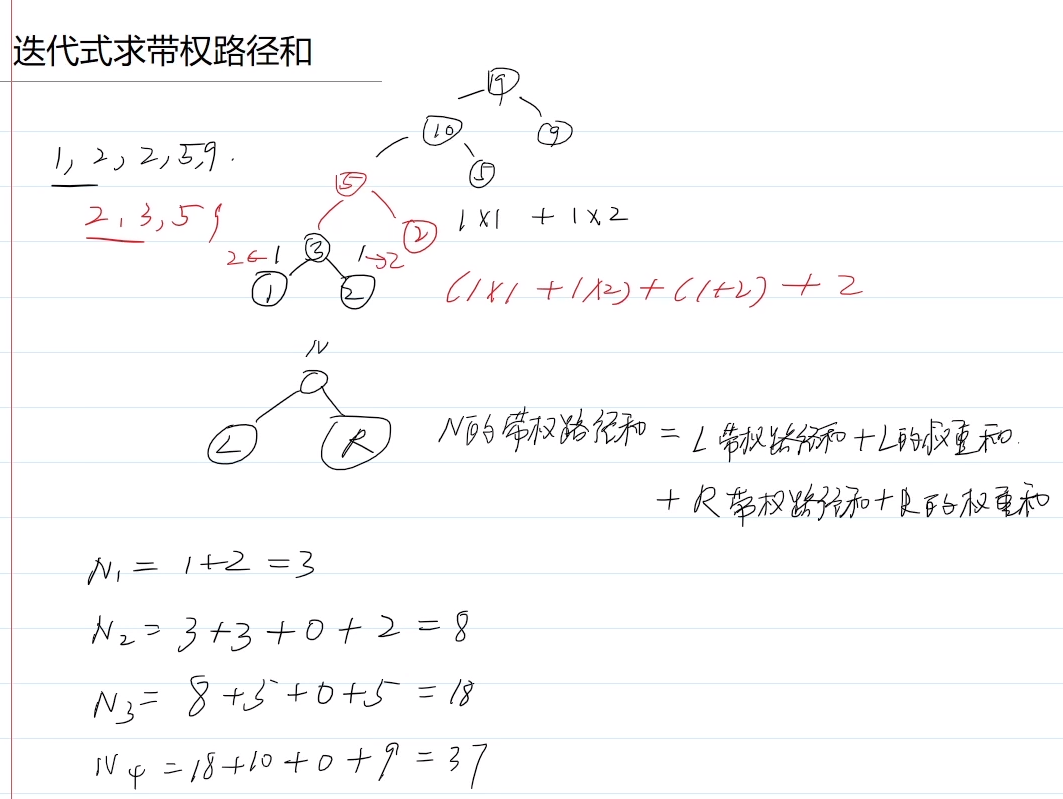
例题1:哈夫曼树 (北邮复试上机真题)
提交网址:http://t.cn/AiCuGMki
#include <cstdio>
#include <queue>
using namespace std;
int main(){
priority_queue<int> pqueue;
int n;
scanf("%d",&n);
for(int i = 0; i < n; ++i){
int weight;
scanf("%d",&weight);
pqueue.push(-weight);
}
int res = 0; //存储带权路径长度和的中间结果
while(pqueue.size()>1){
int leaf1 = pqueue.top();
pqueue.pop();
int leaf2 = pqueue.top();
pqueue.pop();
res += leaf1 + leaf2;
pqueue.push(leaf1+leaf2);
}
printf("%d\n",-res);
return 0;
}
4.散列表 map
映射 map
1.map底层:红黑树 (RBT∈BST),
2.特点:所以map会自动排好序 (BST中序遍历是升序序列)。
3.map查找:时间复杂度 O(logn) (和二分查找相同的时间复杂度,但比二分查找需要更多的空间)
4.操作
(1)头文件
#include <map>
using namespace std;
定义
map<string,int> myMap;
初始化:
map<string,int> myMap = {
{"Caixukun",1},
{"Wuyifan",2},
{"Liyifeng",3}
};
(2)插入键值对
①insert()方法
myMap.insert(pair<string,int>("Wuyifan",2));
②[]下标访问运算符
myMap["Caixukun"] = 1;
删除键值对:erase()
myMap.erase("Wuyifan");
读取键对应的值:
(3)判空:empty()
求长度(获取键值对个数):size()
(4)map的遍历:迭代器 iterator (迭代器是指向内部元素的指针)
①定义迭代器:map<string,int>::iterator it;
②第一个成员的位置:.begin()
③尾后位置:.end()
④迭代器指针后移:++it (++it使得迭代器指针指向下一对键值对,unorder_map不支持此操作)
⑤键:it->first
⑥值:it->second
map<string,int>::iterator it;
for(it = myMap.begin();it != myMap.end();++it){
printf("%s %d\n",it->first.c_str(),it->second);
}
(5)查找某个键是否存在:find()函数

例题1:查找学生信息 (清华大学复试上机题)
提交网址:http://t.cn/AiCuVIuY
#include <cstdio>
#include <string>
#include <map>
using namespace std;
struct Student{
string name;
string gender;
int age;
};
int main(){
int n;
scanf("%d",&n);
map<string,Student> InfoMap;
for(int i = 0; i < n; ++i){
char num[30];
char name[30];
char gender[30];
int age;
scanf("%s %s %s %d",num,name,gender,&age);
//key string
string numstr = num;
//value Student
Student student;
student.name = name;
student.gender = gender;
student.age = age;
InfoMap[numstr] = student;
}
int m;
scanf("%d",&m);
for(int i = 0; i < m; ++i){
char num[30];
scanf("%s",num);
string numstr = num;
if(InfoMap.find(numstr) != InfoMap.end()){//找到了
printf("%s %s %s %d\n",numstr.c_str(),
InfoMap[numstr].name.c_str(),
InfoMap[numstr].gender.c_str(),
InfoMap[numstr].age);
}else{//学号没找到
printf("No Answer!\n");//这里漏加换行符\n,导致格式错误了好几次。
}
}
}
例题2:魔咒词典 (浙大上机复试真题)
提交网址:http://t.cn/AiCufczt
#include <cstdio>
#include <string>
#include <map>
using namespace std;
//魔咒词典 (采用 增量编辑法:即写一部分,测试一部分)
int main(){
map<string,string> dict;
while(true){
char line[200];
fgets(line,200,stdin);//输入一行
string linestr = line;
linestr.pop_back();//干掉回车,string最后一个字符为\n
if("@END@" == linestr){
break;
}
// printf("%s\n",linestr.c_str());
int pos = linestr.find("]");
string word = linestr.substr(0,pos+1);
string info = linestr.substr(pos+2);
// printf("word = %s, info = %s\n",word.c_str(),info.c_str());
dict[word] = info;
dict[info] = word;
}
int n;
scanf("%d",&n);
getchar();//吃掉回车 ※
for(int i = 0 ; i < n; ++i){
char line[200];
fgets(line,200,stdin);
string linestr = line;
linestr.pop_back();
if(dict.find(linestr) != dict.end()){//存在魔咒或功能
if('[' == linestr[0]){//输入魔咒,查找功能
printf("%s\n",dict[linestr].c_str());
}else{//输入功能查找魔咒
string charm = dict[linestr];//[xxxxxx],想办法去掉[]
string charm_sub = charm.substr(1,charm.size()-2);//取子串,去掉了[]
printf("%s\n",charm_sub.c_str());
}
}else{//不存在该魔咒或功能
printf("what?\n");
}
}
}
unorder_map
1.底层:HashTable 散列表
2.unorder_map查找:时间复杂度O(1)
3.特点:①空间特别大 ②无序,不能遍历
七、搜索
搜索问题,就是带有限制的枚举问题。
BFS 广度优先搜索
BFS,Breadth First Search,广度优先搜索(宽度优先搜索)。
为了求最优解问题
例题1:Catch that Cow
例题2:Find the Multiple
打表
当OJ时限很小,且输入范围有限(1≤n≤200)
还是上文例题2:Find the Multiple,用打表法解决
DFS 深度优先搜索
DFS,Depth First Search,深度优先搜索。
为了知道问题是否有解,例如找迷宫出口
例题1:A Knight’s Journey
例题2:Square
剪枝算法
在深度优先遍历搜索过程中,可以通过放弃对某些不可能产生结果的子集的搜索,达到提高效率的目的。这样的技术称为剪枝。










![buu [NCTF2019]babyRSA 1](https://img-blog.csdnimg.cn/a84c6d7d505e456bb29a7719367fe26e.png)