目录
- 一、自定义分析器的概述
- 二、自定义的分析器的测试示例
一、自定义分析器的概述
Elasticsearch 带有一些现成的分析器,然而在分析器上 Elasticsearch 真正的强大之
处在于,你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单
元过滤器来创建自定义的分析器。
一个 分析器 就是在一个包里面组合了三种函数的一个包装器, 三种函数按照顺序被执行:
- 字符过滤器
字符过滤器 用来 整理 一个尚未被分词的字符串。例如,如果我们的文本是 HTML 格式的,它会包含像 < p> 或者 < div> 这样的 HTML 标签,这些标签是我们不想索引的。我们可以使用 html 清除 字符过滤器 来移除掉所有的 HTML 标签,并且像把 Á 转换为相对应的 Unicode 字符 Á 这样,转换 HTML 实体。一个分析器可能有 0 个或者多个字符过滤器。 - 分词器
一个分析器 必须 有一个唯一的分词器。分词器把字符串分解成单个词条或者词汇单元。 标准 分析器里使用的 标准 分词器 把一个字符串根据单词边界分解成单个词条,并且移除掉大部分的标点符号,然而还有其他不同行为的分词器存在。
例如:
关键词 分词器 完整地输出 接收到的同样的字符串,并不做任何分词。
空格 分词器 只根据空格分割文本 。
正则 分词器 根据匹配正则表达式来分割文本 。 - 词单元过滤器
经过分词,作为结果的 词单元流 会按照指定的顺序通过指定的词单元过滤器 。词单元过滤器可以修改、添加或者移除词单元。 如:lowercase 和 stop 词过滤器。
在 Elasticsearch 里面还有很多可供选择的词单元过滤器,例如:
词干过滤器 把单词遏制为词干。
ascii_folding 过滤器 移除变音符,把一个像 “très” 这样的词转换为 “tres” 。
ngram 和 edge_ngram 词单元过滤器 可以产生 适合用于部分匹配或者自动补全的词单元。
二、自定义的分析器的测试示例
-
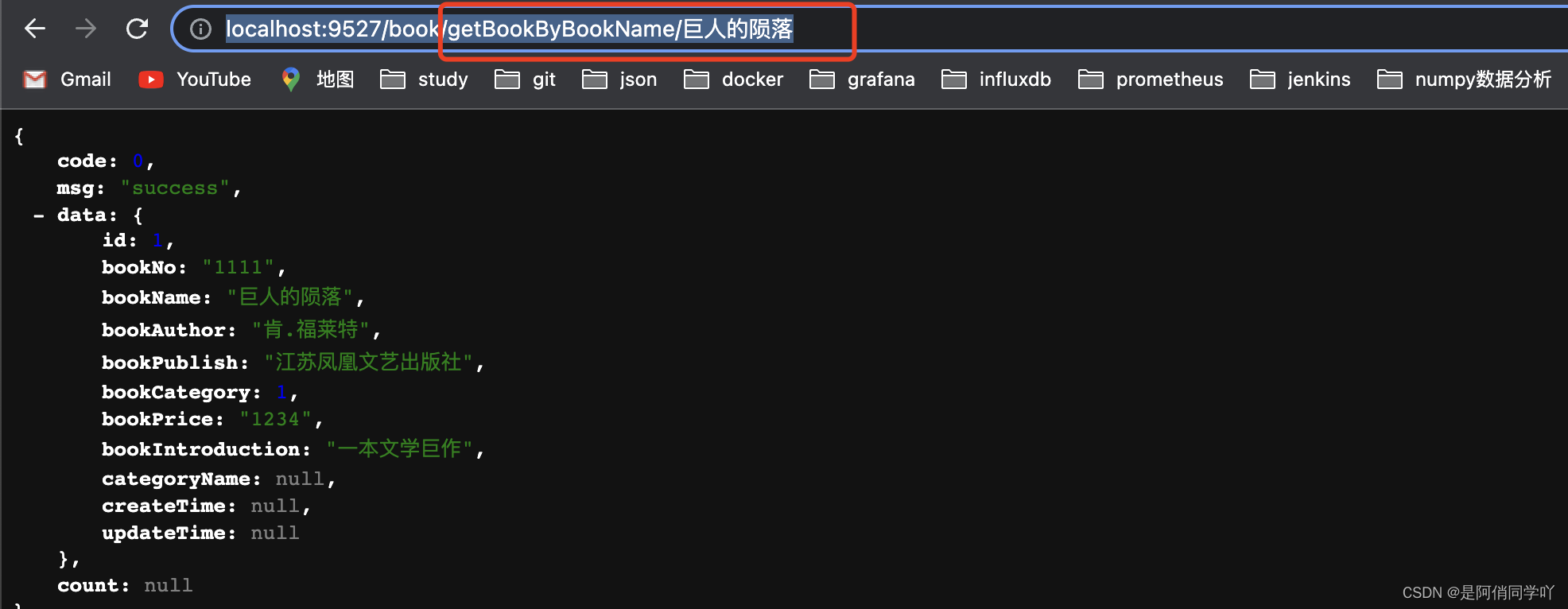
通过postman工具,在消息体里,指定分析器和要分析的文本
# PUT http://localhost:9200/my_index { "settings": { "analysis": { "char_filter": { "&_to_and": { "type": "mapping", "mappings": [ "&=> and "] } }, "filter": { "my_stopwords": { "type": "stop", "stopwords": [ "the", "a" ] } }, "analyzer": { "my_analyzer": { "type": "custom", "char_filter": [ "html_strip", "&_to_and" ], "tokenizer": "standard", "filter": [ "lowercase", "my_stopwords" ] } } } } }
-
索引被创建以后,使用 analyze API 来 测试这个新的分析器
# GET http://127.0.0.1:9200/my_index/_analyze { "text":"The quick & brown fox", "analyzer": "my_analyzer" }

![【洛谷 P1563】[NOIP2016 提高组] 玩具谜题(模拟+结构体数组+指针)](https://img-blog.csdnimg.cn/img_convert/2883bf91a18fa198dacc9a654ba9435b.png)