有轮子尽量用轮子 😭 😭 😭 😭 😭 😭
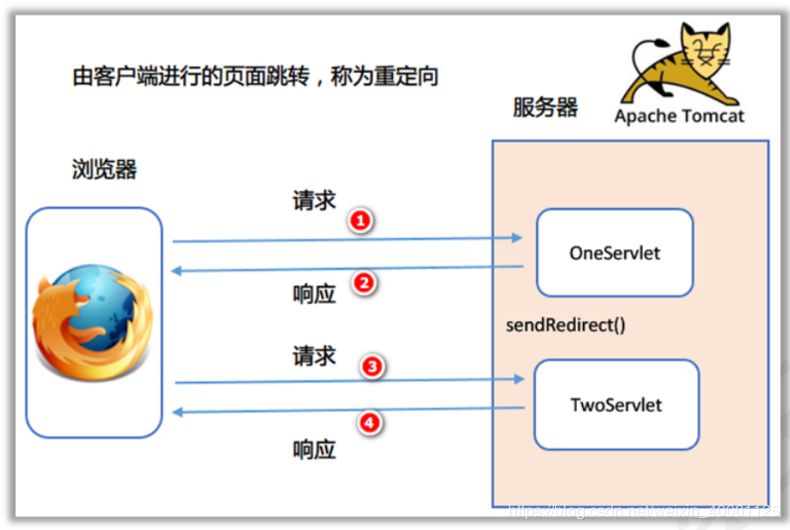
我们在开发中基于Gin开发了一个Api网关,但上线后发现内存会在短时间内暴涨,然后被OOM kill掉。具体内存走势如下图:

放大其中一次

在图二中可以看到内存的增长是很快的,在一分半的时间内,内存增长了近2G。
对于这种内存短时间暴涨的问题,pprof不好管用,除非写个脚本定时去pprof
经过再次review代码,找到了原因了
package server
import (
"bytes"
"fmt"
"github.com/gin-gonic/gin"
jsoniter "github.com/json-iterator/go"
)
var json = jsoniter.ConfigCompatibleWithStandardLibrary
type BodyDumpResponseWriter struct {
gin.ResponseWriter
body *bytes.Buffer
}
func (w *BodyDumpResponseWriter) Write(b []byte) (int, error) {
w.body.Write(b) // 注意这一行
return w.ResponseWriter.Write(b)
}
func ReadResponseBody(ctx *gin.Context) {
rbw := &BodyDumpResponseWriter{body: &bytes.Buffer{}, ResponseWriter: ctx.Writer}
ctx.Writer = rbw
ctx.Next()
rawResp := rbw.body.String()
if len(rawResp) == 0 {
AbnormalPrint(ctx, "resp-empty", rawResp)
return
}
ctx.Set(ctx_raw_response_body, rawResp)
// 序列化Body,并放到ctx中
// 读取响应Body的目的是记录审计日志用
}
// AbnormalPrint 异常情况,打印信息到日志
func AbnormalPrint(ctx *gin.Context, typ string, rawResp string) {
// 具体代码忽略
}
简单一看,这不就是Gin获取响应体一种标准的方式吗?毕竟GitHub及Stack Overflow上都是这么写的
https://github.com/gin-gonic/gin/issues/1363
https://stackoverflow.com/questions/38501325/how-to-log-response-body-in-gin
那么问题出在哪呢?
再看下代码,可以看到这个代码的逻辑是每一个请求都会将响应的Body完整的缓存在内存一份,对于响应体很大的请求,在这里就会造成内存暴涨,比如:像日志下载。
找到了原因修改起来就比较简单了,根据请求响应的Header跳过文件下载类的请求;同时根据请求的Header跳过SSE及Websocket请求,因为这两类流的请求记录到审计日志中意义不大,而且在json序列化的时候也会有问题。
package server
import (
"bytes"
"fmt"
"net/http"
"strings"
"github.com/gin-gonic/gin"
jsoniter "github.com/json-iterator/go"
)
var json = jsoniter.ConfigCompatibleWithStandardLibrary
type BodyDumpResponseWriter struct {
gin.ResponseWriter
body *bytes.Buffer
}
func (w *BodyDumpResponseWriter) Write(b []byte) (int, error) {
// 文件下载类请求,不再缓存相应结果
if !isFileDownLoad(w.Header()) {
w.body.Write(b)
}
return w.ResponseWriter.Write(b)
}
func isNoNeedToReadResponse(req *http.Request) bool {
if isSSE(req) || isWebsocket(req) {
return true
}
return false
}
func isSSE(req *http.Request) bool {
contentType := req.Header.Get("Accept")
if contentType == "" {
contentType = req.Header.Get("accept")
}
contentType = strings.ToLower(contentType)
// sse
if !strings.Contains(contentType, "text/event-stream") {
return false
}
return true
}
// https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/MIME_types
// https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Disposition
func isFileDownLoad(responseHeader http.Header) bool {
contentType := strings.ToLower(responseHeader.Get("Content-Type"))
if strings.Contains(contentType, "application/octet-stream") {
return true
}
contentDisposition := responseHeader.Get("Content-Disposition")
if contentDisposition != "" {
return true
}
return false
}
func isWebsocket(req *http.Request) bool {
conntype := strings.ToLower(req.Header.Get("Connection"))
upgrade := strings.ToLower(req.Header.Get("Upgrade"))
if conntype == "upgrade" && upgrade == "websocket" {
return true
}
return false
}
func ReadResponseBody(ctx *gin.Context) {
if isNoNeedToReadResponse(ctx.Request) {
return
}
rbw := &BodyDumpResponseWriter{body: &bytes.Buffer{}, ResponseWriter: ctx.Writer}
ctx.Writer = rbw
ctx.Next()
contentType := ctx.Writer.Header().Get("content-type")
if !strings.Contains(contentType, "application/json") {
return
}
rawResp := rbw.body.String()
if len(rawResp) == 0 {
AbnormalPrint(ctx, "resp-empty", rawResp)
return
}
ctx.Set(ctx_raw_response_body, rawResp)
// 序列化Body,并放到ctx中
// 读取响应Body的目的是记录审计日志用
}
// AbnormalPrint 异常情况,打印信息到日志
func AbnormalPrint(ctx *gin.Context, typ string, rawResp string) {
// 具体代码忽略
}
其实,写这篇文章的目的并不是为了阐述这个问题如何解决,而是想说:
- Copy 代码的时候留意下自己的场景
- 尽量用轮子,而不是自己去造轮子
在我们手写API网关的时候,还遇到过以下问题
- 第一版的网络处理也是手写的,导致对于各种Content-Type处理不好;
- 因为要解析Body,也没有精力去适配各种压缩协议,所以在网关这里会强制关闭压缩;
- 手写网络处理,会一些情况会出现一些诡异的问题
- 比如:我们支持页面终端连接到K8S集群,而这个终端连接走的是Websocket,假设支持该连接操作的服务是A(就是:页面< - - - - - - >服务A< - - - - - - >K8S集群),那么后面过网关的请求部分请求会直接请求到服务A上(此时根本没有走网关的API router,
直接就复用Websocket这个连接了),即使这些API不是服务A的。
- 比如:我们支持页面终端连接到K8S集群,而这个终端连接走的是Websocket,假设支持该连接操作的服务是A(就是:页面< - - - - - - >服务A< - - - - - - >K8S集群),那么后面过网关的请求部分请求会直接请求到服务A上(此时根本没有走网关的API router,
第一版手写网络请求处理的代码示意如下:
func proxyHttp(ctx context.Context, proxy_req *http.Request, domain string) {
// origin request
req := ctx.Request()
response, err := HttpClient.Do(proxy_req)
if err != nil {
// 打印异常
return
}
defer response.Body.Close()
//copy response header
if response != nil && response.Header != nil {
for k, values := range response.Header {
for _, value := range values {
ctx.ResponseWriter().Header().Set(k, value)
}
}
}
// status code
ctx.StatusCode(response.StatusCode)
buf := make([]byte, 1024)
for {
len, err := response.Body.Read(buf)
if err != nil && err != io.EOF {
// 打印异常
break
}
if len == 0 {
break
}
ctx.ResponseWriter().Write(buf[:len])
ctx.ResponseWriter().Flush()
continue
}
ctx.Next()
}
func proxyWebSocket(ctx context.Context, request *http.Request, target string) {
var logger = ctx.Application().Logger()
responseWriter := http.ResponseWriter(ctx.ResponseWriter())
conn, err := net.Dial("tcp", target)
if err != nil {
// 打印异常
return
}
hijacker, ok := responseWriter.(http.Hijacker)
if !ok {
http.Error(responseWriter, "Not a hijacker?", 500)
return
}
nc, _, err := hijacker.Hijack()
if err != nil {
// 打印异常
return
}
defer nc.Close()
defer conn.Close()
err = request.Write(conn)
if err != nil {
// 打印异常
return
}
errc := make(chan error, 2)
cp := func(dst io.Writer, src io.Reader) {
_, err := io.Copy(dst, src)
errc <- err
}
go cp(conn, nc)
go cp(nc, conn)
// wait over
<-errc
ctx.Application().Logger().Infof("websocket proxy to %s over", target)
}
后来换成了基础类库的httputil.ReverseProxy来处理网络连接,问题解决。