背景需求:
最近测试以前的多线程(同时下载5个视频),结果30个视频只下到了3个,于是把“单个下载(单线程下载)”的一个代码进行拓展研究。前一篇介绍了网址尾数递增的遍历程序,本篇介绍“网址中间字母不同,前面后面相同”的列表代码拼接方法。(PS:单线程下载非常非常慢。)
适用情况:
视频网址前面部分一样、后面部分一样,中间的一部分随机字母不一样
可能在一个视频列表内,只要点击列表就能找到网址,也可能要从视频主页上分别点开,才能找到网址
代码演示:
import sys
from you_get import common
'''
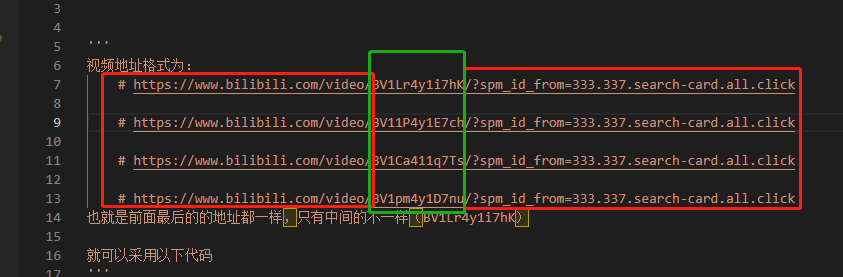
视频地址格式为:
# https://www.bilibili.com/video/BV1Lr4y1i7hK/?spm_id_from=333.337.search-card.all.click
# https://www.bilibili.com/video/BV11P4y1E7ch/?spm_id_from=333.337.search-card.all.click
# https://www.bilibili.com/video/BV1Ca411q7Ts/?spm_id_from=333.337.search-card.all.click
# https://www.bilibili.com/video/BV1pm4y1D7nu/?spm_id_from=333.337.search-card.all.click
也就是前面最后的的地址都一样,只有中间的不一样(BV1Lr4y1i7hK)
就可以采用以下代码
'''
address_1=input('前面部分的网址\n')
# 拷贝:“https://www.bilibili.com/video/)
address_2=input('后面部分的网址\n')
# 拷贝:“/?spm_id_from=333.337.search-card.all.click”
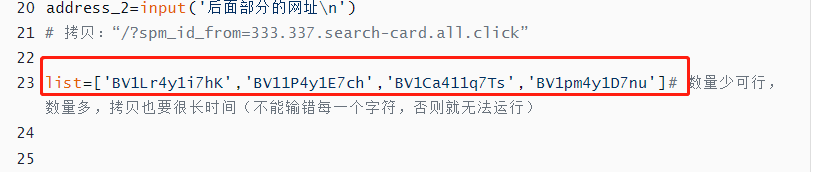
list=['BV1Lr4y1i7hK','BV11P4y1E7ch','BV1Ca411q7Ts','BV1pm4y1D7nu']# 数量少可行,数量多,拷贝也要很长时间(不能输错每一个字符,否则就无法运行)
# name=input(input('名称\n'))
# path = r'D:\test\' # 根据你的物理环境自行设定,不存在的话会自行创建这么一个文件夹
# # 如果savePath不存在,就新建这么一个目录
# if not os.path.exists(path):
# os.makedirs(path)
for i in range (0,int(len(list))): # 计算list的长度,一共有4个,遍历0,1,2,3
#提取信息
def get_i(url):
sys.argv=["you-get","-i",url]
common.main()
#基本下载
def get_o(url,pwd):
sys.argv=["you-get","-o",pwd,url]
common.main()
#指定格式下载
def get_type(url,pwd,type):
sys.argv=["you-get","-F",type,"-o",pwd,url]
common.main()
pwd="D:\\test"
type="dash-flv360"
url="{}{}{}".format(address_1,list[i],address_2) # 网址分成三段组合,list[i]提取list的每个数组
print(url)
get_o(url,pwd)
# 删除所有XML格式的文件
import glob,os
path =r'D:\test'
for infile in glob.glob(os.path.join(path, '*.xml')):
os.remove(infile)
print(infile+'已删除')
终端展示
输入前面和后面完全相同的部分

用过多线程下载,再看单线程实在是太慢了,但是能下载已经很不错了!
第一个拼接网址下载完成后,自动进入第二个拼接网址,继续下载
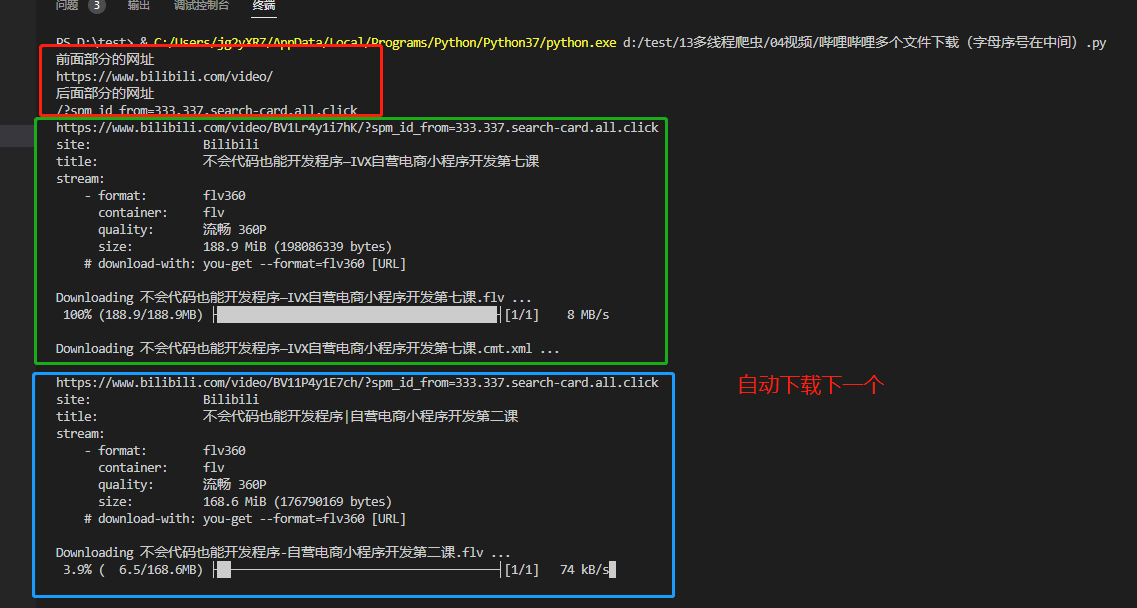
下载D:/test下
(13:59分截图)

全部下载完成后,删除xml格式文件
存在问题:
这种提取方法,视频数量不能多,否则光是复制列表里的随机字母串就很费时间。
其他思路方案:
1 把所有需要的网址都贴到代码里.两头加'' 做成list ——list=['全网址1’,'全网址2’]
2.如何批量提取网址
3.把所有需要的网址都贴到代码里,尝试提取第25-37个数字?

![数据结构与算法之[把数字翻译成字符串]动态规划](https://img-blog.csdnimg.cn/img_convert/619808a6dc64103a387a206898673c98.png)