离线数仓-6-数据仓库开发ODS层设计要点
- 离线数仓-6-数据仓库开发ODS层
- 1.数据仓库开发ODS层设计要点
- 2.ODS层用户行为日志表
- 1.hive中复杂结构体复习
- 1.array
- 2.map
- 3.struct 复杂结构
- 4.嵌套格式
- 2.hive中针对复杂结构字符串的练习
- 1.针对ods层为json格式数据的练习
- 2.用户行为日志表的设计
- 用户行为日志表结构设计如下:
- 3.业务表的设计-全量&增量
离线数仓-6-数据仓库开发ODS层
1.数据仓库开发ODS层设计要点
ODS层的设计要点如下:
(1)ODS层的表结构设计依托于从业务系统同步过来的数据结构。
(2)ODS层要保存全部历史数据,故其压缩格式应选择压缩比较高的,此处选择gzip。
(3)ODS层表名的命名规范为:ods_表名_单分区增量全量标识(inc/full)。
2.ODS层用户行为日志表
- 一个字符串需要执行反序列操作,才能转化成一个对象。
- hive创建DDL的官网:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
1.hive中复杂结构体复习
- 官网配置如下:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-ComplexTypeConstructors
1.array
- 1.定义:
array<string> - 2.取值:arr[0]
- 3.构造:array(val1,val2,val3,…),split(),collect_set()
2.map
- 1.定义:map<string,bigint>
- 2.取值:map[key]
- 3.构造:map(key1,value1,key2,value2,…),str_to_map(text[,delimiter1,delimiter2])
3.struct 复杂结构
- 1.定义:
struct<id:int,name:string> - 2.取值:struct.id
- 3.构造:named_struct(name1,val1,name2,val2,…)
4.嵌套格式
- 1.定义:
array<struct<id:int,name:string>> - 2.取值:
- 3.构造:
2.hive中针对复杂结构字符串的练习
1.针对ods层为json格式数据的练习
--一、测试一,简单json对应的数据表格创建
--1.同步json本地数据到hive中,数据样例:{"id":1001,"name":"zhangsan"}
CREATE TABLE person(id int, name string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
location '/person';
-- 2.load数据:hive本地执行:load data local inpath '/data/person' overwrite into table person;
-- 3.查看数据:
select * from person;
-- 二、测试二,复杂结构json对应的数据表格创建,以及如何获取里面数据
-- 1.确定数据样例:{"id":1001,"name":"zhangsan","hobby":["reading","coding","smoking"],"address":{"country":"China","city":"Shandong"}}
-- 2.创建对应表格
DROP table if exists person;
CREATE TABLE person(
id int,
name string,
hobby Array<string>,
address struct<country:string,city:string>)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
location '/person';
show tables;
-- 3.load数据:hive本地执行:load data local inpath '/data/person' overwrite into table person;
-- 4.查询数据
SELECT * from person;
-- 4.1 查询array数组类型里面的数据
SELECT hobby[0] as hobby0,hobby[1] as hobby1,hobby[2] as hobby2 from person;
-- 4.2 查询 struct类型里面的数据
SELECT address.country as country, address.city as city from person;
2.用户行为日志表的设计
- 用户日志行为表分为两种:启动日志和用户行为日志,在设计用户日志行为表时,需要兼顾这两种格式的数据,要做到一张表融合所有的类型数据的字段,所以在设计用户行为日志表的时候,需要将以下7个字段都整合到一个表中,才能满足业务需求。
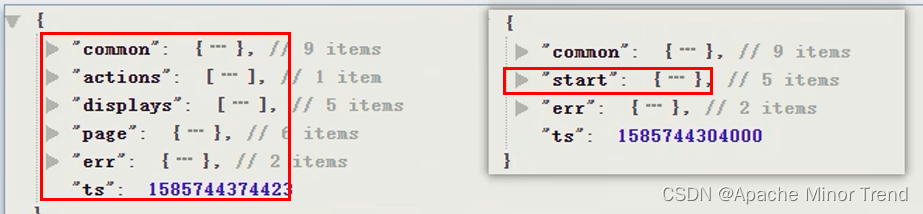
- hive中表结构的思考:行、列、分区。
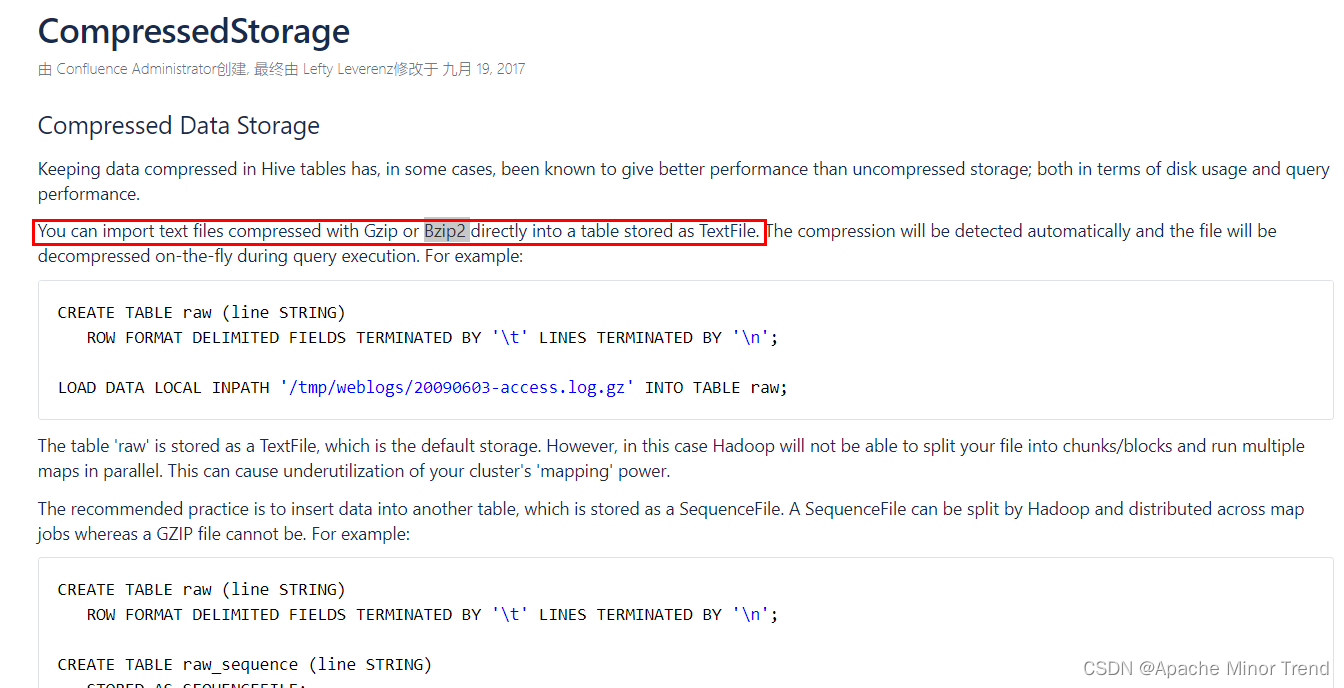
- 外部数据如果是 Gzip或者Bzip2 格式的数据,在建hive表的时候,可以不声明文本类型,hive官网介绍如下:https://cwiki.apache.org/confluence/display/Hive/CompressedStorage
用户行为日志表结构设计如下:
- 1.日志行为表结构如下:
DROP TABLE IF EXISTS ods_log_inc;
CREATE EXTERNAL TABLE ods_log_inc
(
`common` STRUCT<ar :STRING,ba :STRING,ch :STRING,is_new :STRING,md :STRING,mid :STRING,os :STRING,uid :STRING,vc
:STRING> COMMENT '公共信息',
`page` STRUCT<during_time :STRING,item :STRING,item_type :STRING,last_page_id :STRING,page_id
:STRING,source_type :STRING> COMMENT '页面信息',
`actions` ARRAY<STRUCT<action_id:STRING,item:STRING,item_type:STRING,ts:BIGINT>> COMMENT '动作信息',
`displays` ARRAY<STRUCT<display_type :STRING,item :STRING,item_type :STRING,`order` :STRING,pos_id
:STRING>> COMMENT '曝光信息',
`start` STRUCT<entry :STRING,loading_time :BIGINT,open_ad_id :BIGINT,open_ad_ms :BIGINT,open_ad_skip_ms
:BIGINT> COMMENT '启动信息',
`err` STRUCT<error_code:BIGINT,msg:STRING> COMMENT '错误信息',
`ts` BIGINT COMMENT '时间戳'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_log_inc/';
- 2.load数据到Hive表,脚本设计,脚本命名规范:数据源_to_目的地.sh hdfs_to_ods_log.sh
- hive中执行load语句的时候,数据还是存储在hdfs的DataNode上,没有移动,实际上修改的是:hdfs中NameNode的元数据到真实文件路径的映射关系,没有真正的移动数据,load操作没有性能开销。
load data inpath '/origin_data/gmall/log/topic_log/2020-06-14' into table ods_log_inc partition(dt='2020-06-14');
- hive中执行load语句的时候,数据还是存储在hdfs的DataNode上,没有移动,实际上修改的是:hdfs中NameNode的元数据到真实文件路径的映射关系,没有真正的移动数据,load操作没有性能开销。
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo ================== 日志日期为 $do_date ==================
sql="
load data inpath '/origin_data/$APP/log/topic_log/$do_date' into table ${APP}.ods_log_inc partition(dt='$do_date');
"
hive -e "$sql"
3.业务表的设计-全量&增量
-
全量表(通过DataX上传到HDFS,\t分割的text文本)结构设计
- 1.分隔符,全量表字段都跟原来的保持一致,但是分割符要跟全量同步工具DataX的writer工具中的分隔符保持一致即可。
- 2.空值的处理,DataX中,将空值存为了’ ‘空串,所以在创建hive表的时候,需要指定一下空值使用’ '空串来代替。
NULL DEFINED AS ' '
-
增量表(通过Maxwell上传到HDFS,json文件)结构设计
- 确定原始数据中,哪些字段需要保留
-
1.创建表格
-
2.书写同步数据脚本
#!/bin/bash
APP=gmall
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d '-1 day' +%F` # linux上输入 date --help 可以查看帮助命令,获取前一天的日期,并按照标准格式输出。
fi
load_data(){
sql=""
for i in $*; do
#判断路径是否存在
hadoop fs -test -e /origin_data/$APP/db/${i:4}/$do_date # 1.-test -e 判断路径是否存在,存在 echo $?返回0,否则返回1 2.i:4 字符串的分割,获取第五个字符及以后的字符串
#路径存在方可装载数据
if [[ $? = 0 ]]; then
sql=$sql"load data inpath '/origin_data/$APP/db/${i:4}/$do_date' OVERWRITE into table ${APP}.$i partition(dt='$do_date');"
fi
done
hive -e "$sql"
}
case $1 in
"ods_activity_info_full")
load_data "ods_activity_info_full"
;;
"ods_activity_rule_full")
load_data "ods_activity_rule_full"
;;
"ods_base_category1_full")
load_data "ods_base_category1_full"
;;
"ods_base_category2_full")
load_data "ods_base_category2_full"
;;
"ods_base_category3_full")
load_data "ods_base_category3_full"
;;
"ods_base_dic_full")
load_data "ods_base_dic_full"
;;
"ods_base_province_full")
load_data "ods_base_province_full"
;;
"ods_base_region_full")
load_data "ods_base_region_full"
;;
"ods_base_trademark_full")
load_data "ods_base_trademark_full"
;;
"ods_cart_info_full")
load_data "ods_cart_info_full"
;;
"ods_coupon_info_full")
load_data "ods_coupon_info_full"
;;
"ods_sku_attr_value_full")
load_data "ods_sku_attr_value_full"
;;
"ods_sku_info_full")
load_data "ods_sku_info_full"
;;
"ods_sku_sale_attr_value_full")
load_data "ods_sku_sale_attr_value_full"
;;
"ods_spu_info_full")
load_data "ods_spu_info_full"
;;
"ods_cart_info_inc")
load_data "ods_cart_info_inc"
;;
"ods_comment_info_inc")
load_data "ods_comment_info_inc"
;;
"ods_coupon_use_inc")
load_data "ods_coupon_use_inc"
;;
"ods_favor_info_inc")
load_data "ods_favor_info_inc"
;;
"ods_order_detail_inc")
load_data "ods_order_detail_inc"
;;
"ods_order_detail_activity_inc")
load_data "ods_order_detail_activity_inc"
;;
"ods_order_detail_coupon_inc")
load_data "ods_order_detail_coupon_inc"
;;
"ods_order_info_inc")
load_data "ods_order_info_inc"
;;
"ods_order_refund_info_inc")
load_data "ods_order_refund_info_inc"
;;
"ods_order_status_log_inc")
load_data "ods_order_status_log_inc"
;;
"ods_payment_info_inc")
load_data "ods_payment_info_inc"
;;
"ods_refund_payment_inc")
load_data "ods_refund_payment_inc"
;;
"ods_user_info_inc")
load_data "ods_user_info_inc"
;;
"all")
load_data "ods_activity_info_full" "ods_activity_rule_full" "ods_base_category1_full" "ods_base_category2_full" "ods_base_category3_full" "ods_base_dic_full" "ods_base_province_full" "ods_base_region_full" "ods_base_trademark_full" "ods_cart_info_full" "ods_coupon_info_full" "ods_sku_attr_value_full" "ods_sku_info_full" "ods_sku_sale_attr_value_full" "ods_spu_info_full" "ods_cart_info_inc" "ods_comment_info_inc" "ods_coupon_use_inc" "ods_favor_info_inc" "ods_order_detail_inc" "ods_order_detail_activity_inc" "ods_order_detail_coupon_inc" "ods_order_info_inc" "ods_order_refund_info_inc" "ods_order_status_log_inc" "ods_payment_info_inc" "ods_refund_payment_inc" "ods_user_info_inc"
;;
esac





![[译文] 基于PostGIS3.1 生成格网数据](https://img-blog.csdnimg.cn/img_convert/ecb0588f8dc76232158bc16d14b0dff6.png)