目录
主从复制
一, 主从复制原理
二,主从复制配置
1,一主双从
1、配置三个redis示例
2、配置主从
3、集群测试
2, 主从切换
哨兵模式
一, 什么是哨兵模式
二, 配置哨兵
三,启动哨兵
四,验证哨兵
五, 复制延时
六, 选举策略
主从复制
随着项目访问量的增加,对Redis服务器的操作也越加频繁,虽然Redis读写速度都很快,但是一定程度上也会造成一定的延时,那么为了解决访问量大的问题,通常会采取的一种方式是主从架构Master/Slave,Master 以写为主,Slave 以读为主。
一, 主从复制原理
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
Redis 一般是使用一个 Master 节点来进行写操作,而若干个 Slave 节点进行读操作,Master 和 Slave 分别代表了一个个不同的 Redis Server 实例。
另外定期的数据备份操作也是单独选择一个 Slave 去完成,这样可以最大程度发挥 Redis 的性能。
另外,Master 和 Slave 的数据不是一定要即时同步的,但是在一段时间后 Master 和 Slave 的数据是趋于同步的,这就是最终一致性。
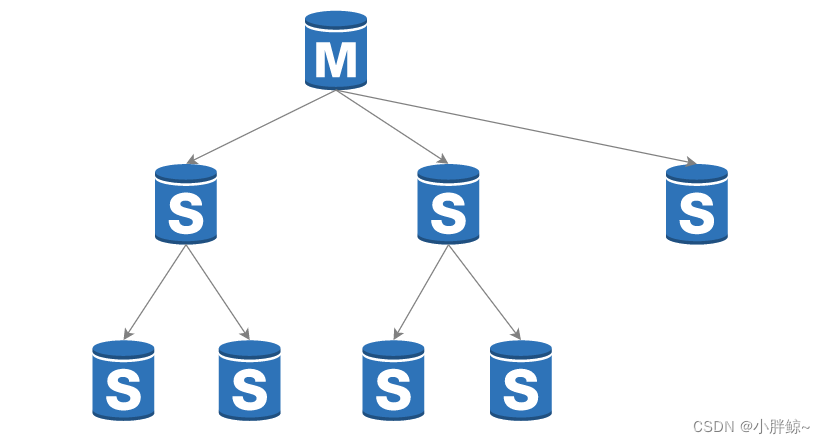
全量同步过程如下:
- Slave 发送 Sync 命令到 Master。
- Master 启动一个后台进程,将 Redis 中的数据快照保存到文件中。
- Master 将保存数据快照期间接收到的写命令缓存起来。
- Master 完成写文件操作后,将该文件发送给 Slave。
- slave使用新的 RDB 或 AOF 文件替换掉旧的 RDB 或 AOF 文件。
增量同步过程如下:
主从服务器在完成第一次同步后,主从节点进入命令传播阶段;在这个阶段主节点将自己执行的写命令发送给从节点,从节点接收命令并执行,从而保证主从节点数据的一致性。如果主从服务器间的网络连接断开了,那么就无法进行命令传播了,这时从服务器的数据就没办法和主服务器保持一致了,客户端就可能从「从服务器」读到旧的数据。
增量同步就是用于网络中断等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效。需要注意的是,如果网络中断时间过长,导致主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制。增量同步的实现,依赖于以下三个重要的概念:
(1)复制偏移量:主节点和从节点分别维护一个复制偏移量(offset),代表的是主节点向从节点传递的字节数;主节点每次向从节点传播N个字节数据时,主节点的offset增加N;从节点每次收到主节点传来的N个字节数据时,从节点的offset增加N。offset用于判断主从节点的数据库状态是否一致:如果二者offset相同,则一致;如果offset不同,则不一致,此时可以根据两个offset找出从节点缺少的那部分数据。
(2)复制积压缓冲区:复制积压缓冲区是由主节点维护的、固定长度的、先进先出(FIFO)队列,默认大小1MB;当主节点开始有从节点时创建,其作用是备份主节点最近发送给从节点的数据。注意,无论主节点有一个还是多个从节点,都只需要一个复制积压缓冲区。
在命令传播阶段,主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(offset)。由于复制积压缓冲区定长且是先进先出,所以它保存的是主节点最近执行的写命令;时间较早的写命令会被挤出缓冲区。
由于该缓冲区长度固定且有限,因此可以备份的写命令也有限,当主从节点offset的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。反过来说,为了提高网络中断时部分复制执行的概率,可以根据需要增大复制积压缓冲区的大小(通过配置repl-backlog-size);例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。
从节点将offset发送给主节点后,主节点根据offset和缓冲区大小决定能否执行部分复制:如果offset偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制;如果offset偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制。
(3)服务器运行ID(runid)
每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;runid用来唯一识别一个Redis节点。通过info Server命令,可以查看节点的runid:
主从节点初次复制时,主节点将自己的runid发送给从节点,从节点将这个runid保存起来;当断线重连时,从节点会将这个runid发送给主节点;主节点根据runid判断能否进行部分复制:
如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况);
如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。
二,主从复制配置
下面我们来搭建一主双从的 Redis 集群。
1,一主双从
准备三台虚拟机,配置好主机名、IP地址和Redis环境。本教程中为了演示方便,在一台虚拟机中配置三个Redis实例。
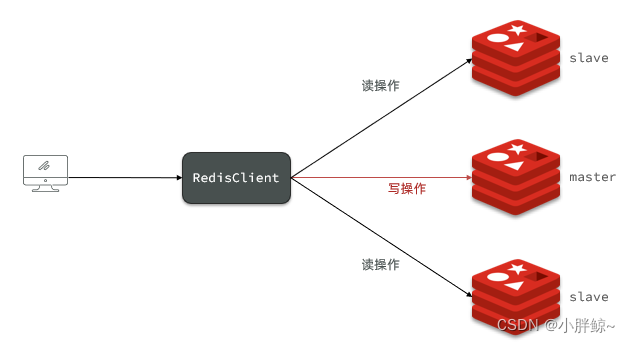
可以通过修改端口号在一台虚拟机上启动三个相同的服务
1、配置三个redis示例
(1)创建实例的配置文件所在目录
[root@localhost ~]# mkdir /rediscluster
[root@localhost ~]# cd /rediscluster
(2)查看是否有正在运行的redis进程,如果有则停掉
[root@localhost rediscluster]# ps -ef | grep redis
(3)停止正在运行的redis服务
(1)方法一:
[root@localhost rediscluster]# systemctl stop redis
(2)方法二:
[root@localhost rediscluster]# redis-cli shutdown
(3)方法三:
[root@localhost rediscluster]# redis-cli
127.0.0.1:6379> shutdown
(4)把配置文件复制到创建的目录下面
[root@localhost rediscluster]# cp -a /etc/redis/redis.conf /rediscluster/redis.conf
(5)为了演示方便,暂时关闭AOF持久化,并开启以后台守护进行的方式运行,把 redis.conf 中的 appendonly no;daemonize yes。
使用命令vim redis.conf打开文件进行修改



(6)查看是否修改成功
[root@localhost rediscluster]# grep -E '^(append|daemon)' redis.conf
创建三个实例的配置文件redis-6379.conf、redis-6380.conf 和 redis-6381.conf
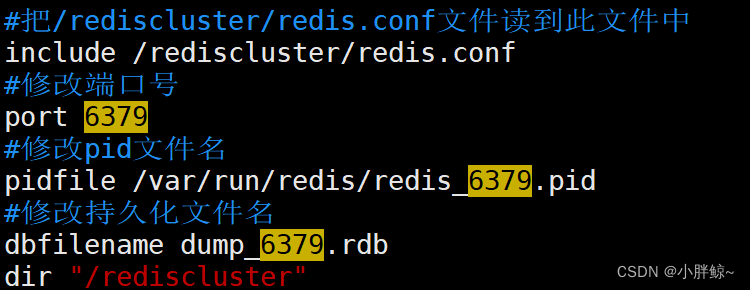
(1)创建实例redis-6379.conf的配置文件文件
1,打开文件redis-6379.conf
[root@localhost rediscluster]# vim redis-6379.conf
2,对redis-6379.cond的配置文件进行以下编辑
#把/rediscluster/redis.conf文件读到此文件中
include /rediscluster/redis.conf
#修改端口号
port 6379
#修改pid文件名
pidfile /var/run/redis/redis_6379.pid
#修改持久化文件名
dbfilename dump_6379.rdb
dir "/rediscluster"
(2)创建实例redis-6380.conf的配置文件文件
1,打开文件redis-6380.conf
[root@localhost rediscluster]# vim redis-6380.conf
2,对redis-6380.conf的配置文件进行以下编辑
#把/rediscluster/redis.conf文件读到此文件中
include /rediscluster/redis.conf
#修改端口号
port 6380
#修改pid文件名
pidfile /var/run/redis/redis_6380.pid
#修改持久化文件名
dbfilename dump_6380.rdb
dir "/rediscluster"

(3)创建实例redis-6381.conf的配置文件文件
1,打开文件redis-6381.conf
[root@localhost rediscluster]# vim redis-6381.conf
2,对redis-6381.con的配置文件进行以下编辑
#把/rediscluster/redis.conf文件读到此文件中
include /rediscluster/redis.conf
#修改端口号
port 6381
#修改pid文件名
pidfile /var/run/redis/redis_6381.pid
#修改持久化文件名
dbfilename dump_6381.rdb
dir "/rediscluster"

(4)查看当前没有reids进程,发现并没有redis进程
[root@localhost rediscluster]# ss -lntup | grep redis
启动服务后面要加配置文件
(1)启动6379服务
[root@localhost rediscluster]# redis-server redis-6379.conf
[root@localhost rediscluster]# ss -lntup | grep redis
(2)启动6380服务
[root@localhost rediscluster]# redis-server redis-6380.conf
[root@localhost rediscluster]# ss -lntup | grep redis
(3)启动6381服务
[root@localhost rediscluster]# redis-server redis-6381.conf
[root@mysql8-0-30 rediscluster]# ps -ef | grep redis
连接服务,访问3个不同的redis
(1)连接6379服务
[root@localhost rediscluster]# redis-cli -p 6379
127.0.0.1:6379> ping
(2)连接6381服务
[root@localhost rediscluster]# redis-cli -p 6380
127.0.0.1:6380> ping
PONG
(2)连接6381服务
[root@localhost rediscluster]# redis-cli -p 6381
127.0.0.1:6381> ping
(3)此时rediscluster目录下面有以下文件
客户端连接上后,查看每个实例上的信息
(1)查看6379的信息
[root@localhost rediscluster]# redis-cli -p 6379127.0.0.1:6379> info replication
# Replication
role:master (角色为主)
connected_slaves:0 (连接到的从为0个)
master_failover_state:no-failover
master_replid:a5aee73c3795529656197f7b69c0bb2fc5969ffb (id号)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0 (主偏移量)
second_repl_offset:-1 (从偏移量)
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
(2)查看6380的信息
[root@localhost rediscluster]# redis-cli -p 6380127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:57295c9b494fe8db48dab0dd104e08fe068ccbf6
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0

(3)查看6381的信息
[root@localhost rediscluster]# redis-cli -p 6381127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:82ceb9b016a932ab8f781bcf10f2428e95c35ccf
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6381>
从输出信息可以发现,这三台都是 master,也就是都是主服务器
2、配置主从
假设我们希望 6379 是主服务器,而 6380 和 6381 是从服务器,则需要在从主机上做如下配置。
命令格式:slaveof <主ip> <主port>
(1) 把主机6380配置为从主机
[root@localhost rediscluster]# redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
(2) 把主机6381配置为从主机
[root@localhost rediscluster]# redis-cli -p 6381
127.0.0.1:6381> slaveof 127.0.0.1 6379
OK
注意:
- 在 redis-cli 客户端中执行 slaveof 命令只会对当前环境生效,重启后失效。要想永久生效,需要在 redis.conf 配置文件中添加 slaveof <masterip> <masterport> 配置。
- 在 Redis 5.0 后,新增了 replicaof 命令,作用与 slaveof 命令效果一致。
(3)此时再次查看6379的信息,可以发现已经变为了主机了。
127.0.0.1:6379> info replication# Replication
role:master (角色为主)
connected_slaves:2 (有2个从)
slave0:ip=127.0.0.1,port=6380,state=online,offset=266,lag=1 (从的信息)
slave1:ip=127.0.0.1,port=6381,state=online,offset=266,lag=1
master_failover_state:no-failover
master_replid:ba3c83719438dc7db87859c4140eeb0881fb07e5 (id号)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:266
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:266

(4)此时再次查看6380的信息,可以发现已经变为了从机了。
127.0.0.1:6380> info replication# Replication
role:slave (角色为从)
master_host:127.0.0.1 (主Ip)
master_port:6379 (主端口号)
master_link_status:up
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_read_repl_offset:224
slave_repl_offset:224
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:ba3c83719438dc7db87859c4140eeb0881fb07e5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:224
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:224
(5)此时再次查看6380的信息,可以发现已经变为了从机了。
127.0.0.1:6381> info replication# Replication
role:slave (角色为从)
master_host:127.0.0.1 (主Ip)
master_port:6379 (主端口号)
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_read_repl_offset:168
slave_repl_offset:168
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:ba3c83719438dc7db87859c4140eeb0881fb07e5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:168
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:57
repl_backlog_histlen:112
3、集群测试
(1)添加数据,进行测试
1,在主6379上添加数据
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
2,查看6380上面发现数据已经同步了
[root@localhost rediscluster]# redis-cli -p 6380
127.0.0.1:6380> get k1
"v1"
127.0.0.1:6380> get k2
"v2"
3,查看6381上面发现数据已经同步了
[root@localhost rediscluster]# redis-cli -p 6381
127.0.0.1:6381> get k1
"v1"
127.0.0.1:6381> get k2
"v2"
4,如果我们在从服务器中添加数据,则会报错。因为从服务器只能读。
127.0.0.1:6381> set k3 v3
(error) READONLY You can't write against a read only replica.
,
5,会生成对应的rdb文件,如下所示
(2)如果其中一台主机宕机
1,如果主6379宕机
[root@localhost rediscluster]# redis-cli -p 6379 shutdown
[root@localhost rediscluster]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=2434,fd=6))
tcp LISTEN 0 511 0.0.0.0:6381 0.0.0.0:* users:(("redis-server",pid=2442,fd=6))
(1)从6380依旧能获取到,主宕机不影响从的读,但是从永远不能写
从机6380可以读取数据
[root@localhost rediscluster]# redis-cli -p 6380
127.0.0.1:6380> get k1
"v1"
127.0.0.1:6380> get k2
"v2"
从机6380不能写数据
127.0.0.1:6380> set k3 v3
(error) READONLY You can't write against a read only replica
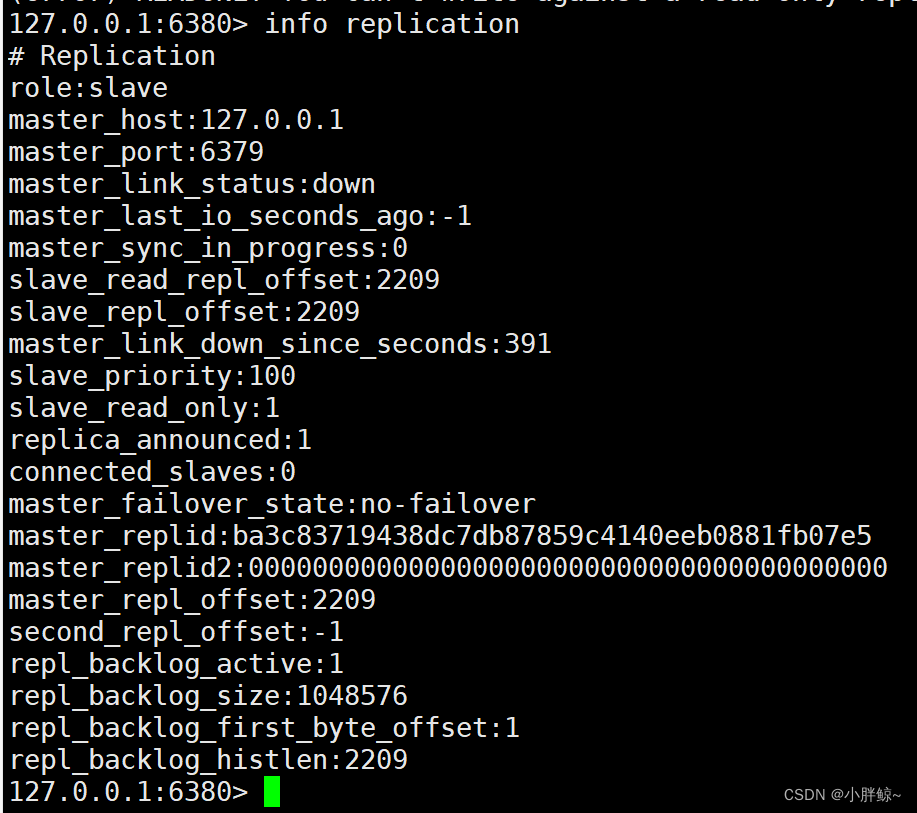
(2)此时,从6380 的详细信息如下所示
127.0.0.1:6380> info replication# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:2209
slave_repl_offset:2209
master_link_down_since_seconds:391
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:ba3c83719438dc7db87859c4140eeb0881fb07e5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2209
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:2209
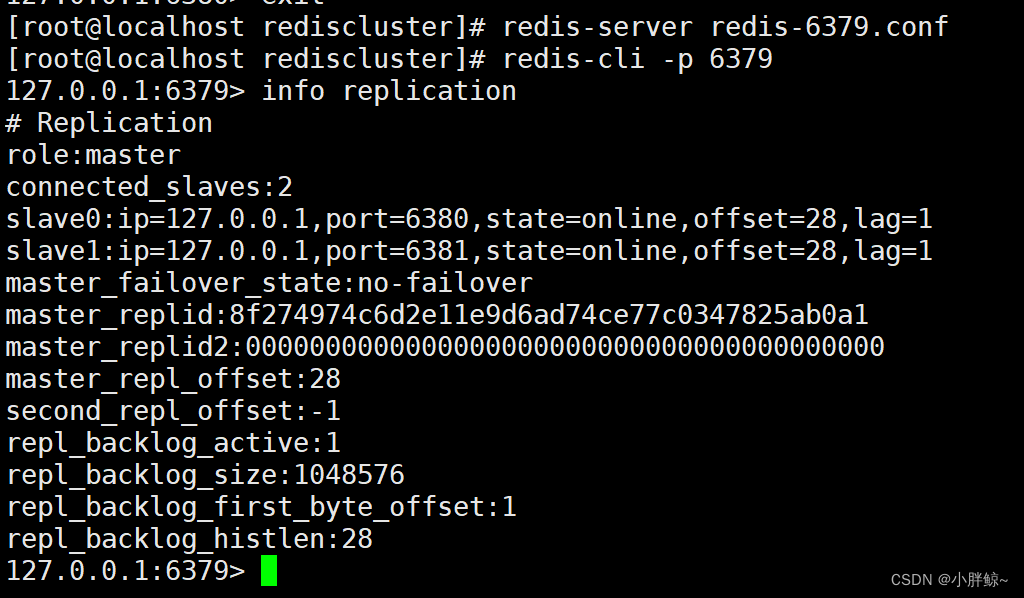
(3)重新启动主6379依旧为主,重启后6379的详细信息如下所示
[root@localhost rediscluster]# redis-server redis-6379.conf
[root@localhost rediscluster]# redis-cli -p 6379
127.0.0.1:6379> info replication# Replication
role:master (依旧为主)
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=28,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=28,lag=1
master_failover_state:no-failover
master_replid:8f274974c6d2e11e9d6ad74ce77c0347825ab0a1 (id号改变)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:28
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:28
(4)重启后6380的详细信息如下所示
[root@localhost rediscluster]# redis-cli -p 6380
127.0.0.1:6380> info replication# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_read_repl_offset:224
slave_repl_offset:224
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8f274974c6d2e11e9d6ad74ce77c0347825ab0a1 (id号与重启后的主id相同)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:224
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:224

(5)重启后6381的详细信息如下所示
[root@localhost rediscluster]# redis-cli -p 6381
127.0.0.1:6381> info replication# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:9
master_sync_in_progress:0
slave_read_repl_offset:378
slave_repl_offset:378
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8f274974c6d2e11e9d6ad74ce77c0347825ab0a1 (id号与重启后的主id相同)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:378
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:378

2、如果从6380宕机了,重启后会变为主服务器,需要重新执行 `slaveof <ip> <port>`命令。
(1)从6380宕机后,查看主6379的详细信息如下:
[root@localhost rediscluster]# redis-cli -p 6380 shutdown
[root@localhost rediscluster]# redis-cli -p 6379
127.0.0.1:6379> info replication# Replication
role:master
connected_slaves:1 (从只有6380一个)
slave0:ip=127.0.0.1,port=6381,state=online,offset=602,lag=1
master_failover_state:no-failover
master_replid:8f274974c6d2e11e9d6ad74ce77c0347825ab0a1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:602
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:602

(2)重启从6380服务,并查看6380的详细信息,发现从6380服务变为主6380服务
[root@localhost rediscluster]# redis-server redis-6380.conf
[root@localhost rediscluster]# redis-cli -p 6380
127.0.0.1:6380> info replication
# Replication
role:master (从变为主)
connected_slaves:0
master_failover_state:no-failover
master_replid:0eae3222154ca00bef75b2222845184d926bafad (id与主6379服务不同)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
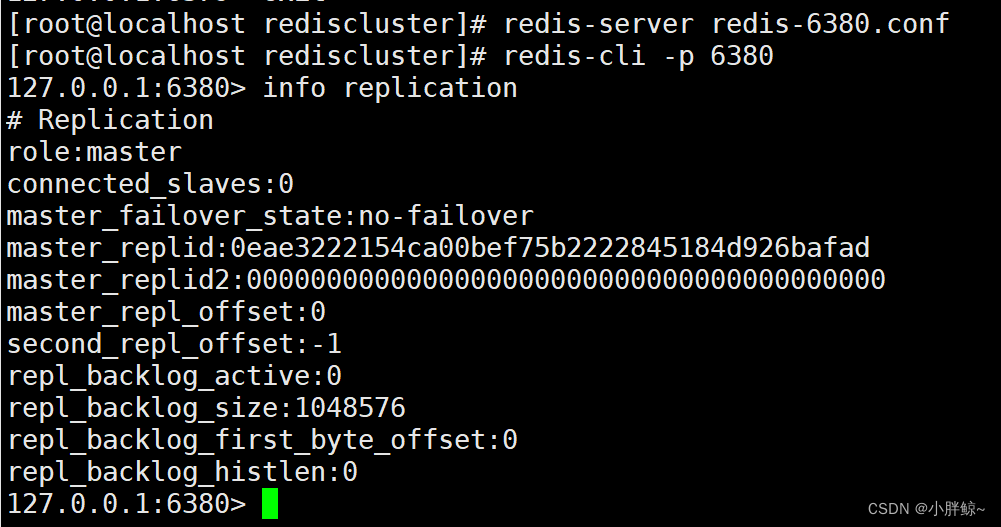
(3)重新把6380服务配置为从6380服务,主id自动变为6379的id,数据依旧在
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
127.0.0.1:6380> info replication# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_read_repl_offset:1232
slave_repl_offset:1232
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8f274974c6d2e11e9d6ad74ce77c0347825ab0a1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1232
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1233
repl_backlog_histlen:0

2, 主从切换
当一个 master 宕机后,后面的 slave 可以立刻升为 master,其后面的 slave 不用做任何修改。
用 slaveof no one 将从机变为主机。
(1)主机6379宕机
[root@localhost rediscluster]# redis-cli -p 6379 shutdown
[root@localhost rediscluster]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=2529,fd=6))
tcp LISTEN 0 511 0.0.0.0:6381 0.0.0.0:* users:(("redis-server",pid=2442,fd=6))
(2)从机6380的信息如下所示
127.0.0.1:6380> info replication# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:2086
slave_repl_offset:2086
master_link_down_since_seconds:112
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8f274974c6d2e11e9d6ad74ce77c0347825ab0a1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2086
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1233
repl_backlog_histlen:854

(3)将从6380升为主6380服务
127.0.0.1:6380> slaveof no one
OK
127.0.0.1:6380> info replication# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:83f664284d50f831644598b798505909cba39f4a
master_replid2:8f274974c6d2e11e9d6ad74ce77c0347825ab0a1
master_repl_offset:2086
second_repl_offset:2087
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1233
repl_backlog_histlen:854
127.0.0.1:6380> get k1
"v1"
127.0.0.1:6380> get k2
"v2"

(4)主6380可以写入数据
[root@localhost rediscluster]# redis-cli -p 6380
127.0.0.1:6380> set k3 v3
OK
127.0.0.1:6380> set k4 v4
OK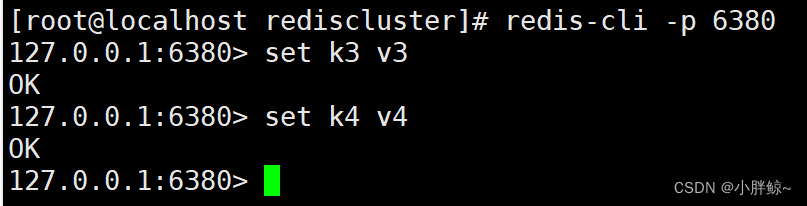
(5)从6381的信息没有任何改变,依旧认为自己是从,主为6379
[root@localhost rediscluster]# redis-cli -p 6381
127.0.0.1:6381> info replication# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:2086
slave_repl_offset:2086
master_link_down_since_seconds:308
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8f274974c6d2e11e9d6ad74ce77c0347825ab0a1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2086
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:208
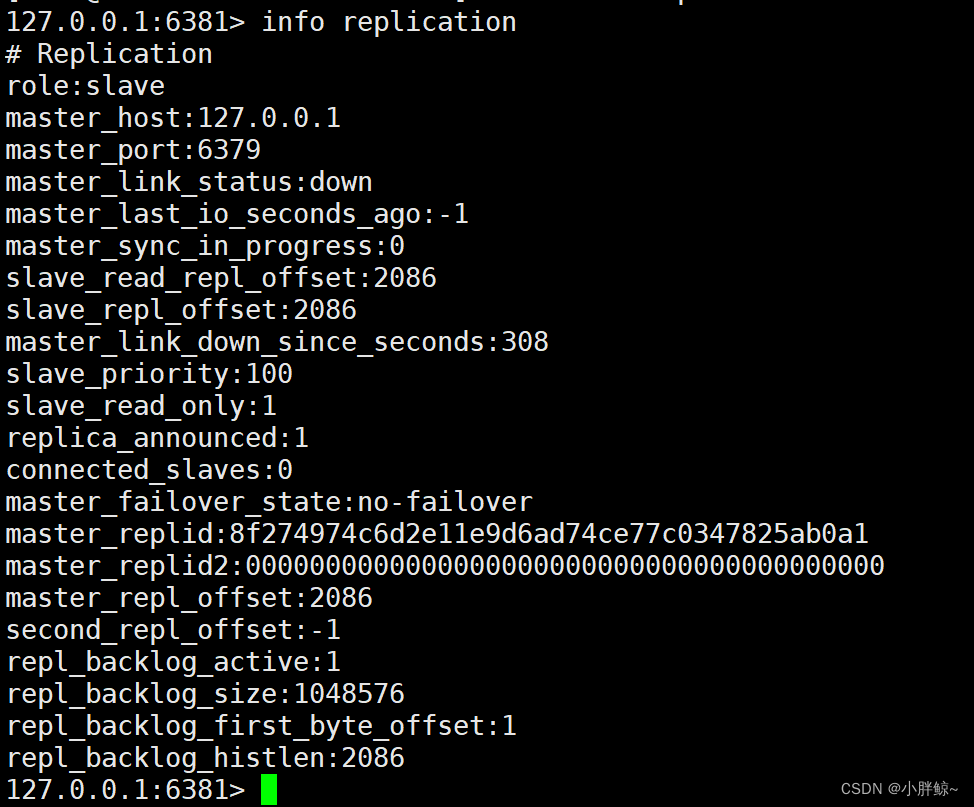
(6)将从6381的主从原来的6379修改为6380,主id既有6380id也有6381id
127.0.0.1:6381> slaveof 127.0.0.1 6380
OK
127.0.0.1:6381> info replication# Replication
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_read_repl_offset:2086
slave_repl_offset:2086
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:83f664284d50f831644598b798505909cba39f4a
master_replid2:8f274974c6d2e11e9d6ad74ce77c0347825ab0a1
master_repl_offset:2086
second_repl_offset:2087
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:2086
127.0.0.1:6381>

(7)之前主6379的信息仍旧存在
127.0.0.1:6381> get k1
"v1"
127.0.0.1:6381> get k2
"v2"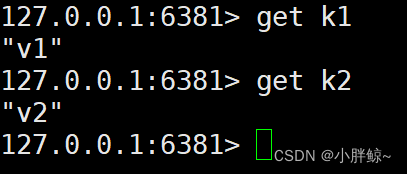
(8)从6381也可以读取新主6380创建的数据
[root@localhost rediscluster]# redis-cli -p 6381
127.0.0.1:6381> get k3
"v3"
127.0.0.1:6381> get k4
"v4"
哨兵模式
一, 什么是哨兵模式
哨兵也叫 sentinel,它的作用是能够在后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。

二, 配置哨兵
1,首先停止三台 Redis 服务
[root@localhost rediscluster]# redis-cli -p 6380 shutdown
[root@localhost rediscluster]# redis-cli -p 6381 shutdown
[root@localhost rediscluster]# redis-cli -p 6379 shutdown
[root@localhost rediscluster]# ss -lntup | grep redis
2,然后再重新启动三台 Redis 服务器,并实现一主双从
(1)主6039服务器的详细信息
[root@localhost rediscluster]# redis-cli -p 6379
127.0.0.1:6379> info replication# Replication
role:master (角色为主)
connected_slaves:2 (有两个从)
slave0:ip=127.0.0.1,port=6380,state=online,offset=322,lag=1 (从的信息)
slave1:ip=127.0.0.1,port=6381,state=online,offset=322,lag=0
master_failover_state:no-failover
master_replid:6a7e8e2adfcc24edc92e2bc9a325fe8192789599 (主id)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:322
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:322
(2)从6380服务器的配置以及详细信息
[root@localhost rediscluster]# redis-server redis-6380.conf
[root@localhost rediscluster]# redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
127.0.0.1:6380> info replication# Replication
role:slave (角色为从)
master_host:127.0.0.1
master_port:6379 (主端口)
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_read_repl_offset:14
slave_repl_offset:14
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:6a7e8e2adfcc24edc92e2bc9a325fe8192789599 (主id)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14

(3)从6381服务器的配置以及详细信息
[root@localhost rediscluster]# redis-server redis-6381.conf
[root@localhost rediscluster]# redis-cli -p 6381
127.0.0.1:6381> slaveof 127.0.0.1 6379
OK
127.0.0.1:6381> info replication# Replication
role:slave (角色为从)
master_host:127.0.0.1
master_port:6379 (主端口号)
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_read_repl_offset:224
slave_repl_offset:224
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:6a7e8e2adfcc24edc92e2bc9a325fe8192789599 (主id)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:224
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:211
repl_backlog_histlen:14
(4)最后在 /rediscluster 目录下新建 sentinel.conf 文件,文件名称不能写错,必须叫这个名称。
[root@localhost rediscluster]# vim sentinel.conf
内容如下:
sentinel monitor redismaster 127.0.0.1 6379 1

参数说明:
- monitor:监控
- redismaster:为监控对象起的服务名称
- 1:法定数量,代表只有1个或1个以上的哨兵认为主节点不可用的时候,才会把 master 设置为客观下线状态,然后进行 failover 操作。
三,启动哨兵
(1)执行如下命令来启动哨兵:
[root@localhost rediscluster]# redis-sentinel sentinel.conf
四,验证哨兵
(1)我们在另一个端口把主服务器停止:
[root@localhost rediscluster]# redis-cli -p 6379 shutdown
(2)这时,哨兵就会介入,并进行选举,然后把选举成功的从面切换为主机。

(3)此时查看从6380服务器的详细信息,发现6380被选举为主
[root@localhost rediscluster]# redis-cli -p 6380
127.0.0.1:6380> info replication# Replication
role:master (角色为主)
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=27020,lag=0 (从6381的信息)
master_failover_state:no-failover
master_replid:e5522f539a742719f3d3b960412c9e07bf520a57 (主6380id)
master_replid2:6a7e8e2adfcc24edc92e2bc9a325fe8192789599 (主6379id)
master_repl_offset:27020
second_repl_offset:7838
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:27020

(4)重启6379服务器并查看详细信息,发现6379变为从机。
[root@localhost rediscluster]# redis-server redis-6379.conf
[root@localhost rediscluster]# redis-cli -p 6379
127.0.0.1:6379> info replication# Replication
role:slave (角色为从)
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_read_repl_offset:37045
slave_repl_offset:37045
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:e5522f539a742719f3d3b960412c9e07bf520a57 (主6380id)
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:37045
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:35485
repl_backlog_histlen:1561

五, 复制延时
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
六, 选举策略
- 选择优先级靠前的服务器。优先级的配置在 redis.conf 文件中的 replica-priority 配置,默认为 100,值越小优先级越高。
- 选择偏移量最大的。偏移量是指获得原主机数据最全的。
- 选择 runid 最小的从服务器。每个redis实例启动后都会随机生成一个40位的runid。