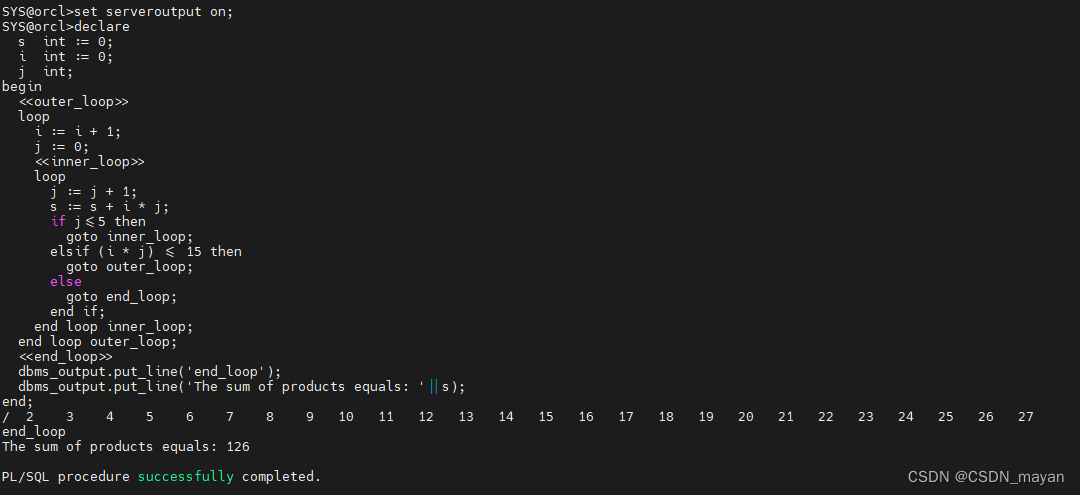
一、基本NMS
1. 处理过程
为了保证物体检测的召回率,对于同一个真实物体往往会有多于1个的候选框输出。但是多余的候选框会影响检测精度,因此需要利用NMS过滤掉重叠的候选框,基本的NMS方法利用得分高的边框抑制得分低且重叠程度高的边框。
如图1-1所示,图片中存在3个候选框,但是候选框A与C对应的是同一个物体,由于C的得分比A要低,在计算召回率时,C候选框会被当做一个False Positive来看待,从而降低模型的精度。( R e c a l l = T N T N + F P Recall=\frac{TN}{TN+FP} Recall=TN+FPTN,当 F P FP FP增大时, R e c a l l Recall Recall减小)实际上,由于候选框A的质量要比C好,理想的输出是A而不是C,因此希望能够抑制掉候选框C。

2. 量化指标
检测网络在最后会增加一个NMS(非极大值抑制),将重复冗余的候选框去掉。这个过程涉及以下两个量化指标:
- 预测得分:NMS假设一个边框的预测得分越高,这个边框就要被优先考虑,其他与其重叠超过一定程度的边框都要被舍弃,非极大值即是指得分的非极大值。
- IoU:用于评价两个边框的重合程度。如果两个边框的IoU超过一定阈值时,得分低的边框会被舍弃。阈值通常取0.5或者0.7。
3. 具体流程
NMS的输入包含5个预测量,即所有候选框的得分、左上点坐标、右下点坐标,以及1个设定的IoU阈值。
具体流程如下:
- 按照得分,对所有边框进行降序排列,记录下排列的索引order,并新建一个列表keep,作为最终筛选后的边框索引结果。
- 将排序后的第一个边框置为当前边框,并将其保留到keep中,再求当前边框与剩余所有框的IoU。
- 在order中,仅仅保留IoU小于设定阈值的索引,重复第二步,直到order中仅仅剩余一个边框,则将其保留到keep中,退出循环,NMS结束。
二、Soft NMS
1. 漏检现象
NMS对于分布密集的物体,容易出现漏检现象。即当两个真实物体靠的较近且得分不一致时,两个框的IoU较大,可能超过了阈值,此时NMS会筛掉得分较低的框。
NMS的计算公式如式(2-1)所示:
s
i
=
{
s
i
,
i
o
u
(
M
,
b
i
)
<
N
t
0
,
i
o
u
(
M
,
b
i
)
⩾
N
t
(2-1)
s_{i}=\left\{\begin{matrix} s_{i}, & iou(M,b_{i})< N_{t}& \\ 0, & iou(M,b_{i})\geqslant N_{t}& \end{matrix}\right.\tag{2-1}
si={si,0,iou(M,bi)<Ntiou(M,bi)⩾Nt(2-1)
公式中 S i S_{i} Si代表了每个框的得分, M M M为当前得分最高的框, b i b_{i} bi为剩余框的某一个, N t N_{t} Nt为设定的阈值,可以看到当IoU大于 N t N_{t} Nt时,该边框的得分直接置0,相当于被舍弃了,从而有可能造成边框的漏检。
2. Soft NMS
Soft NMS对于IoU大于阈值的边框,没有将其得分直接置0,而是降低该边框的得分。
Soft NMS的计算公式如式(2-2)所示:
s i = { s i , i o u ( M , b i ) < N t s i ( 1 − i o u ( M , b i ) ) , i o u ( M , b i ) ⩾ N t (2-2) s_{i}=\left\{\begin{matrix} s_{i}, & iou(M,b_{i})< N_{t}& \\ s_{i}(1-iou(M,b_{i})), & iou(M,b_{i})\geqslant N_{t}& \end{matrix}\right.\tag{2-2} si={si,si(1−iou(M,bi)),iou(M,bi)<Ntiou(M,bi)⩾Nt(2-2)
从公式中可以看出,利用边框的得分与IoU来确定新的边框得分,如果当前边框与边框 M M M的IoU超过设定阈值 N t N_{t} Nt时,边框的得分呈线性的衰减。
但是,式(2-2)不是一个连续函数,当一个边框与 M M M的重叠IoU超过阈值 N t N_{t} Nt时,其得分会发生跳变,这种跳变会对检测结果产生较大的波动,因此还需要寻找一个更为稳定、连续的得分重置函数,最终Soft NMS给出了式(2-3)所示的重置函数。
s i = s i e − i o u ( M , b i ) 2 σ , ∀ b i ∉ D (2-3) s_{i}=s_{i}e^-{\frac{iou(M,b_{i})^{2}}{\sigma }}, \forall b_{i}\notin D \tag{2-3} si=sie−σiou(M,bi)2,∀bi∈/D(2-3)
采用这种得分衰减的方式,对于那些得分很高的边框来说,在后续的计算中还有可能被作为正确的检测款框,从而提高模型的召回率。
三、Softer NMS
1. 定位置信度
NMS和Soft NMS都使用了预测分类置信度作为衡量指标,即假定分类置信度越高的边框,其位置也越准确。
但位置置信度与分类置信度并不是强相关的关系,基于此,Softer NMS新增加了一个定位置信度的预测,使得高分类置信度的边框位置变得更加准确,从而有效提升了检测的性能。
2. 分布假设
为了更全面地描述边框预测,Softer NMS方法对预测边框与真实物体做了两个分布假设:
- 真实物体的分布是狄拉克delta分布,即标准差为0的高斯分布的极限。
δ ( x ) = { + ∞ , x = 0 0 , x = o t h e r w i s e \delta (x)=\left\{\begin{matrix} +\infty , & x=0 & \\ 0 , & x=otherwise & \end{matrix}\right. δ(x)={+∞,0,x=0x=otherwise
- 预测边框的分布满足高斯分布。
X ∼ N ( μ , σ 2 ) X\sim N(\mu ,\sigma ^{2}) X∼N(μ,σ2)
基于以上两个假设,Softer NMS提出了一种基于KL(Kullback-Leibler)散度的边框回归损失函数KL Loss。( K L 散度是用来精确计算当把一个分布近似为另一个分布时,损失了多少信息 KL散度是用来精确计算当把一个分布近似为另一个分布时,损失了多少信息 KL散度是用来精确计算当把一个分布近似为另一个分布时,损失了多少信息)这里的KL Loss是最小化预测边框的高斯分布与真实物体的狄克拉分布之间的KL散度。即预测边框分布越接近于真实物体分布,损失越小。
3. 网络结构

Softer NMS在计算回归损失时,增加了一个标准差预测分支,从而形成边框的高斯分布,与边框的预测一起求得KL损失。
边框的标准差可以被看做边框的位置置信度,因此Softer NMS利用该标准差也改善了NMS过程。