347. 前 K 个高频元素
答案
思路:
1、首先,用到了每个值对应的出现次数,想到要用哈希map存放
2、还需要将出现频率从大到小进行排序,找出前k个元素
3、时间复杂度应该比O(nlogn)小
如果想用快速排序,是达不到最后一个要求的
通过从大到小排序,很可能会想到用大顶堆,但是由于大顶堆是每次都把频率最大的那个元素放在堆顶上,而如果达到了k个,就会把当前的最大元素弹出,这对于寻找所有元素中频率最大的k个元素并不方便
所以考虑小顶堆:
1、小顶堆可以在堆达到k个元素后,每次弹出当前最小的元素,这样最后剩下的k个元素就是我们要找的
2、在当堆元素达到k个后,进行判断:
如果当前的堆顶元素的出现次数,比当前的元素的次数小,就舍弃堆顶元素,并把当前遍历的元素加入堆中;
如果当前的堆顶元素的出现次数比当前遍历的元素的出现次数大,说明当前堆中的所有元素的出现次数都比当前遍历的元素的出现次数大,则舍弃当前遍历的元素。
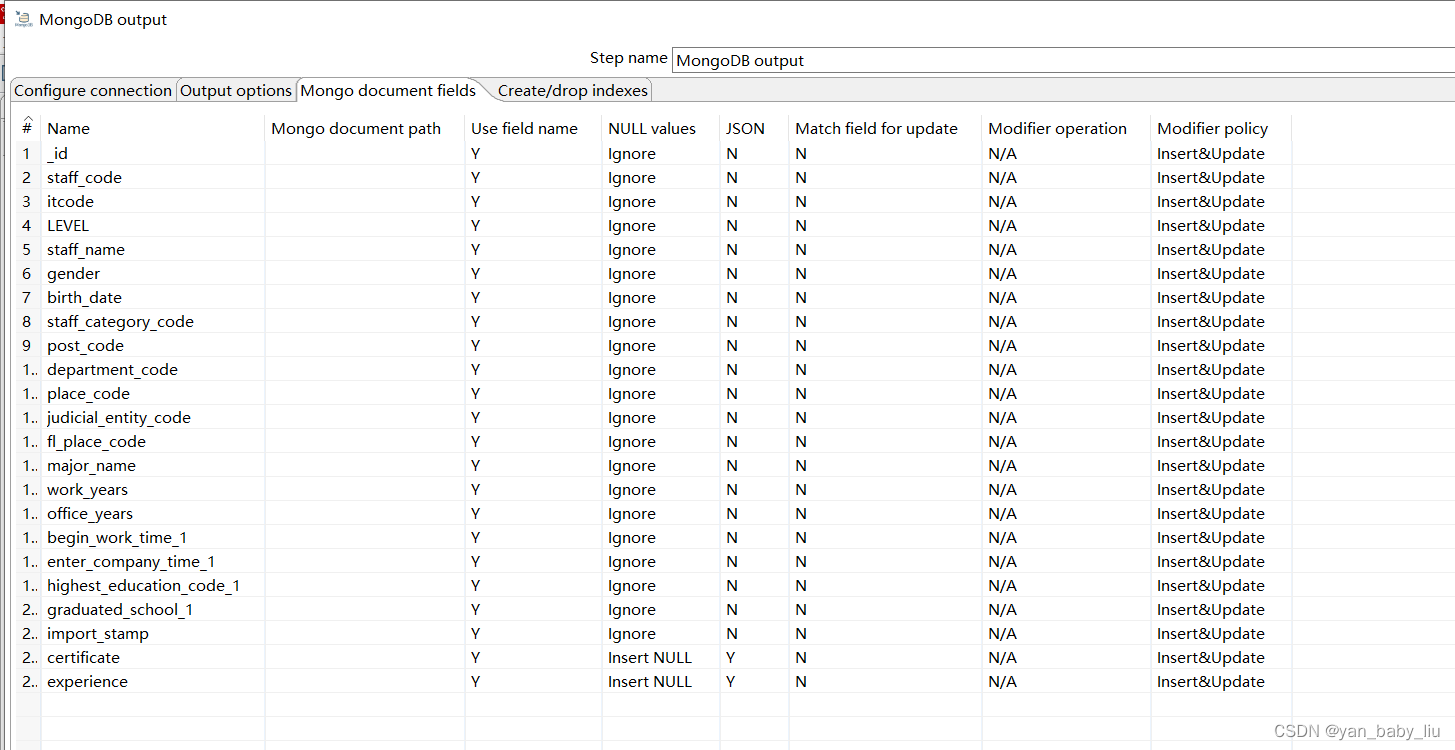
用到的知识点
优先级队列(PriorityQueue)
我们知道队列是遵循先进先出(First-In-First-Out)模式的,但有些时候需要在队列中基于优先级处理对象。
在概念上,默认为小顶堆
1、在Java1.5中引入并作为 Java Collections Framework 的一部分
2、基于优先堆的一个无界队列,这个优先队列中的元素可以默认自然排序或者通过提供的Comparator(比较器)在队列实例化的时排序。(不指定Comparator时默认为最小堆),优先队列的头是基于自然排序或者Comparator排序的最小元素。堆排序只能保证根是最大(最小),整个堆并不是有序的
3、优先队列不允许空值
4、优先队列不允许空值
5、PriorityQueue是非线程安全的,所以Java提供了PriorityBlockingQueue(实现BlockingQueue接口)用于Java多线程环境
6、优先队列的大小是不受限制的,但在创建时可以指定初始大小。当我们向优先队列增加元素的时候,队列大小会自动增加
常用方法
Map
1、HashMap、LinkedHashMap和Hashtable是Map的两个常用实现类
HashMap特点:
- HashMap是无序的集合,存储元素和取出元素的顺序有可能不一致
- 集合是不同步的,也就是说是多线程的,速度快
LinkedHashMap特点:
- LinkedHashMap是一个有序的集合,存储元素和取出元素的顺序一致
2、常用方法
put——添加元素
putall——向map添加指定的集合
containsKey——判断是否包含指定的key
containsValue——判断是否包含指定的值
get——获取指定key对应的value
remove——删除指定的key对应的元素
size——获取元素个数
getOrDefault
getOrDefault(Object key, V defaultValue)
意思就是当Map集合中有这个key时,就使用这个key对应的value值,如果没有就使用默认值defaultValue
Entry
Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entry<K,V>。它表示Map中的一个实体(一个key-value对)。接口中有getKey(),getValue方法。
Map遍历的方法
- for循环中遍历value
Map<String, String> map = new HashMap();
map.put("开发", "开发");
map.put("测试", "测试");
for (Object value : map.values()) {
System.out.println("第一种:" + value);
}
- 通过key遍历
for (String key: map.keySet()) {
System.out.println("第二种:" + map.get(key));
}
- 通过entrySet实现遍历
Set<Map.Entry<String, String>> entrySet = map.entrySet();
for (Map.Entry entry : entrySet) {
System.out.println("第三种:" + entry.getKey() + " :" + entry.getValue());
}
- 通过Iterator迭代器实现遍历
Iterator<Map.Entry<String, String>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, String> entry = entryIterator.next();
System.out.println("第四种:" + entry.getKey() + " :" + entry.getValue());
}
- 通过lambda表达式进行遍历
map.forEach((key, value) -> {
System.out.println("第五种:" + key + " :" + value);
});
代码
class Solution {
public int[] topKFrequent(int[] nums, int k) {
Map<Integer,Integer> map=new HashMap<>();
for(int num:nums){
map.put(num,map.getOrDefault(num,0)+1);//
}
PriorityQueue<int[]> queue=new PriorityQueue(new Comparator<int[]>(){//comparator
public int compare(int[] m,int[] n){
return m[1]-n[1];
}
});
for(Map.Entry<Integer,Integer> entry:map.entrySet()){//
int num=entry.getKey();
int value=entry.getValue();
if(queue.size()==k){
if(queue.peek()[1]<=value){
queue.poll();
queue.offer(new int[]{num,value});//
}
}else{
queue.offer(new int[]{num,value});
}
}
int[] res=new int[k];
for(int i=0;i<k;i++){
res[i]=queue.poll()[0];//
}
return res;
}
}
注意:
1、接口的书写:Comparator
2、方法名不大写:compare
3、再重写方法时,new Comparator<int[ ]>不能省略<int[ ]>
4、PriorityQueue的添加方法是offer
5、push和pop是栈中常用的方法
栈中常用方法:push、pop、peek、isEmpty
队列常用方法:offer、poll、peek、isEmpty
二叉树的基本知识
Java定义
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
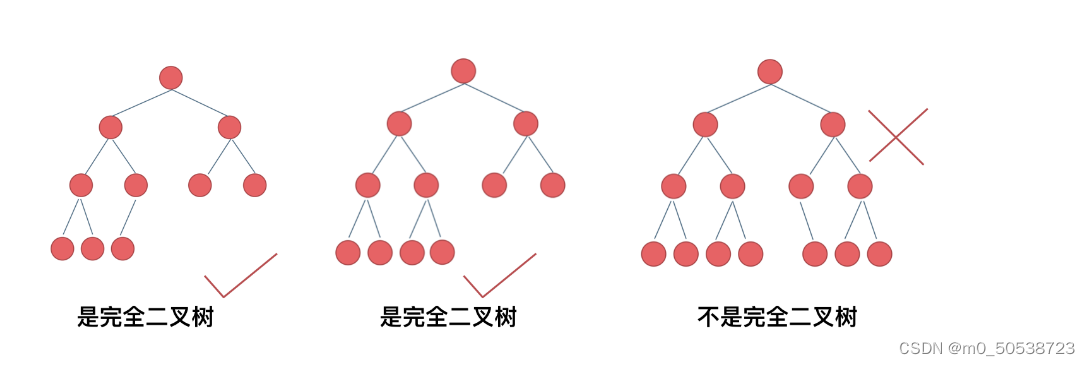
完全二叉树
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。
二叉搜索树
前面介绍的树,都没有数值的,而二叉搜索树是有数值的了,二叉搜索树是一个有序树。
若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
它的左、右子树也分别为二叉排序树
下面这两棵树都是搜索树
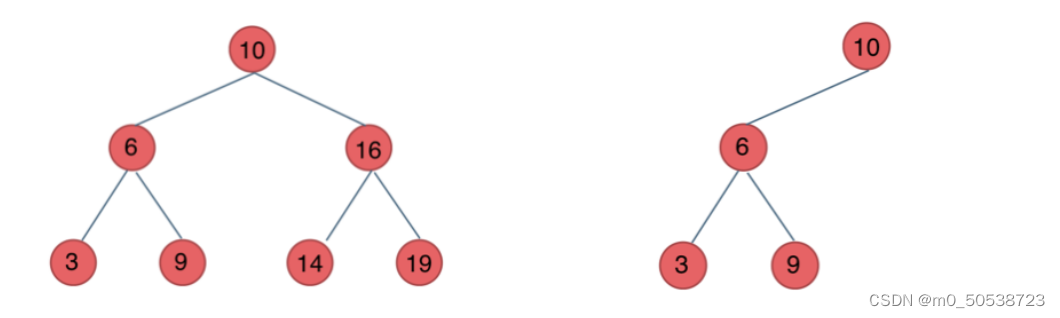
平衡二叉搜索树
平衡二叉搜索树:又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
如图:

遍历方式
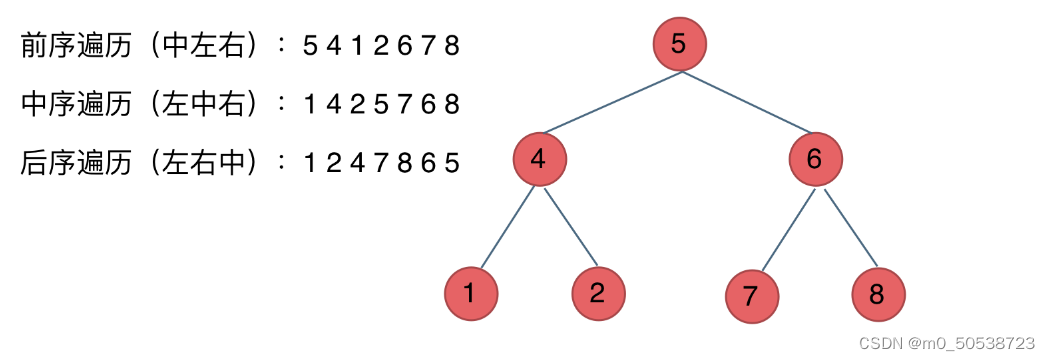
存储方式
二叉树可以链式存储,也可以顺序存储
关于二叉树遍历的题目(使用递归——144、145、94)
- 144
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new LinkedList<Integer>();
preorder(root, result);
return result;
}
public void preorder(TreeNode root, List<Integer> result) {
if (root == null) {//这里判断的是节点是否为null,不是结点的值
return;
}
result.add(root.val);//别忘了加
preorder(root.left, result);
preorder(root.right, result);
}
}
- 145
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res=new LinkedList<>();
traversal(root,res);
return res;
}
public void traversal(TreeNode root,List res){
if(root==null){
return;
}
traversal(root.left,res);
traversal(root.right,res);
res.add(root.val);
}
}
- 94
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res=new LinkedList<>();
traversal(root,res);
return res;
}
public void traversal(TreeNode root,List res){
if(root==null){
return;
}
traversal(root.left,res);
res.add(root.val);
traversal(root.right,res);
}
}
关于List的用法:
1、
添加方法是:.add(e);
获取方法是:.get(index);
删除方法是:.remove(index); 按照索引删除; .remove(Object o); 按照元素内容删除;
2、
否包含某个元素:.contains(Object o); 返回true或者false
3、
根据索引将元素数值改变(替换):
.set(index, element); set是将替换该索引位置的值
.add(index, element); add是在该索引位置插入一个值;
4、
.indexOf(); 第一个该值的索引
lastIndexOf()的不同;最后一个该值的索引;
5、
判断list是否为空:.isEmpty(); 空则返回true,非空则返回false





![[NOIP2002 普及组] 过河卒](https://img-blog.csdnimg.cn/b816aaea74df43e99e02192b8569591a.png)