当创建k8s pod的时候调度器会决定pod在哪个node上被创建且运行,
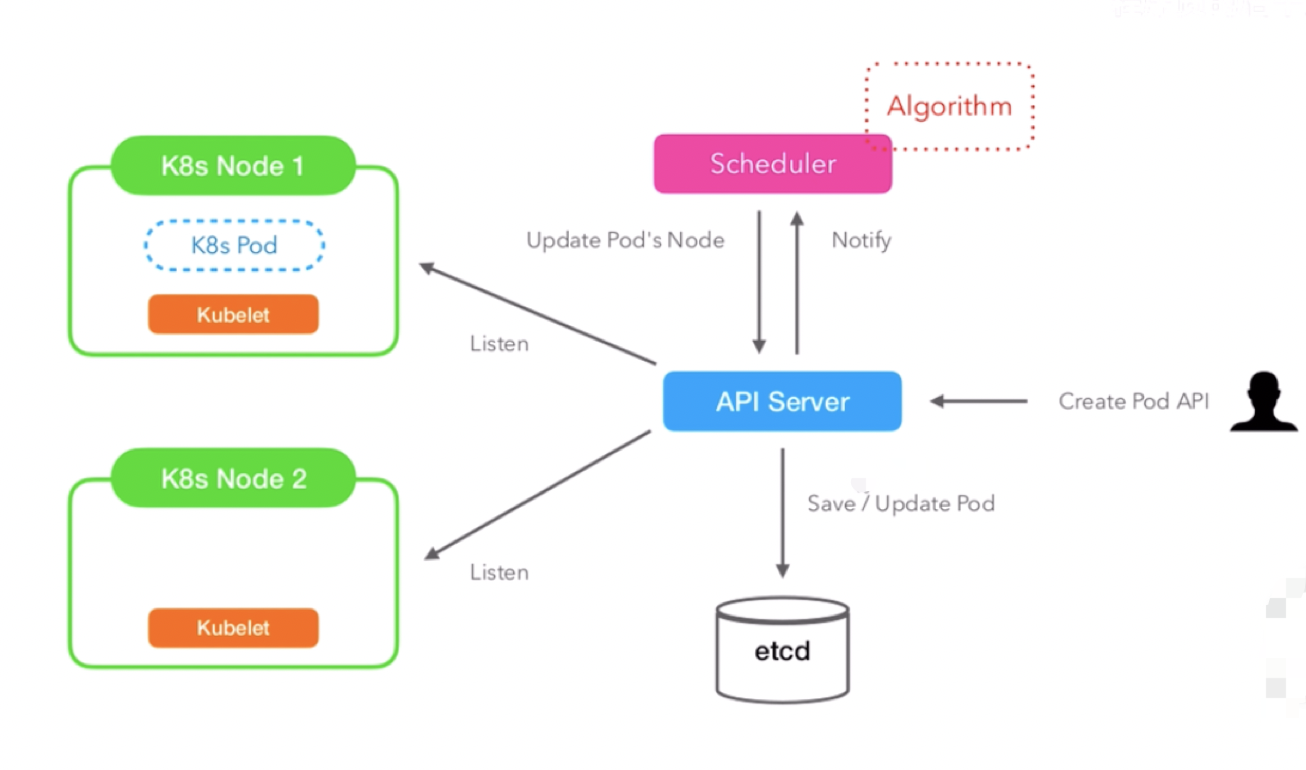
调度器给apiserver发出了一个创建pod的api请求,apiserver首先将pod的基本信息保存在etcd,apiserver又会把这些信息给到每个node上的kubelet进程,kubelet一直在监听这些信息,当kubelet发现这个pod的节点信息跟它当前运行的节点一致的时候,就会创建pod进程以及容器当中的docker image进程,创建相应的命名空间,使得进程之间互相隔离,这样pod就在这个节点上运行起来了。
k8s调度器会尽量的去保证所有节点上的资源是相对平衡的,判断节点资源(CPU、内存、存储、端口等)是否适合Pod的资源申请。
查看K8s资源在etcd中的信息
借助kube-etcd-helper这个工具查看etcd中的内容,
写一个操作etcd命令的脚本./etcdheloper.sh,指定etcd的地址,鉴权需要的证书等信息,
查看k8s资源列表,./etcdheloper.sh ls
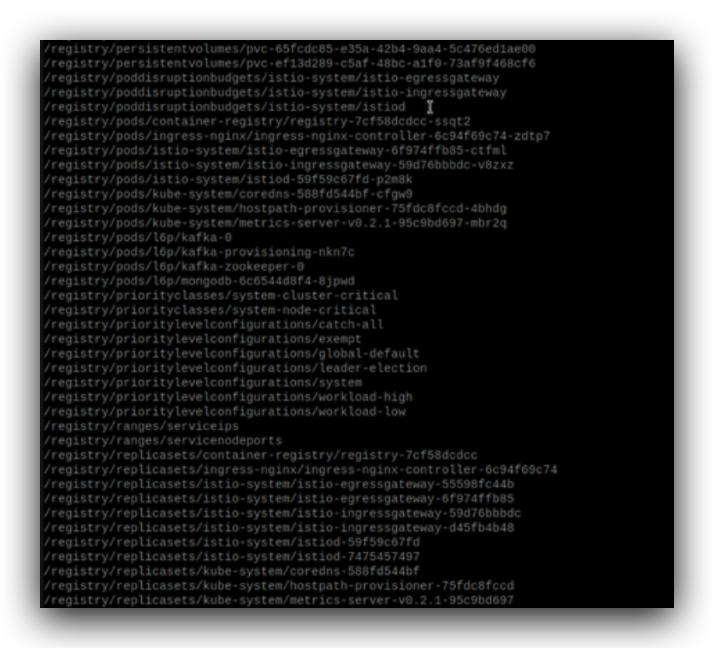
这是etcd中保存的k8s资源信息,查看指定的pod信息,
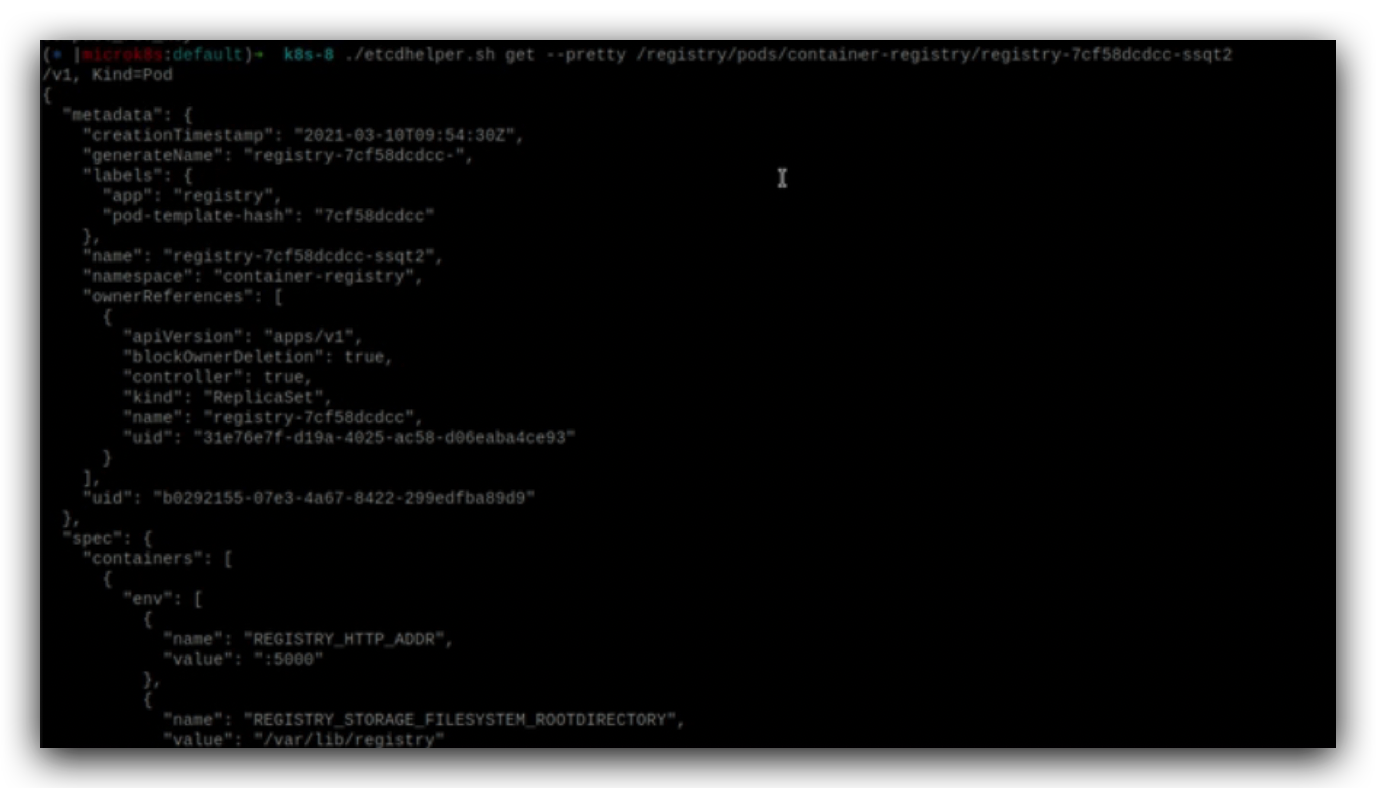
跟调度器相关的是这个nodeName,

验证调度器的工作方式
有了etcd helper可以更加详细的看下调度器的工作原理,调度器一直在监听k8s中的pod的创建,通过etcd watch的功能可以去监听一个pod的创建并且看到创建的整个过程。
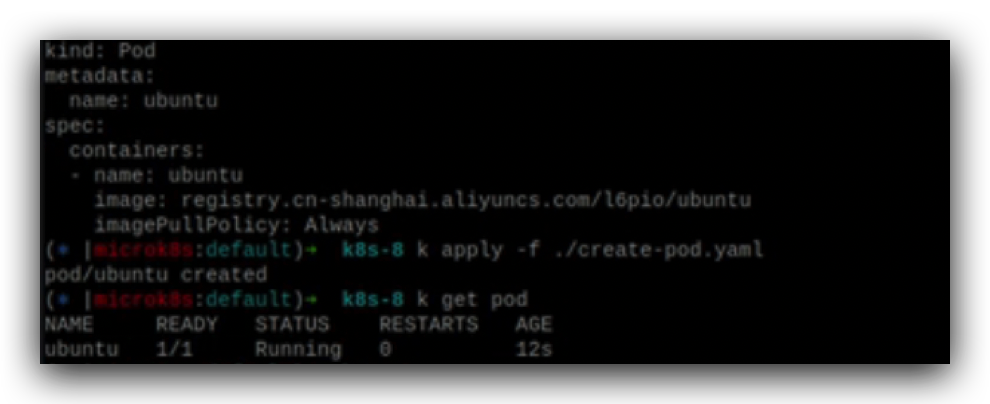
创建这个pod,使用etcd helper来监听下这个pod在etcd当中变动的过程,

通过这个命令可以看到在etcd中关于这个pod产生了4次变动,每次变动都是一个json,通过JSON Diff工具比较每次json都变动了哪些内容,
第一个json和第二个json比较,多了一个nodeName,
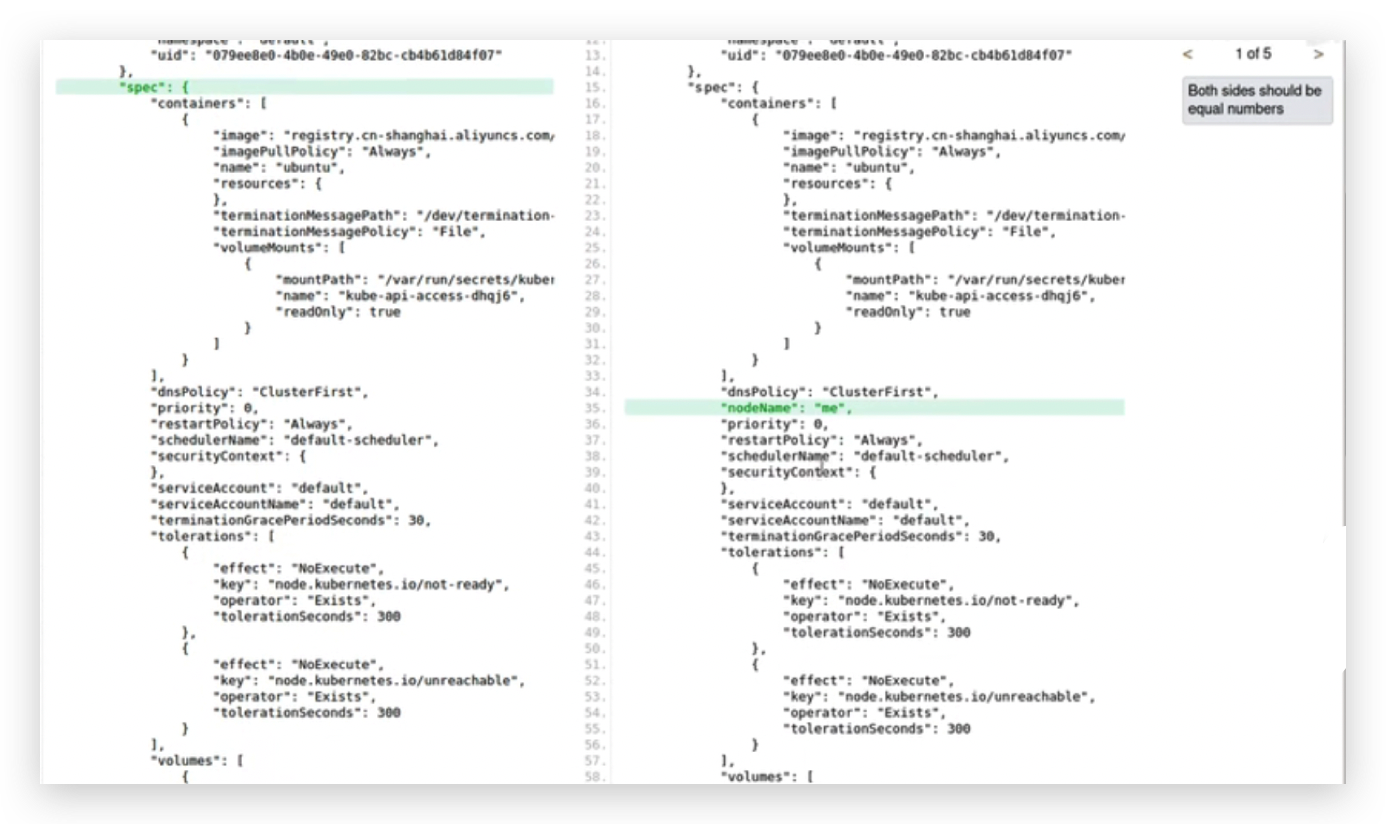
第一次给apiserver发送请求把这个信息保存在etcd当中的时候还没有nodeName,第二次就是更新nodeName,调度器通过算法决定了这个pod要在这个node上创建,
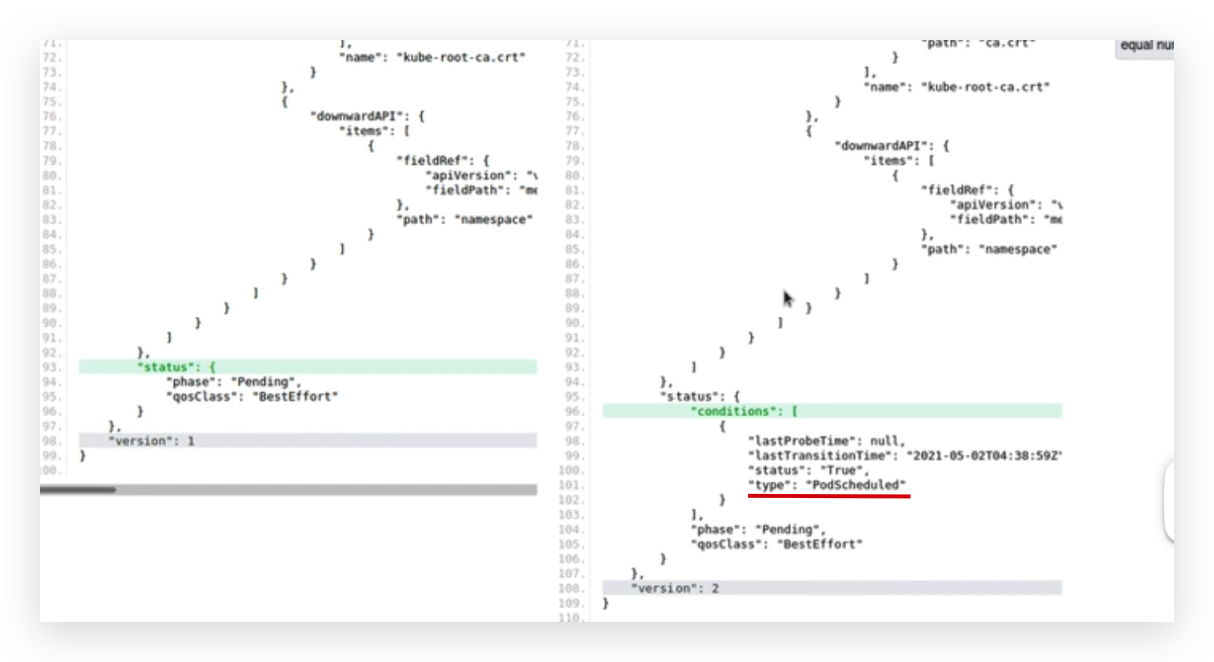
这里声明了pod已经被调度了;
第三次的json相比第二次json的变更内容:

记录了pod中container容器的启动状态和pod的ip。
Pod指定节点运行

这是集群中node的情况,
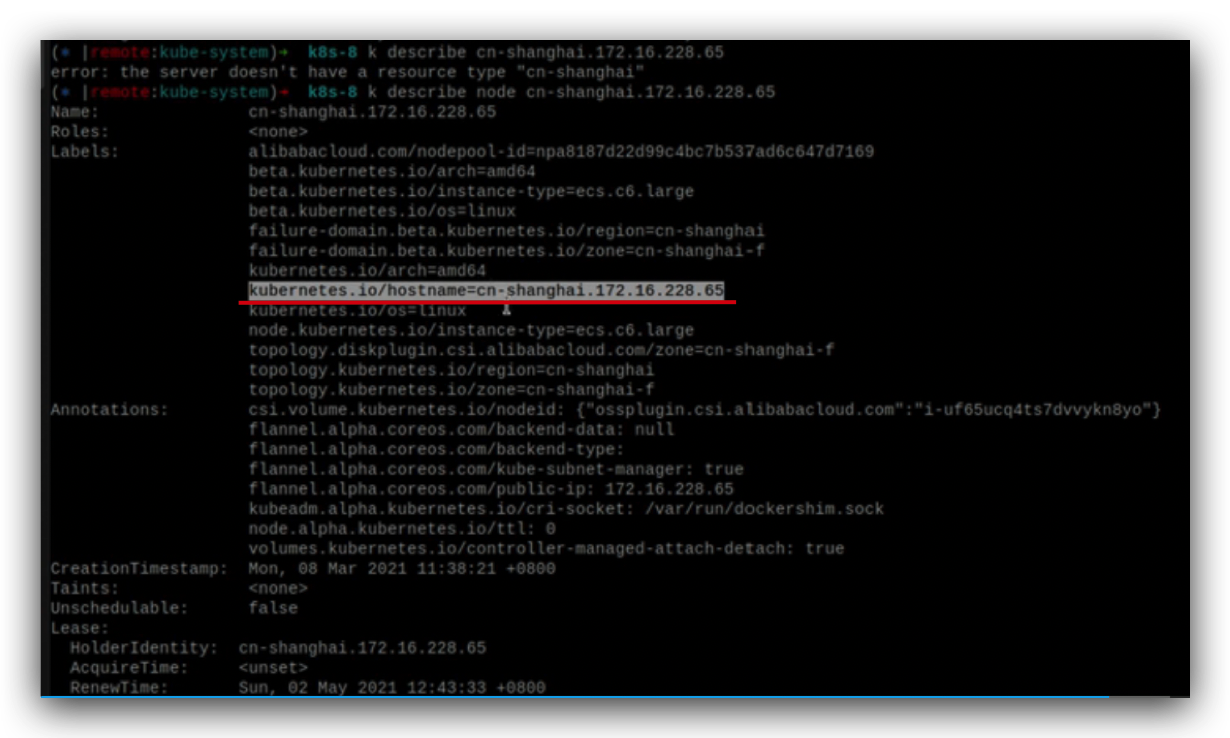
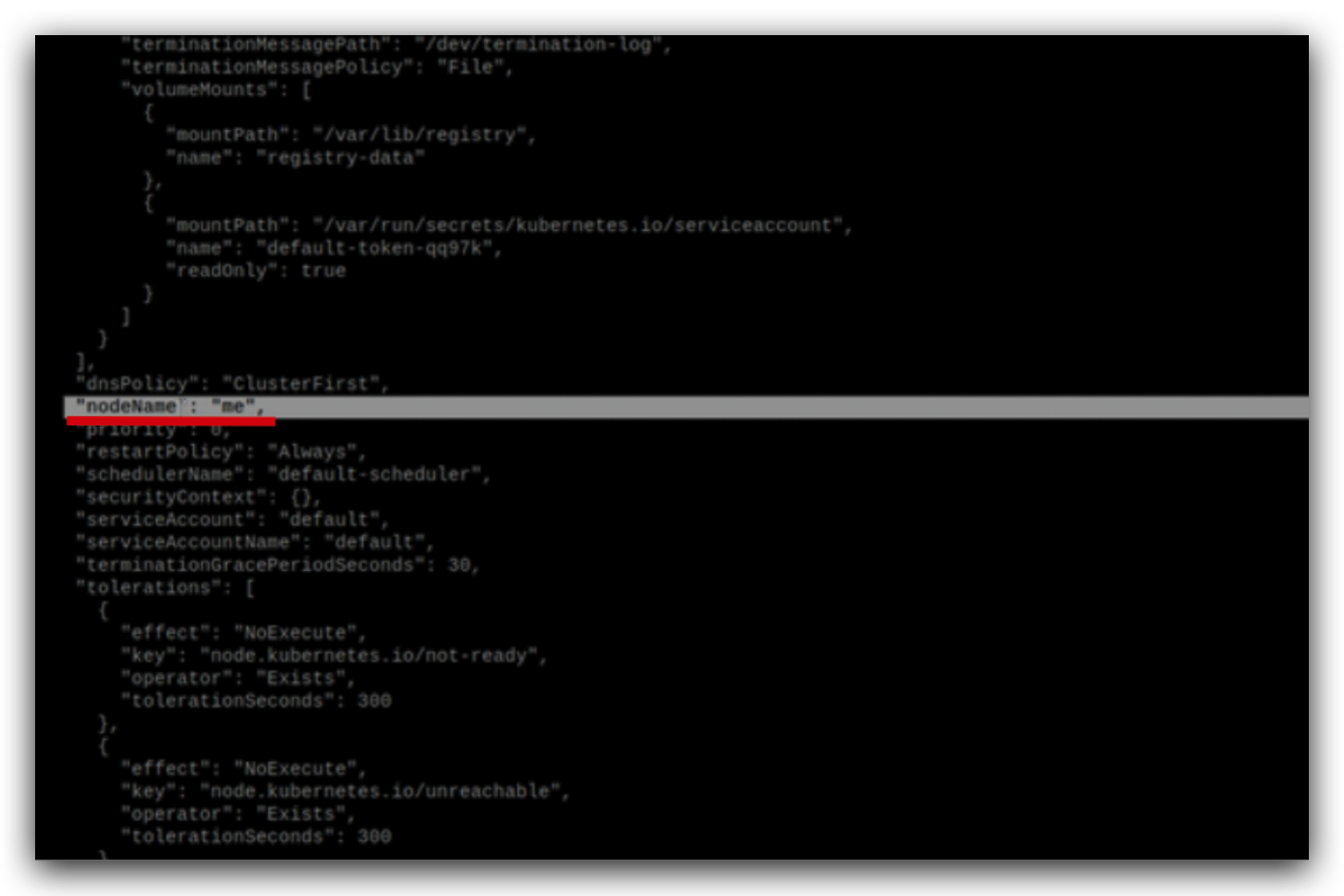
查看指定node的详情,红色部分决定了node的名称,
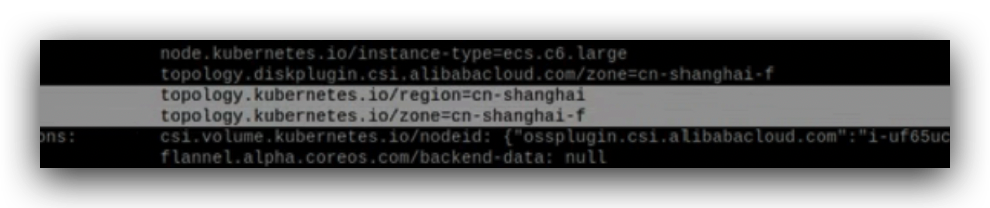
这个分别代表节点所在的区域和时区,
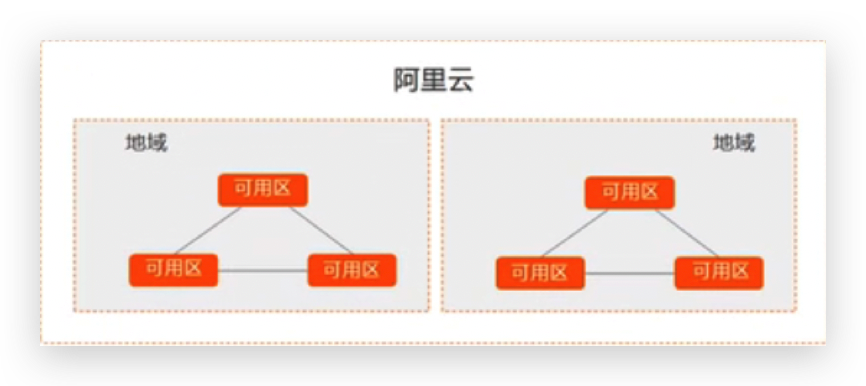
每个地域完全独立,但同一个地域的可用区中间是互通的。
地域是指电力和网络互相独立的区域;同一可用区内实例之间的网络延迟更小;
关键点是电力和网络相互独立,这个是在灾备的时候要考虑的。
数据库、k8s的节点、消息队列等常用的资源都是需要做冗余的,如果在一个可用区内做大量的冗余,
看起来比较安全,一旦这个可用区废掉了,所有的冗余信息在短时间内是不可工作的,跨可用区做冗余可用性就会得到极大的增强。
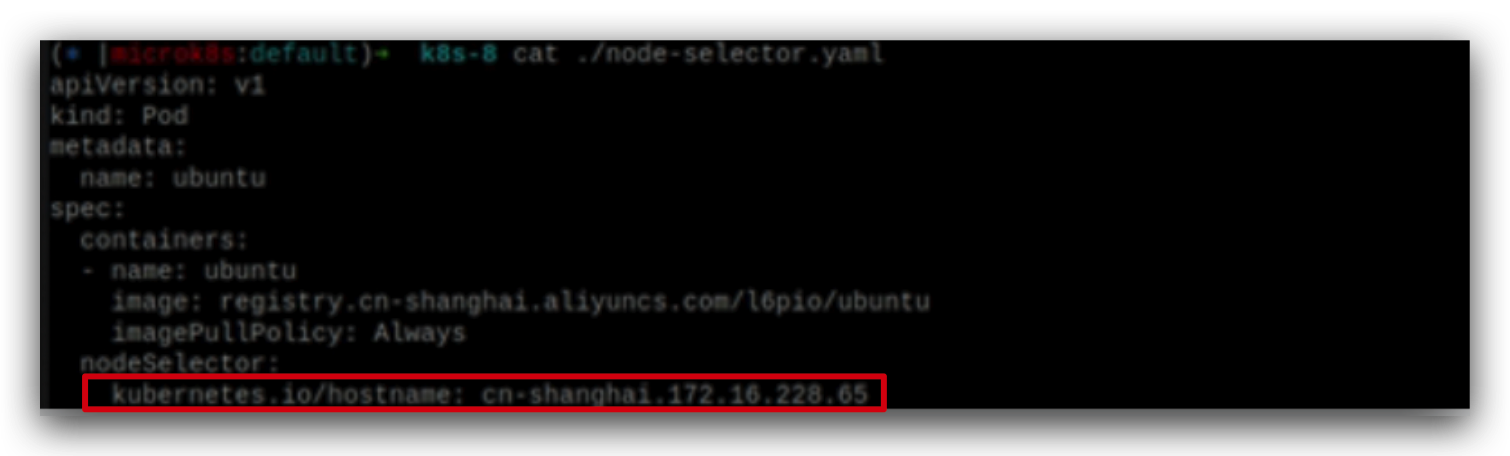

pod在指定的node上运行。
正常工作的节点
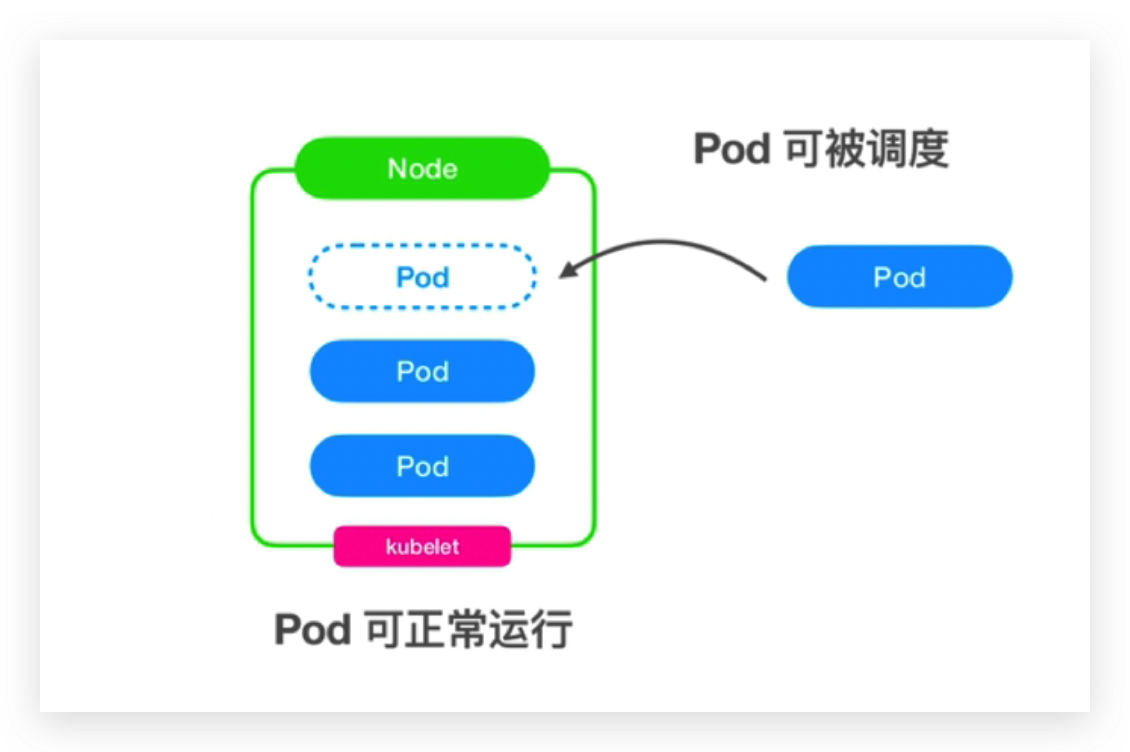
这是正常工作的节点,pod通过kubelet这个进程被创建出来。
kubectl向apiserver发送了一个请求,apiserver就把请求信息存储在etcd数据库里,调度器通过事件的监听,通过调度算法来决定pod将会被调度到哪个节点上去,确定是哪个node之后,所以就在etcd的pod信息里面增加了一个nodeName。
kubelet也进行监听,当它发现调度器分配这个pod到某一个节点信息修改的时候,来看这个节点是不是属于它当前运行的node,如果是的话,就会创建这个pod。
k8s是go语言写的,一般用glog打日志,
k8s 基于glog fork出来一个klog,k8s内核是用klog来记录日志的。

glog有个参数:-v,表示日志的详细程度,
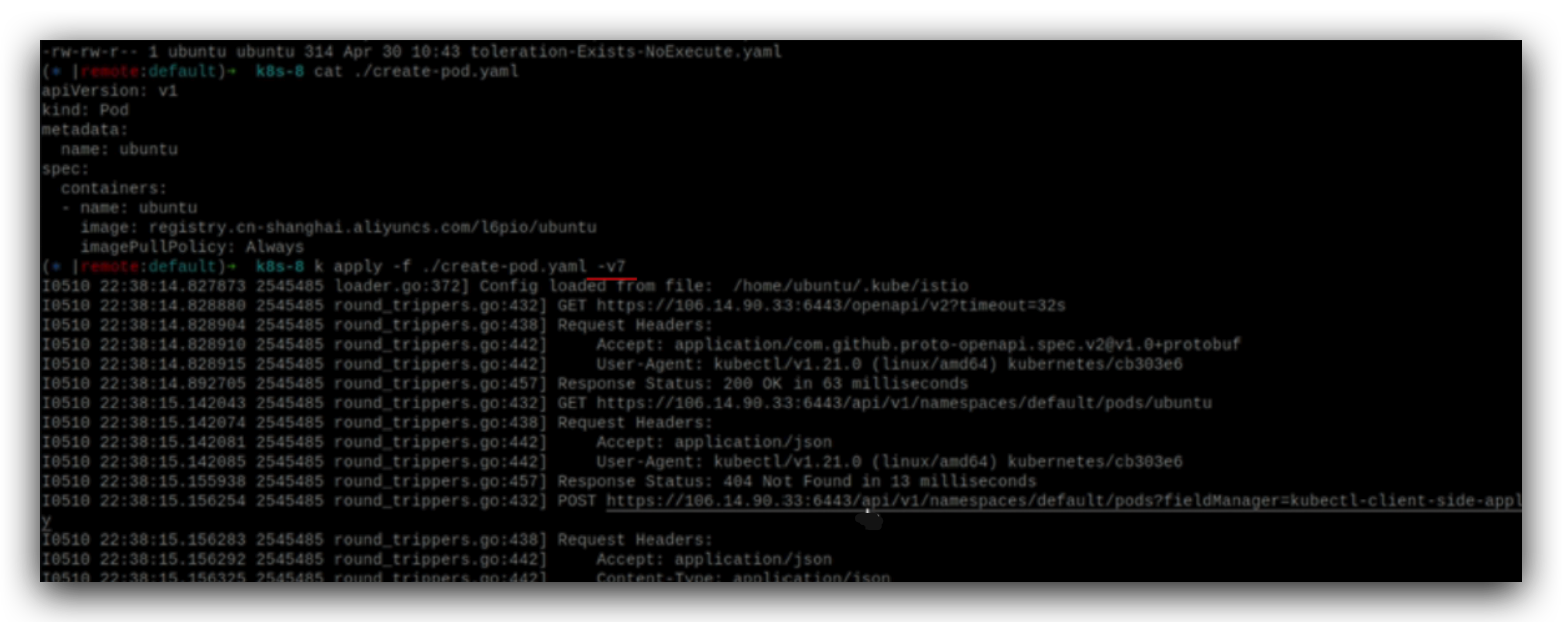
从日志中可以看到,在创建pod的时候,先判断pod是否存在,如果不存在的话,则创建。
有2种情况不属于正常工作的节点,
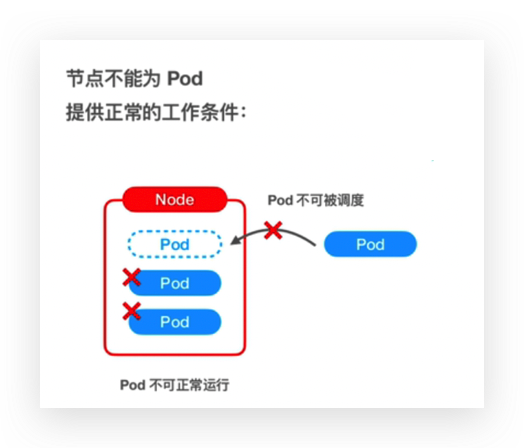
pod不能被调度到节点或者pod根本不可以在节点上运行,比如这个节点的systemd后台进程有问题导致节点不能正常运行,并不代表节点所在的虚拟机崩溃了,但是作为k8s节点是不能正常运行的,这种情况下node被打上一个污点。
NoScheduler表示不能调度到指定节点上;
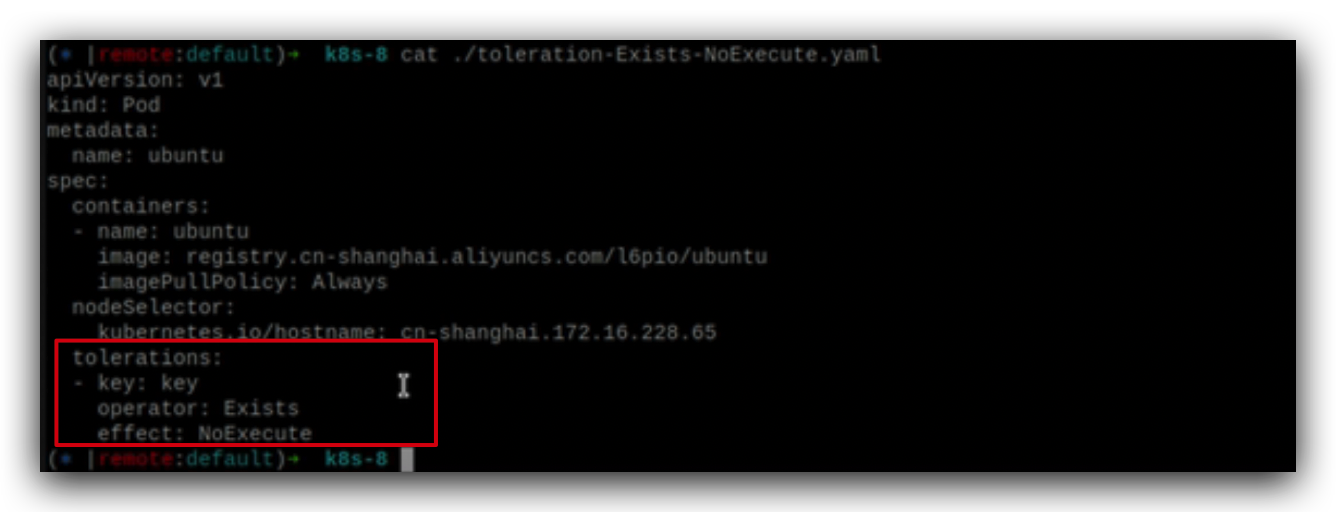
NoExecute表示新的pod将不可以被调度到指定node上运行,当前在上面运行的pod也将被驱逐。
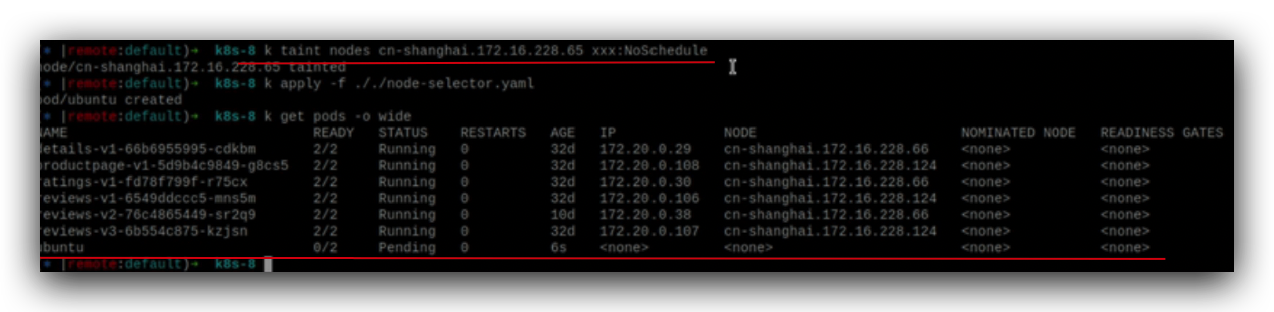
参数名称可以任意起,污点一旦被创建,对节点就生效了,ubuntu这个pod状态一直pending,就表示调度不过去 ,原因就是因为这个node被打上了污点。
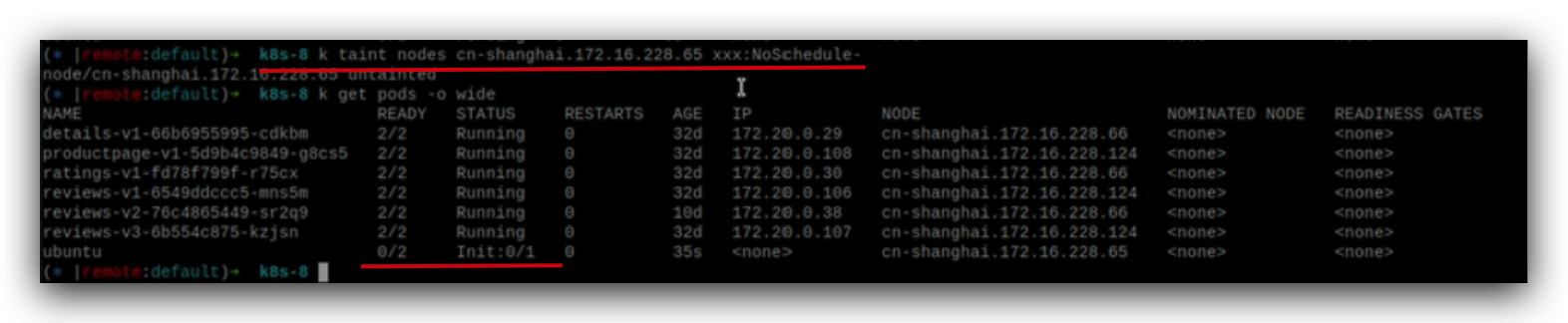
解除污点,pod就被调度到这个node节点上启动了。

给node打上NoExecute污点,

这个节点上面的这个pod直接就停掉了,

去掉NoExecute污点,新的pod就可以在这个节点上运行了。
给node打污点的情况实际用的比较少,除非排错,比如pod还能在node上跑,不希望新的pod被调度过来,先打一个污点,再在上面排查问题。
如果要重启node或修改配置,一般通过拉警戒线的方式,
跟打污点的效果是一样的,
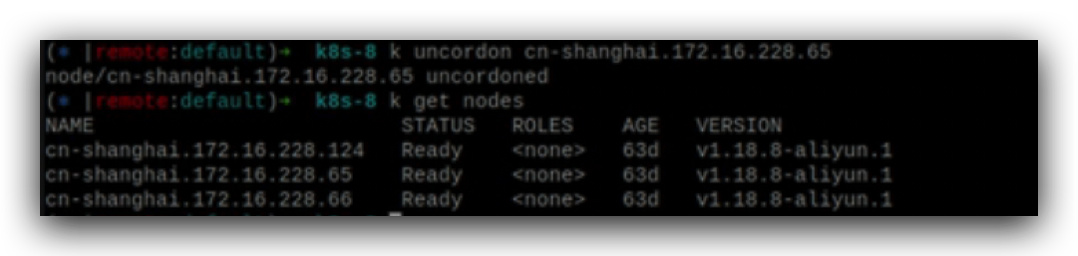
去除警戒线。
打污点或拉警戒线的使用场景:
场景1,比如阿里云systemd进程因版本的问题需要升级,会用这个命令,
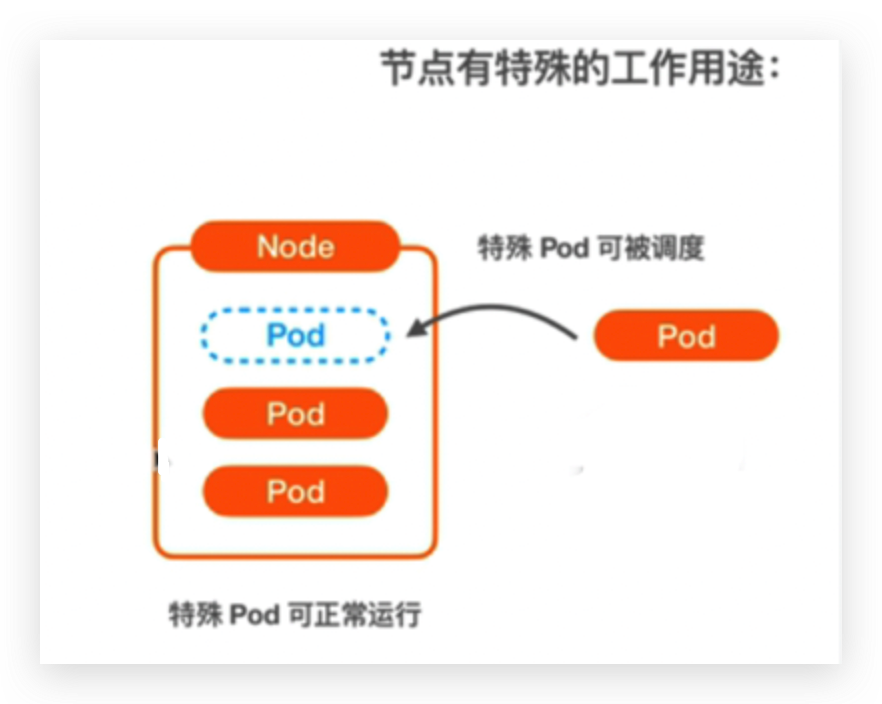
场景2,节点有特殊的工作用途,比如master节点,一般至少用2个node做master节点,阿里云可以去托管master节点,比如当前的集群中只有worker节点没有master节点是因为被阿里云托管了,对于这种情况也需要给master node打上污点,不将pod调度到master node上去。
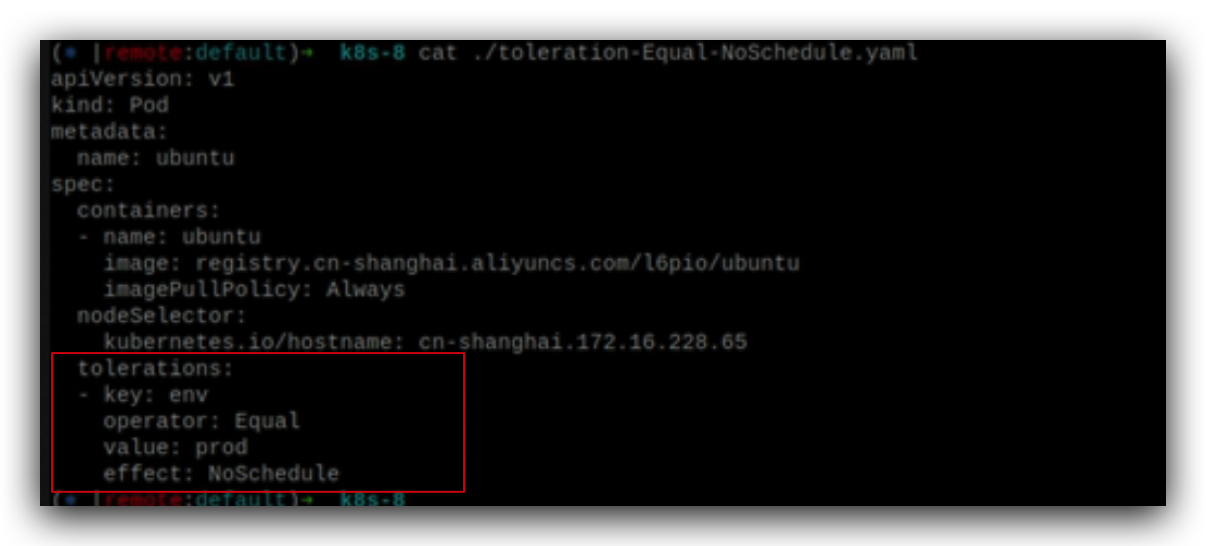
打污点key有两种形式,一种是以字符串label的方式,

另外一种比如env=prod,

表示节点是测试环境还是生产环境。
除非pod有env=prod并且可以容忍NoExecute这样的标签,才能被调度在这个pod上,
node亲和性
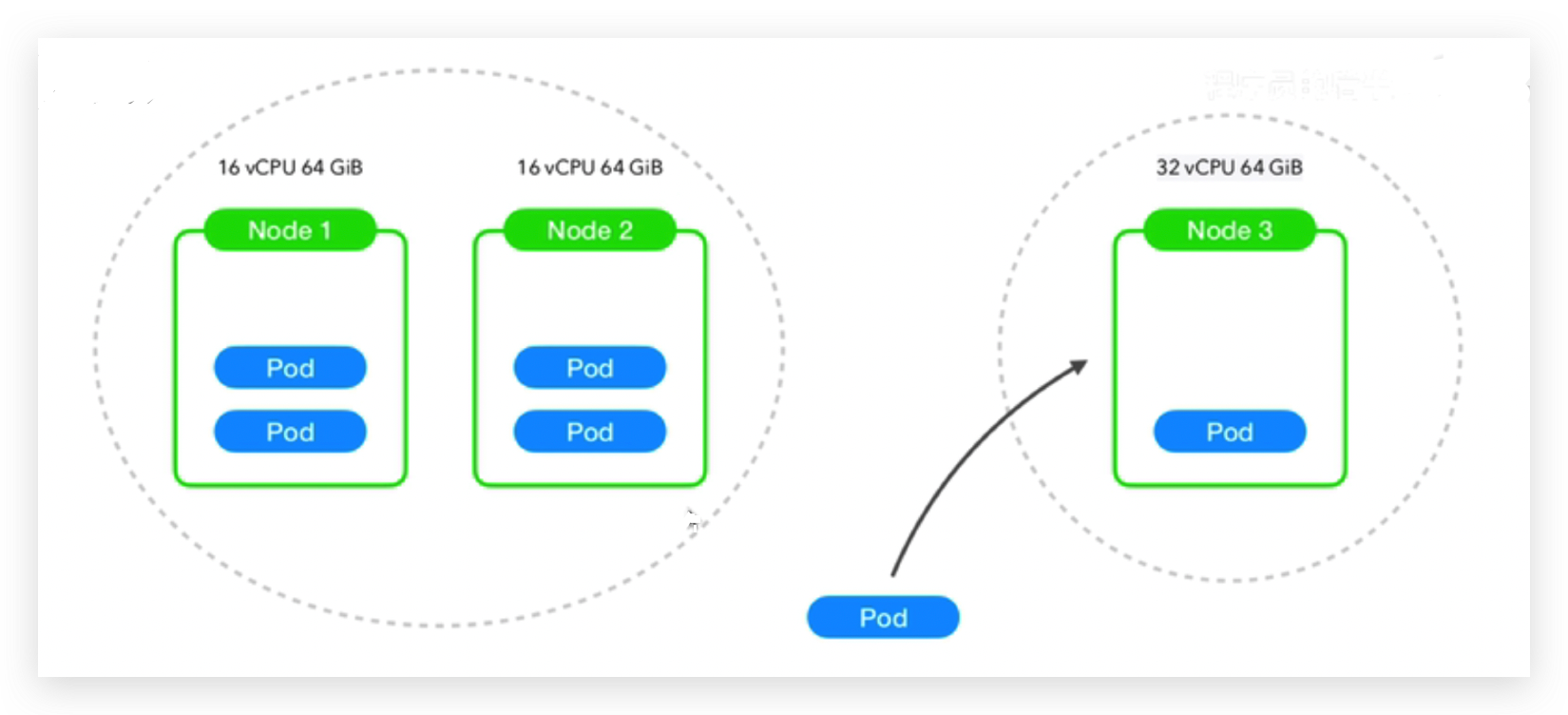
node1 16核64G内存,node2 16核64G内存,node3 32核 64G内存,让pod向性能比较好的node上运行即pod亲和node3,
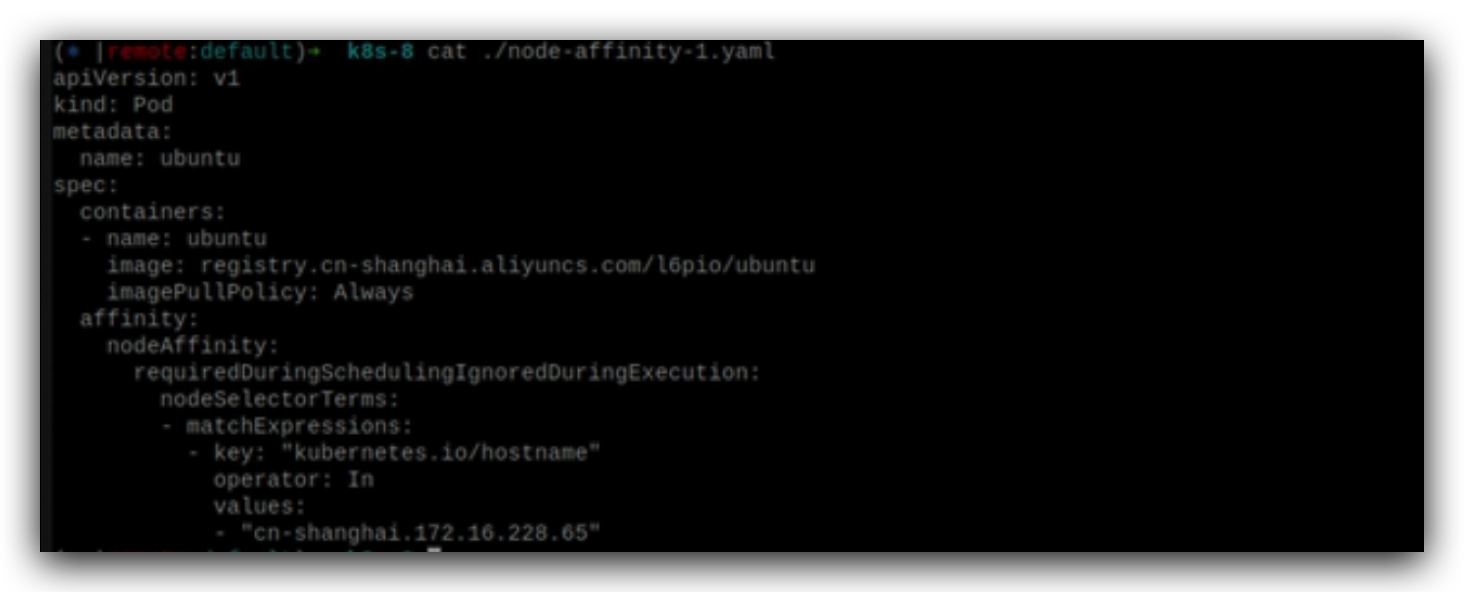
pod亲和于什么样的node去运行,在调度的时候affinity是必须的,但在实际运行的时候又用不到,只是调度的时候用到。
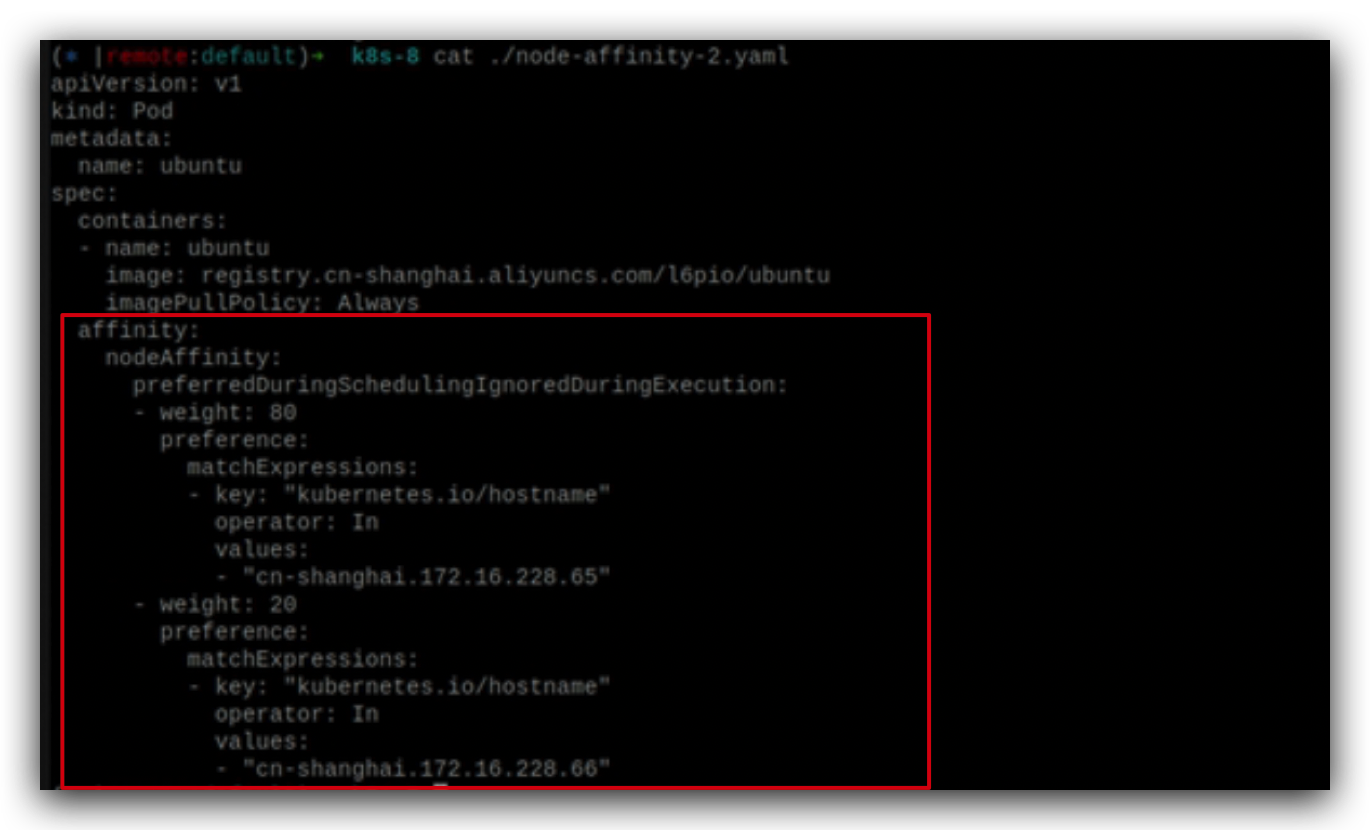
在调度的时候80%的概率到一个node,20%的概率到另外一个node。
pod的亲和性
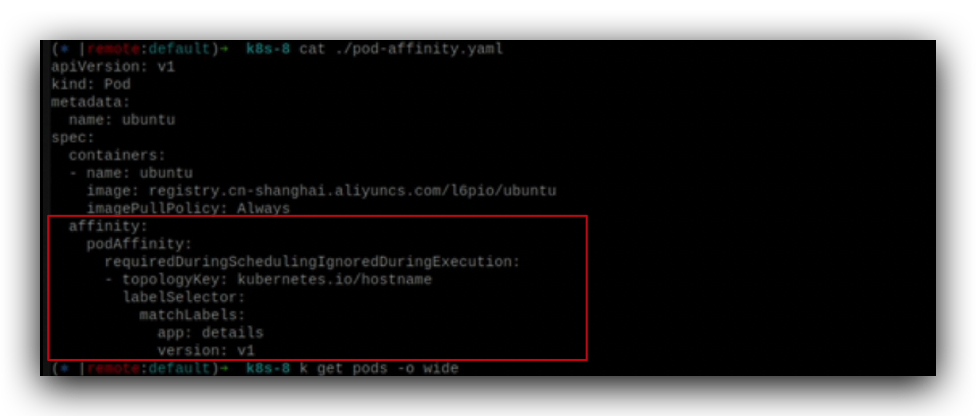
details pod运行在哪个node上,ubuntu pod也运行在details pod所在的node上,
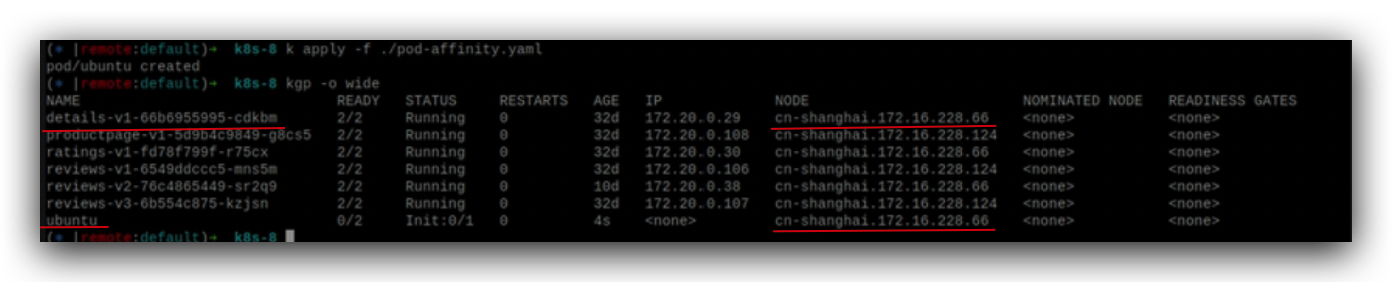
实际运用的场景比如前后端的pod运行在同一个node上。启动pod的时候去查有没有满足app:details这个条件的pod,如果有的话,就在运行在这个pod所在的node上。
pod的反亲和性
每个node有不同的hostname,如果发现这个node上已经运行了跟我一样label的pod,那我就不在这个node上运行了,再找一个新的node即同样的一个pod不在同一个node上运行这样的效果,
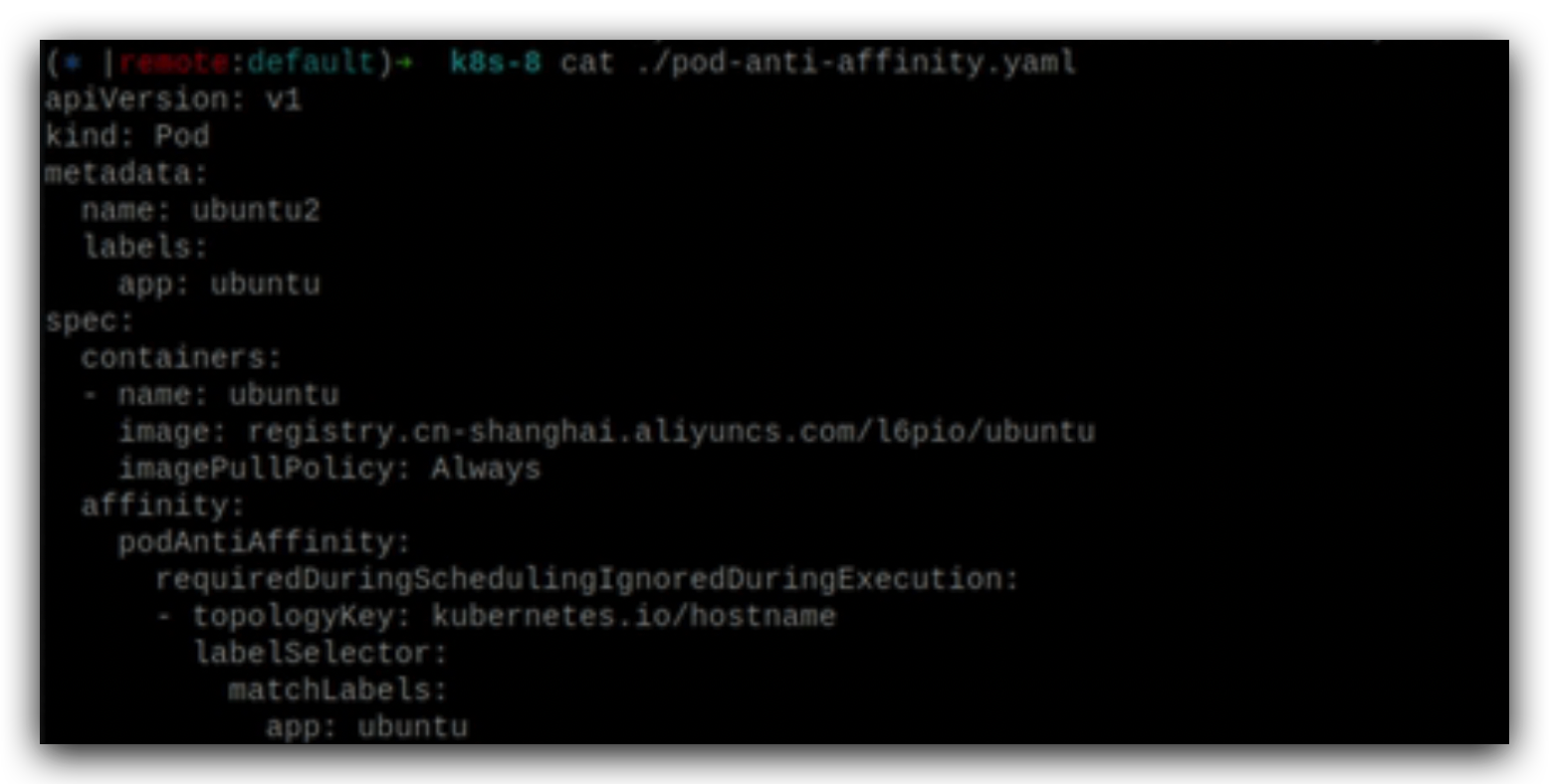

65这个node上已经运行了ubuntu了,
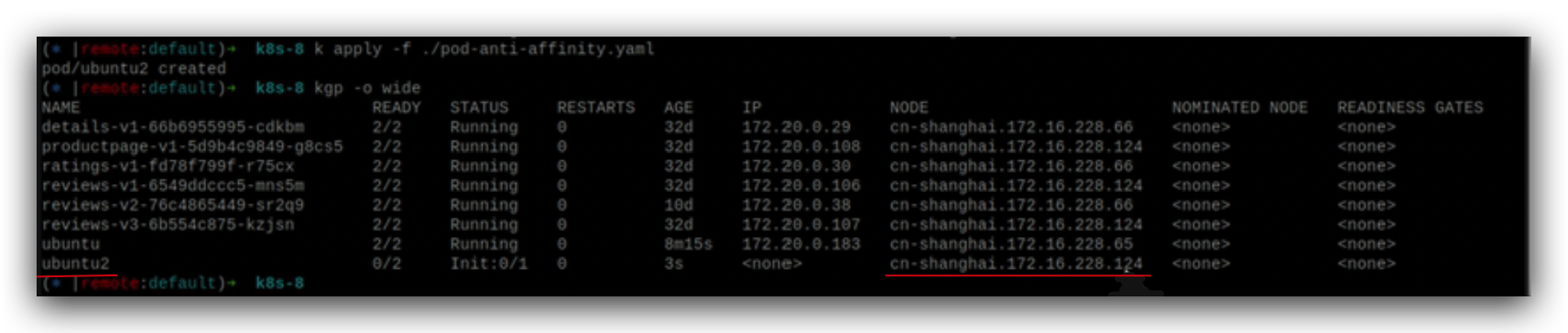
再启动一个ubuntu,就不会在65这个node上运行了,而是在124这个node上运行,

再运行ubuntu3和ubuntu4,为什么ubuntu4一直pending是因为每个node上都有ubuntu了,4没有node可以运行了。
pod亲和度使用场景比较多,node亲和度几乎用不到,因为同一个集群,尽量使用同样的ecs虚拟机,尽量不要有差异化。
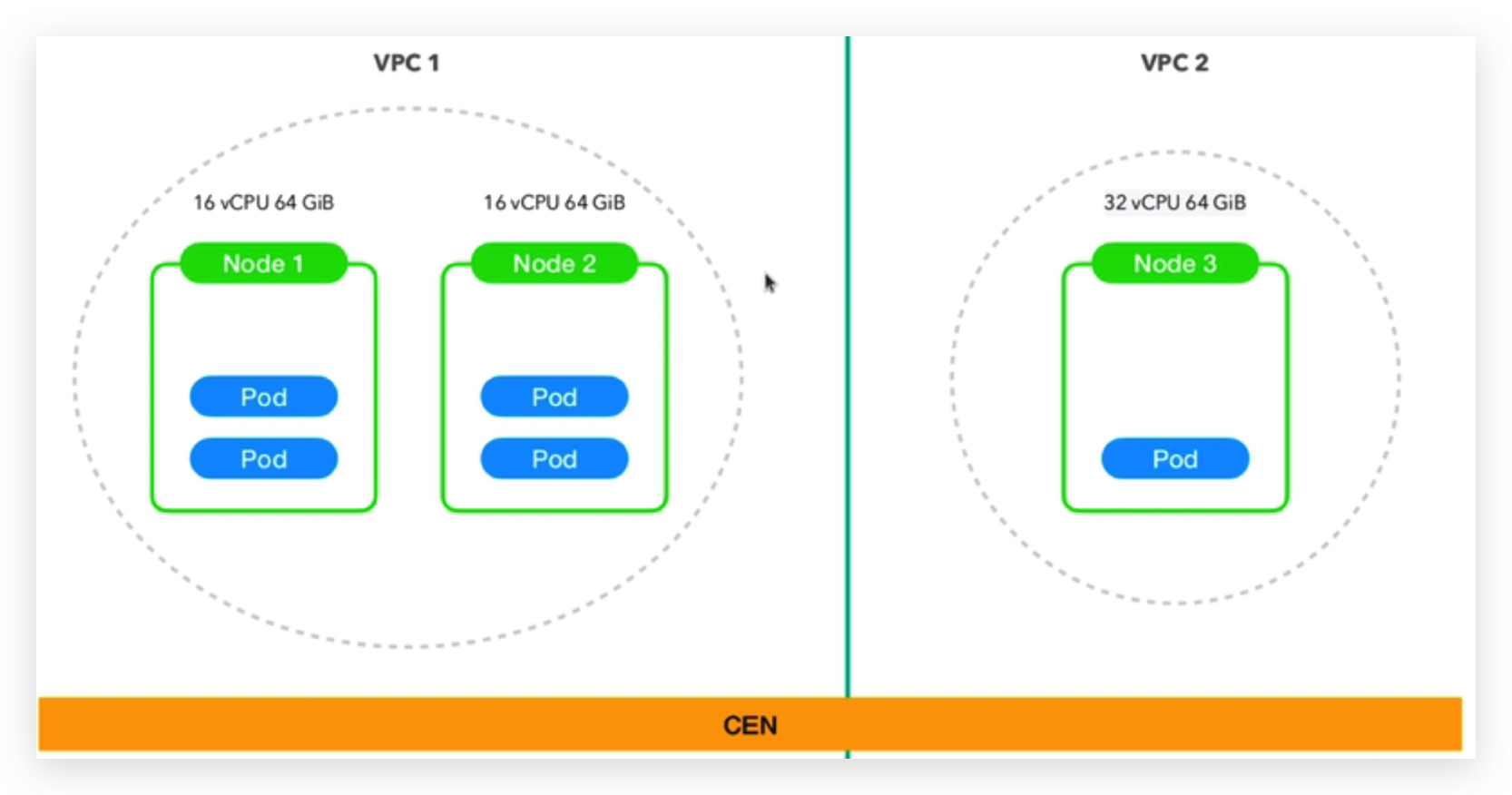
就算要区分环境,比如这2台配置比较小的机器做测试环境,(生产环境的机器要比测试环境多的多,这里只是做假设),更倾向于配成2个不同的vpc(私有云)
,每个vpc有自己独立的网段,2个vpc相对安全些,让2个网段互通可以使用阿里云的cen,

这样比较好,而不是做一个大的集群(里面什么样的node都有),再通过打污点、打标签,个人感觉这样会比较累。
,





![CSS字体样式(font)[详细]](https://img-blog.csdnimg.cn/13aef95f583a487bb1e7596a85db308b.png)