文章目录
- url统一资源定位符
- http协议介绍
- GET vs POST
- http状态码
- http常见header
- cookie + session
上篇博客定制了一个协议,该协议用来进行简单的计算,其包含了数据的序列化和反序列化,编码和解码的定制,并且该协议基于TCP通信,是一种客户端请求服务端响应的模型。如果你也实现了一个自己的协议,肯定会有疑问:自己定制的协议不够成熟,而且应用场景有限,有没有一个成熟且应用场景广泛的协议?这还真有,它就是上网必须使用的协议——http,https
url统一资源定位符
要了解http就要先了解url
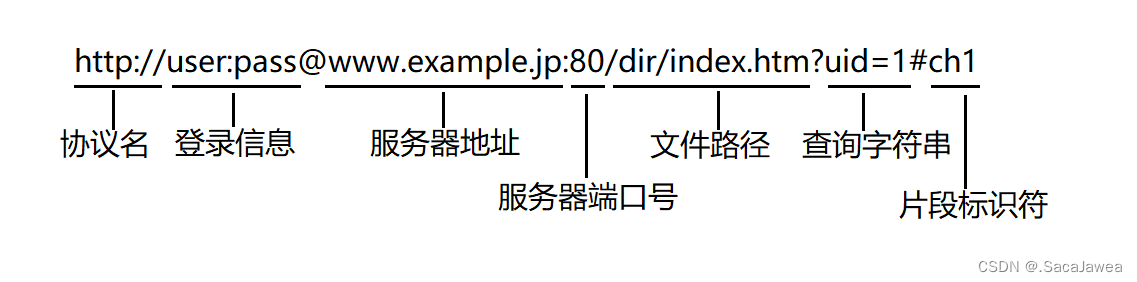
协议名:表示该url采用的协议
登录信息:一般在url中被隐去,其体现在http请求的报头或者正文当中
服务器地址:也称域名,域名最终会被解析为IP地址
服务器端口号:网络通信的本质是进程间通信,所以需要告知IP+端口号,使通信能够进行。但是由于服务器的端口号通常是固定的,不写端口号时,端口号也能通过其他特殊方法得知,通信照样能进行
文件路径:用具体的路径来表示想要访问服务器的哪些资源
查询字符串:通常用来过滤网页中的信息,得到想要的信息
片段标识符:也称锚点,用来指定网页的停靠位置,或者音视频的播放位置
可以看到,url中不同字段需要用特殊符号进行分隔,这就意味着每一字段中不能出现这些特殊符号,或者说如果出现了这些特殊符号,需要对这些特殊符号做处理。比如搜索c++这这个关键字
由于‘+‘是特殊字符,所以其被编码成其他格式。再者,搜索汉字时,汉字也会被重新编码

虽然url栏显式的是汉字,但是把url复制下来再粘贴,得到的url是
https://www.baidu.com/s?wd=%E5%93%88%E5%93%88
这里说明一下特殊字符的编码规则,将特殊字符转换成十六进制,以两个十六进制数为一组,从低到高一次取出每一组,再它们的前面加上%,编码成%XY的形式。查询ASCII码表,+的码值为43,表示成十六进制是2B,所以在url中,其被编码成%2B
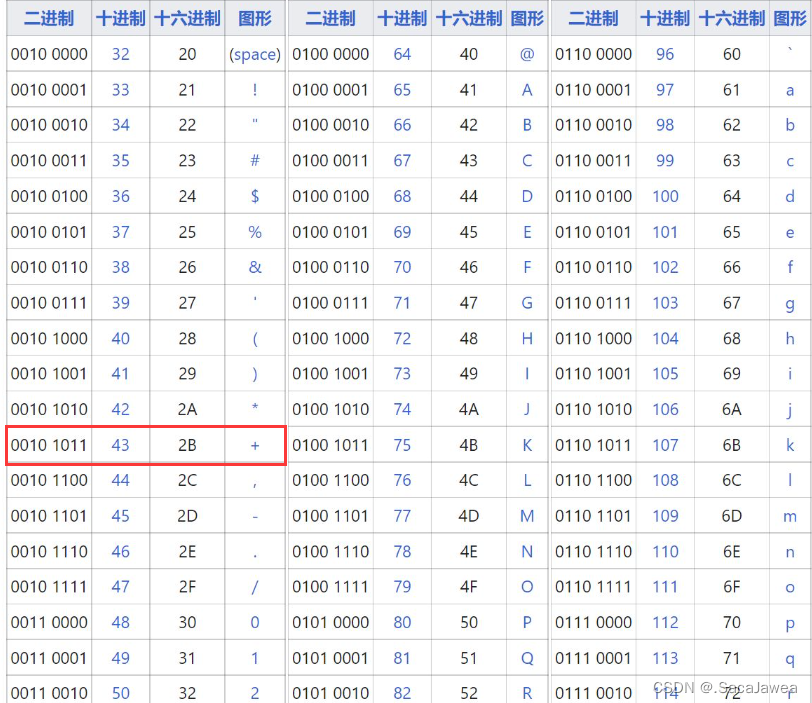
由于url采用的是utf-8编码格式,在该格式下汉字被编码成3个字节,由于两个十六进制数表示1个字节,刚才“哈哈”被编码后,有6组%XY格式的数据,也就是6个字节。关于把特殊字符进行编码的过程,我们叫做urlencode,将%XY格式的数据解码的过程,我们叫做urldecode
再回过头来看url,其全称是Uniform Resource Locator,统一资源定位符,通过url我们就能定位互联网上某一台主机的某些资源。我们使用http协议进行请求,就是请求获取某一天主机(服务器)上的某些资源(音视频,文本),当然,服务器的响应就是将客户端请求获取的资源返回。所以说,我们访问的网页,看到的视频,文字,不是凭空产生的,这些资源都是存储在某些服务器的磁盘上,在我们请求资源时,由服务器发送给我们的。
http协议介绍
比起上篇博客,自己定制的协议,http协议能够使用的场景实在是太多了,同样的,关于http的协议格式也是更复杂的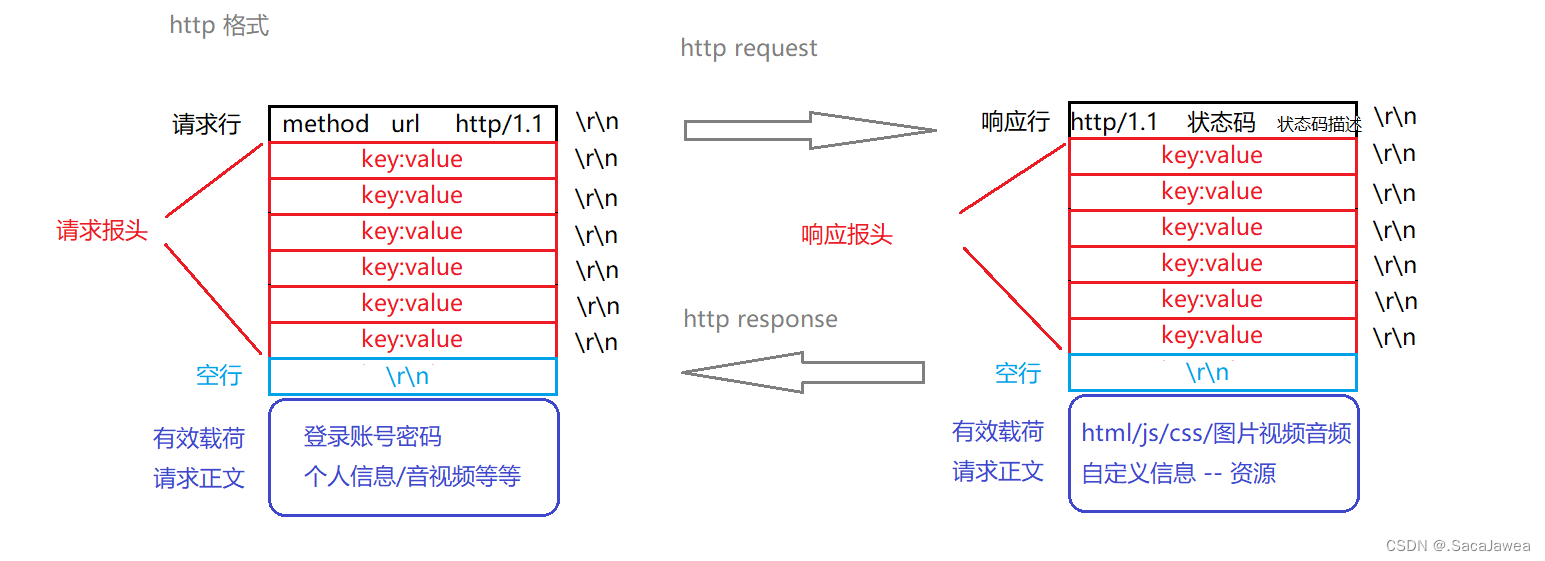
可以看到http协议格式使用\r\n作为不同字段的分隔符,以http请求为例,在第一个分隔符之前的数据就是http的请求行,里面含有
method:具体http请求的方法,如GET,POST
url:刚才说过的,url用来定位具体资源
http/1.1:http协议的版本
在第一行,请求行之后的字段就是请求报头,其中可能含有客户端主机的信息,连接的属性,有效载荷的长度等等信息,这些信息以key:value的格式保存在报头中,由于这些字段以\r\n分隔,所以可以直观的认为报头的每一行都是一对key:value信息。继续这样进行读取,我们会遇到一个空行,也就是说在报头的最后一个key:value后会有两个\r\n,前一个\r\n用来分隔最后的key:value字段,那么后一个key:value是用来划分有效载荷与报头的,读取http请求时,如果遇到了一个空行,就说明接下来的数据是这次请求的有效载荷了。客户端的请求无非两种,一是请求获取服务端的资源,二是请求将客户端的资源上传到服务端,这些信息都将在有效载荷中体现
至于服务端的响应,其格式与客户端的请求几乎相同,都是三个字段:响应行,响应报头,有效载荷。它们的分隔规则是一样的,不同的是响应行中的数据
http/1.1 状态码 状态码描述
可以看到请求和响应都含有协议的具体版本信息,这样做的目的是:为了使通信能够正常进行,通信双方要保证通信协议版本的一致性,所以客户端和服务端互相发送http协议的版本,如果两者的版本不同,将按照:以较低版本进行通信的原则,进行协议的调整。响应行还包括了状态码和其描述,通常我们请求的网页都是能正常访问的,但是也会有错误情况出现,错误码就表征了请求中的错误,最常见到的错误码就是404,如果你要访问的服务端资源不存在,那么服务端的状态码将被设置为404
GET vs POST
http协议中有很多方法:GET,POST,PUT,DELETE,OPTIONS…其中最经常使用的方法是GET,POST,至于其他方法就较为少见了,如果遇到就现学吧。这里主要说明GET和POST的区别,其中的依据来自
HTTP 方法:GET 对比 POST。首先,GET和POST都是明文传送,两者都是不安全的,使用这两个方法时,我们的数据总是在网络上裸奔,只是方式不同罢了
(在之前的博客中,我搭建了一个TCP网络通信模型,由于http协议是基于tcp的,所以我这里就直接改造这个模型,实现一份服务端代码,对浏览器(客户端)的请求做出响应)
#include <iostream>
#include <string>
#include <stdlib.h>
#include <fstream>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
using namespace std;
#define CRLF "\r\n"
#define HOME_PAGE "index.html"
#define ROOT_PAGE "wwwroot"
#define SPACE " "
string getPath(const string& req)
{
// 请求行的获取
size_t head_pos = req.find(CRLF);
if (head_pos == string::npos)
return "";
string head = req.substr(0, head_pos);
// 资源路径的获取
size_t path_start = head.find(SPACE);
size_t path_end = head.rfind(SPACE);
if (path_start == string::npos || path_end == string::npos)
return "";
// 获取资源地址
string path = head.substr(path_start + 1, path_end - path_start - 1);
// 如果地址为/,默认访问家目录
if (path[0] == '/' && path.size() == 1) path += HOME_PAGE;
return path;
}
string readFile(const string& path)
{
ifstream file(path);
if (!file.is_open()) return "404";
// 将资源的所有数据返回
string line;
string content;
// 读取整份文件的内容
while (file.peek() != EOF)
{
getline(file, line);
content += line;
}
return content;
}
// 先获取请求报头中的资源位置
// 读取该资源,将其返回
void handlerRequest(int sock)
{
char buf[10240] = {0};
ssize_t r_ret = read(sock, buf, sizeof(buf));
if (r_ret < 0)
cout << "read fail" << endl;
else if (r_ret == 0)
cout << "client quit" << endl;
// 读取成功
else
{
string req_str = buf;
// for test
cout << req_str << endl;
// 获取请求行中的资源
string path = getPath(req_str);
// 读取客户请求的资源,当前根路径的保存
string resource_path = ROOT_PAGE;
resource_path += path;
// 获取文件资源
string resource = readFile(resource_path);
string suffix = "";
// 获取文件的后缀
size_t suffix_pos = resource_path.rfind('.');
if (suffix_pos != string::npos)
suffix = resource_path.substr(suffix_pos);
// 创建响应
string response = "HTTP/1.1 200 OK\r\n";
// 根据后缀为响应报头添加不同字段
if (suffix == ".jpg") response += "Content-type: image/jpeg\r\n";
else response += "Content-type: text/html\r\n";
// 请求正文长度字段的添加
response += ("Content-Length: " + to_string(resource.size()) + "\r\n");
response += "\r\n";
// 响应正文
response += resource;
// 向客户端发送响应
write(sock, response.c_str(), response.size());
}
}
class tcpServer
{
public:
tcpServer(uint16_t port, std::string ip = "") : _ip(ip), _port(port) {}
~tcpServer() {}
void init()
{
// 创建套接字文件
_listen_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (_listen_sockfd < 0)
{
std::cerr << "socket: fail" << std::endl;
exit(-1);
}
// 填充套接字信息
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(_port);
_ip.empty() ? local.sin_addr.s_addr = INADDR_ANY : inet_aton(_ip.c_str(), &local.sin_addr);
// 将信息绑定到套接字文件中
if (bind(_listen_sockfd, (const struct sockaddr *)&local, sizeof(local)) < 0)
{
std::cerr << "bind: fail" << std::endl;
exit(-1);
}
// 至此,套接字创建完成,所有的步骤与udp通信一样
// 使套接字进入监听状态
if (listen(_listen_sockfd, 5) < 0)
{
std::cerr << "listen: fail" << std::endl;
exit(-1);
}
// 套接字初始化完成
std::cout << "listen done" << std::endl;
}
void loop()
{
// signal(SIGCHLD, SIG_IGN); // 设置SIGCHLD信号为忽略,这样子进程就会自动释放资源
// 创建保存套接字信息的结构体
struct sockaddr_in peer;
socklen_t peer_len = sizeof(peer);
// 接受监听队列中的套接字请求
while (true)
{
int server_sockfd = accept(_listen_sockfd, (struct sockaddr *)&peer, &peer_len);
if (server_sockfd < 0)
{
std::cerr << "accept: fail" << std::endl;
continue;
}
std::cout << "accept done" << std::endl;
// 提取请求方的套接字信息
uint16_t peer_port = ntohs(peer.sin_port);
std::string peer_ip = inet_ntoa(peer.sin_addr);
// 打印请求方的套接字信息
std::cout << "accept: " << peer_ip << " [" << peer_port << "]" << std::endl;
// 使用孙子进程提供服务
// grandparent
pid_t id = fork();
// 祖父进程
if (id == 0)
{
// 父进程
pid_t cid = fork();
if (cid > 0)
{
// 关闭父进程
exit(1);
}
// 孙子进程,孤儿,由1号进程管理
handlerRequest(server_sockfd);
}
// 阻塞的回收进程资源
waitpid(id, nullptr, 0);
}
}
private:
std::string _ip;
uint16_t _port;
int _listen_sockfd;
};
static void Usage(std::string proc)
{
std::cerr << "Usage:\n\t" << proc << " port" << std::endl;
std::cerr << "example:\n\t" << proc << " 8080\n"
<< std::endl;
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(0);
}
uint16_t port = atoi(argv[1]);
tcpServer svr(port);
svr.init();
svr.loop();
return 0;
}
tcp通信的部分就不再赘述了。为防止僵尸进程,该通信模型创建孙子进程为客户端提供服务,而退出子进程,使孙子进程成为孤儿进程,由1号进程负责其资源的释放。服务端接收到客户端的请求,会对该请求进行解析,得到请求需要的资源路径,服务端会将该资源返回给客户端。下面这份网页就是服务端默认返回给用户的资源
<!-- index.html -->
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>测试</title>
</head>
<body>
<h3>hello my server!</h3>
<p>我终于测试完了我的代码</p>
<form action="/a/b/c.html" method="get">
Username: <input type="text" name="user"><br>
Password: <input type="password" name="passwd"><br>
<input type="submit" value="Submit">
</form>
</body>
</html>
这个网页中有一个表单,客户可以提交它们的用户名和密码信息,其中action标签表示将这些信息发送到指定网页上(当然是客户端再向服务端发送一次请求了),为了测试简单,这里将信息发送到一个不存在的网页中,我们只观察GET和POST的区别。
注意,服务端接收到客户端的请求后,会将客户端的请求打印出来,方便我们的测试,在浏览器的url中输入IP:port,访问服务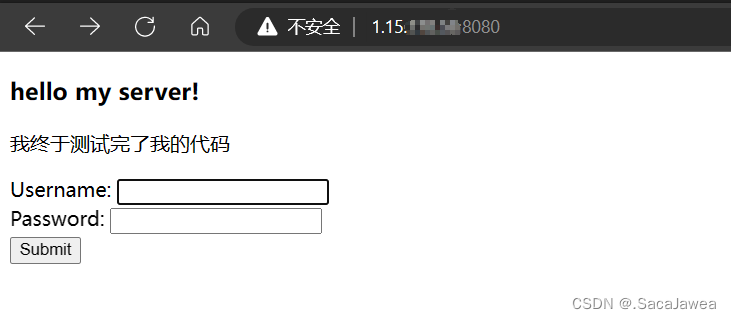
我们输入用户名123,密码456,点击submit按钮,这些数据会被发送到action指定的网页上,并且方法是get
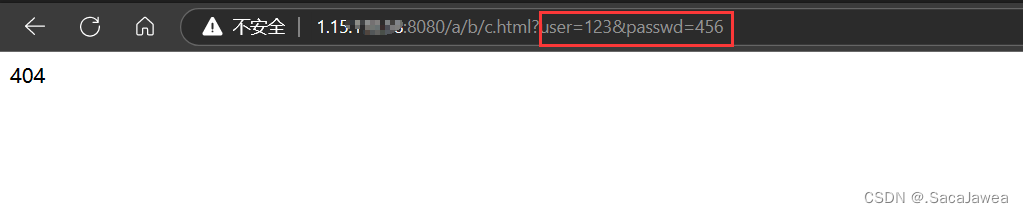
很正常,因为网页不存在,所以返回404。但是我们注意到,输入的用户名和密码在url中以查询字符串的方式显示了出来。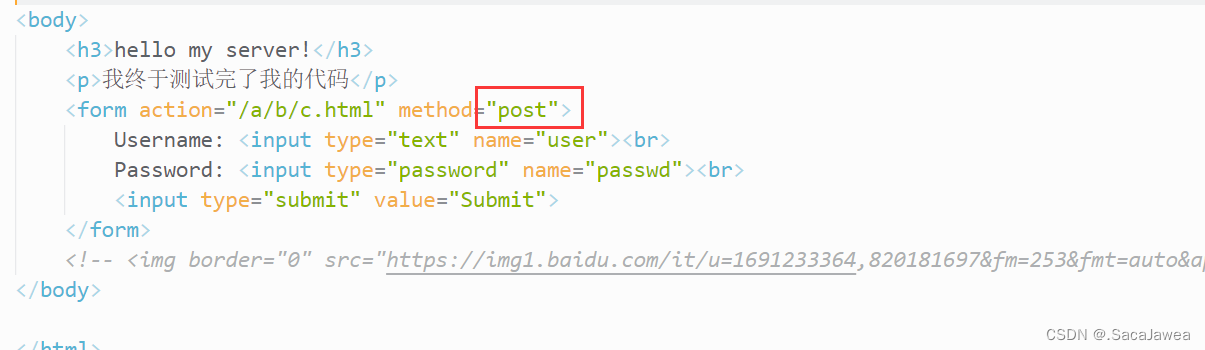
将网页提交数据的方式修改为post,重新运行服务,重新连接到该服务,输入用户名密码,submit


可以看到,用户名和密码没有在url中体现,观察服务端打印的客户端请求,可以看到这些信息出现在请求的正文部分。
总结一下:GET将数据以查询字符串的方式拼接到url中,而POST将数据以正文的方式置于请求中,两者都是明文传输,不同的只是POST较GET更隐蔽一些,但两者在本质上都是不安全的。
http状态码
| 1xx | 信息状态码Informational | 接收的请求正在处理,由于现在的网络响应快,这样的状态码很少使用了 |
|---|---|---|
| 2xx | 成功状态码Success | 请求正常处理完毕 |
| 3xx | 重定向状态码Redirection | 将请求重定向到其他资源上 |
| 4xx | 客户端错误状态码Client Error | 服务器无法处理请求,请求非法 |
| 5xx | 服务端错误状态码Server Error | 服务端运行出错 |
这些状态码也不需要具体记忆,记住几个常用的就行了,比如200(OK),404(Not Found),403(Forbidden),302(Redirect),504(Bad Gateway,服务器访问上游服务器超时)
void for_redirection(int sock)
{
char buf[10240] = {0};
ssize_t r_ret = read(sock, buf, sizeof(buf));
if (r_ret < 0)
cout << "read fail" << endl;
else if (r_ret == 0)
cout << "client quit" << endl;
// 读取成功
else
{
string req_str = buf;
// 创建响应
string response = "HTTP/1.1 302 Moved Temporarily\r\n";
// 请求正文长度字段的添加
response += "location: https://baike.baidu.com/item/302/878045?fr=aladdin\r\n";
response += "\r\n";
// 向客户端发送响应
write(sock, response.c_str(), response.size());
}
}
简单的,将服务端的响应修改,请求行修改为"HTTP/1.1 302 Moved Temporarily\r\n",然后在报头中添加location字段,表示重定向的url,如果服务端只提供以上服务的话,不论客户端向服务端发送什么,客户端都将跳转到location字段的url上。不过关于301和302的区别还是要注意一下的,301是当前资源的永久性转移,而302是资源的临时性转移。如果收藏夹中,有一个url301了,浏览器可能会将该url修改为新的url,而302就不会
http常见header
Content-type:正文数据类型(html/text,image/jpeg)
Content-Length:正文长度
Host:告知服务端,客户端要访问的资源在哪台主机上
User-Agenr:声明用户的操作系统和浏览器版本信息
referer:当前页面是从哪个页面跳转过来了
location:配合3xx使用,指定重定向的url,客户端将访问该url
Cookie:存储用户一些数据,用来进行会话的维持
header就是http中的报头字段,以上展示的是字段中的key,每一字段以key:value的方式呈现
最后还剩一个值得讲解的header:Connection,http1.0的Connection默认为closed,http1.1的Connection默认为keep-alive,一个为短连接一个为长连接。在互联网发展早期,网页中的信息没有现在这么的密集,一次http请求就可以获取完整的网页并呈现给客户。但是随着互联网的发展,网页中的信息越来越多,越来越复杂,所以一次http协议无法获取完整的网页,而http是基于tcp通信的,多次http请求就代表这多次tcp的连接,这样的做法势必会导致网页加载速度的下降,由此http/1.1默认开启长连接,只有一个网页的资源请求完成,tcp连接才会关闭。关于长连接的深入学习,具体实现可以阅读这篇博客
cookie + session
http有一个特性:无状态,即无法进行状态的保持,每一次请求都是独立的。但在网页端浏览b站时,登录账号过后,每次访问b站都会保持你的登录信息,其中的原理就与cookie有关
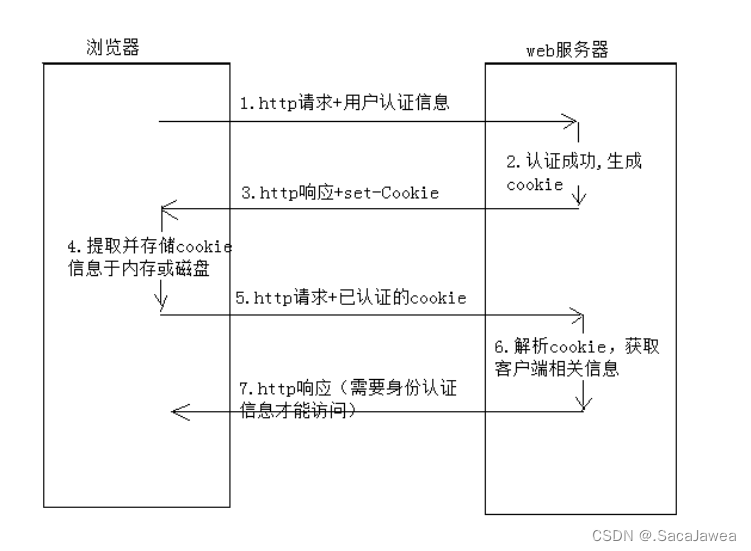
(上图来自网络)当然了,首次登录b站时,你还是需要输入你的账号密码的,一旦选择登录,浏览器就会将你的用户信息通过http协议传输到b站的服务端,服务端认证成功,确认该账号是有效的之后,会生成一个cookie文件,并发送一个set-Cookie的响应,使客户端在磁盘或者内存上保持该cookie文件。之后客户端的http请求就会携带这份cookie文件,服务端收到cookie文件后进行解析,得到有效数据认证成功之后,才会将特定的响应返回给客户端,此时客户端看到的网页就是已经登陆账号的网页了。
如果cookie存储在磁盘上,那么关闭浏览器,甚至关机之后再打开该网页,你的账号登录信息依旧能保持,因为cookie文件在磁盘上,除非你直接删除,否则该文件会一直存在。但是cookie文件存储在内存(浏览器)中时,关闭了浏览器(注意不是关闭网页),浏览器的进程资源被释放,属于浏览器资源的cookie文件当然也被释放,此时再打开浏览器,登录信息就无法保持。如果只是把网站关闭,浏览器没关闭,再打开该网站,登录信息依旧是能保存的,因为cookie文件没有被释放。
但由于安全性的问题,将cookie文件存储在客户端的做法。因为客户端容易遭到攻击,或者说信息容易泄漏,如果cookie被非法窃取,cookie所有者的权益将会受到损害。所以现在主流的策略都是cookie+session,将cookie文件存储在服务端(Linux系统安全性极高)。其主要实现是:客户端提交登录信息,服务端接收后在后台数据库上将这些信息存储起来,然后生成一个唯一的id,这个id可以理解为key,数据库中存储的信息可以理解为value,这就是一对key:value模型。服务端将id返回给客户端,使客户端set-Cookie,将该id值保存起来,此后客户端的http请求都会带上该id值,服务端收到id后,找到其对应value,就能解析出客户的信息,也就能根据这些信息进行会话保持了。
但是cookie+session的方式同样是不安全的,id值同样可以被窃取,被非法利用。但是被窃取的只是一个id值,你的具体信息没有得到泄漏,具体信息存储在服务端的数据库中,要攻击这样的数据库还是比较难的。这也是相对直接使用cookie的优势吧,或者这么说,http协议就是不安全的,它的目的是通信的进行,侧重于通信的实现,至于安不安全就是另外一回事了,因此不推荐用http进行私密数据的传输,要进行这样的传输可以使用更侧重安全性的https协议