街景门牌号数据集(SVHN),这是一个现实世界数据集,用于开发目标检测算法。它需要最少的数据预处理过程。它与 MNIST 数据集有些类似,但是有着更多的标注数据(超过 600,000 张图像)。这些数据是从谷歌街景中的房屋门牌号中收集而来的。
大小:2.5GB
数量:6,30,420 张图像,共 10 类
The Street View House Numbers (SVHN) Dataset:下载地址
1、数据集概述
- 10 个类别,每个数字 1 个。数字“1”的标签为 1,“9”的标签为 9,“0”的标签为 10。
- 73257 个数字用于训练,26032 个数字用于测试,以及 531131 个额外的、难度稍低的样本,用作额外的训练数据
- 有两种格式:
1. 带有字符级边界框的原始图像。
2. 以单个字符为中心的类似 MNIST 的 32×32 图像(许多图像确实在侧面包含一些干扰项)。
2、数据集两种方式
(半监督学习中采用这种方式)方式一:完整数字: train.tar.gz , test.tar.gz , extra.tar.gz
原生的数据集1也就是官网的 Format 1 是一些原始的未经处理的彩色图片,如下图所示(不含有蓝色的边框),下载的数据集含有 PNG 的图像和 digitStruct.mat 的文件,其中包含了边框的位置信息,这个数据集每张图片上有好几个数字,适用于 OCR 相关方向。这里采用 Format2, Format2 将这些数字裁剪成32x32的大小,如图所示,并且数据是 .mat 文件。
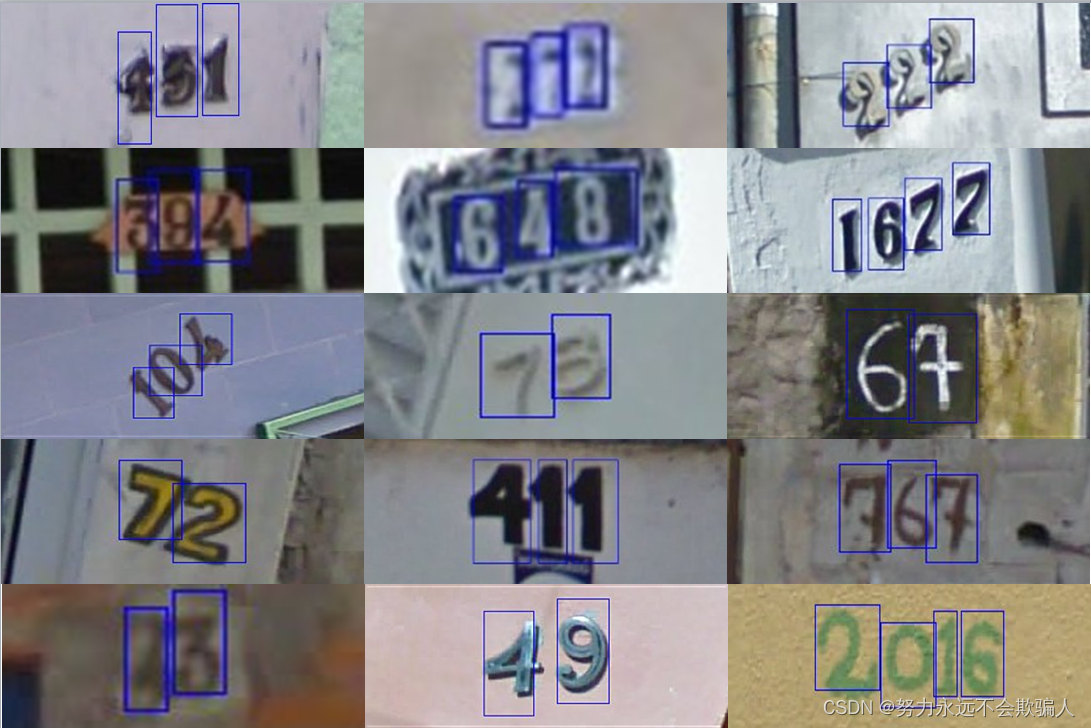
这些是带有字符级别边界框的原始可变分辨率彩色门牌号图像,如上面的示例图像所示。(这里的蓝色边界框只是为了说明目的。边界框信息存储在digitStruct.mat中,而不是直接绘制在数据集中的图像上。)每个 tar.gz 文件包含 png 格式的原始图像,以及一个digitStruct.mat 文件,可以使用 Matlab 加载。digitStruct.mat 文件包含一个名为digitStruct的结构,其长度与原始图像的数量相同。digitStruct 中的每个元素都有以下字段:name是一个包含相应图像文件名的字符串。 bbox这是一个结构数组,包含图像中每个数字边界框的位置、大小和标签。例如:digitStruct(300).bbox(2).height给出第 300 个图像中第 2 个数字边界框的高度。
方式二:裁剪的数字 train_32x32.mat , test_32x32.mat , extra_32x32.mat
以类似 MNIST 的格式表示的字符级基本事实。所有数字都已调整为 32 x 32 像素的固定分辨率。原始字符边界框在适当的维度上扩展成为方形窗口,因此将它们调整为 32×32 像素不会引入纵横比失真。然而,这种预处理在感兴趣数字的两侧引入了一些分散注意力的数字。加载 .mat 文件会创建 2 个变量:X是包含图像的 4 维矩阵,y是类标签的向量。要访问图像,X(:,:,:,i)给出第 i 个 32×32 RGB 图像,类标签为y(i)。
3.数据处理
数据集含有两个变量 X 代表图像, 训练集 X 的 shape 是 (32,32,3,73257) 也就是(width, height, channels, samples), tensorflow 的张量需要 (samples, width, height, channels),所以需要转换一下,由于直接调用 cifar 10 的网络模型,数据只需要先做个归一化,所有像素除于255就 OK,另外原始数据 0 的标签是 10,这里要转化成 0,并提供 one_hot 编码。
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 19 09:55:36 2017
@author: cheers
"""
import scipy.io as sio
import matplotlib.pyplot as plt
import numpy as np
image_size = 32
num_labels = 10
def display_data():
print 'loading Matlab data...'
train = sio.loadmat('train_32x32.mat')
data=train['X']
label=train['y']
for i in range(10):
plt.subplot(2,5,i+1)
plt.title(label[i][0])
plt.imshow(data[...,i])
plt.axis('off')
plt.show()
def load_data(one_hot = False):
train = sio.loadmat('train_32x32.mat')
test = sio.loadmat('test_32x32.mat')
train_data=train['X']
train_label=train['y']
test_data=test['X']
test_label=test['y']
train_data = np.swapaxes(train_data, 0, 3)
train_data = np.swapaxes(train_data, 2, 3)
train_data = np.swapaxes(train_data, 1, 2)
test_data = np.swapaxes(test_data, 0, 3)
test_data = np.swapaxes(test_data, 2, 3)
test_data = np.swapaxes(test_data, 1, 2)
test_data = test_data / 255.
train_data =train_data / 255.
for i in range(train_label.shape[0]):
if train_label[i][0] == 10:
train_label[i][0] = 0
for i in range(test_label.shape[0]):
if test_label[i][0] == 10:
test_label[i][0] = 0
if one_hot:
train_label = (np.arange(num_labels) == train_label[:,]).astype(np.float32)
test_label = (np.arange(num_labels) == test_label[:,]).astype(np.float32)
return train_data,train_label, test_data,test_label
if __name__ == '__main__':
load_data(one_hot = True)
display_data()3、TFearn 训练
注意 ImagePreprocessing 对数据做了 0 均值化。网络结构也比较简单,直接调用 TFlearn 的 cifar10 例子。
from __future__ import division, print_function, absolute_import
import tflearn
from tflearn.data_utils import shuffle, to_categorical
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
from tflearn.data_preprocessing import ImagePreprocessing
from tflearn.data_augmentation import ImageAugmentation
# Data loading and preprocessing
import svhn_data as SVHN
X, Y, X_test, Y_test = SVHN.load_data(one_hot = True)
X, Y = shuffle(X, Y)
# Real-time data preprocessing
img_prep = ImagePreprocessing()
img_prep.add_featurewise_zero_center()
img_prep.add_featurewise_stdnorm()
# Convolutional network building
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep)
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='relu')
network = dropout(network, 0.5)
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.001)
# Train using classifier
model = tflearn.DNN(network, tensorboard_verbose=0)
model.fit(X, Y, n_epoch=15, shuffle=True, validation_set=(X_test, Y_test),
show_metric=True, batch_size=96, run_id='svhn_cnn')训练结果:
Training Step: 11452 | total loss: 0.68217 | time: 7.973s
| Adam | epoch: 015 | loss: 0.68217 - acc: 0.9329 -- iter: 72576/73257
Training Step: 11453 | total loss: 0.62980 | time: 7.983s
| Adam | epoch: 015 | loss: 0.62980 - acc: 0.9354 -- iter: 72672/73257
Training Step: 11454 | total loss: 0.58649 | time: 7.994s
| Adam | epoch: 015 | loss: 0.58649 - acc: 0.9356 -- iter: 72768/73257
Training Step: 11455 | total loss: 0.53254 | time: 8.005s
| Adam | epoch: 015 | loss: 0.53254 - acc: 0.9421 -- iter: 72864/73257
Training Step: 11456 | total loss: 0.49179 | time: 8.016s
| Adam | epoch: 015 | loss: 0.49179 - acc: 0.9416 -- iter: 72960/73257
Training Step: 11457 | total loss: 0.45679 | time: 8.027s
| Adam | epoch: 015 | loss: 0.45679 - acc: 0.9433 -- iter: 73056/73257
Training Step: 11458 | total loss: 0.42026 | time: 8.038s
| Adam | epoch: 015 | loss: 0.42026 - acc: 0.9469 -- iter: 73152/73257
Training Step: 11459 | total loss: 0.38929 | time: 8.049s
| Adam | epoch: 015 | loss: 0.38929 - acc: 0.9491 -- iter: 73248/73257
Training Step: 11460 | total loss: 0.35542 | time: 9.928s
| Adam | epoch: 015 | loss: 0.35542 - acc: 0.9542 | val_loss: 0.40315 - val_acc: 0.9085 -- iter: 73257/73257





![【项目设计】高并发内存池(一)[项目介绍|内存池介绍|定长内存池的实现]](https://img-blog.csdnimg.cn/082dab52de4a46318aaf6171d621ac38.png)
![[visual studio]中,关于如何 【调试】 的问题 及 技巧](https://img-blog.csdnimg.cn/53a204b4930048f0bba9157ec670403d.png)


