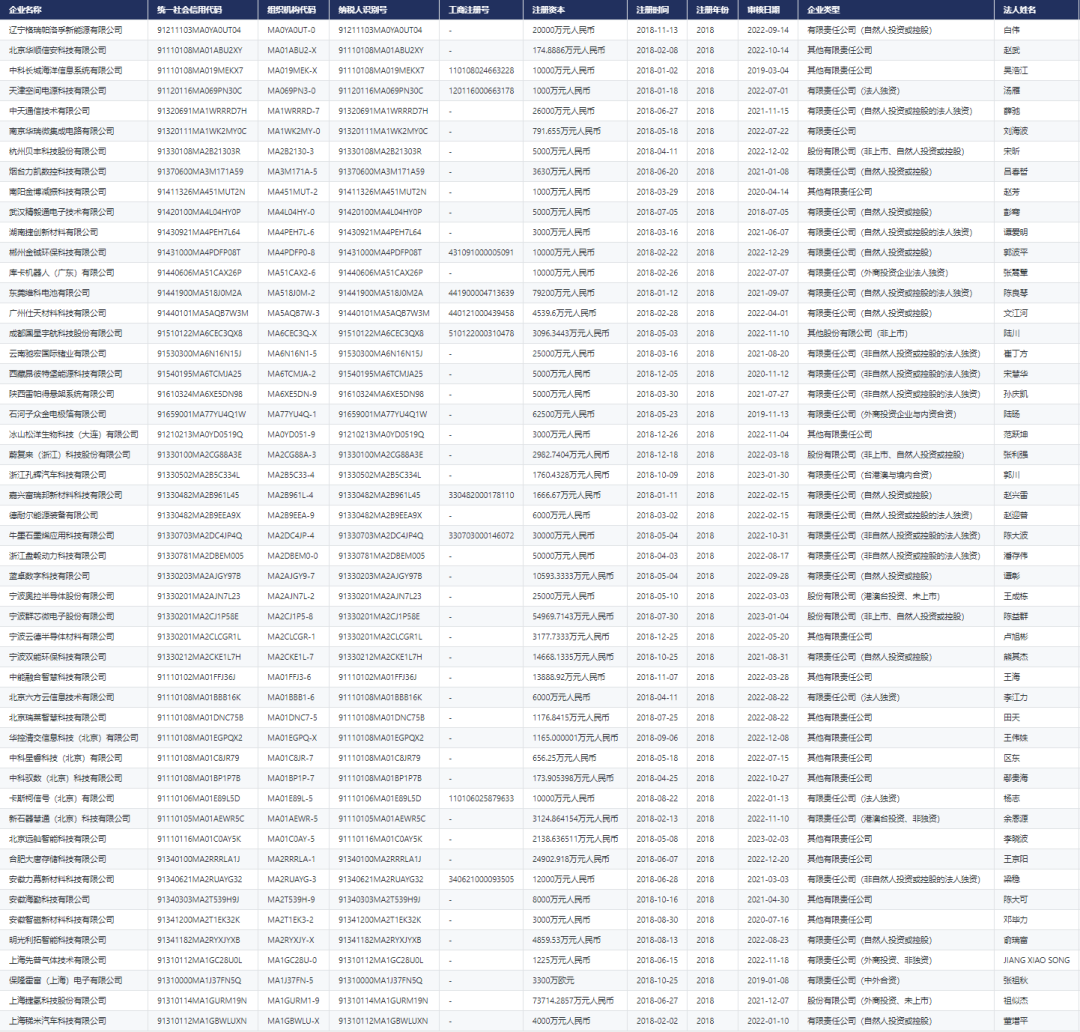
这里写自定义目录标题
- 写在前面
- 23.2.19
- 报错`Unable to allocate xxx GiB for an array with shape (xxxx, xxxx)`
- 23.2.20
- psi6图片绘制
- 选择了部分r,绘制了g6(r)
- 23.2.21
- 从lammpstrj文件中导出了1001X6个csv文件
- 虚拟内存扩展
- 代码运行占用资源查询
写在前面
好好学习,走出宿舍,走向毕设!
一些心路历程记录,很少有代码出现
因为鬼知道哪条代码到时候变成毕设的一部分了咧,还是不要给自己的查重挖坑罢了
23.2.19
报错Unable to allocate xxx GiB for an array with shape (xxxx, xxxx)
看到一长串报错的时候,直接拉到最后、、、我就知道,md内存不够咯

解决办法:夺命狂删C盘内存,卸载了很多软件,清理了QQ和微信的缓存,不然这代码运行不出来了QwQ
后期经过实测,代码使用spyder无法运行,虚拟缓存超过了上限,必须用jupyter notebook拆开来慢慢运行
实际运行过程中,C盘显示占用内存最高约为12GB
附上一条抄来的检查内存的代码和结果:
import psutil
import os
info = psutil.virtual_memory()
print('内存使用:',psutil.Process(os.getpid()).memory_info().rss)
print('总内存:',info.total)
print('内存占比:',info.percent)
print('CPU个数:',psutil.cpu_count())

23.2.20
psi6图片绘制
绘制了6个温度条件下第一帧的psi6,以定性查看其晶体的状态【固态or液态】
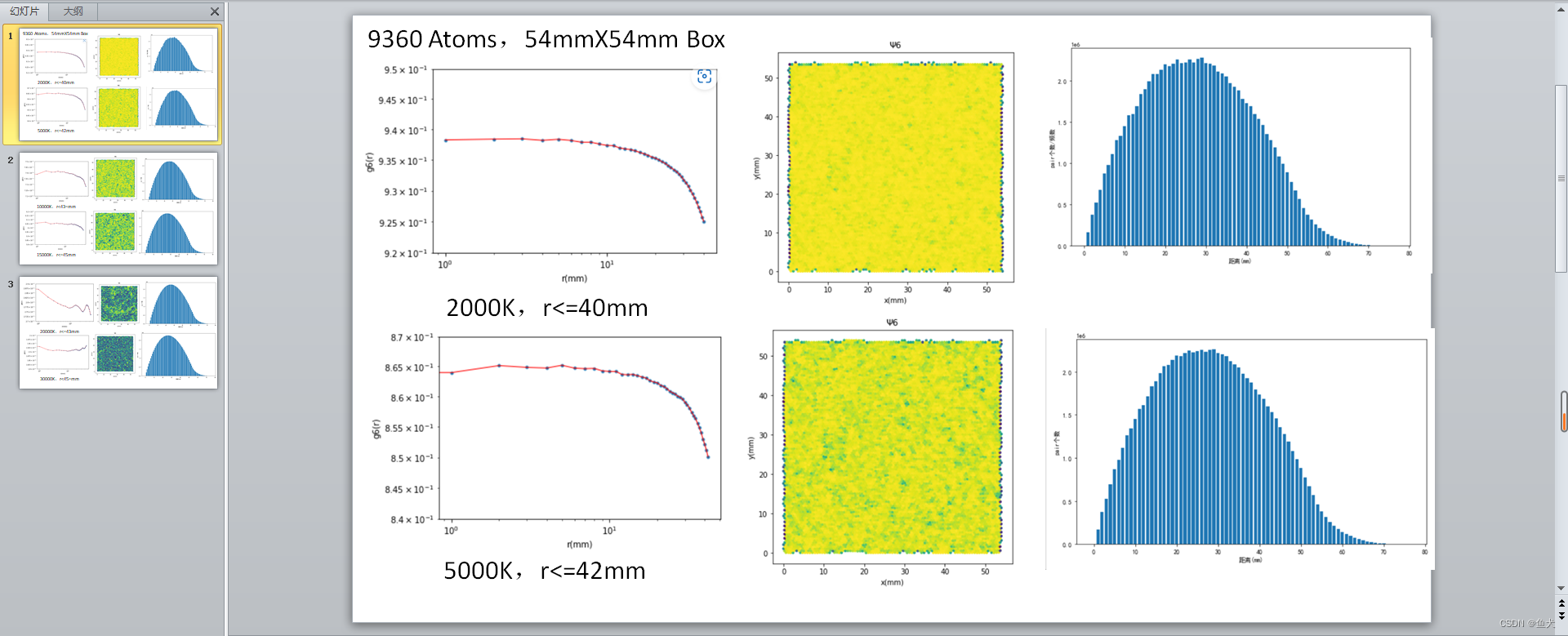
选择了部分r,绘制了g6(r)
问题1:需要了解颗粒平均间距
做法:打出所有最近邻list,计算每个最近邻粒子间的距离,得出平均值
问题2:样本数据量过小
做法:将一次模拟的全部帧数放入其中,算出平均值
23.2.21
从lammpstrj文件中导出了1001X6个csv文件
import pandas as pd
#导入所需包
f = open("D:\\2D melt\\30000.lammpstrj","r")
data = []
for line in f.readlines():
line = line.strip("\n")
line = line.split()
data.append(line)
f.close()
for i in range(0,1001):
l = data[9360*i+9*(i+1):9360*(i+1)+9*(i+1)]
name = ["id","type","x","y"]
newtable = pd.DataFrame(l,columns=name)
newtable.to_csv("D:\\221115\\30000.csv",index=False)
csv1 = pd.read_csv("D:\\221115\\30000.csv")
csv2 = csv1.sort_values("id")
csv2.to_csv("D:\\230220\\30000\\30000_sorted"+str(i)+".csv",index=False)
虚拟内存扩展
根据CSDN上的指引,进行如图所示操作
1、打开 控制面板

2、找到 系统 这一项;
3、找到 高级系统设置 这一项;
4、点击 性能 模块的 设置 按钮;

5、选择 高级,在 虚拟内存 模块点击更改;

6、选择一个你文件运行的磁盘,点击自定义大小
记得 不要 选中“自动管理所有驱动器的分页文件大小”,手动输入初始大小和最大值,当然,最好不要太大,更改之后能在查看盘的使用情况,不要丢掉太多空间。


7、都设置好之后,记得点击 “设置”, 然后再确定,否则无效,最后 重启电脑 就可以了。(一开始我没有重启电脑,还是跑不动,一度怀疑自己的硬件问题。)

代码运行占用资源查询
运用了和鲸平台,因此我知道了我代码运行时候占用的内存、CPU的占用情况,因此可以将其作为判断我的电脑是否需要加装内存条的依据

结论就是、、、要装,装两根~