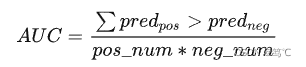LDBC benchmark
这是官方文档
https://ldbcouncil.org/ldbc_snb_docs/ldbc-snb-specification.pdf
主要有几点
-
Scale Factors
是生成数据的一个大小,For both workloads, the SF1 data set is 1 GiB, the SF100 is 100 GiB, and the SF10 000 data set is 10 000 GiB (not 10 TiB).
下面是可用的参数
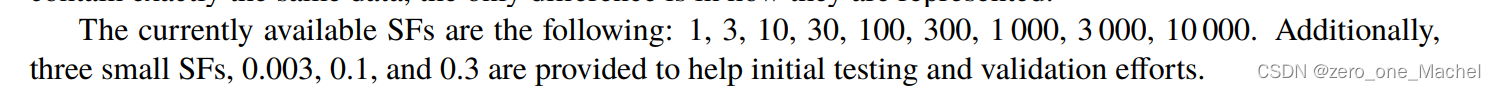
数据集的组成,分为静态和动态的数据,因为有一些数据需要在数据库启动以后执行插入操作添加数据(dynamic),大部分是一开始批导入(static)
-
two SNB workloads
可以生成两种工作负载,一个是Interactive,另一个是BI(商业智能)。相同的Scale Factors生成的数据集数据完全相同,只是表示不同。(It is important to note that for a given workload and scale factor, data sets generated using different serializers contain exactly the same data, the only difference is in how they are represented)
Nebula -bench
NebulaGraph Bench 用于测试 NebulaGraph 的基线性能数据,使用 LDBC v0.3.3 的标准数据集。
主要功能:
- 生产 LDBC 数据集并导入 NebulaGraph。
- 用 k6 进行压测。
参考github官方说明
1. 安装一些库
ubuntu执行下面(centos看前面github链接)
sudo apt-get install -y \
git \
wget \
python3-pip \
python \
openjdk-8-jdk \
maven
export JAVA_HOME=/usr/lib/jvm/default-java/
2. 安装go
go官方安装教程
注意 环境配置
export PATH=$PATH:/usr/local/go/bin
这个每次bush关掉都要重新执行,下面可以每次开机自动配置
echo "export PATH=$PATH:/usr/local/go/bin" >> ~/.bashrc
tail -3 ~/.bashrc //查看是否修改,其实就是查看~/.bashrc的最后三行
source ~/.bashrc //重新加载
最后通过go version 查看是否安装成功
3. 下载编译Nebula-bench
git clone https://github.com/vesoft-inc/nebula-bench.git
cd nebula-bench
pip3 install --user -r requirements.txt
python3 run.py --help
4. 编译安装两个工具

nebula-importer:是将LDBC数据导入到nebula的
xk6-nebula:是后面压测的工具
可以自己分别安装,在github链接安装即可,但是Nebula-bench里面有安装的脚本
cd nebula-bench //进入刚才下载的nebula-bench
/bin/bash scripts/setup.sh //执行脚本自动安装nebula-importer和xk6-nebula,如果你的网很慢可能会失败,那可以自己安装这两个工具
如果 go get 的包下载不下来,需要设置 golang 代理。
export GOPROXY=https://goproxy.cn
5.生成数据
生成的是sf10的数据,就是10Gib的数据
# generate sf10 ldbc data
python3 run.py data -s 10
6.导入数据
python3 run.py nebula importer
上面这个语句会做两件事。
一是会根据 header 文件,自动生成 importer 的配置文件。
二是运行 importer 导入数据
所以会看到命令运行结束后会生成一个importer_config.yaml 的文件和数据
下面是生成的数据

但是导入数据可能失败,因为nebula-bench本来生成的yaml配置文件是适合三个nebula-storaged的,即三台服务器的,但是我只有一台
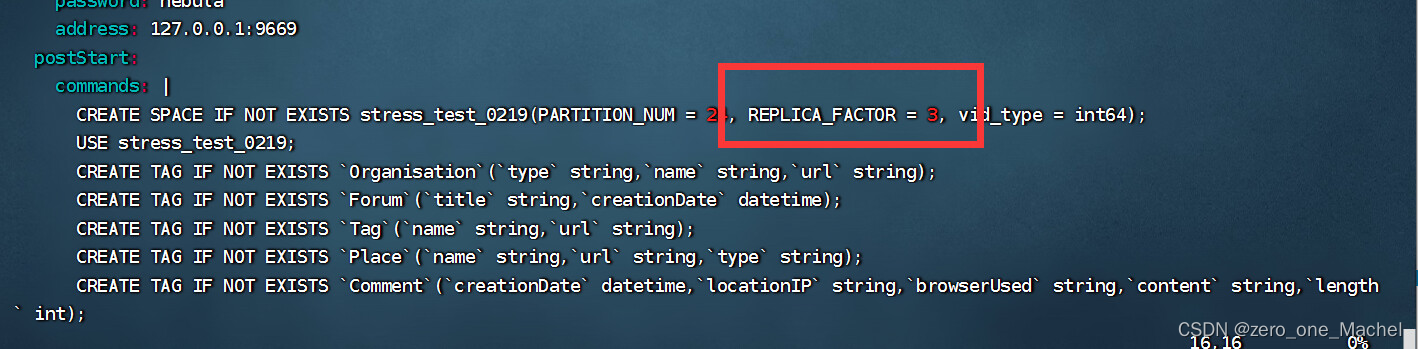
所以要把这个地方改为1,就可以导入数据了
也可以看一下这个链接https://discuss.nebula-graph.com.cn/t/topic/12210
7. 压测
使用带有 xk6-nebula 插件的 K6 来进行压测。
自动化的场景,在 nebula_bench/scenarios/ 中。
# run all scenarios with 10 virtual users, every scenario lasts 3 seconds.
python3 run.py stress run --args='-u 10 -d 3s'
注意
- 结合https://github.com/dutor/nebula-bench/blob/master/README_cn.md这恶鬼去看
- 有问题可以在评论问我,一起讨论
![[element plus] 对话框组件再封装使用 - vue](https://img-blog.csdnimg.cn/50039c98df4a4de7ba40b99f4fc40191.png)