复现BERT:
只能说爷今天干了一上午一下午的代码
bert的输入: batch_size * max_len * emb_num @768 * 768 bert的输出:三维字符级别特征(NER可能就更适合) 二维篇章级别特征(比如文本分类可能就更适合) batch_size * max_len * emb_num, batch_size * emb_num
绝对位置编码
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
import pandas as pd
import sklearn
import random
import numpy as np
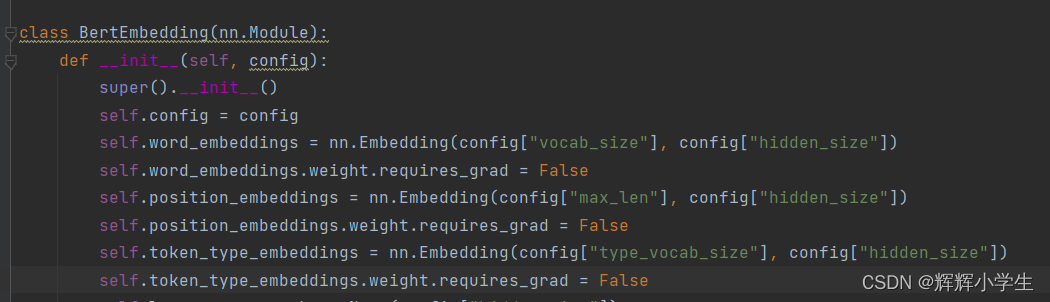
class BertEmbedding(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.word_embeddings = nn.Embedding(config["vocab_size"], config["hidden_size"])
self.word_embeddings.weight.requires_grad = True
self.position_embeddings = nn.Embedding(config["max_len"], config["hidden_size"])
self.position_embeddings.weight.requires_grad = True
self.token_type_embeddings = nn.Embedding(config["type_vocab_size"], config["hidden_size"])
self.token_type_embeddings.weight.requires_grad = True
self.layernorm = nn.LayerNorm(config["hidden_size"])
self.dropout = nn.Dropout(config["hidden_dropout_pro"])
def forward(self, batch_index, batch_seg_idx):
word_emb = self.word_embeddings(batch_index)
pos_idx = torch.arange(0, self.position_embeddings.weight.data.shape[0])
pos_idx = pos_idx.repeat(self.config["batch_size"], 1)
pos_emb = self.position_embeddings(pos_idx)
token_emb = self.token_type_embeddings(batch_seg_idx)
emb = word_emb + pos_emb + token_emb
layer_norm_emb = self.layernorm(emb)
dropout_emb = self.dropout(layer_norm_emb)
return dropout_emb
class BertModel(nn.Module):
def __init__(self, config):
super().__init__()
self.embedding = BertEmbedding(config)
self.bert_layer = nn.Linear(config["hidden_size"], config["hidden_size"])
def forward(self, batch_index, batch_seg_idx):
emb = self.embedding(batch_index, batch_seg_idx)
bert_out1 = self.bert_layer(emb)
return bert_out1
class Model(nn.Module):
def __init__(self, config):
super().__init__()
self.bert = BertModel(config)#batch_size * max_len * emb_num @768 * 768 = batch_size * max_len * emb_num, batch_size * emb_num
self.cls_mask = nn.Linear(config["hidden_size"], config["vocab_size"])
self.cls_nsp = nn.Linear(config["hidden_size"], 2)
def forward(self, batch_index, batch_seg_idx):
bert_out = self.bert(batch_index, batch_seg_idx)
def get_data(file_path):
all_data = pd.read_csv(file_path)
all_data = sklearn.utils.shuffle(all_data)
t1 = all_data["text1"].tolist()
t2 = all_data["text2"].tolist()
l = all_data["label"].tolist()
return t1, t2, l
class BertDataset(Dataset):
def __init__(self, text1, text2, label, max_len, word_2_index):
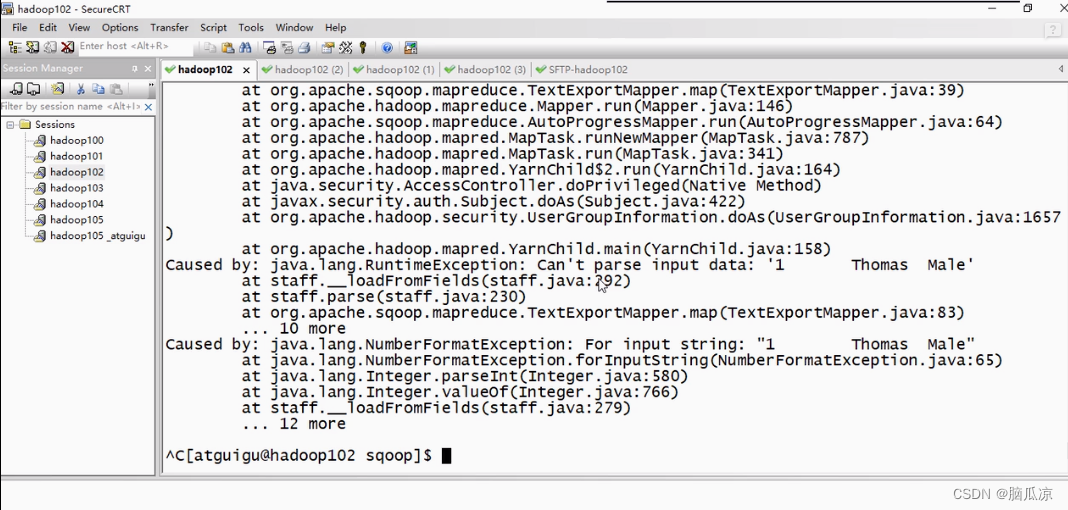
assert len(text1) == len(text2) == len(label), "NSP数据长度不一,复现个锤子!!!"
self.text1 = text1
self.text2 = text2
self.label = label
self.max_len = max_len
self.word_2_index = word_2_index
def __getitem__(self, index):
#mask_id = [0] * self.max_len
mask_v = [0] * self.max_len
text1 = self.text1[index]
text2 = self.text2[index]
label = self.label[index]
n = int((self.max_len-4) / 2)
text1_id = [self.word_2_index.get(i, self.word_2_index["[UNK]"]) for i in text1][:n]
text2_id = [self.word_2_index.get(i, self.word_2_index["[UNK]"]) for i in text2][:n]
#text = text1 + text2
text_id = [self.word_2_index["[CLS]"]] + text1_id + [self.word_2_index["[SEP]"]] + text2_id + [self.word_2_index["[SEP]"]]
segment_id = [0] + [0] * len(text1_id) + [0] + [1] * len(text2_id) + [1] + [2] * (self.max_len - len(text_id))
text_id = text_id + [self.word_2_index["[PAD]"]] * (self.max_len - len(text_id))
for i, v in enumerate(text_id):
if v in [self.word_2_index["[PAD]"], self.word_2_index["[SEP]"], self.word_2_index["[UNK]"]]:
continue
if random.random() < 0.15:
r = random.random()
if r < 0.8:
text_id[i] = self.word_2_index["[MASK]"]
mask_v[i] = v
elif r > 0.9:
text_id[i] = random.randint(6, len(self.word_2_index)-1)
mask_v[i] = v
return torch.tensor(text_id), torch.tensor(label), torch.tensor(mask_v), torch.tensor(segment_id)
def __len__(self):
return len(self.text1)
if __name__ == "__main__":
text1, text2, label = get_data("..//self_bert//data//self_task2.csv")
epoch = 1024
batch_size = 32
max_len = 256
with open("..//self_bert//data//index_2_word.text", "r", encoding="utf-8") as f:
index_2_word = f.read().split("\n")
word_2_index = {word: index for index, word in enumerate(index_2_word)}
config ={
"epoch": epoch,
"batch_size": batch_size,
"max_len": max_len,
"vocab_size": len(word_2_index),
"hidden_size": 768,
"type_vocab_size": 3,
"hidden_dropout_pro": 0.2,
}
train_dataset = BertDataset(text1, text2, label, max_len, word_2_index)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False)
model = Model(config)
for e in range(epoch):
print(f"here is the {e}th epoch")
for batch_text_index, batch_text_label, batch_mask_value , batch_segment_id in train_dataloader:
model.forward(batch_text_index, batch_segment_id)
回家看看花书,也许还会谢谢代码,结束!