思维导图
常见知识点
1.mysql存储引擎:
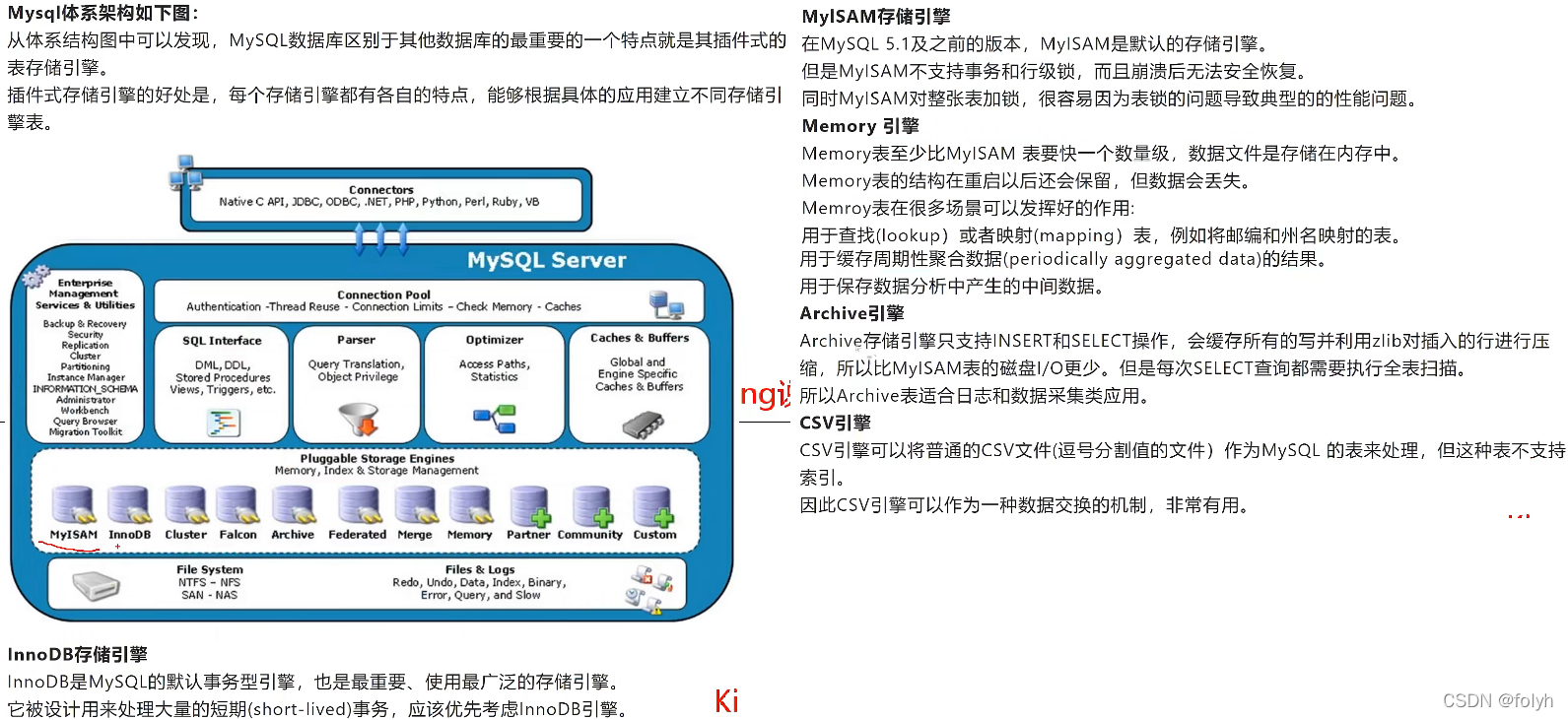
2.innodb与myisam区别:

3.表设计字段选择:

4.mysql的varchar(M)最多存储数据:

5.事务基本特性:

6.事务并发引发问题:

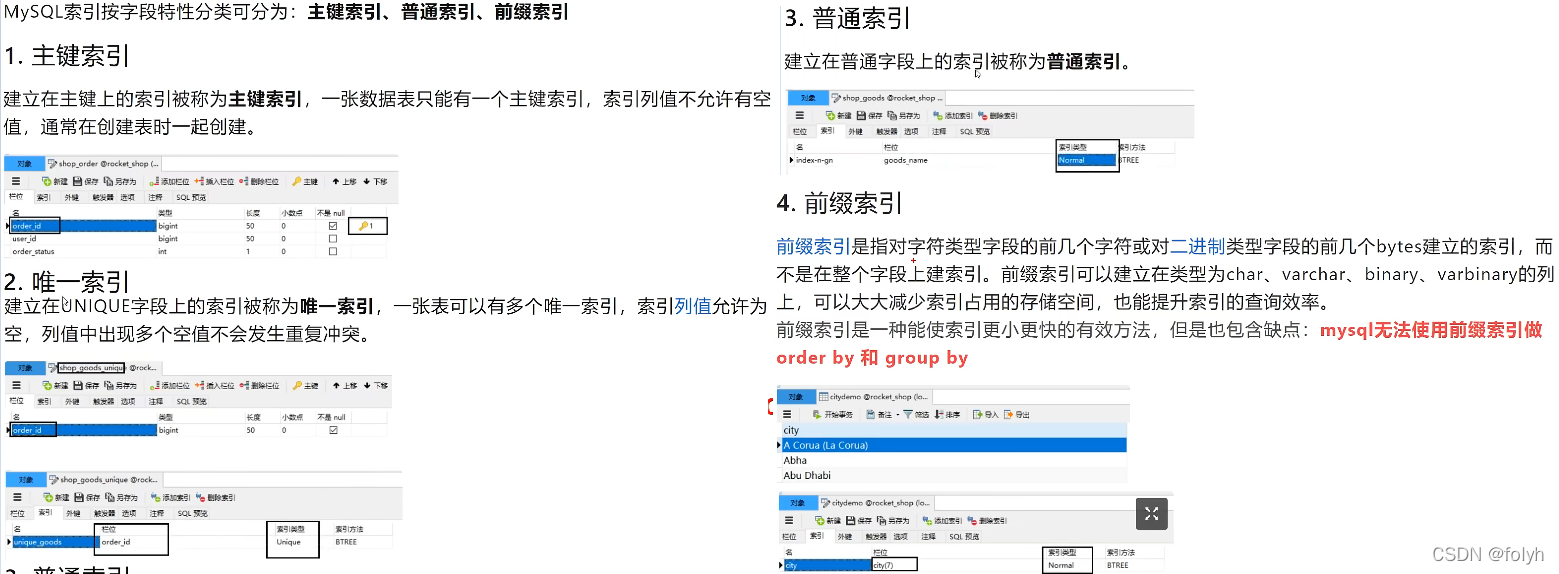
7.mysql索引:
8.三星索引:

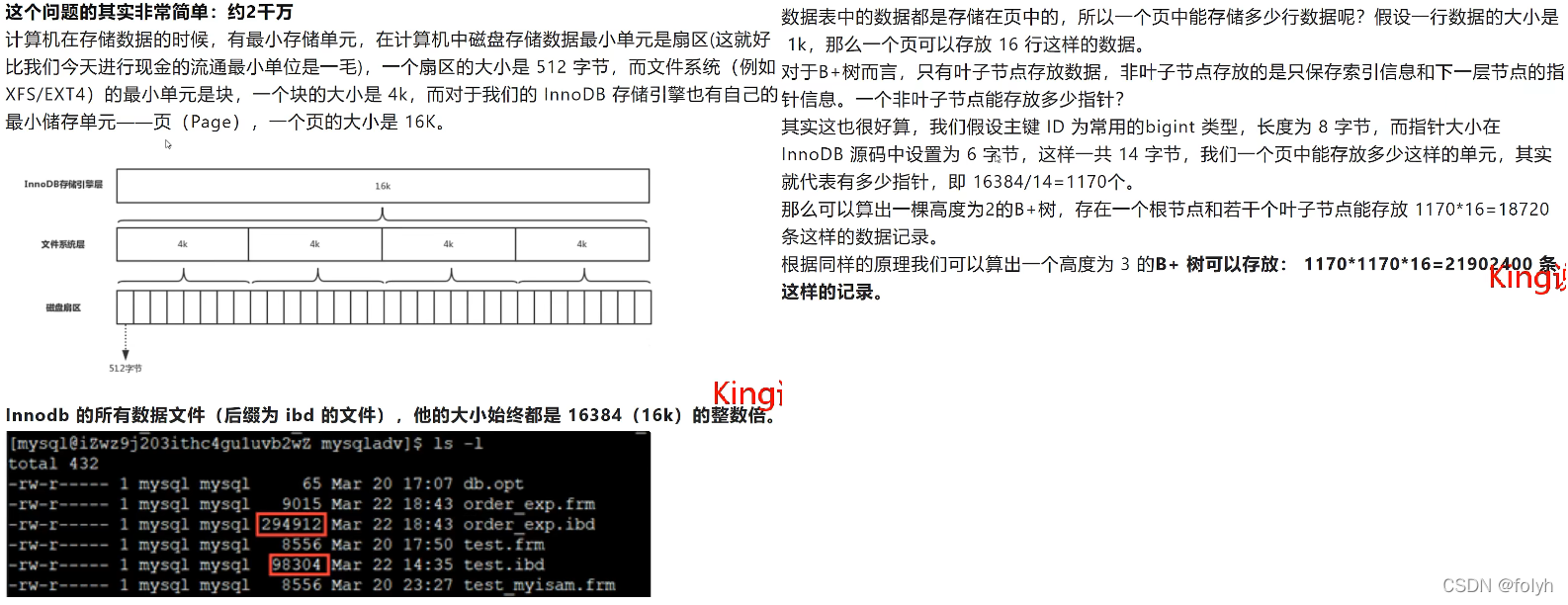
9.innodb一颗b+树存放可以存放多少行数据:
10.如何提高insert性能:

11.全局锁、共享锁、排他锁:

12.mysql死锁:
13.读写分离
1.1 主从复制结构
一主一从、一主多从、双主复制、级联复制、双主级联
1.2 原理
MySQL Replication:从服务器拉取主服务器的二进制日志文件–bin-log,再解析成失去了语句并执行从而保证数据一致性。属于异步复制(5.7以上添加半同步)。
读写分离参考链接
14.分库分表
14.1 分表(单分库原理一样把表换成库)
通过id%100(id取模表数数量,如果是uuid则进行hash获取整数值再取模)算出哪张表,
再通过 select * from table_1 where id= 101查询数据,
或者直接在MyBatis配置好:
<select id="getOrder" resultMap="BaseResultMap">
select * from order_${tableNum}
where user_id = #{userId}
</select>
14.2 分库分表
常见路由策略:
1、中间变量 = id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;
例: id为200,885,应分配到第8个数据库的第85张数据表中(库和表都是从0开始算起即序号0-9数据库,每个数据库的序号0-99数据表)
1、中间变量 = 200,885%(10*100)= 885;
2、库序号 = 取整 (885/100)= 8;
3、表序号 = 885 % 100 = 85;
分库分表参考链接
15.海量数据解决方案
15.1 使用缓存
设置key随机过期时间
设置热点key永不过期
设置限速、ngnix单个ip单位时间内访问次数
设置不合法参数直接返回、缓存及数据库都没有的数据值为null、布隆过滤器
设置redis主从复制+哨兵机制、集群
合适的过期策略
15.2 页面静态化技术
前后端分离
nodejs提供路由向后端请求数据,然后在浏览器对数据渲染(而非后台服务器进行渲染才返回前端浏览器进行解析执行)
静态化
HTML、CSS、JS、图片等放在CDN或Ngnix服务器

15.3 数据库优化
表结构优化
sql优化
分表
分库或分区
索引优化
存储过程代替直接操作
15.4 分离数据库中活跃的数据
使用缓存、分离出僵尸用户级数据等
15.5 批量读取和延迟修改
批量读取:多次查询合并到一次查询、异步方式
延迟修改:高并发且修改频繁数据,先将数据保存到缓存中,再定时保存到数据库中,读取时可以同时读取数据库中及缓存中数据
15.6 读写分离
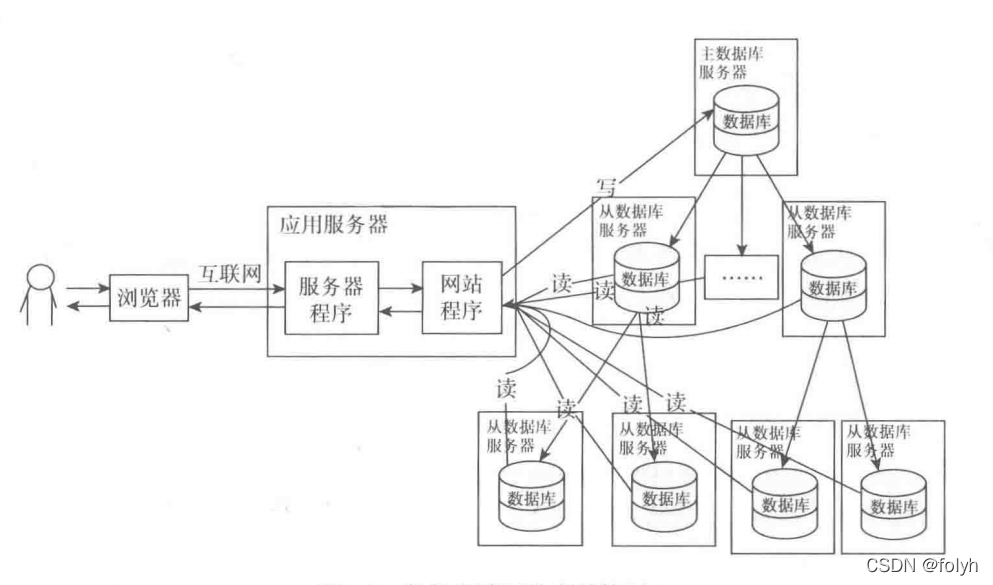
15.7 使用Nosql和Hadoop等技术
如mongDB
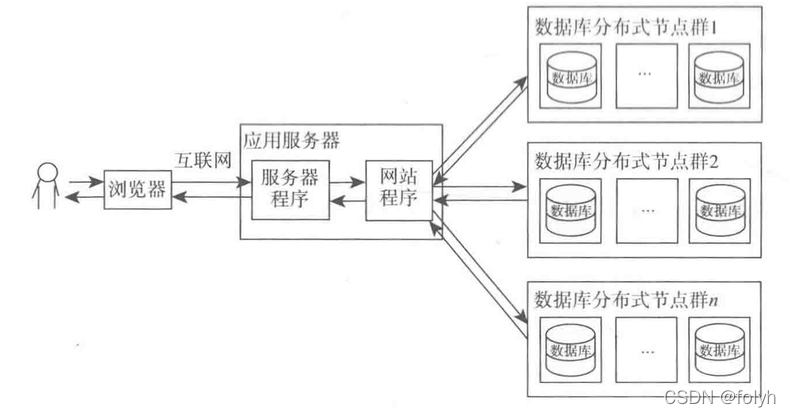
15.8 分布式部署数据库
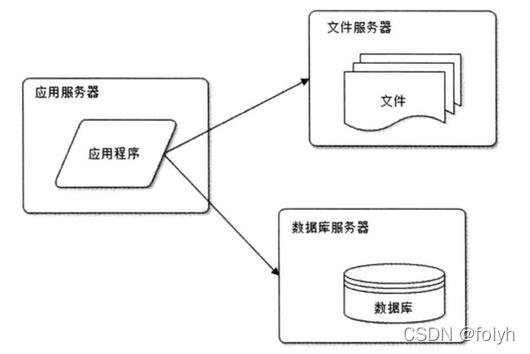
15.9 应用服务和数据服务分离
15.10 使用搜索引擎搜索数据库中的数据
ELK stack
15.11 业务拆分
本篇文章主要参考链接如下:
参考链接1-King说Java
参考链接2-JavaGuide
随心所往,看见未来。Follow your heart,see light!
欢迎点赞、关注、留言,一起学习、交流!