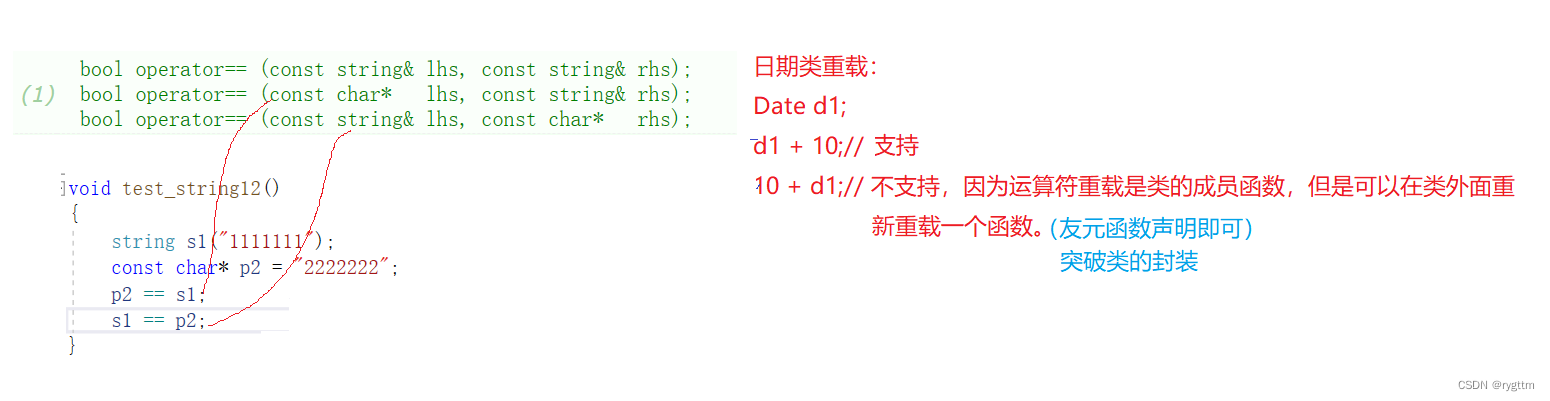
js的数组上有很多实用的方法,不论是在遍历数组上,还是在操作数组内元素上,它有许多不同的遍历数组的方法,同时它还有着可以直接操作数组中间元素的方法。
接下来,我来带大家手写数组里的 遍历方法 。
Array.forEach()
首先, Array.forEach() 接收一个回调作为参数;
同时,在它的回调则接收三个参数,分别代表着(数组项,下标,整个数组本身);
最后,forEach 会把数组进行遍历调用这个传进去的回调函数。
例如:
const singer = [{ name: '周杰伦', num: 20 },{ name: '许嵩', num: 25 },{ name: '林俊杰', num: 19 },{ name: '蔡徐坤', num: 10 },{ name: '鹿晗', num: 0 },
];
singer.forEach((item, index, arr) => {console.log(item, index, arr);
})
// 输出
// { name: '周杰伦', num: 20 },0, [{ name: '周杰伦', num: 20 },{ name: '许嵩', num: 25 },{ name: '林俊杰', num: 19 },{ name: '蔡徐坤', num: 10 },{ name: '鹿晗', num: 0 }]
// { name: '许嵩', num: 25 },1,[{ name: '周杰伦', num: 20 },{ name: '许嵩', num: 25 },{ name: '林俊杰', num: 19 },{ name: '蔡徐坤', num: 10 },{ name: '鹿晗', num: 0 }]
// ...
// ...
// ...
知道了 Array.forEach() 接收的参数以及怎么执行的,那么我们就可以开始手写它了。
Array.prototype.my_forEach = function(callback) {//将我们手写的方法定义在Array的原型上,接收一个callback回调for (let i = 0; i < this.length; i++) { //遍历这个数组,同时在遍历里面调用这个接收到的回调callback(this[i], i, this)}
}
相对于其它数组遍历方法,forEach方法应该是最简单的一种方法了,没有很特殊的地方,只是简简单单的遍历数组里每一个元素,传递出来。
Array.map()
Array.map() 方法跟 Array.forEach() 方法接收的参数相似;
也是接收一个回调,回调里也是接收那三个参数,分别代表着(数组项,下标,整个数组);
但是它跟 Array.forEach() 还是有一个差别;
那就是它会返回出来一个数组,返回出来的数组的每一项都是回调里面返回出来的值。
例如:
const singer = [{ name: '周杰伦', num: 20 },{ name: '许嵩', num: 25 },{ name: '林俊杰', num: 19 },{ name: '蔡徐坤', num: 10 },{ name: '鹿晗', num: 0 },]const newSinger = singer.map((item, index, arr) => {return item})console.log(newSinger);
打印出来的结果会是:
那么知道了 Array.map() 的特性之后,我们完全可以开始手写它了,
Array.prototype.my_map = function(callback) { // 写一个my_map方法写在Array原型上,接收一个回调const res = []//定义一个数组,用来接收遍历回调得到的新的返回值,最后返回出去for (let i = 0; i < this.length; i++) {res.push(callback(this[i], i, this))//把回调返回出来的值往res数组添加}return res //返回出去数组res
}
Array.map() 相对于普通的遍历来说,它只是会返回出来一个数组,用来接收每个回调的返回值。
Array.filter()
Array.filter() 方法跟 Array.map() 方法接收的参数一样,也是接收一个回调;
回调里同样也是接收那三个参数,分别代表着(数组项,下标,整个数组);
同时它跟 Array.map() 一样,它也会返回出来一个数组;
但是不一样的是,它会对数组每一项进行筛选(故我们通常会叫 filter 叫筛选器方法);
筛选的条件就是回调函数里的 return 所返回出来的条件。
例如:
const singer = [{ name: '周杰伦', num: 20 },{ name: '许嵩', num: 25 },{ name: '林俊杰', num: 19 },{ name: '蔡徐坤', num: 10 },{ name: '鹿晗', num: 0 },]const newSinger = singer.filter((item, index, arr) => {return item.num > 15})console.log(newSinger);//打印结果:// [{ name: '周杰伦', num: 20 },//{ name: '许嵩', num: 25 },//{ name: '林俊杰', num: 19 }]
这里我们用官方的 Array.filter() 方法,在里面返回的条件是 item.num>15 ;
所以我们打印用来接收 filter 返回出来的那个数组,可以看到的是打印的是:
[{ name: '周杰伦', num: 20 }, { name: '许嵩', num: 25 }, { name: '林俊杰', num: 19 }]
打印出来的这个数组里每一个元素都是满足 item.num>15 这个条件的数组项;
所以我们如果想写一个 filter 方法的话,目标就很明确了,我们需要满足:
1.遍历这个数组的同时拿回调函数里返回出来的判断条件来判定数组项是否满足条件2.满足条件的数组项我们就把它放到一个新数组里去,用于最后返回出来那么知道这些,我们就可以很轻松的把这个方法手写出来了:
Array.prototype.my_filter = function(callback) {const res = [];//定义一个空数组,用来装满足判定条件的数组项for (let i = 0; i < this.length; i++) { //遍历回调callback(this[i], i, this) && res.push(this[i]) //语句判断,如果满足回调函数返回出来的判定条件,就把数组该项加入res数组}return res//返回出来满足条件的数组
}
Array.every()
Array.every() 方法与其它数组方法接收的参数也是基本一致,不同的是它是返回出来一个 boolean 值;
应用场景一般是发生在检查所有数组值是否通过测试;
一旦有一个值不通过,那么就会直接返回 false,只有所有值都满足条件,才会返回 true。
根据这些条件我们就可以有了大致方向:
1.对数组每一项进行条件判断,只有一个不满足,直接 return false2.循环结束后加一个 return true 用于返回当所有情况都满足了,那么返回 true```
Array.prototype.my_every = function(callback) {for(let i = 0 ; i < this.length; i++) {if(!callback(this[i],i,this)){//判定不满足的情况return false; //一旦有一个不满足,那么我们就直接返回false,不再执行接下来的代码}}return true;//当所有的元素都不返回false,那么咱们就返回true
}
Array.some()
------------
Array.some() 方法跟 Array.every() 方法刚好相反;
它也是返回出来一个 boolean 值,不同的是只要有数组里有一个元素满足判定条件,那么就会直接返回 true;
若没有一个满足条件,那么就会返回 false。
根据这些条件我们就可以往这个方向思考:
1.对数组每一项进行条件判断,只有一个满足,直接 return true2.循环结束后加一个 return false 用于返回当所有情况都不满足了,那么返回 false```
Array.prototype.my_every = function(callback) {for(let i = 0 ; i < this.length; i++) {if(callback(this[i],i,this)){//判定满足的情况return true; //一旦有一个满足,那么我们就直接返回true,不再执行接下来的代码}}return false;//当所有的元素都不返回true,那么咱们就返回false
}
Array.reduce()
Array.reduce() 方法应该算是数组的所有的遍历方法里面比较特殊的一个方法吧;
它接收两个参数,第一个参数是需要执行的回调函数,而第二个参数则是初始的一个变量值;
这么说它的第二个参数可能大家都不太理解,没关系,待会儿会带大家仔细讲解。
再讲它的回调函数,它的回调接收四个参数:
function myFunction(pre, value, index, array) {return pre + value;
}
//四个参数分别代表着:
//- 总数(初始值/先前返回的值)
//- 项目值
//- 项目索引
//- 数组本身
那么咱们来看一看官方给出的 Array.reduce() 的实例吧:
let arr = [1,2,3,4,5,6];
const res = arr.reduce((pre, value, index, array)=>{console.log(pre,value,index,array);return pre + value
},0)
console.log(res);
// 运行结果:
// 0 1 0 [ 1, 2, 3, 4, 5, 6 ]
// 1 2 1 [ 1, 2, 3, 4, 5, 6 ]
// 3 3 2 [ 1, 2, 3, 4, 5, 6 ]
// 6 4 3 [ 1, 2, 3, 4, 5, 6 ]
// 10 5 4 [ 1, 2, 3, 4, 5, 6 ]
// 15 6 5 [ 1, 2, 3, 4, 5, 6 ]
// 21
我们可以看到的就是第一次 pre 的值就是我们 reduce 所接收到的第二个参数,而之后的 pre 都是上一次 pre 与 value 的和;
那么为什么是 pre 和 value 的和呢?
原因是每次 reduce 都在执行那个回调,而回填返回出来的值都会传到下一次 reduce 遍历的 pre 中;
这就是 reduce 所接收的各个参数了。
reduce 这个方法多用于数组的累加,累乘等等累积值。
那么如果不给 reduce 传第二个参数会怎样?
这是个好问题,咱们来一起看看:
可以看到的是,它的打印少了一层,那就是第一层,它从数组的第二项开始遍历,而第一个 pre 则是数组没有被遍历的第一项。
所以由此可知,如果我们不给 reduce 传第二个参数,那么它就会默认从数组第二项开始遍历,而第一个 pre 则会变成数组第一项。
那么要手写 reduce 这个方法,我们需要做到哪些条件呢?
1.判断 reduce 是否有接收到第二个参数,做情况判断,决定开始从数组哪个位置开始遍历;2.把每一次回调 return 出来的值都传给下一次回调的 pre ;3.把回调里最后一次 return 传出去。有了这个方向咱们就可以开始手写了:
Array.prototype.my_reduce = function(callback, ...args) {let pre, start = 0;// 定义一个 pre ,方便把最后一次 pre 传出去;if (args.length) {// 判断是否存在第二个参数,决定数组从下标0,还是下标1开始遍历,同时给第一次 pre 赋值pre = args[0]} else {pre = this[0]start = 1}for (let i = start; i < this.length; i++) { // 遍历调用回调,把每一次 pre 传到下一次pre = callback(pre, this[i], i, this)}return pre// 把最后的 pre 传出去}
那么最后的 Array.reduce() 也写完了,数组的遍历方法手写也就到此为止啦。
最后
最近找到一个VUE的文档,它将VUE的各个知识点进行了总结,整理成了《Vue 开发必须知道的36个技巧》。内容比较详实,对各个知识点的讲解也十分到位。




有需要的小伙伴,可以点击下方卡片领取,无偿分享



![[技术经理]01 程序员最优的成长之路是什么?](https://img-blog.csdnimg.cn/281245e6005049b38ff0636a68bb19f5.jpeg#pic_center)