四、分布式数据库HBase
1. 产生背景
1.1 Hadoop的局限性
- 优点:存储结构化、半结构甚至非结构化的数据,是传统数据库的补充,是海量数据存储的最佳方法。
- 缺陷:
- 只能进行批处理,并且只能以顺序的方式访问数据。(即最简单的工作也必须搜索全部数据库,无法实现对数据的随机访问;反观传统的关系型数据库,其主要特点就在于随机访问,但它们却不能用于海量数据的存储)
1.2 HBase VS 传统数据库
- 数据结构的分类:
- 结构化数据:即以关系型数据库表形式管理的数据
- 半结构化数据:具有非关系模型、基本固定结构模式的数据,例如日志文件、XML文档、JSON文档、Email等;
- 非结构化数据:没有固定模式的数据,如Word、PDF、PPT、Excel、各种格式的图片、视频等。
- 数据库的类型:
- 关系型数据库:关系型数据库模型,是把复杂的数据结构归结为简单的二元关系(即二维表格形式)(代表:MySql)
- 键值存储数据库:键值数据库是一种非关系数据库,它使用简单的键值方法来存储数据。键值数据库将数据存储为键值对集合,其中键作为唯一标识符。(即python中的字典形式)(代表:Redis)
- 列存储数据库:列式存储(column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的。简单来说,两者的区别就是对表中数据的存储形式的差异。(代表:HBase)
- 面向文档数据库:此类数据库可存放并获取文档,可以是XML、JSON、BSON等格式,这些文档具备可描述性(self-describing),呈现分层的树状结构(hierarchical tree data structure),可以包含映射表、集合和纯量值。数据库中的文档彼此相似,但不必完全相同。文档数据库所存放的文档,就相当于键值数据库所存放的“值”。文档数据库可视为其值可查的键值数据库。(代表:MongoDB)
- 图形数据库:图形数据库顾名思义,就是一种存储图形关系的数据库。图形数据库是NoSQL数据库的一种类型,可以用于存储实体之间的关系信息。最常见例子就是社会网络中人与人之间的关系。(代表:Neo4J、ArangoDB、OrientDB、FlockDB、GraphDB、InfiniteGraph、Titan和Cayley等)
- 搜索引擎数据库:搜索引擎数据库是一类专门用于数据内容搜索的非关系数据库。搜索引擎数据库使用索引对数据中的相似特征进行归类,并提高搜索能力。搜索引擎数据库经过优化,以处理可能内容很长的半结构化或非结构化数据,它们通常提供专业的方法,例如全文搜索、复杂搜索表达式和搜索结果排名等。(代表:Solr,Elasticsearch)
传统数据库无法适应当今时代的原因:无论在数据高并发方面,还是在高可拓展性和高可用性方面,传统的关系型数据库都显得力不从心,其完善的事务机制和高效的查询机制也成为“鸡肋”。
- HBase与传统的关系型数据库的区别主要在于:
- 数据类型丰富:有
int、date、long等。Hbase数据类型简单,每个数据都被存储为未经解释的字符串,用户需要自己编写程序把字符串解析成不同的数据类型。 - 数据操作高效:关系型数据库存在增删改查,还有我们比较熟悉的联表操作,效率较低。Hbase不会把数据进行充分的规范化。很多数据是存在一张表里,避免了低效率的连接操作。
- 存储模式:关系型数据库采用行模式存储,Hbase是基于列存储
- 数据索引:关系型数据库可以对不同的列构建复杂的索引结构。Hbase支持对行键的索引。
- 数据维护:更新操作时,关系型数据库会把数据替换掉,Hbase会保留旧的版本数据一段时间,到了一定期限才会在后台清理数据。
- 可伸缩性:关系型数据库很难实现水平扩展,Hbase采用分布式集群存储,水平扩展性较好
- 数据类型丰富:有
- HBase的局限:不支持事务,因此无法实现跨行的原子性
2. 概述
2.1 HBase简介
- HBase是构建在Hadoop文件系统之上的一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
- HBase旨在提供对大量结构化数据的快速随机访问。它利用Hadoop文件系统(HDFS)提供的容错功能,同时作为Hadoop生态系统的一部分,提供对Hadoop文件系统中的数据的随机实时读写访问。
- 在Hadoop生态系统中,HBase利用Hadoop MapReduce来处理HBase中的海量数据,实现高性能计算;利用ZooKeeper作为协同服务,实现稳定服务和失败恢复;使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力。Sqoop为HBase提供了高效、便捷的RDBMS数据导入功能,Pig和Hive为HBase提供了高层语言支持。
2.2 HBase访问接口
| 类型 | 特点 | 场合 |
|---|---|---|
| Native Java API | 最常规和高效的访问方式 | 适合Hadoop MapReduce作业并行批处理HBase表数据 |
| HBase Shell | HBase的命令行工具,最简单的接口 | 适合HBase管理使用 |
| Thrift Gateway | 利用Thrift序列化技术,支持C++、PHP、Python等多种语言 | 适合其他异构系统在线访问HBase表数据 |
| REST Gateway | 解除了语言限制 | 支持REST风格的Http API访问HBase |
| Pig | 使用Pig Latin流式编程语言来处理HBase中的数据 | 适合做数据统计 |
| Hive | 简单 | 当需要以类似SQL语言方式来访问HBase的时候 |
3. HBase数据模型
3.1 数据模型概述
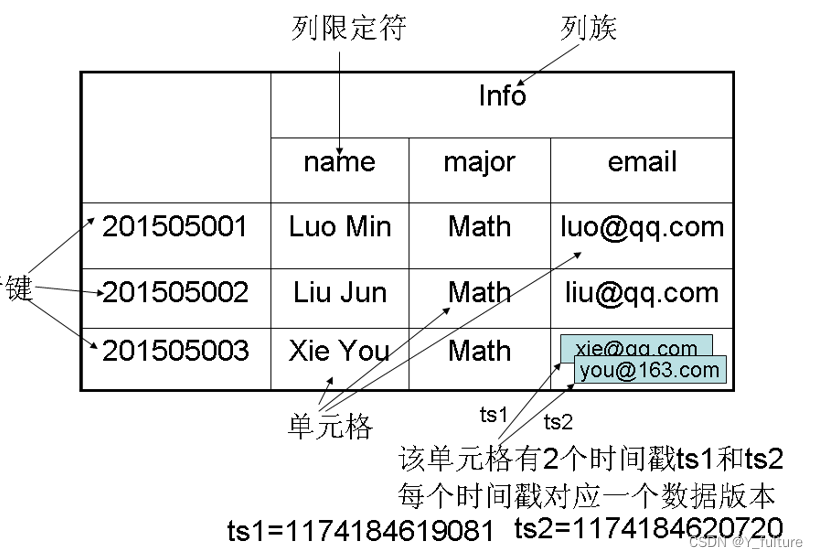
- HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳。
- 每个值是一个未经解释的字符串,没有数据类型。
- 用户在表中存储数据,每一行都有一个可排序的行键和任意多的列。
- 表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起。
- 列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储。因此对于整个映射表的每行数据而言,有些列的值是空的,所以说HBase是稀疏的。
- HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的)。
3.2 数据模型的相关概念
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族。
- 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
- 列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元。表中的每个列都归属于某个列族,数据可以被存放到列族的某个列下面(列族需要先创建好)。在创建完列族以后,就可以使用同一个列族当中的列。列名都以列族作为前缀。例如,
courses:history和courses:math这两个列都属于courses这个列族。 - 列限定符:列族里的数据通过列限定符(或列)来定位。
- 单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组
byte[]。 - 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
3.3 数据坐标
- HBase使用坐标来定位表中的数据,也就是说,每个值都通过坐标来访问。HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此,可以视为一个“四维坐标”,即
[行键, 列族, 列限定符, 时间戳]。 - 也可以视为键值数据库(思维坐标为键,对应数据为值)
3.4 概念试图
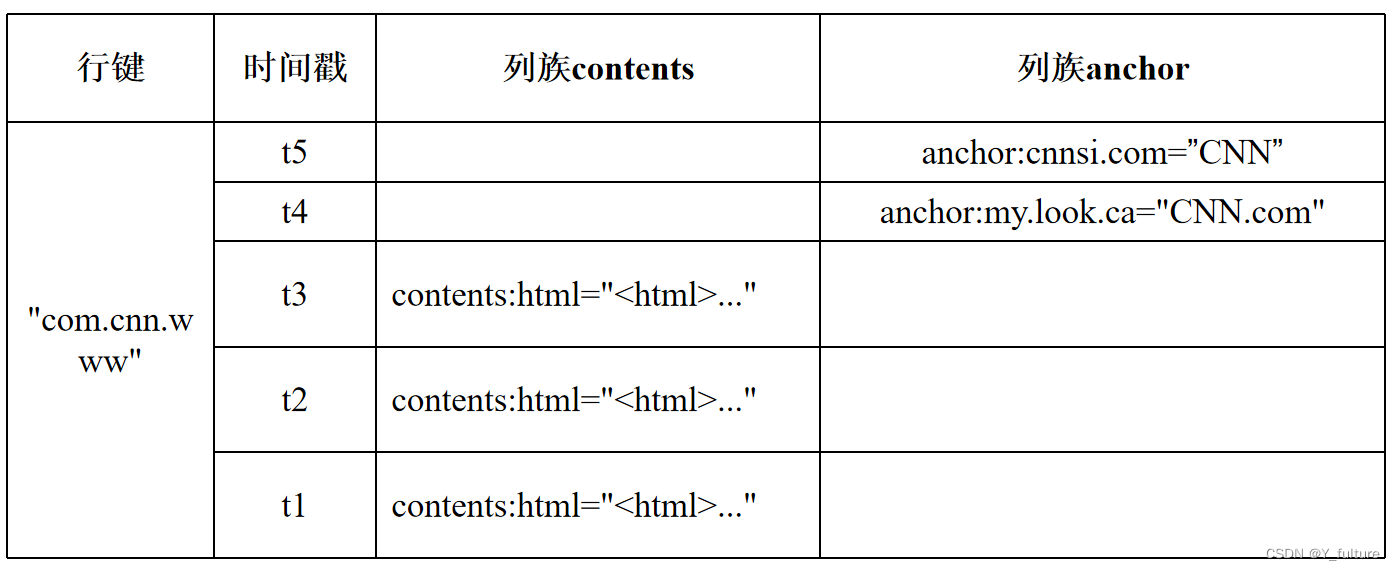
- 行键是一个反向
URL,由于HBase是按照行键的字典序来排序存储数据的,采用这种方式可以让来自同一个网站的数据内容都存在相邻的位置,在按照行键的值进行水平分区时,就可以尽量把来自同一个网站的数据分到同一个分区(Region)中。 - 列族
content用来存储网页内容。 - 列族
anchor包含了任何引用这个页面的锚链接文本。 - 时间戳代表不同时间的版本
3.5 物理视图
- 物理存储层面,它采用基于列的存储方式(带有行键和时间戳一起存储,空的单元格并不会进行存储,如果访问,会返回null),而不是像传统关系数据库那样采用基于行的存储方式,这也是HBase和传统关系数据库的重要区别。
3.6 面向列的存储

-
传统行式数据库
- 数据是按行存储的
- 没有索引的查询使用大量I/O。在从磁盘中读取数据时,需要从磁盘中顺序扫描每个元组的完整内容,然后从每个元组中筛选出查询所需要的属性
- 建立索引和物理视图需要花费大量时间和资源
- 面对查询的需求,数据库必须被大量膨胀才能满足性能要求
-
列式数据库
- 数据按列存储,每一列单独存放
- 数据即是索引
- 只访问查询涉及的列,大量降低系统IO
- 每一列由一个线索来处理,查询采用并发处理方式
- 数据类型一致,数据特征相似,采用高效压缩方式
- 缺陷:执行链接操作时,需要昂贵的元组重构代价
4. HBase的实现原理
4.1 HBase组件功能
主要包含一下几个部分:
- 库函数(用于连接到每个客户端)
- 一个Master主服务器:负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡。
- 许多个Region服务器:负责存储和维护分配给自己的Region,处理来自客户端的读写请求。
- 客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据。
- 客户端并不依赖Master,而是通过Zookeeper获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小
4.2 表和Region
- 一个HBase可以存储很多表。对于每个HBase表而言,表中的行是根据行键的值的字典序进行维护的,表中包含的行的数量可能非常庞大,无法存储在一台机器上,需要分布存储到多台机器上。因此,需要根据行键的值对表中的行进行分区。每个行区间构成一个分区,被称为Region。Region包含了位于某个值域区间内的所有数据,是负载均衡和数据分发的基本单位。
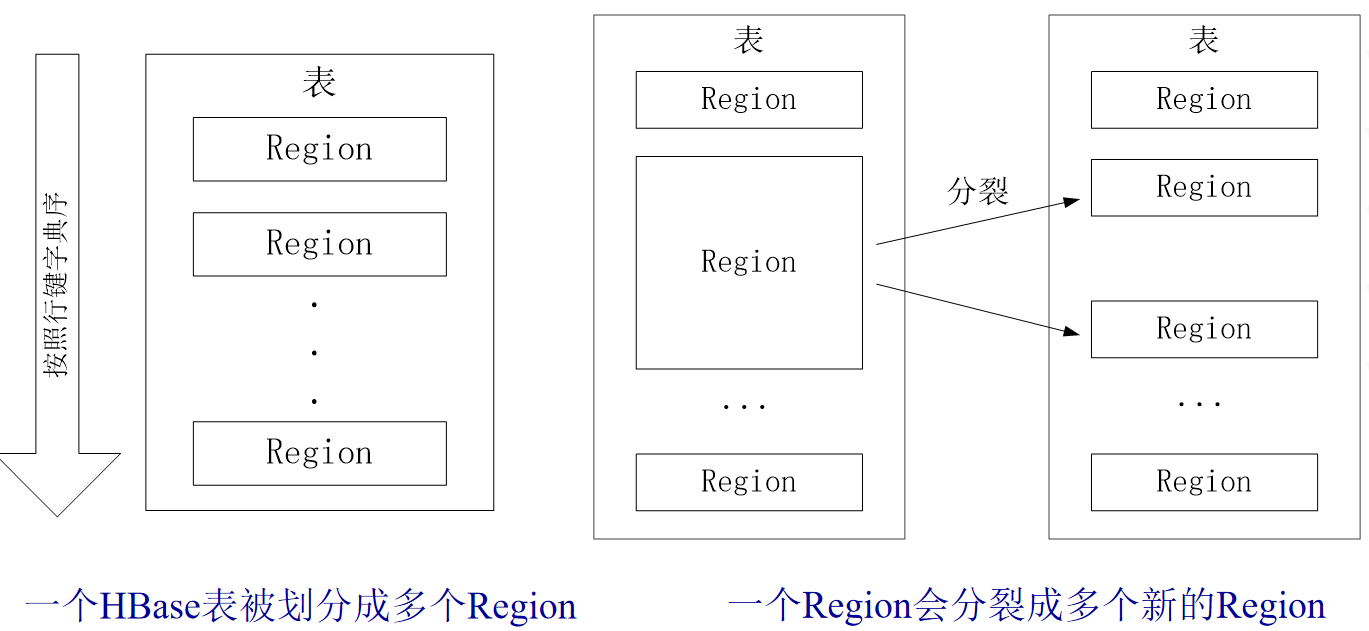
- 生成Region的过程
- 开始只有一个Region,随着数据不断的插入,Region越来越大。当达到一定的阈值时,开始分裂成两个新的Region
- 随着表中行的数量继续增加,就会分裂出越来越多的Region
- Region拆分操作非常快,因为拆分之后的Region读取的仍然是原存储文件,直到“合并”过程把存储文件异步地写到独立的文件之后,才会读取新文件

其中:
- 每个Region的最佳大小取决于单台服务器的有效处理能力,目前每个Region最佳大小建议1GB-2GB(2013年以后的硬件配置)
- 同一个Region不会被分拆到多个Region服务器
- 每个Region服务器负责管理一个Region集合,通常在每个Region服务器会存储10-1000个Region
4.3 Region定位
-
一个HBase的表可能非常庞大,会被分裂成很多个Region,这些Region可被分发到不同Region服务器上
-
每个Region都有一个
RegionID来标识它的唯一性,这样,一个Region标识符就可以表示成表名+开始主键+RegionID -
为了定位每个Region所在的位置,可以构建一张映射表,每行包含两项内容(表示Region和Region服务器之间的对应关系,从而就可以知道某个Region被保存在哪个Region服务器中):Region标识符、Region服务器标识。这个映射表包含了关于Region的元数据(即Region和Region服务器之间的对应关系)。因此,也被称为“元数据表”,又名
.META.表。 -
当一个HBase表中的Region数量非常庞大的时候,
.META.表的条目就会非常多 ,一个服务器保存不下,也需要分区存储到不同的服务器上,因此,.META.表也会被分裂成多个Region。 -
这时,为了定位这些Region,就需要再构建一个新的映射表,记录所有元数据的具体位置,这个新的映射表就是“根数据表”,又名
-ROOT-表。该表的特点有: -
-ROOT-表是不能被分割的,永远只存在一个Region用于存放-ROOT-表。 -
这个用来存放
-ROOT-表的唯一个Region,它的名字是在程序中被写死的,Master主服务器永远知道它的位置。 -
综上所述,HBase使用类似B+树的三层结构来保存Region位置信息,详见下图
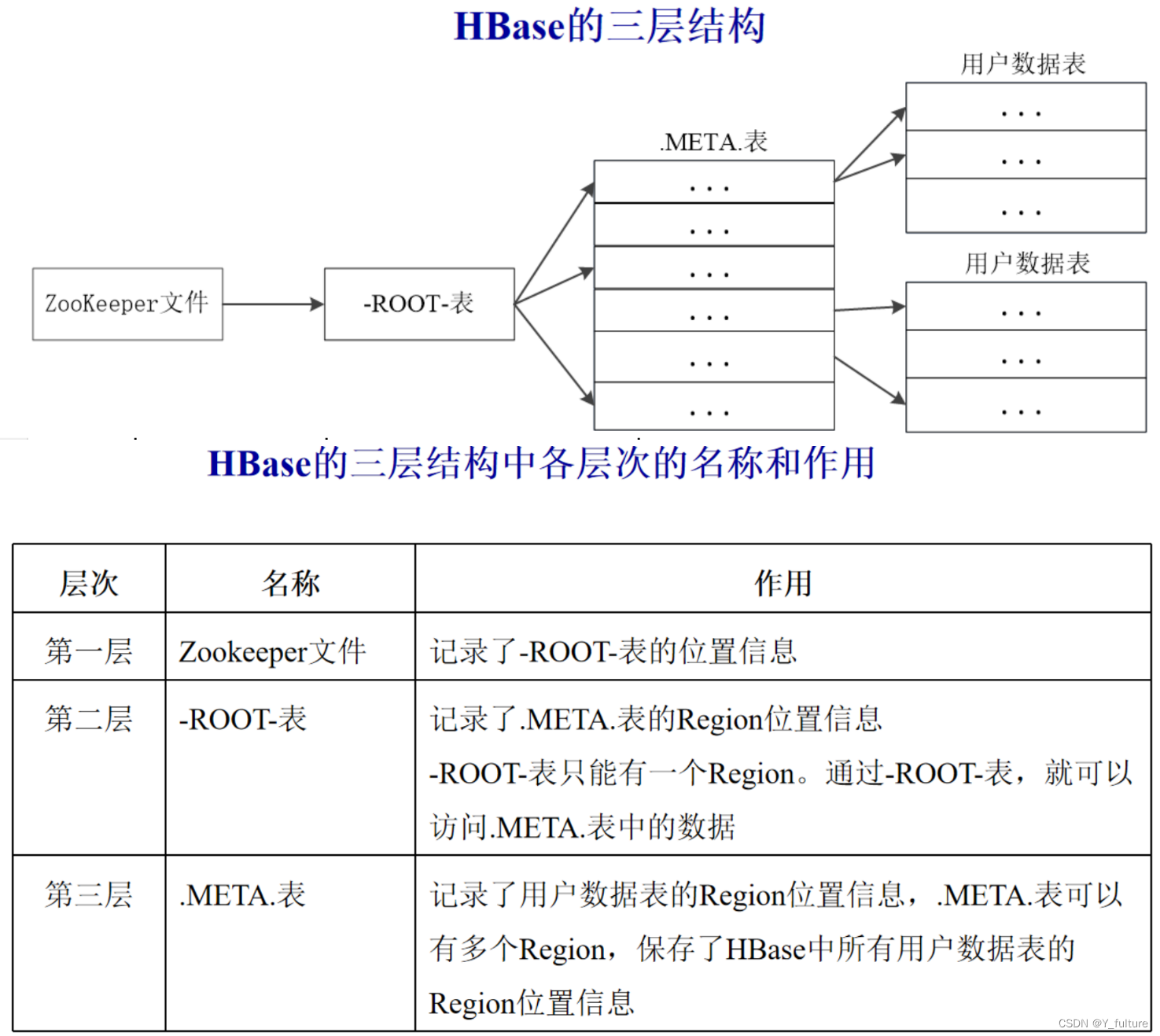
三层结构的特点:
- 为了加快访问速度,
.META.表的全部Region都会被保存在内存中 - 客户端访问数据时采用的是三级寻址
- 为了加速寻址,客户端会缓存位置信息。同时,需要解决缓存失效问题
- 寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器。因此,主服务器的负载相对就小了很多。
4.4 HBase运行机制
4.4.1 HBase系统架构
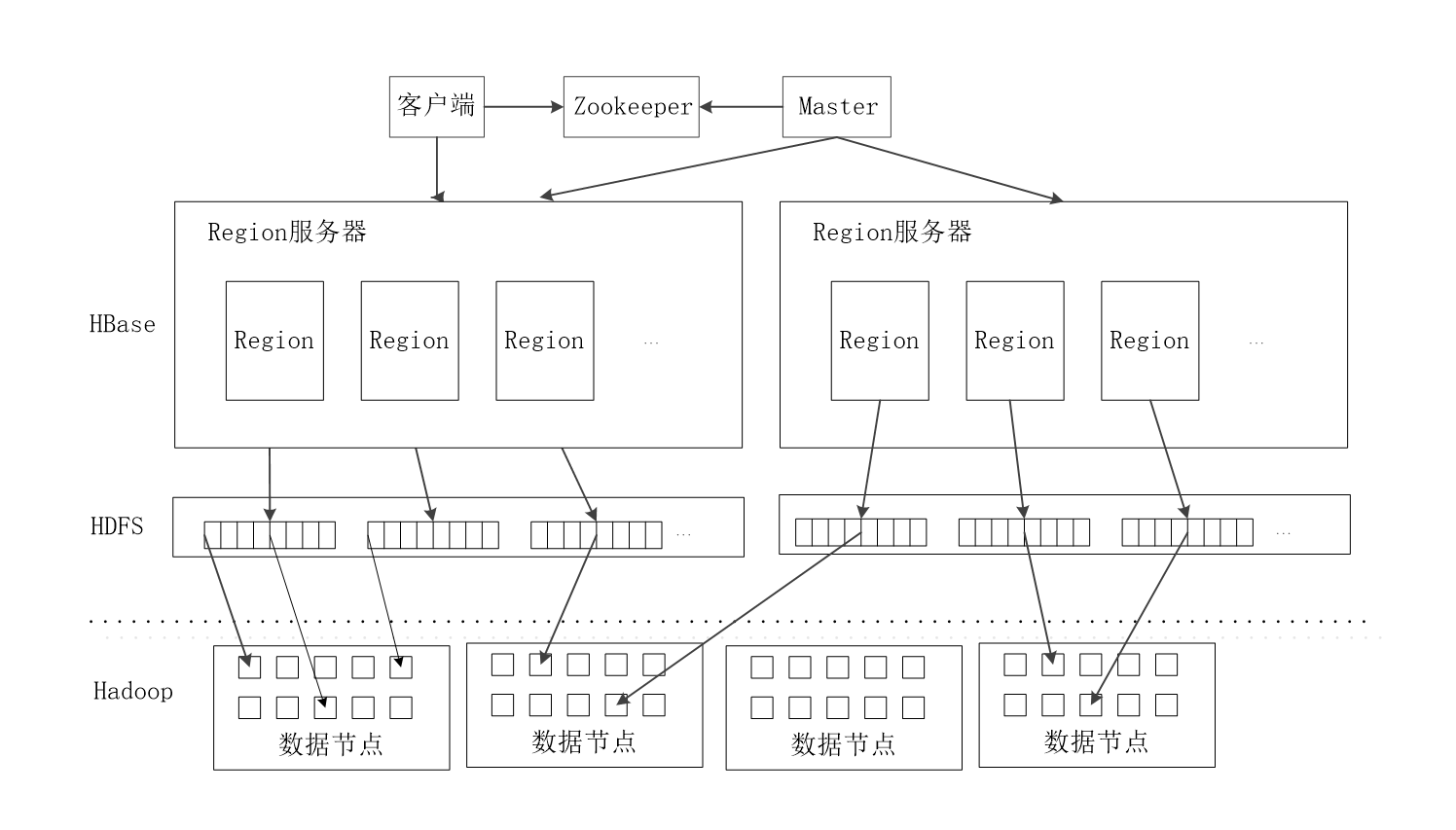
-
客户端:客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的
Region位置信息,用来加快后续数据访问过程。 -
Zookeeper服务器:Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题。同时,Zookeeper也是一个很好的集群管理工具,被大量用于分布式计算,提供配置维护、域名服务、分布式同步、组服务等。

-
Master服务器:主服务器Master主要负责表和Region的管理工作:
- 管理用户对表的增加、删除、修改、查询等操作
- 实现不同Region服务器之间的负载均衡
- 在Region分裂或合并后,负责重新调整Region的分布
- 对发生故障失效的Region服务器上的Region进行迁移
-
Region服务器:Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求。
4.4.2 Region服务器的工作原理
- 用户读写数据过程
- 用户写入数据时,被分配到相应Region服务器去执行
- 用户数据首先被写入到
MemStore和Hlog中 - 只有当操作写入
Hlog之后,调用commit()方法才会将其返回给客户端 - 当用户读取数据时, Region服务器会首先访问
MemStore缓存,如果找不到,再到磁盘的StoreFile中寻找
- 缓存的刷新
- 系统会周期性地把
MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记 - 每次刷写都生成一个新的
StoreFile文件,因此,每个Store包含多个StoreFile文件 - 每个Region服务器都有一个自己的
HLog文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务
- 系统会周期性地把
StoreFile的合并- 每次刷写都生成一个新的
StoreFile,数量太多,影响查找速度 - 调用
Store.compact()把多个StoreFile合并成一个 - 合并操作比较耗费资源,只有数量达到一定阈值后才会启动合并
- 每次刷写都生成一个新的
4.4.3 Store工作原理
Store是Region服务器的核心- 多个
StoreFile合并成一个StoreFile - 单个
StoreFile过大时,又触发分裂操作,1个父Region被分裂成两个子Region
合并与分裂过程如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iHi7EeYv-1676986847283)(null)]
4.4.4 HLog工作原理
在分布式环境下,必须考虑到系统出错的情形,比如当Region服务器发生故障时,MemStore缓存中的数据(还没有写入文件)会全部丢失。因此,HBase用HLog来保证系统发生故障时能够恢复到正确的状态,HLog具有以下特点:
-
HBase系统为每个Region服务器配置了一个
HLog文件,它是一种预写式日志(Write Ahead Log)。 -
用户更新数据必须首先写入日志后,才能写入
MemStore缓存,并且,直到MemStore缓存内容对应的日志已经写入磁盘后,该缓存内容才能被刷写到磁盘。 -
Zookeeper会实时监测每个Region服务器的状态,当某个Region服务器发生故障时,Zookeeper会通知Master。
-
Master首先会处理该故障Region服务器上面遗留的
HLog文件,这个遗留的HLog文件中包含了来自多个Region对象的日志记录。 -
系统会根据每条日志记录所属的Region对象对
HLog数据进行拆分,分别放到相应Region对象的目录下,然后,再将失效的Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器。 -
Region服务器领取到分配给自己的Region对象以及与之相关的
HLog日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入到MemStore缓存中,然后,刷新到磁盘的StoreFile文件中,完成数据恢复。 -
共用日志的优点是提高对表的写操作性能;其缺点是恢复时需要分拆日志。
4.4.5 HBase性能优化
- 行键(Row Key): 行键是按照字典序存储。因此,设计行键时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。例如:如果最近写入HBase表中的数据是最可能被访问的,可以考虑将时间戳作为行键的一部分 。(将时间戳倒序排序进行查找)
- InMemory:创建表的时候,可将表放到Region服务器的缓存中,保证在读取的时候被
cache命中。 - Max Version:创建表的时候,可设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置
setMaxVersions(1)。 - Time To Live:创建表的时候,可设置表中数据的存储生命期,过期数据将自动被删除。
5. 实验(后期统一补上)
参考自DataWhale组队学习资料