文章目录
- ESRT
- 1. 超分基本知识
- 1.1 SRF
- 1.2 xxx_img
- 1.3 裁剪
- 1.4 超分模型评估标准
- 2. LCB、LTB 模块
- 2.1 序列模型
- 3. 损失函数
- 4. 部署运行
- 4.1 数据集
- 4.1.1 训练集
- 4.1.2 验证集
- 4.1.3 测试集
- 4.2 数据集转换
- 4.3 训练
- 4.4 测试
- 4.5 效果
ESRT
ESRT(Efficient Super-Resolution Transformer)是一种单图像超分辨率重建算法。
- 相较于传统的超分辨率方法,ESRT 提出了一种基于自注意力机制的Transformer 网络,可以充分利用全局信息,从而获得更好的性能。
- 同时也是第一次将CNN和Transformer相结合应用于超分方向的一次大胆尝试。
1. 超分基本知识
1.1 SRF
SRF是指超分辨率因子(Super-Resolution Factor),也称为上采样倍率,是指将低分辨率图像放大到高分辨率图像的大小时所使用的比例因子。
一般来说,低分辨率图像的大小是高分辨率图像大小的一个较小比例,因此在进行超分辨率重建时,需要将低分辨率图像放大到与高分辨率图像相同的大小,这就需要使用上采样操作。而上采样的倍率就是超分辨率因子,即 SRF。
因此,在超分辨率算法中,常常会看到 SRF 的设置,用来指定超分辨率因子,也就是放大倍数。例如,如果 SRF=2,则表示将低分辨率图像放大2倍,得到高分辨率图像。这也是为什么在很多超分辨率数据集中,数据集的文件名通常会标注 SRF 值,方便进行比较和评估。
1.2 xxx_img
- gt_img:对应的高分辨率图像。
- sr_img:超分辨率算法输出的图像
- hr_img:高分辨率图像。
- lr_img:低分辨率图像。
对于一个训练样本,它包含一个低分辨率图像和一个对应的高分辨率图像,这两张图像就分别对应着ESRT中的lr_img和hr_img。
模型的训练过程就是输入低分辨率图像lr_img,输出对应的超分辨率图像sr_img,并计算sr_img与对应的高分辨率图像gt_img之间的差异,以此来更新模型参数。
在测试过程中,sr_img指的是模型输入低分辨率图像lr_img后输出的超分辨率图像,而gt_img是参考答案,即高分辨率图像。
超分辨率算法的目标就是尽可能准确地将低分辨率图像转换为高分辨率图像,因此模型输出的sr_img与真实的高分辨率图像gt_img应该尽量接近。
1.3 裁剪
shave()函数是用于对模型输出的超分辨率图像进行修剪的函数。
具体来说,由于超分辨率算法会对低分辨率图像进行上采样处理,因此在得到超分辨率图像后,我们需要将其裁剪成与原始高分辨率图像相同的大小。
1.4 超分模型评估标准
常用的评估指标包括峰值信噪比(PSNR)、结构相似性(SSIM) 和 感知质量指标(LPIPS) 等。这些指标可以帮助评估模型的超分辨能力和图像质量,从而确定模型是否适合用于特定的应用场景。
compute_psnr()函数要求的两张图片是原图(ground-truth image,gt_img)和重建图(super-resolution image,sr_img)。
其中,原图是指高分辨率的参考图像,也就是输入超分辨率算法的高分辨率图像。重建图是指由超分辨率算法生成的低分辨率图像的超分辨率重建图像,是与原图相对应的输出图像。
compute_psnr()函数的作用是计算两张图片的 PSNR 值。通过比较重建图与原图之间的 PSNR 值,可以评估超分辨率算法的性能。
在ESRT模型中,avg_psnr 和 avg_ssim 是两个用来评估模型性能的指标。
PSNR是图像质量评估中常用的一种指标,代表峰值信噪比(Peak Signal-to-Noise Ratio),通常用来衡量重构图像与原始图像之间的差异,公式如下:
PSNR = 10 * log10( 2552 / MSE)
其中,MSE是均方误差(Mean Squared Error),255代表图像中每个像素的最大值。
在ESRT模型中,avg_psnr 是指模型对所有测试图像进行预测后,预测结果与原始高分辨率图像之间的PSNR的平均值。该指标的值越大,表示模型预测的结果越接近于原始高分辨率图像。
SSIM是图像质量评估中另一种常用的指标,代表结构相似性(Structural Similarity),通常用来衡量重构图像与原始图像之间的结构相似性,公式如下:
SSIM(x, y) = (2 * μ_x * μ_y + c1) * (2 * σ_xy + c2) / (μ_x2 + μ_y2 + c1) * (σ_x2 + σ_y2 + c2)
其中,x和y分别代表原始高分辨率图像和模型预测的结果,μ表示像素的均值,σ表示像素的标准差,c1和c2是常数,通常为(0.01 * 255)^2和(0.03 * 255)^2。
在ESRT模型中,avg_ssim 是指模型对所有测试图像进行预测后,预测结果与原始高分辨率图像之间的SSIM的平均值。该指标的值越接近于1,表示模型预测的结果越接近于原始高分辨率图像。
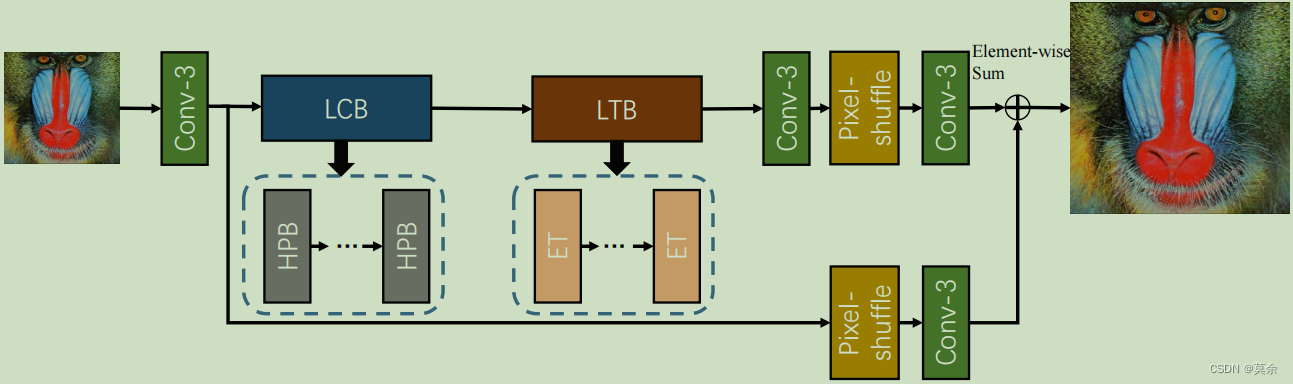
2. LCB、LTB 模块
具体而言,ESRT 的网络架构包含了局部特征提取(Local Context Block, LCB)和局部特征融合(Local Transformer Block, LTB)两个部分,以及多层的 Transformer Encoder 和 Decoder。
- LCB 用于提取低分辨率图像的局部特征
- LTB 则用于对这些局部特征进行有效的融合
ET只使用了transformer中的encoder
每个 Transformer Encoder 包含一个 Multi-Head Self-Attention 层,一个 Feed-Forward 层,以及一个残差连接。
每个 Transformer Decoder 则包含一个 Multi-Head Self-Attention 层、一个 Multi-Head Cross-Attention 层、一个 Feed-Forward 层,以及一个残差连接。
通过 LCB 和 LTB 模块的组合,ESRT 算法能够充分提取图像的局部信息,同时增强图像的多尺度特征表示,从而实现更加准确、细致的超分辨率重建。
2.1 序列模型
sequential(*args) 函数是用来创建一个序列模型的函数。该函数将一系列网络层传入,按照传入的顺序将它们打包成一个序列模型,并返回该模型。
例如,下面的代码创建了一个包含三个卷积层和三个批量归一化层的序列模型:
model = sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 3, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(3)
)
3. 损失函数
ESRT 采用了一种混合损失函数,同时考虑了 L1 Loss 和 Perceptual Loss。此外,为了提高模型的鲁棒性,ESRT 还采用了一种增量训练方法。
4. 部署运行
4.1 数据集
4.1.1 训练集
下载DIV2K数据集,https://data.vision.ee.ethz.ch/cvl/DIV2K/
下载如下标注的数据集即可。

4.1.2 验证集
Set5/Urban100/BSD100……
下载链接如下:
https://www.aliyundrive.com/s/JD4ZkSmbH1g
提取码: 71fe
任选其中一种即可。
4.1.3 测试集
自己的低分辨率数据集即可。
4.2 数据集转换
python scripts/png2npy.py --pathFrom /path/to/DIV2K/ --pathTo /path/to/DIV2K_decoded/
python scripts/png2npy.py --pathFrom E:\Projects\pythonprojects\ESRT-main\DIV2K\ --pathTo E:\Projects\pythonprojects\ESRT-main\DIV2K_decoded\
4.3 训练
python train.py --scale 4 --patch_size 192
注意:scale的参数根据SRF而定。
4.4 测试
python test.py --is_y --test_hr_folder datasets/Set14/HR/ --test_lr_folder datasets/Set14/LR_bicubic/x4/ --output_folder results/Set14/x4 --checkpoint experiment/checkpoint_ESRT_x4/epoch_990.pth --upscale_factor 4
python test2.py --is_y --test_lr_folder datasets/Set14/LR_bicubic/x4/ --output_folder results/Set14/x4 --checkpoint experiment/checkpoint_ESRT_x4/epoch_990.pth --upscale_factor 4
python test.py --is_y --test_lr_folder datasets/Set14/LR_bicubic/x4/ --output_folder results/Set14/x4 --checkpoint experiment/checkpoint_ESRT_x4/epoch_990.pth --upscale_factor 4
4.5 效果
在只有低分辨率的图像上进行测试,为了能够得到较好的分辨率效果。
设置SRF为4,一张3K的图像超分之后变成了70多M。且不说与MOT结合的价值意义,反正看高清电影是不用愁了。