Kaldi语音识别技术(七) ----- GMM
文章目录
- Kaldi语音识别技术(七) ----- GMM
- 训练GMM
- train_mono.sh 用于训练GMM
- 训练GMM—生成文件
- 训练GMM—final模型查看
- 训练GMM—final.occs查看
- 训练GMM—对齐信息查看
- 训练GMM—fsts.*.gz查看
- 训练GMM—tree决策树查看
- align_si.sh 用于对齐
- 训练GMM—查看mono_ali.sh 生成内容
- 训练GMM—比对mono和mono_ali对齐信息
训练GMM
前面文章中我们讲了相比DTW,GMM的优点,那么我们怎么获取训练GMM呢?
GMM的训练流程如下图:
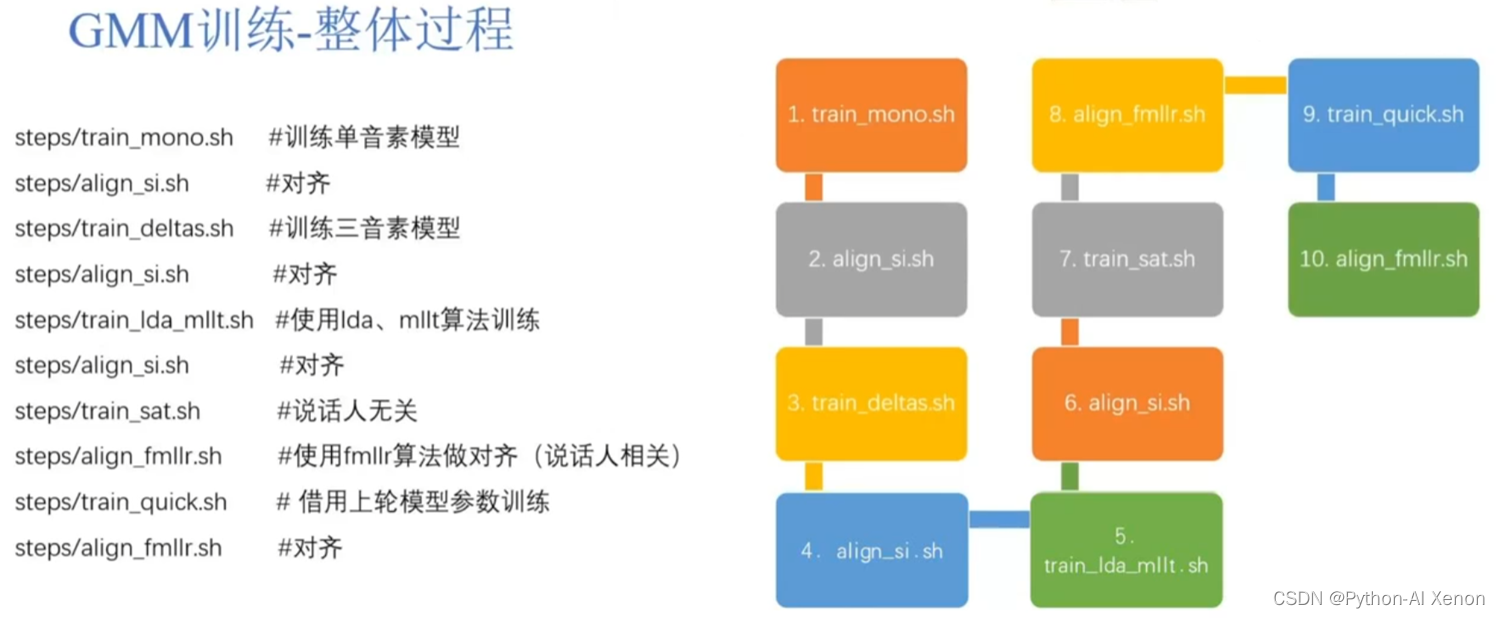
整个过程分为10个环节,其中有5个是与对齐相关的,为了方便理解,这10个环节,只讲其中的2个(train_mono 单因素训练模型和align_si对齐),其他的基本都是进行优化,大家以后涉及这一块可以自行百度。大致的流程是先训练一个高斯模型,使用这个高斯模型对训练数据进行对齐,然后使用对齐后的数据再训练一个高斯模型。如(上面右侧的图),最开始,先训练一个单音素模型,然后使用单音素模型对训练数据进行对齐,然后基于这些对齐数据,再训练一个三音素模型,然后再使用三音素模型对训练数据进行对齐,然后再使用lda、mllt等算法重估GMM模型,然后再对训练数据进行对齐,然后对模型进行说话人无关和相关操作,最后再次对训练数据进行对齐。整个GMM训练模型的过程就是这样。总的来说,模型训练得越好,对齐就对得越准,就越可以提高语音识别的准确度。
训练GMM—mono训练流程
我们来看下单音素模型是怎么训练的,首先训练一个模型,必须先要有一个起始模型,然后在再这个起始模型上进行迭代训练。所以kaldi就调用了gmm-init-mono来初始化模型,它使用了训练数据中特征来初始化模型。初始化好模型后,就是制作graph,这个图的输入有好几个,有初始化的模型,有lang文件中的L.fst,还有词典及训练数据中的文本,生成的结果是一个句子到音素级别的fst的压缩包(gz)。
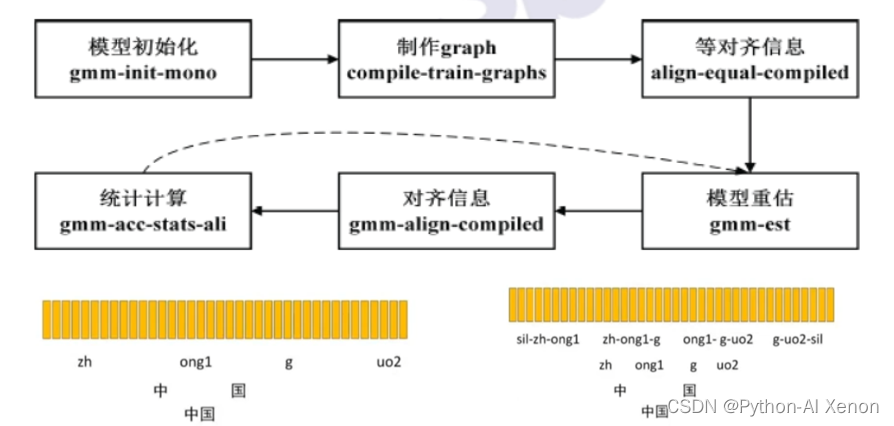
我们完成前面2步后,如何使用我们提取好的特征与制作的FST图对应起来,这就需要对齐。第三步使用了均匀对齐(图中的等对齐),前面也讲过FST是把标签文件的句子细化拆分到词、到字、到音素,再到HMM中的状态。
为了方便理解,图中我们只细化到音素,将词(中国)拆分为字(中和国),再拆分为音素(zh,ong1,g,uo2),每一个字有2个音素,总共4个音素,上面的黄色竖条分别代表一帧特征(MFCC特征),这里的均匀对齐就是假设有上诉4个音素,有100帧特征,每个音素就均匀分到了25帧特征,分别求这25帧特征的均值和方差,就可以得到相应的高斯模型了。
图下部分为我们的三音素模型(考虑了协同发音),三音素模型的数据量很大,所以在kaldi中使用了决策树聚类,将一些相近发音的音素聚合在一起归为一类,然后集中训练。在均匀对齐后,我们就要进行模型重估了,初始化模型是在部分训练数据中随机出来的,现在我们已经统计了全部音频数据的特征,及通过均匀对齐,每帧特征对应的状态及跳转概率。基于这些信息,我们对模型进行重估,下一步,对重估后的模型对齐数据(第五步),此时我们就不是使用均匀对齐的方式,而是使用重估模型后的统计量,并结合前面所做的fst生成新的对齐信息,这个过程可以简单理解为一个模型对训练集的解码过程,把每帧数据对应的特征放到每个音素或者每个状态对应的GMM中算概率,概率最大的音素就是这一帧对应的音素,如前面我们说的每个音素对应25帧,经过这一步后,每个音素对应的就变化了(假设第一个音素就对应20帧了)。基于这些对齐信息,我们就可以统计计算每个音素的跳转次数占全部跳转次数的比列,这样就可以重估HMM网络中每个状态的跳转概率,然后更新这些状态转移概率和每一帧的对齐信息后,又可以重估我们的GMM模型(第六步跳到第四步),就这样反复的重估模型,生成新的对齐信息,统计转移概率,然后再重估模型。具体这样多少次由我们自行设置,默认为40次。
train_mono.sh 用于训练GMM
我们来看下单音素模型在Kaldi中具体是怎么训练的,是调用step文件夹下的train_mono.sh脚本。特别要注意,如果使用多线程参数,nj数不能超过说话人数(spekerid),它是按照说话人数来进行分线程数的。
train_mono.sh 用法:
./steps/train_mono.sh
Usage: steps/train_mono.sh [options] <data-dir> <lang-dir> <exp-dir>
e.g.: steps/train_mono.sh data/train.1k data/lang exp/mono
main options (for others, see top of script file)
--config <config-file> # config containing options
--nj <nj> # number of parallel jobs
--cmd (utils/run.pl|utils/queue.pl <queue opts>) # how to run jobs.
参考:Kaldi 入门详解 train_mono.sh 官方文档
首先准备一下kaldi环境
. ~/kaldi/utils/path.sh
mkdir H_learn
cd ~/kaldi/data
然后执行脚本
./steps/train_mono.sh --nj 2 --cmd "run.pl" H/kaldi_file_test L/lang H/mono
参数详解:
第一个参数:–nj 几个线程并行训练 (注:如果是提取的每个说话人的特征,nj数不能超过说话人数)
第二个参数:run.pl 本机运行
第三个参数:特征文件夹(含cmvn以及原始的mfcc特征,见专栏博文五)
第四个参数:lang文件夹(L文件夹中的lang文件夹)
第五个参数:输出GMM训练数据(单音素模型)文件夹
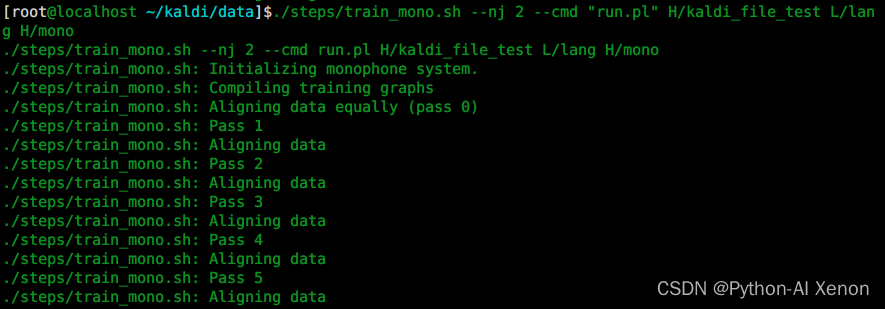
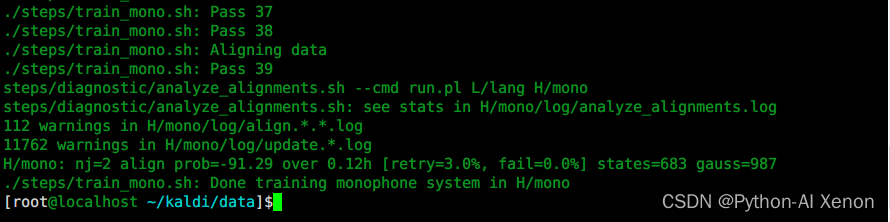
训练GMM—生成文件
使用train_mono.sh训练单音素模型后,我们生成了这些文件,首先最重要的肯定是模型(mdl,其中0.mdl表示初始化的模型;40.mdl表示迭代了40次的结果;final.mdl表示最终模型),其次是occs结尾的文件,可以简单理解为是一个全局统计量,统计每个音素或者每个音素对应几个状态的信息。ali..gz是对齐信息,每迭代一次模型,对齐信息就会更新一次。fst..gz是网格信息,就是我们前面所讲的一些FST信息。tree是决策树,是将发音类似的一些音素聚集成一类,方便计算。log是训练过程中产生的日志,如果训练过程中出现错误,基本都能在这里面找到相应的错误信息。

*.mdl:模型 0.mdl表示初始化的模型;40.mdl表示迭代了40次的结果;final.mdl表示最终结果。
*.occs:每个pdf出现的个数
ali.*.gz:对齐信息
fst.*.gz:网格信息
tree:决策树
log :训练过程log
训练GMM—final模型查看
将final.mdl的数据转换为文本并输出到final_mdl.txt文本中 (–binary=false 表示不使用二进制数据)
gmm-copy --binary=false final.mdl final_mdl.txt
vim final_mdl.txt 打开文件如下:
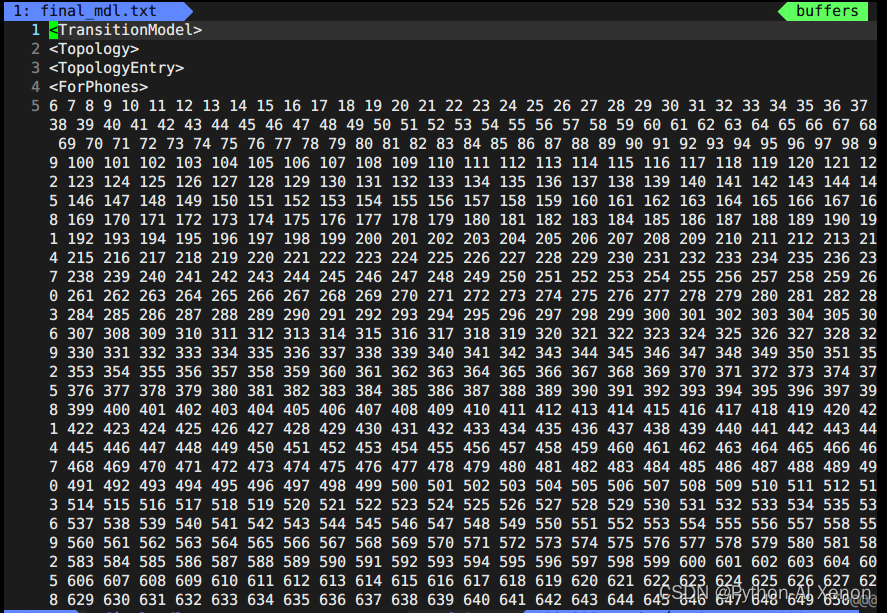
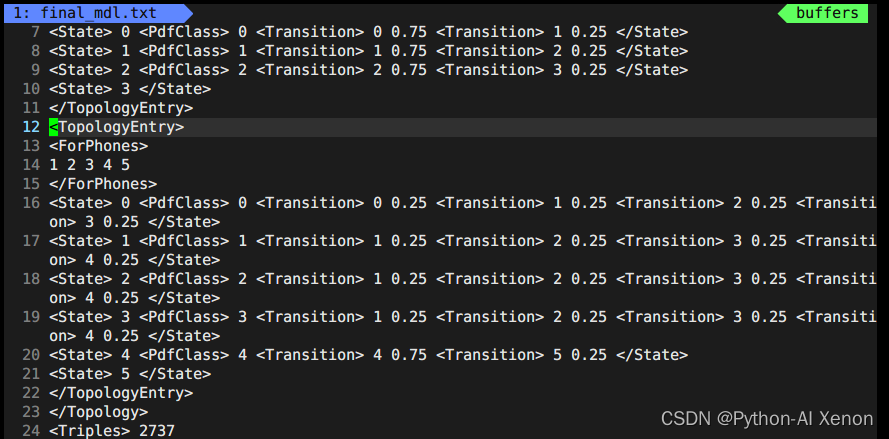
这里面前面23行前面我们生成G.fst时生成的topo文件中有这部分信息。我们可以画出相应的HMM状态,即6-909状态共用一个HMM3状态,1-5(静音音素)共用一个HMM5状态,第24行2727表示我们决策树聚类的个数。决策树信息中:第一列为音素索引(phone-id),第二列为HMM状态,第三列为PDF索引(决策树的类)
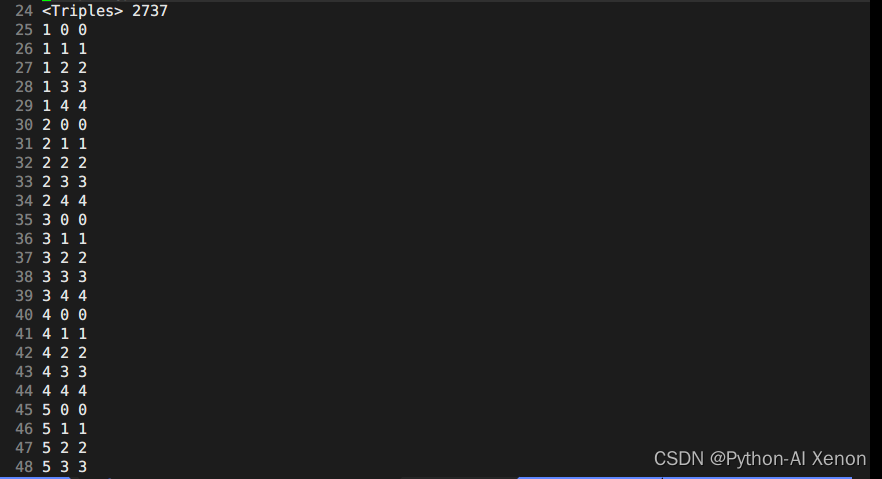
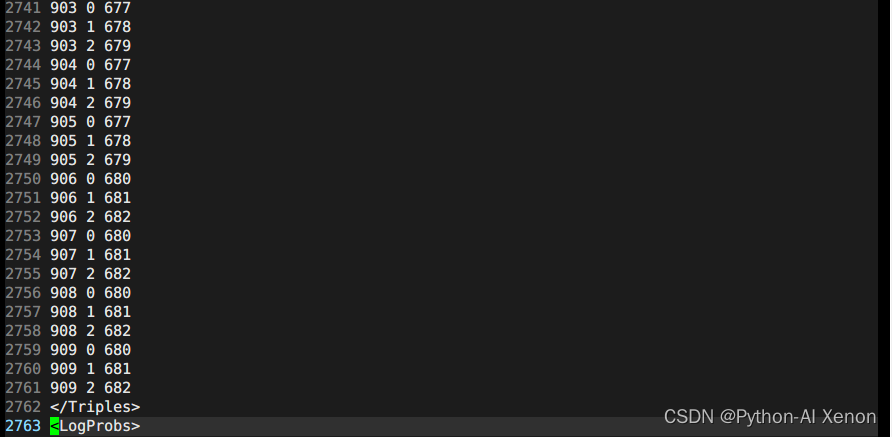
我们可以看见我们的音素总共有909个,那么为什么可以聚为2737个类呢?可以在图中看见,从25行开始到49行总共25行的第二列看出,他们都属于静音音素(为什么?序号都是0-4,5个状态,只有静音音素才有5个状态)。最终我们可以得出聚类的个数公式为:
决策树类的个数 = 静音音素数 * 5 + 非静音音素 * 3


由于决策树中其他信息较多,大家可自行打开本机决策树信息查看,<LogProbs> 中的信息为每个类的转移概率,<dimension>中的数字为输入特征(MFCC)的3倍,是因为输入的特征做了一阶差分和二阶差分,再加上原来的特征就是这个数字39,<numpdfs>就是我们的决策树类的个数,每一个类都可以对应一个高斯混合模型(GMM)。下面的就是对图中的656个GMM的描述,一个高斯模型的描述只需要均值和方差即可(知道就行),如果是一个混合高斯的话,就需要多个高斯组合在一起,就需要每个高斯的在混合高斯中的权重,如上图中的权重<weights>中有2个权重,那么就说明描述这个音素的概率的混合高斯是由2个单高斯组成的,各自的权重分别是XXX,XXX,均值有39列,1个高斯对应1个39维的均值,2个高斯就有2个均值。同样的,方差也是一样的。除了权重,这里还有一个超参<gconsts>,也是一个高斯对应一个。这里不在过多的进行深度介绍。
训练GMM—final.occs查看
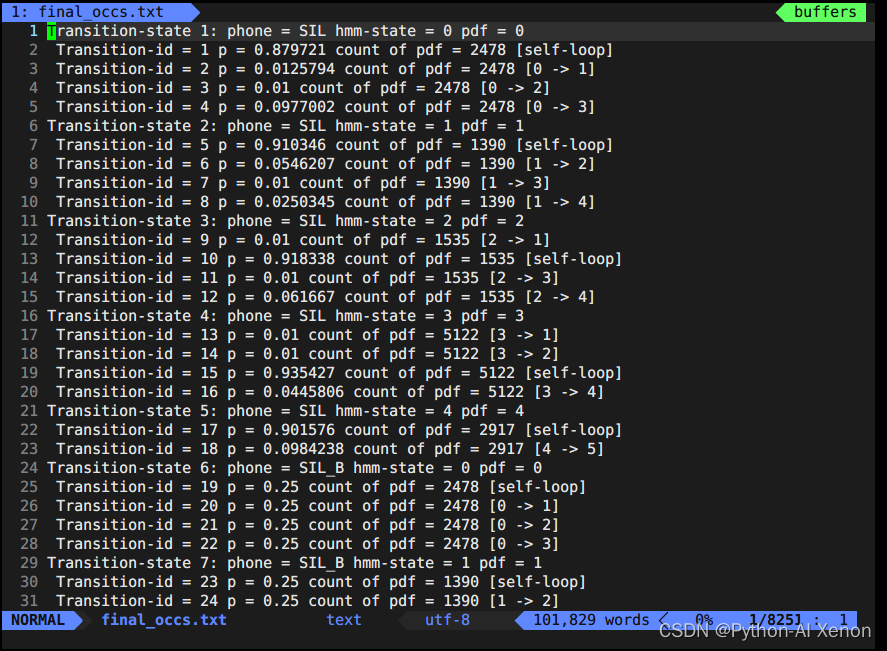
接下来我们看下final.occs文件,可以简单把它理解为是一个全局统计量,统计每个音素或者每个音素对应几个状态的信息。即对每个HMM网络的描述。前面我们讲过每个音素又可以细分为BEIS(分别对应几个状态),我们知道HMM静音音素有5个状态(BEIS+自身5个状态),非静音音素BEI3个状态。occs就是将每个音素拆分后分别进行统计。Transition-state是对每个状态的描述,其中count of pdf中的数字表示这个边出现的次数。
统计每个音素或者每个音素对应几个状态的信息
show-transitions phones.txt final.mdl final.occs > final_occs.txt
vim final_occs.txt 打开文件如下:
训练GMM—对齐信息查看
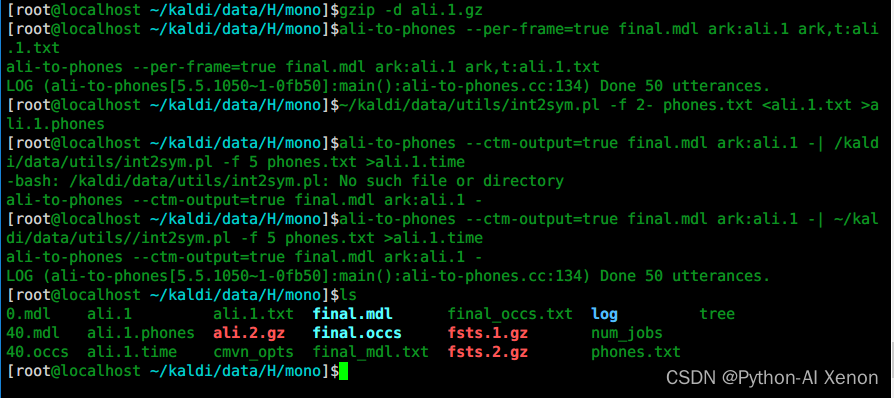
# 1 解压
gzip -d ali.1.gz
提特征按帧级别提的,训练也是按帧级别训练的,训练的结果是什么?可以通过ali-to-phones 命令查看我们哪几帧对应哪一个音素,图中每一个数字表示一个音素Id,为方便查看,我们需要将音素id转换为对应音素。
# 2 使用ali-to-phones进行查看
ali-to-phones --per-frame=true final.mdl ark:ali.1 ark,t:ali.1.txt
每个phone-id对应的音素是什么?使用int2sym.pl 脚本可以将音素id转换为对应的音素,我们就可以看见每个音素的时间信息。
# 3 将音素id转换为对应的音素
~/kaldi/data/utils/int2sym.pl -f 2- phones.txt <ali.1.txt >ali.1.phones
每个音素持续的时间是多久? 比如这一句话“设定二十九度”,大家可以通过音频查看软件查看核实,由于我们现在使用的是单音素训练模型,对齐的不一定完全准确,所以需要多次反复对模型进行训练。
# 4 各音素的对齐时间信息
ali-to-phones --ctm-output=true final.mdl ark:ali.1 -| ~/kaldi/data/utils//int2sym.pl -f 5 phones.txt >ali.1.time
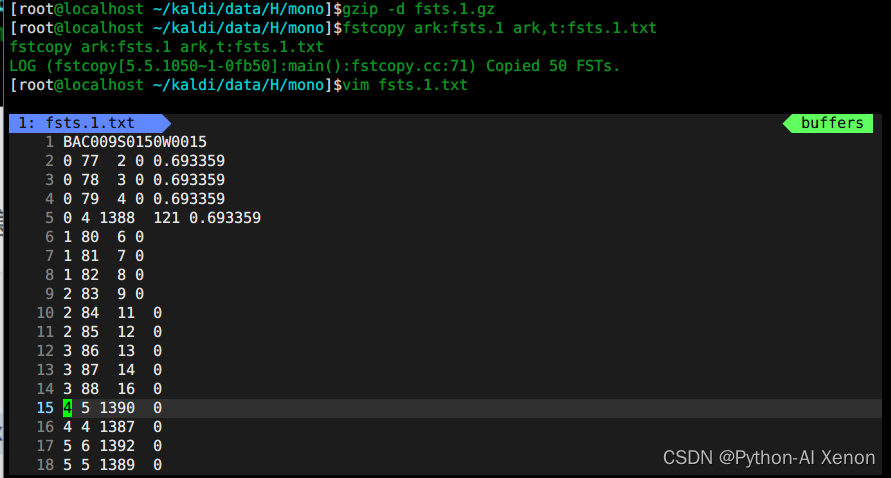
训练GMM—fsts.*.gz查看
这里面存储的是每个语句对应的fst网络结构信息,这里不过多赘述
# 1、解压
gzip -d fsts.1.gz
# 2、查看
fstcopy ark:fsts.1 ark,t:fsts.1.txt
vim fsts.1.txt
训练GMM—tree决策树查看
- 文本查看
tree-info tree

num-pdfs 683 表示:决策树类的个数,一共分了683个类
context-width 1 单音素模型不考虑相互音素,所以为1,如果是3音素模型的话,这里就是3
central-position 0 表示决策树的位置是0,如果是3音素,这里就是1(central表示中间音素,前面的为0,后面的为2)
- 可视化决策树
draw-tree phones.txt tree | dot -Gsize=8,10.5 -Tps | ps2pdf - tree.pdf
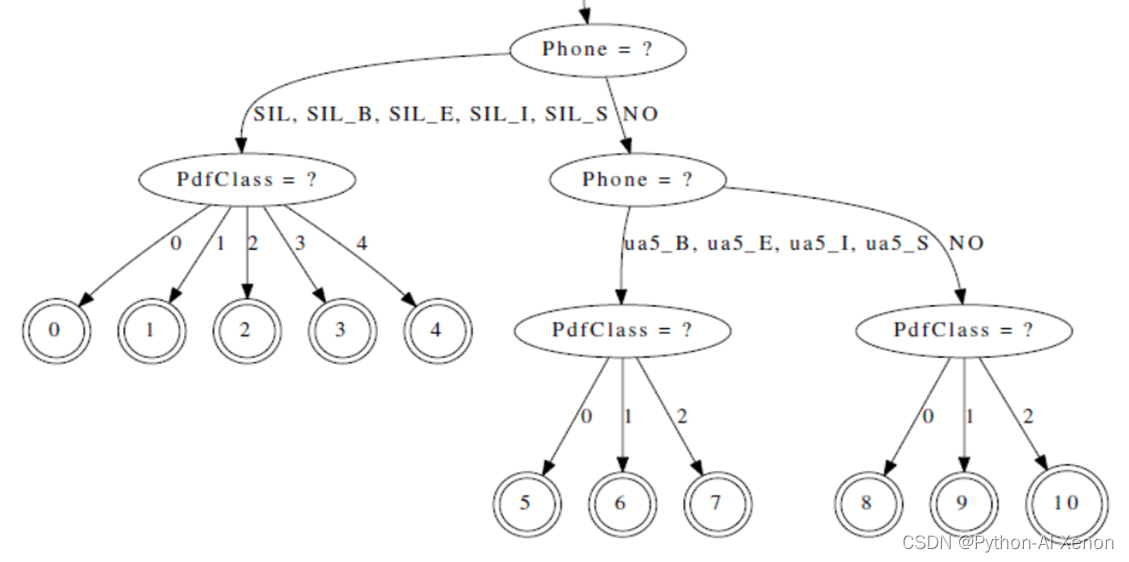
可以通过draw-tree命令把决策树可视化画出来,由于决策树很大,这里只截取了一部分,未显示完全,可在pdf中打开查看。从上图中可以看见,SIL静音音素是一个子节点,对应着5个节点(0-4节点),音素ua5对应着3个节点(5-7节点),就与前面所讲的对应起来了(静音音素5个状态,非静音音素3个状态)
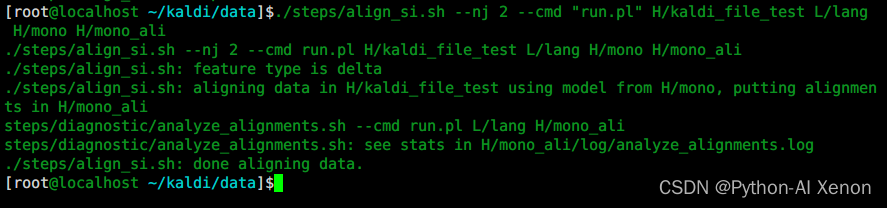
align_si.sh 用于对齐
用于对齐
单音素模型训练好后,接下来,我们就可以使用单音素模型对训练数据进行对齐。对齐命令为align_si.sh,这就是GMM训练模型的第二步。
cd ~/kaldi/data
./steps/align_si.sh --nj 2 --cmd "run.pl" H/kaldi_file_test L/lang H/mono H/mono_ali
参数详解:
第一个参数:–nj 几个线程并行训练 (注:如果是提取的每个说话人的特征,nj数不能超过说话人数)
第二个参数:run.pl 本机运行
第三个参数:特征文件夹(含cmvn以及原始的mfcc特征)
第四个参数:lang文件夹(L文件夹中的lang文件夹)
第五个参数:单音素训练模型文件夹
第六个参数:对齐后的数据文件夹
训练GMM—查看mono_ali.sh 生成内容

# 1、解压
gzip -d ali.1.gz
# 2、生成各音素的对齐时间信息
ali-to-phones --ctm-output=true final.mdl ark:ali.1 -|~/kaldi/data/utils/int2sym.pl -f 5 phones.txt >ali.1.time
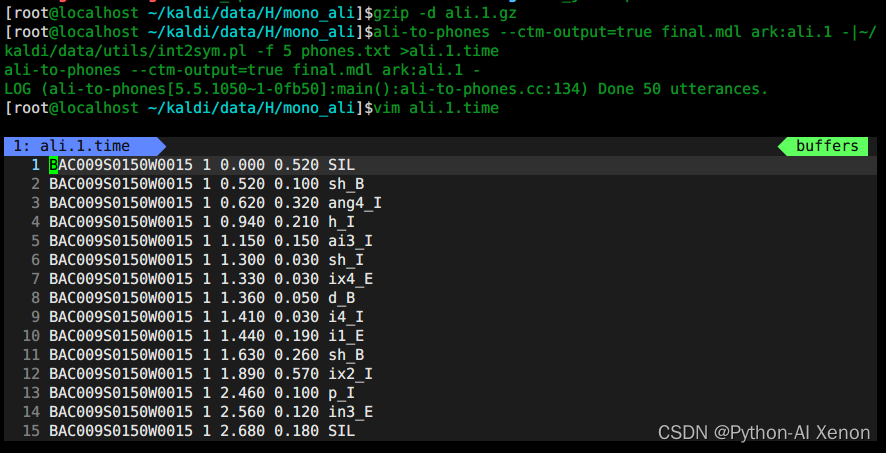
ps: 同样,我们也可以使用ali-to-phones命令查看对齐信息。
训练GMM—比对mono和mono_ali对齐信息
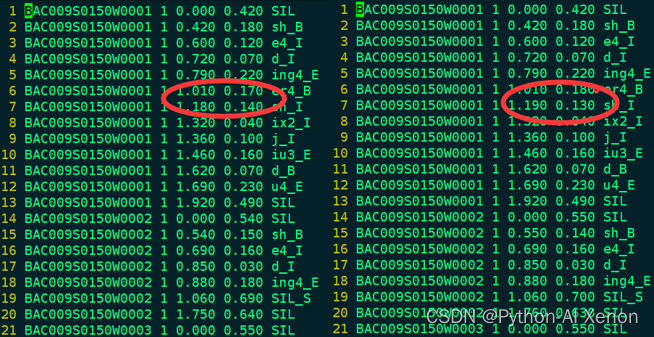
我们可以比较我们对齐后的信息与训练Mono时的对齐信息,可以看出2个文件的总行数相差不大,大部分对齐信息相差不大,说明单音素模型的对齐能力就这样了,需要换新的算法来提高模型的对齐能力。