数据结构(四)
- 一、树
- 1.树结构
- 2.树的常用术语
- 二、二叉树
- 1.什么是二叉树
- 2.二叉树的数据存储
- (1)使用数组存储
- (2)使用链表存储
- 三、二叉搜索树
- 1.这是什么东西
- 2.封装二叉搜索树:结构搭建
- 3. insert插入节点
- 4. 遍历二叉树
- (1)前序遍历
- (2)中序遍历
- (3)后序遍历
- (4)测试代码
- 5.最大值和最小值
- 6.search查找特定的值
- 7.删除某个节点(难上加难)
- (1)找到节点
- (2)情况一:删除的节点没有子节点
- (3)情况二:删除的节点只有一个子节点
- (4)情况三:删除的节点有两个子节点
本节详细笔记请参考大佬博客:二叉树的理解
一、树
1.树结构
- 树(Tree):由 n(n ≥ 0)个节点构成的有限集合。当 n = 0 时,称为空树。
对于任一棵非空树(n > 0),它具备以下性质: - 数中有一个称为根(Root)的特殊节点,用r表示;
- 其余节点可分为 m(m > 0)个互不相交的有限集合 :T1,T2,…,Tm,其中每个集合本身又是一棵树,称为原来树的子树(SubTree)。
2.树的常用术语

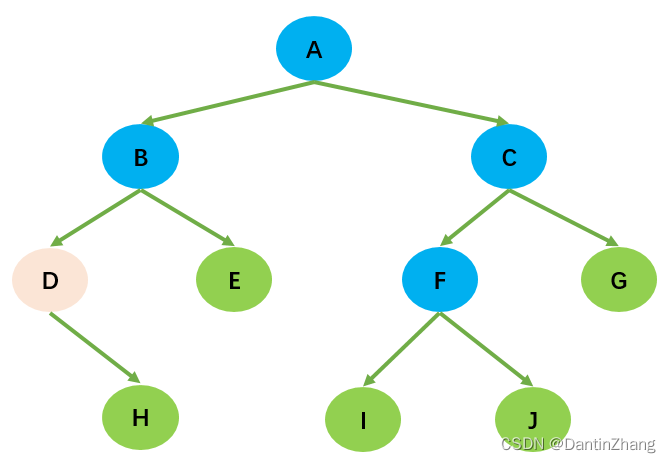
- 节点的度(Degree):节点的子树个数,比如节点B的度为2; 树的度:树的所有节点中最大的度数,如上图树的度为2;
- 叶节点(Leaf):度为0的节点(也称为叶子节点),如上图的H,I等;
- 父节点(Parent):度不为0的节点称为父节点,如上图节点B是节点D和E的父节点;
- 子节点(Child):若B是D的父节点,那么D就是B的子节点;
- 兄弟节点(Sibling):具有同一父节点的各节点彼此是兄弟节点,比如上图的B和C,D和E互为兄弟节点;
- 路径和路径长度:路径指的是一个节点到另一节点的通道,路径所包含边的个数称为路径长度,比如A->H的路径长度为3;
- 节点的层次(Level):规定根节点在1层,其他任一节点的层数是其父节点的层数加1。如B和C节点的层次为2;
- 树的深度(Depth):树种所有节点中的最大层次是这棵树的深度,如上图树的深度为4;
二、二叉树
1.什么是二叉树
如果树中的每一个节点最多只能由两个子节点,这样的树就称为二叉树;
二叉树的特性:
1、 一个二叉树的第 i 层的最大节点树为:2(i-1),i >= 1;
2、 深度为k的二叉树的最大节点总数为:2k - 1 ,k >= 1;
3、对任何非空二叉树,若 n0 表示叶子节点的个数,n2表示度为2的非叶子节点个数,那么两者满足关系:n0 = n2 +1;如上图所示:H,E,I,J,G为叶子节点,总数为5;A,B,C,F为度为2的非叶子节点,总数为4;满足n0 = n2 + 1的规律。
2.二叉树的数据存储
常见的二叉树存储方式为数组和链表
(1)使用数组存储
完全二叉树,按照从上到下,从左到右的顺序存储
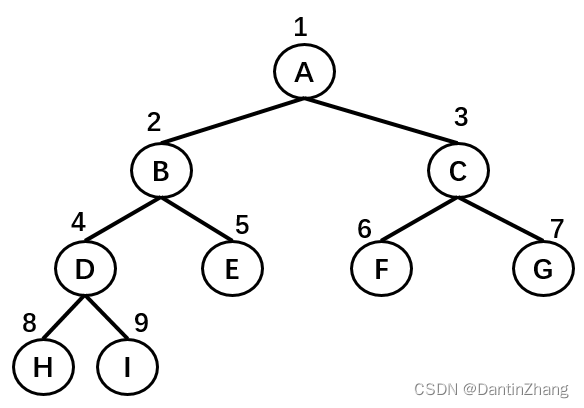
使用数组存储时,取数据的时候也十分方便:左子节点的序号等于父节点序号 * 2,右子节点的序号等于父节点序号 * 2 + 1 。
[0,1,2,3,4,5,6,7,8,9] => [A,B,C,D,E,F,G,H,I]
非完全二叉树需要转换成完全二叉树才能按照上面的方案存储,这样会浪费很大的存储空间。

[0,1,2,3,4,5,6,7,8,9,10,11,12,13] =>
[A,B,C,null,null,F,null,null,null,null,null,null,M,]
(2)使用链表存储
二叉树最常见的存储方式为链表:每一个节点封装成一个Node,Node中包含存储的数据、左节点的引用和右节点的引用。
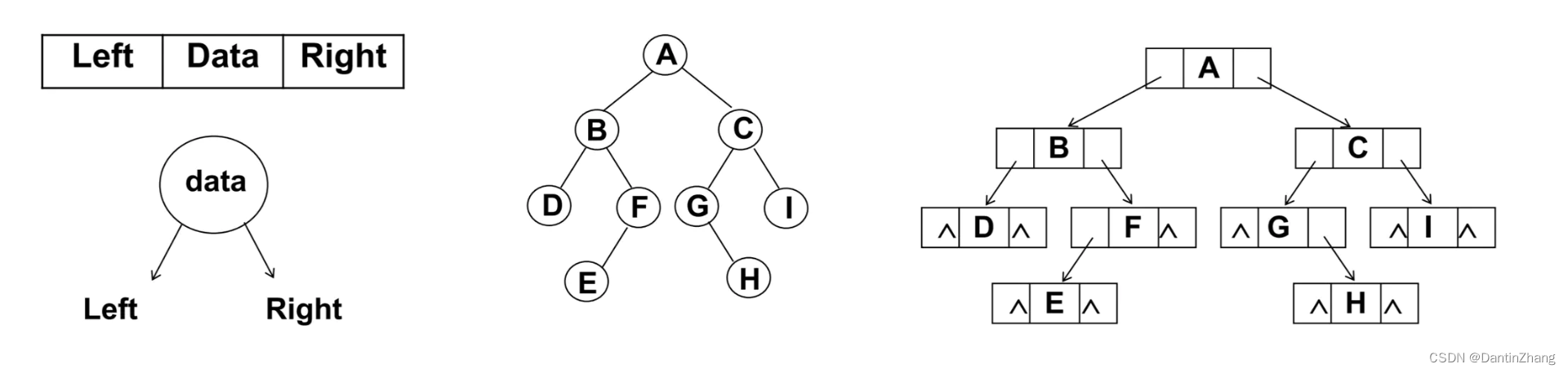
三、二叉搜索树
1.这是什么东西
二叉搜索树(BST,Binary Search Tree),也称为二叉排序树和二叉查找树。
二叉搜索树是一颗二叉树,可以为空,但是如果不为空的话,需要满足以下条件。
条件1:非空左子树的所有键值小于其根节点的键值。比如三中节点6的所有非空左子树的键值都小于6;
条件2:非空右子树的所有键值大于其根节点的键值;比如三中节点6的所有非空右子树的键值都大于6;
条件3:左、右子树本身也都是二叉搜索树;
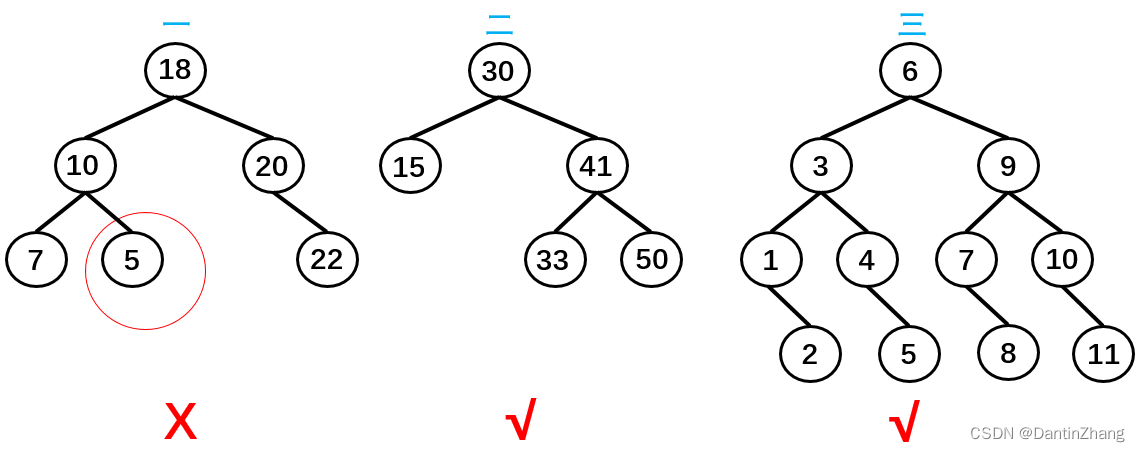
总结:二叉搜索树的特点主要是较小的值总是保存在左节点上,相对较大的值总是保存在右节点上。这种特点使得二叉搜索树的查询效率非常高,这也就是二叉搜索树中"搜索"的来源。
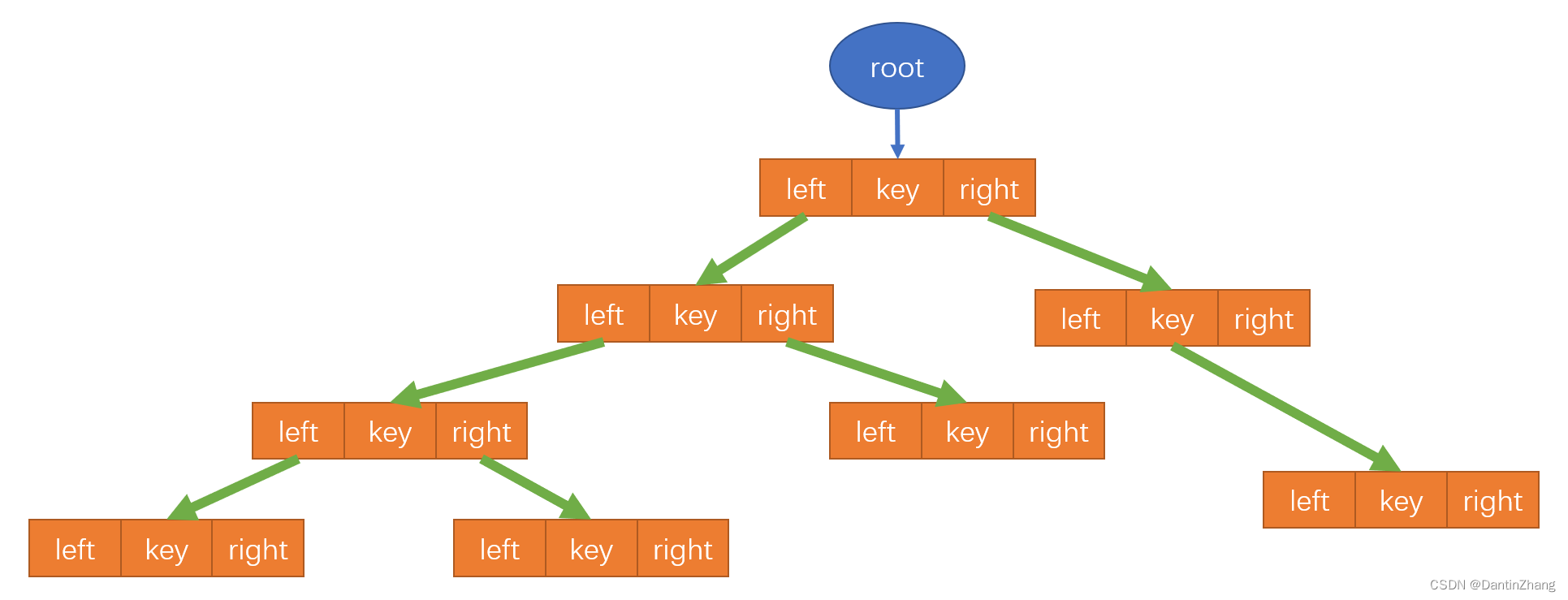
2.封装二叉搜索树:结构搭建
作为一个二叉搜索树,应该有一个内部类,该类是节点类,应该包含left、key、right三个属性,分别存储的是左子树,键值,右子树。(其实再加个value才对)
3. insert插入节点
主要思路:
1、新建节点类实例,传入键值
2、判断有没有根节点,如果没有根节点,就让根节点指向新插入的节点
3、如果有根节点,就要使用递归,依次向后查找并插入
//插入数据
insert(key) {
//1.先生成新的节点
let newNode = new Node(key);
//2.判断有没有根节点
if(this.root == null) {
//2.1如果没有根节点,那么当前插入的就是根节点
this.root = newNode;
}else {
//2.2如果有根节点,就调用递归函数
this.insertRecursion(this.root, newNode);
}
}
那么递归的思路又是什么呢?(其实用循环也可以,但是递归更好)
1、接收一个current参数,指向当前的节点
2、判断插入的节点和当前节点键值大小关系,如果小往左查找,大往右查找
3、以往左查找为例,如果左边节点是空,那么就直接添加到左边
4、如果左边还有节点,那么就要递归调用本函数,继续向下查找。
//插入操作的递归函数(依次向下查找)
insertRecursion(current, newNode) {
//1.看一下要往哪边查找
if(newNode.key < current.key){
//2.1向左查找
if(current.left == null) {
//3.1如果左节点为空,那么就直接插入
current.left = newNode;
}else {
//3.2如果左节点不为空,就递归调用,直到一直到叶子节点
this.insertRecursion(current.left, newNode);
}
} else {
//2.2向右查找,同理
if(current.right == null) {
current.right = newNode;
} else {
this.insertRecursion(current.right, newNode);
}
}
}
测试代码:
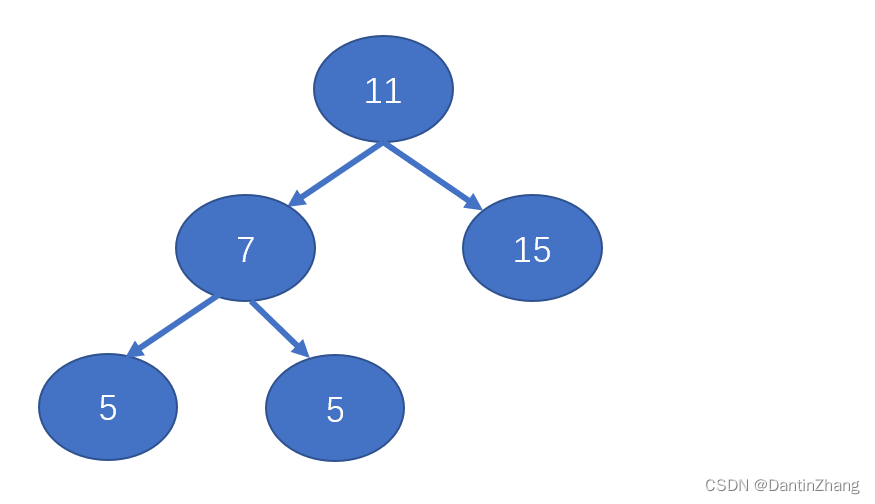
//测试代码
let bst = new BinarySearchTree();
bst.insert(11);
bst.insert(7);
bst.insert(15);
bst.insert(5);
bst.insert(9);
console.log(bst);
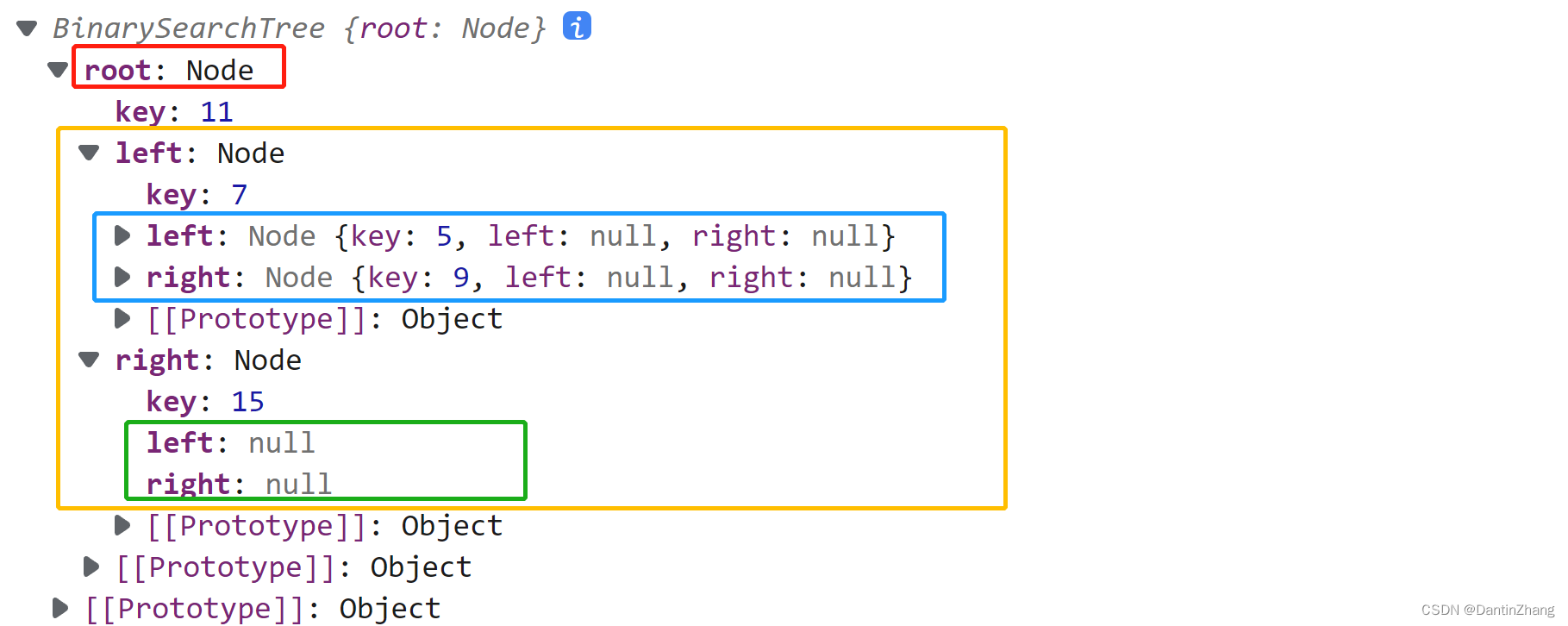
这样插入得到的树应该长下面这个样子:
4. 遍历二叉树
这里涉及到递归的概念,去看这个老师的视频,讲的非常好:递归和函数调用栈
这个大佬的博客写的也非常好:二叉搜索树的遍历和递归
要先搞清楚递归和函数调用栈的概念,递归函数执行时,先执行函数上文,遇到递归调用时卡住,先依次入栈,全部入栈后依次执行函数下文,然后出栈。
function f(n) {
console.log(n+' 入栈');
if(n==0) return 0;
n + f(n-1);
console.log(n+' 出栈');
}
f(3);
结果:3 入栈 => 2 入栈 => 1 入栈 => 0 入栈 => 1 出栈 => 2 出栈 => 3 出栈

(1)前序遍历
根节点 => 左子树 => 右子树
有了上面的递归和函数调用栈的理解,这里就比较好理解了。

我们先来看一下代码:
//2.1前序遍历的递归函数
preOrderRecursion(node) {
if(node == null) return false;
console.log(node.key);
this.preOrderRecursion(node.left); //递归1
//递归完成后调用的是上一个栈顶函数的下一个过程,所以来到了node.right
this.preOrderRecursion(node.right); //递归2
}
//2.2前序遍历
preOrderTraversal() {
this.preOrderRecursion(this.root);
}
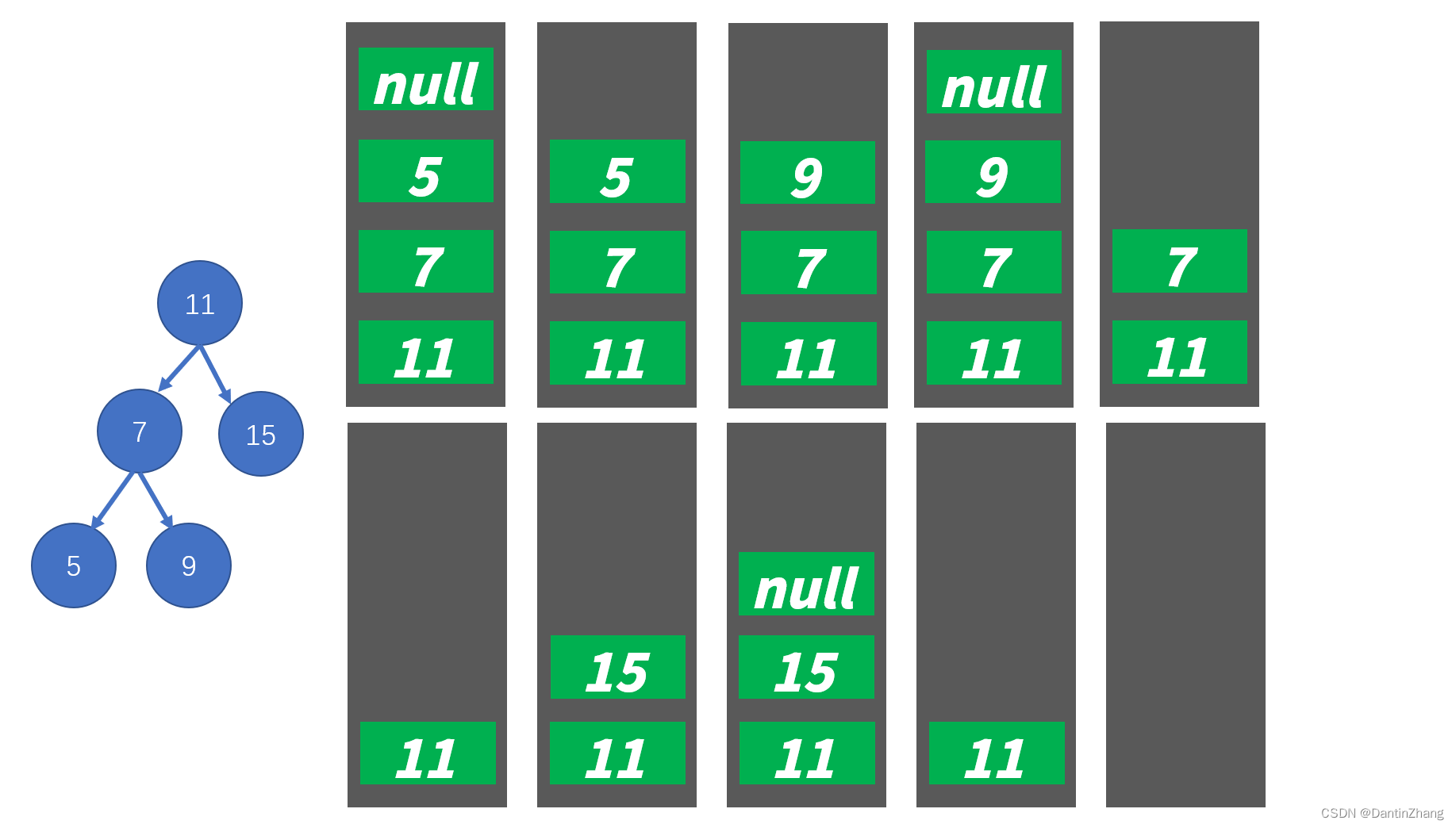
解析一下上面的图:
第一次调用传入的是根节点,输出11入栈 =>
卡在11的递归1(node.left 指向 7) =>
11的递归1调用,输出7入栈 =>
卡在7的递归1(node.left 指向 5) =>
7的递归1调用,输出5入栈 =>
卡在5的递归1(node.left 指向 null) =>
直接return了,5的左子节点null的递归函数出栈 =>
进入5的递归2,函数执行5的下文,卡在5的递归2(node.right 指向 null) =>
5的递归2调用,直接return,5右子节点的递归函数出栈 =>
5执行完毕,出栈 =>
执行7的递归2(node.right 指向 9)=>
7的递归2调用,输出9入栈 =>
卡在9的递归1(node.left 指向 null) =>
直接return了,9的左子节点null的递归函数出栈 =>
进入9的递归2,函数执行9的下文,卡在9的递归2(node.right 指向 null) =>
9的递归2调用,直接return,9右子节点的递归函数出栈 =>
9执行完毕,出栈 =>
7执行完毕,出栈 =>
11的递归1执行完毕,进入11的递归2,函数执行11的下文(node.right 指向 15) =>
11的递归2调用,输出15入栈 =>
15的递归1调用,直接return,15左子节点的递归函数出栈 =>
15的递归2调用,直接return,15右子节点的递归函数出栈 =>
11执行完毕,出栈,遍历结束!!!
其实就是一直套娃
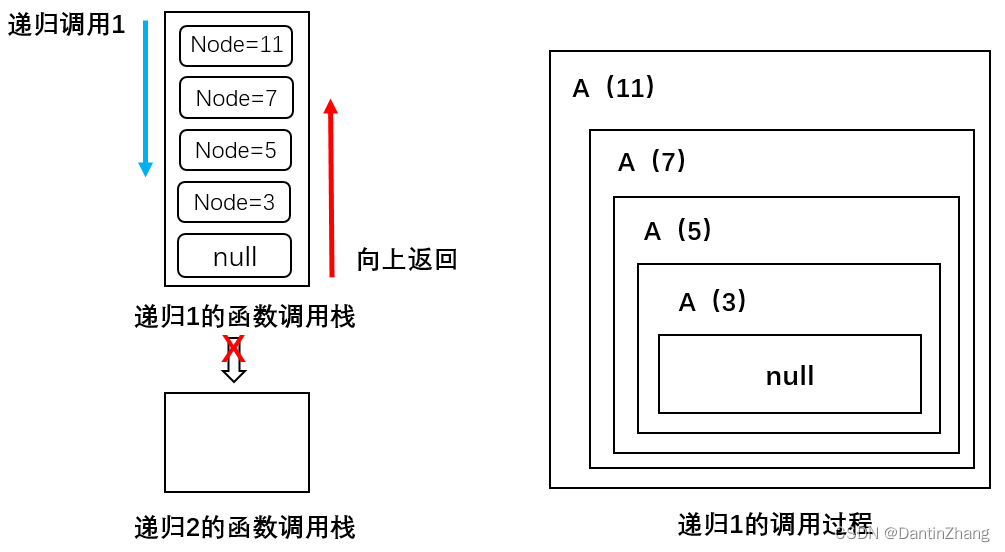
下面这个图画的不错

(2)中序遍历
左子树 => 根节点 => 右子树

//3.1中序遍历的递归函数
inOrderRecursion(node) {
if(node == null) return false;
this.preOrderRecursion(node.left);
console.log(node.key);
//递归完成后调用的是上一个栈顶函数的下一个过程,所以来到了node.right
this.preOrderRecursion(node.right);
}
//3.2中序遍历
inOrderTraversal() {
this.preOrderRecursion(this.root);
}
(3)后序遍历
左子树 => 右子树 => 根节点

//3.1后序遍历的递归函数
afterOrderRecursion(node) {
if(node == null) return false;
this.preOrderRecursion(node.left);
//递归完成后调用的是上一个栈顶函数的下一个过程,所以来到了node.right
this.preOrderRecursion(node.right);
console.log(node.key);
}
//3.2后序遍历
afterOrderRecursion(node) {
this.afterOrderRecursion(this.root);
}
(4)测试代码
测试代码:
//测试代码
let bst = new BinarySearchTree();
bst.insert(11);
bst.insert(7);
bst.insert(15);
bst.insert(5);
bst.insert(9);
console.log(bst);
bst.preOrderTraversal();
console.log('-----------------------------')
bst.inOrderTraversal();
console.log('-----------------------------')
bst.afterOrderTraversal();
结果:
前序遍历:11-7-5-9-15
中序遍历:5-7-9-11-15
后序遍历:5-9-7-15-11
5.最大值和最小值
寻找最大值最小值很简单,最小值在最左边,最大值在最右边,直接循环依次查找就行。
//4.寻找最小值
min() {
let current = this.root;
while(current != null && current.left != null) {
current = current.left;
}
if(current != null) return current.key;
}
//5.寻找最大值
max() {
let current = this.root;
while(current != null && current.right != null) {
current = current.right;
}
if(current != null) return current.key;
}
6.search查找特定的值
可以用递归实现,也可以用循环实现,循环好理解一些。
1、递归:
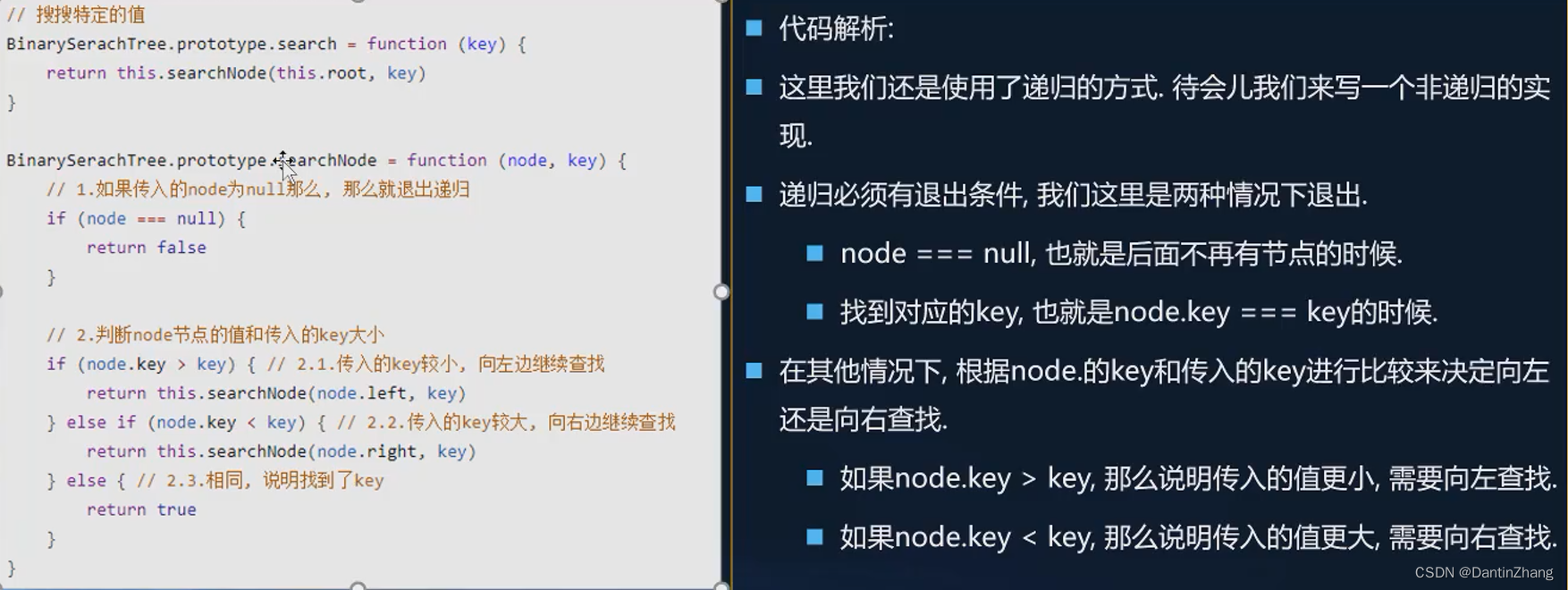
2、循环:
//6.寻找特定值(有返回true,没有返回false)
search(key) {
let current = this.root;
//二分查找原则
while(current != null) {
if(key < current.key) {
//向左查找
current = current.left;
}else if(key > current.key) {
//向右查找
current = current.right;
}else {
return true;
}
}
return false;
}
7.删除某个节点(难上加难)
首先要先找到这个节点,如果没有直接返回false,有的话再说。
(1)找到节点
remove(key) {
//一.寻找要删除的节点
//1.1定义变量保存父节点和左右子树的标识
let current = this.root;
let parent = null; //定义节点的父节点
let isLeftChild = true; //左右子树的标识
if(current == null) return false;//根节点为空直接return
//1.2寻找删除的节点
while(current.key != key) {
parent = current;
if(key < current.key) {
current = current.left;
isLeftChild = true;
} else {
current = current.right;
isLeftChild = false;
}
}
//1.3如果找到最后还是没有,那么就无法删除
if(current == null) return false;
}
(2)情况一:删除的节点没有子节点
如果是这种情况,那么要考虑
1、删除的是根节点
2、删除的不是根节点
主要思路:是根节点就置空,不是根节点就根据左右子树的情况把父节点指针置空(这样的话没有被引用的节点会自动被垃圾回收机制回收掉,相当于删除了)
remove(key) {
//一.寻找要删除的节点
......
//二.已经找到,根据不同的情况进行删除
//(1)情况一:删除的节点没有子节点
if(current.left == null && current.right == null) {
//1.如果是根节点
if(current == this.root) {
this.root = null;
}
//2.如果不是根节点
else if(isLeftChild) {
//2.1如果是左子树
parent.left = null;
} else {
//2.2如果是右子树
parent.right = null;
}
}
}
(3)情况二:删除的节点只有一个子节点
这种情况也比较好处理,首先判断删除节点的子节点是左边还是右边,然后分别改变父节点left,right的指向,让它俩指向删除节点的子节点就可以了。
remove(key) {
查找......
if(current.left == null && current.right == null) {
.......
}
//(2)情况二:删除的节点只有一个子节点
//1.如果删除的节点只有左子节点
else if(current.right == null) {
if(isLeftChild) {
//如果删除的节点是父节点的左子节点
parent.left = current.left;
} else {
//如果删除的节点是父节点的右子节点
parent.right = current.left;
}
}
//2.如果删除的节点只有右子节点
else if(current.left == null) {
if(isLeftChild) {
//如果删除的节点是父节点的左子节点
parent.left = current.right;
} else {
//如果删除的节点是父节点的右子节点
parent.right = current.right;
}
}
}
但是上面这样少了一种情况,那就是如果删除的节点是根节点呢?这种情况需要加上,如果删除的是根节点,那么需要让root指向根节点的左或右节点
remove(key) {
查找......
if(current.left == null && current.right == null) {
.......
}
//(2)情况二:删除的节点只有一个子节点
//1.如果删除的节点只有左子节点
else if(current.right == null) {
//别忘了,如果只有一个根节点带一个子节点呢?
if(current == this.root) {
this.root = current.left;
}
else if(isLeftChild) {
//如果删除的节点是父节点的左子节点
parent.left = current.left;
} else {
//如果删除的节点是父节点的右子节点
parent.right = current.left;
}
}
//2.如果删除的节点只有右子节点
else if(current.left == null) {
if(current == this.root) {
this.root = current.right;
}
else if(isLeftChild) {
//如果删除的节点是父节点的左子节点
parent.left = current.right;
} else {
//如果删除的节点是父节点的右子节点
parent.right = current.right;
}
}
}
(4)情况三:删除的节点有两个子节点
这种情况是非常非常非常复杂的。
非常详细的笔记请见大佬的博客:二叉搜索树删除有两个子节点的节点
这里的删除有一定的规律,我就不写探索过程了,直接说规律。
如果要删除的节点有两个子节点,甚至子节点还有子节点,这种情况下需要从要删除节点下面的子节点中找到一个合适的节点,来替换当前的节点。 这个节点最好是:
1、左子树中的最大值
2、右子树中的最小值
在二叉搜索树中,这两个特殊的节点有特殊的名字:
-
比 current 小一点点的节点,称为 current 节点的前驱。(比如下图中的节点 13 就是节点14 的前驱;)
-
比 current 大一点点的节点,称为 current 节点的后继。(比如下图中的节点18 就是节点 14 的后继;)
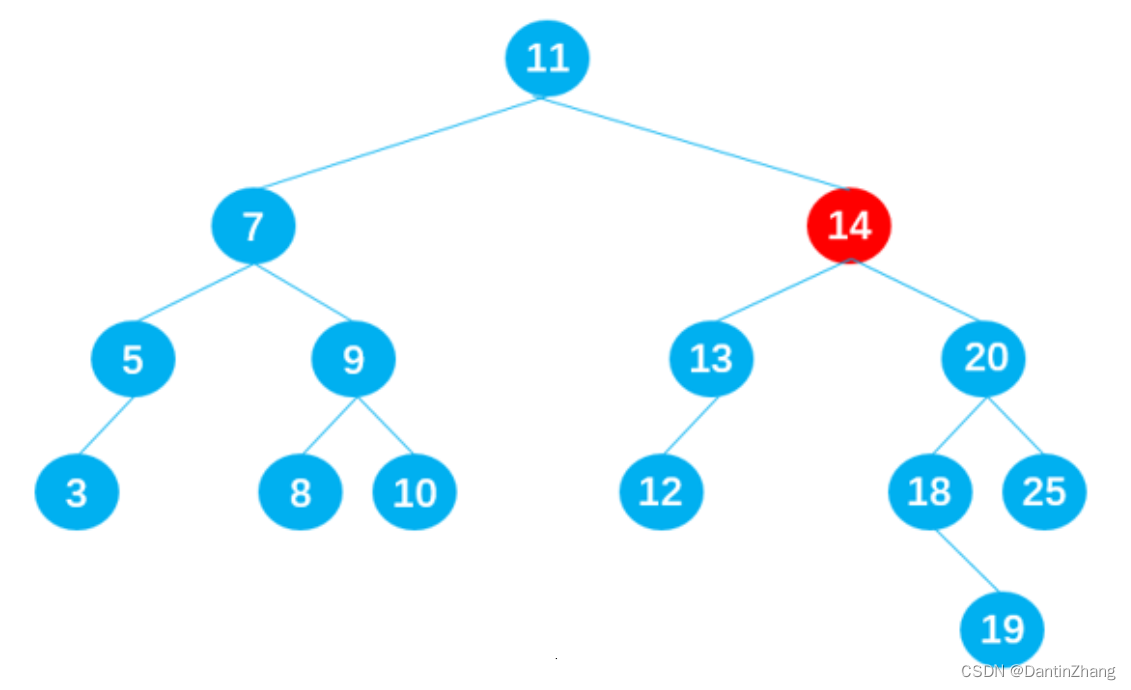
-
查找需要被删除的节点 current 的后继时,需要在
current 的右子树中查找最小值,即在 current 的右子树中一直向左遍历查找; -
查找前驱时,则需要在
current 的左子树中查找最大值,即在 current 的左子树中一直向右遍历查找。
下面只讨论查找 current 后继的情况,查找前驱的原理相同,这里暂不讨论。
remove(key) {
查找......
if(current.left == null && current.right == null) {
.......
}
//(2)情况二:删除的节点只有一个子节点
//1.如果删除的节点只有左子节点
......
//2.如果删除的节点只有右子节点
......
//(3)情况三:删除的节点有两个子节点(复杂)
else {
//1.找到后继节点
let successor = this.getSuccessor(current);
//2.处理删除节点的上面(父)节点的指针指向
if(current == this.root) {
this.root = successor;
}else if(isLeftChild) {
parent.left = successor;
}else {
parent.right = successor;
}
//3.将后继的左子节点改为删除的左子节点
successor.left = current.left;
}
}
寻找后继节点的函数:
//7.1找到情况三的后继节点(右子树最小值)
getSuccessor(delNode) {
//这个函数主要处理的是删除节点下面的节点
let successor = delNode;
let current = delNode.right;//从右子节点开始查找
let successorParent = delNode;
while(current != null) {
successorParent = successor; //保存后继节点的父节点(原地不动)
successor = current; //保存后继节点(向下挪一步)
current = current.left; //保存遍历的指针(向左挪一步)
}
//循环结束,说明找到了右子树的最小值所在节点
//此时还要进行判断:
//1.如果后继节点是第一个右子节点,那么指针的更改去另一个函数中完成
//2.如果不是,那么就要改前后节点的指向,这块儿真tm绕
if(successor != delNode.right) {
successorParent.left = successor.right; //后继节点只可能有右子节点
successor.right = delNode.right;
}
return successor;
}
这里实在是太难了,看着代码画画图就能理解了。。。