文章目录
- 一、解释
- 二、归一化(Normalization)
- 三、为什么只对训练集做fit_transform,对测试集只做transform?
一、解释
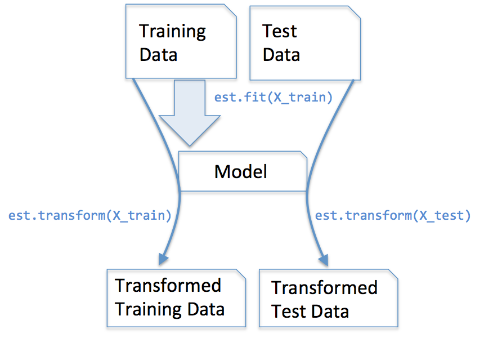
fit(): Method calculates the parameters μ and σ and saves them as internal objects.
解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
transform(): Method using these calculated parameters apply the transformation to a particular dataset.
解释:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。作用是通过找中心和缩放等实现标准化
fit_transform(): joins the fit() and transform() method for transformation of dataset.
解释:fit_transform是fit和transform的组合,既包括了训练又包含了转换。对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值、最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化等)
二、归一化(Normalization)
归一化的目的:
对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内,使其具有可比性。
归一化之后等高线变得不再崎岖, x 1 x_1 x1和 x 2 x_2 x2的更新速度变得更为一致,容易更快地通过梯度下降找到最优解。迭代次数变少,减小梯度下降算法的过程,从而加速模型的生成。
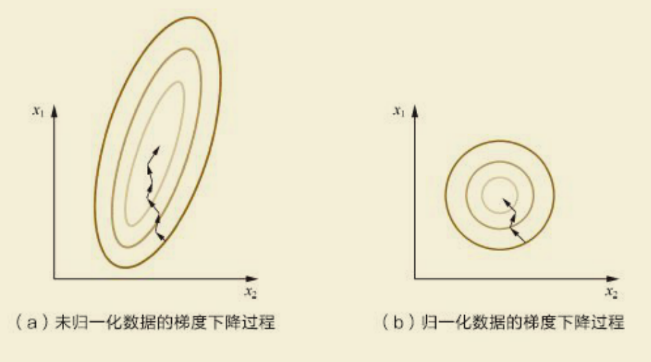
从上图中不难看出,归一化后的数据迭代次数更少!
三、为什么只对训练集做fit_transform,对测试集只做transform?
机器学习假设:
训练集和测试集的每个样本都是从同一分布中抽样得到的,所以在训练集中fit之后在测试集就不能再fit了,要不然二者可能不是同一分布模型,预测效果会很糟糕。