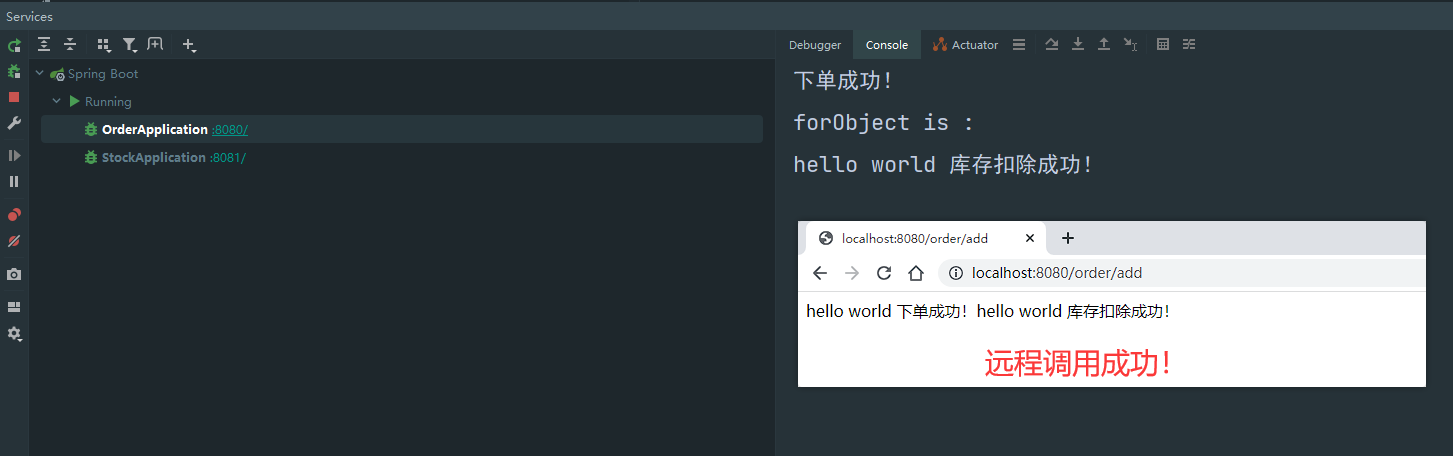
传统的运维方式在监控、问题发现、告警以及故障处理等各个环节均存在明显不足,需要大量依赖人的经验,在数据采集、异常诊断分析、故障处理的效率等方面有待提高。
本关键技术面对传统运维故障处理效率低、问题定位不准确、人力成本高三大痛点,将人工智能与运维相结合,由AI逐步取代人力决策,通过机器学习方法,快速给出决策建议或提前规避故障,实现网云业务智能分析和优化,从而极大提高运维生产力。总体来说智能运维比传统运维方式效率高,数据采集更准确,更智能。
基于机器学习的异常检测和智能分析技术基于资源、告警、性能、拨测、日志等多模态数据,通过人工智能技术,对业务异常事件进行溯源、降噪,第一时间对运维人员展示出异常的根本原因及定位分析,提升运维人员故障处理效率,降低运维成本。
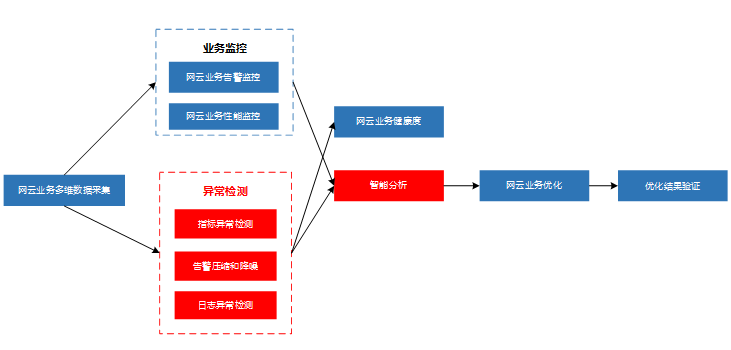
异常检测和智能分析流程图
异常检测的输入由数据中台提供业务资源、告警、性能、拨测、日志等多维数据。
异常检测的输出包括异常指标、重要告警、异常日志等信息,为网云业务健康度、智能分析提供参考依据。
本关键技术包含指标异常检测、告警压缩与降噪、日志异常检测、智能分析等技术。指标异常检测技术,接入运维监控指标通过异常检测算法得出指标的异常点;告警压缩和降噪技术,对海量的告警事件进行关联关系挖掘,在保证核心告警内容的前提下抑制告警消息数量,为运维人员提供有效的告警信息;日志异常检测技术从海量日志中实时分析日志模式的变化趋势,及时发现业务异常。智能分析技术,基于上述检测出的异常指标、重要告警、异常日志,结合故障传播关系、决策树 、知识图谱等技术,对网云业务故障和隐患进行智能分析,输出根本原因及定位、建议处理措施,提升运维人员故障处理效率,降低运维成本。
指标异常检测技术
指标异常检测根据不同场景和应用需求,可以分为单指标异常检测和多指标异常检测。
(1)单指标异常检测
-
检测原理:关注的是某个KPI的值是否异常。例如:KPI突变、抖动等。
-
异常场景:单指标异常主要是KPI值突然发生了较大变化。例如:CPU使用率突然增加、内存突然降低等。
-
检测方法:单指标异常检测主要有基于统计学和预测的两种方法。
-
基于统计学的方法通常是设定阈值判断是否异常。例如:3sigma等。若KPI超过阈值,则判断为异常,反之则正常。
-
基于预测的方法是通过建模并预测KPI曲线,根据预测值与实际值之间的误差大小判断是否异常。例如:ARIMA等。若误差较大,则判断为异常,反之则正常。
(2)多指标异常检测
-
检测原理:关联的多个实体的状态是否异常。如:服务器、设备等。
-
异常场景:多指标异常检测场景主要有两种情况。
-
第一种情况是尽管每个KPI看起来可能并没有异常,但综合多个KPI来看,可能就是异常的。
-
第二种情况是有些单个KPI表现异常,但整体来看可能又是正常的。
-
检测方法:与单指标序列相比,多指标序列具有维度高、数据量大、指标间关系复杂等特性。主要有两种思路:
-
第一种思路是将多指标序列划分成多个单指标序列,利用单指标异常检测方法发现异常;
-
第二种思路是直接分析多指标序列,如将多指标序列按形状或时间分成多个子序列,同时结合聚类等算法发现异常。
针对多指标异常检测,第一种思路相对成熟,但这种思路会丢失指标间的关联性信息,同时对每个KPI进行建模会带来更高的成本。
该分析方案包括离线过程和在线过程,主要是通过判断多指标间的变量关系是否被打破来进行异常检测。
若多指标间的变量关系被打破,则判断为异常,反之则正常。发现异常后,会对异常的KPI进行故障定位。
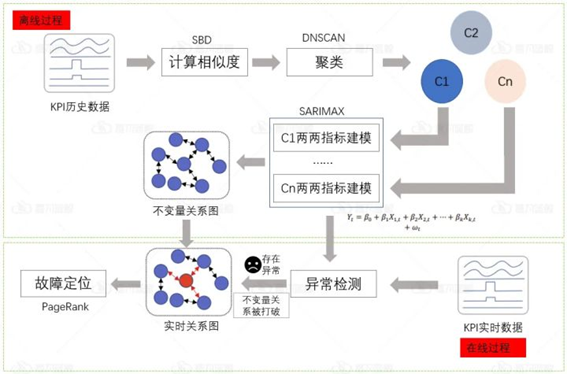
分析方案流程图
方案具体流程如下:
a) 离线过程
基于SBD的DBSCAN聚类:使用基于SBD的DBSCAN聚类算法将相似指标聚类,可以降低分析框架的复杂度,并且将相似形状的指标聚类到同一类中。
SARIMAX建模:随后,在聚类后的每个簇中,对两两指标建立SARIMAX模型,构建指标间的不变量关系。不变量关系指时间序列间存在着不会随时间变化的关系,如指标1为sin(t)和指标2为sin(3t)的关系。
b) 在线过程
异常检测:通过计算两两指标间的残差得分,再根据指定阈值判断不变量关系是否被打破。若残差得分超过阈值,则认为不变量关系被打破,即该指标对存在异常,反之则不存在异常。
可视化不变量关系图:对离线学习和在线学习的不变量关系图进行绘制,可视化异常检测结果。
故障定位:对所有被打破的不变量关系采用改进的PageRank算法进行故障定位。
告警事件压缩与降噪技术
运维一般是通过配置固定阈值,达到阈值后自动触发/生成告警。如网络中断、闪断;系统升级更新;设备多监控内容多等情况下,更会产生海量告警。故障期间,告警风暴,手机/邮箱会被海量告警淹没;运维人员很难从海量告警从筛选出重要告警,容易忽略重要告警;固定阈值控制,频繁误报、漏报告警。
告警压缩和降噪技术,旨在对海量的告警事件进行关联关系挖掘,在保证核心告警内容的前提下抑制告警消息数量,为运维人员提供有效的告警信息。
实现本算法的基础机器学习基础算法常用为有监督训练算法:Apriori。
核心算法思想:通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;利用频繁项集构造出满足用户最小信任度的规则。
Apriori 算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。算法的名字基于这样的事实:算法使用频繁项集性质的先验知识, 正如我们将看到的。Apriori 使用一种称作逐层搜索的迭代方法,k-项集用于探索(k+1)-项集。首先,找出频繁1-项集的集合。该集合记作L1。L1 用于找频繁2-项集的集合L2,而L2 用于找L3,如此下去,直到不能找到频繁k-项集。找每个Lk 需要一次数据库扫描。
频繁项集的所有非空子集都必须也是频繁的。Apriori 性质基于如下观察:根据定义,如果项集I不满足最小支持度阈值s,则I不是频繁的,即P(I)< s。如果项A添加到I,则结果项集(即I∪A)不可能比I更频繁出现。因此, I∪A也不是频繁的,即 P(I∪A)< s 。
该性质属于一种特殊的分类,称作反单调,意指如果一个集合不能通过测试,则它的所有超集也都不能通过相同的测试。称它为反单调的,因为在通不过测试的意义下,该性质是单调的。

频繁项集挖掘
关联规则的一般步骤:
① 找到频繁集,使用候选项集找频繁项集,如果某个项集是频繁的,那么它的所有子集也是频繁的。该定理的逆反定理为:如果某一个项集是非频繁的,那么它的所有超集(包含该集合的集合)也是非频繁的。Apriori原理的出现,可以在得知某些项集是非频繁之后,不需要计算该集合的超集,有效地避免项集数目的指数增长,从而在合理时间内计算出频繁项集。
② 在频繁集中通过可信度筛选获得关联规则。
支持度(Support):支持度揭示了A与B同时出现的概率。如果A与B同时出现的概率小,说明A与B的关系不大;如果A与B同时出现的非常频繁,则说明A与B总是相关的。支持度: P(A∪B),即A和B这两个项集在事务集D中同时出现的概率。
可信度(Confidence):置信度揭示了A出现时,B是否也会出现或有多大概率出现。如果置信度度为100%,则A和B可以捆绑销售了。如果置信度太低,则说明A的出现与B是否出现关系不大。置信度: P(B|A),即在出现项集A的事务集D中,项集B也同时出现的概率。
③ Ariori算法有两个主要步骤:
连接:将项集进行两两连接形成新的候选集,利用已经找到的k个项的频繁项集Lk,通过两两连接得出候选集Ck+1,注意进行连接的两个频繁项集Lk1,Lk2,必须有k-1个属性值相同,然后另外两个不同的分别分布在Lk1,Lk2中,这样的求出的候选集。
剪枝:去掉非频繁项集,候选集中的并不都是频繁项集,必须剪枝去掉,越早越好以防止所处理的数据无效项越来越多。只有当子集都是频繁集的候选集才是频繁集,这是剪枝的依据。
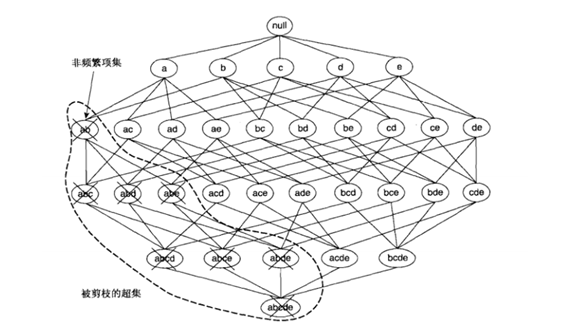
剪枝
日志异常检测技术
本项目日志异常检测技术采用SwissLog方法,使用 LSTM 的深度神经网络模型,将系统日志作为自然语言序列。SwissLog从正常执行中自动学习日志模式,当日志模式偏离训练模型时检测异常。SwissLog从基础系统日志中构建工作流,一旦检测到异常,用户可以诊断异常并有效的执行根因分析。
SwissLog包括两个阶段,即离线处理阶段和在线处理阶段。每个阶段包括日志解析、句子嵌入、基于注意力机制的Bi-LSTM阶段,在线阶段特别包含异常检测阶段。
日志解析部分对历史日志数据进行分词、字典化和聚类,提取多个模板,这些日志语句与相同的标识符联系起来构建日志序列,然后将日志序列转化为语义信息和时间信息。
句子嵌入部分使用BERT模型或Word2Vec模型对句子进行编码,转化为词向量,将这些语义信息和时间信息输入到基于注意力机制的 Bi-LSTM模型中学习正常、异常和性能异常日志序列的特征,在在线检测阶段,一旦检测到异常,就会发出警报,主要流程如下:
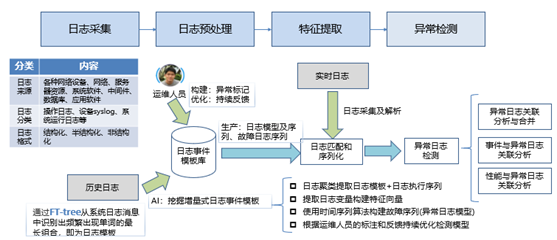
异常日志挖掘与分析流程
(1)日志解析
日志解析的主要目的是日志模板化。
-
中心思想: 尽可能将包含语义信息的部分视作日志语句中的常量;
-
解决方法: 基于字典的日志模板化方法。
-
主要流程如下: a) 日志预处理和字典化
b) 利用有效词集日志聚类
c) 寻找最大公共序列
d) 利用前缀树进行聚类
e) 得到日志解析模板
(2)日志语句编码阶段
异常检测的最终目标是检测我们前面描述的各种故障。我们可以观察到,仅凭语义信息不足以检测多种类型的故障。因此,还引入了时间信息作为特征来补充异常检测方法。日志解析后,我们通过将日志与相同的标识符(如HDFS日志中的block id)或滑动窗口相关联来构建会话。我们将序列转换为语义信息和时间信息。然后我们用下面的方法对这两种信息进行编码。
-
中心思想: 日志序列是一组有时序特征的自然语言;
-
解决方法: 同时考虑日志语句的时序特征和语义特征。
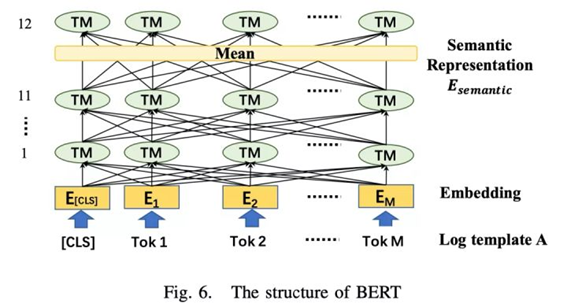
利用BERT学习一条日志语句的语义信息

利用日志序列的打印时间间隔作为时序特征
(3)日志模式学习阶段
在句子嵌入之后,每条日志消息被转换成一个语义向量和一个时间嵌入向量。将二者串联,每个日志序列都表示为一个向量列表,SwissLog以此类向量为输入,采用基于注意力机制的双向LSTM神经网络模型来检测各种异常,如图所示:
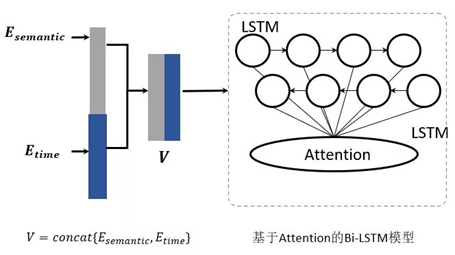
采用双向LSTM神经网络模型检测异常
-
中心思想: 模糊日志序列中不重要的日志语句;
-
解决方法: 基于注意力机制的双向LSTM模型,学习日志序列的模式。
(4)异常检测
在离线阶段,我们使用历史日志训练获得了一个双向LSTM的预训练模型,可以用此模型进行异常检测。当一组新的日志语句到达时,它首先经过日志解析和句子嵌入阶段。然后将上面阶段获得的输出向量作为输入,输入到预训练模型中。最后,通过双向LSTM模型可以检测是否发生异常。SwissLog根据由共同标识符(例如block ID)关联的日志语句做出预测。
智能分析技术
异常检测旨在表明某些不正常现象,而智能分析则试图阐明“是什么问题”、“为什么发生问题“、“问题的最佳解决方案是什么”。
智能分析除了需要用到上面异常检测阶段输出的基于上述检测出的异常指标、重要告警、异常日志等数据,还需要基础的网云融合资源及物理和逻辑拓扑关系。
本技术的思路是构建一个故障树的超集,通过业务调用链获得资源之间的逻辑调用关系,通过网云融合资源及物理拓扑关系,比如共享机器资源、网络资源等。这两部分一起构成一个可能的故障树,这棵树是真正故障树的一个超集。之后我们对这个超集中的每个边进行联动分析、联动分析,对这棵树进行剪枝,构成最终的故障传播关系。这种方法的覆盖面广,计算开销大大降低,并且是AI擅长解决的问题。当我们拥有了故障传播关系,并它比较全而且准的话,根因分析就变得可行了。当发生故障时,依据准确的报警,着故障传播树就能找到根因,从而进行故障修复。
当上述异常指标、重要告警、异常日志之间存在逻辑关系时,可以根据故障树给出根源;当数据存在结构性的时候,可以根据图算法模型对根因进行分析,然后进一步将不同的算法模型对场景和不同的元数据进行适配,对异常进行有效的根因定位。在众多可能引起故障的因素中,追溯到导致故障发生的症结所在,并找出根本性的解决方案。利用机器学习或者深度学习的方法,找出不同因素的之间的强相关关系,并利用这些关系推断出哪些因素是根本原因。
当故障和问题发生时,智能分析功能基于智能算法给出当前问题事件的故障根因推荐,并将问题事件的相关故障信息汇集到一个页面,根因分析结果可以帮助运维工程师快速确定故障的根因,并迅速对故障进行修复,降低损失。