原文链接:https://www.techbeat.net/article-info?id=4614&isPreview=1
作者:林闯
目标检测任务在AI工业界具有非常广泛的应用,但由于数据获取和标注的昂贵,检测的目标一直被限制在预先设定好的有限类别上。而在学术界,研究者们开始探索如何识别更广泛的目标类别,扩大目标检测在实际场景中的应用范围。本文介绍一篇刚刚被ICLR 2023录用的文章,该文使用少量的目标检测标注数据和大量的图像-文本对作为训练数据,基于二分匹配的思想从图像-文本对中提取区域-词语对,扩展了目标检测的物体类别,实现开放世界中的目标检测。

论文链接:
https://arxiv.org/abs/2211.14843
代码链接:
https://github.com/clin1223/VLDet
一、 背景
什么是开放词汇式目标检测(open-vocabulary object detection)?
现今,目标检测任务在一些学术数据集上已经取得了很好的效果。这些数据集通常预先设定好一定的目标类别,如果需要扩大检测的目标种类,那么需要为新的类别标注数据,再重新训练模型来达到目的。然而这样的做法并不是人工智能的最终答案,因为人类可以在开放的环境中感知世界,而不局限于固定的类别。这开始让我们思考视觉模型可以不可以在开放的词汇下进行目标检测,也就是说我们希望视觉模型以零样本的方式识别任意之前未知的类别。很自然地,我们想到利用自然语言的监督,因为我们可以获得大量几乎免费的、具有丰富语义的多模态数据。
在这样的背景下,本文尝试用少量具有标注的目标检测数据和大量无标注的的图像-文本对作为训练数据,得到可扩展的目标检测器,从而达到对训练中未知的类别进行检测,提高检测器的可扩展性和效率。
此时面临的挑战是:训练一个传统的检测器需要人工标注的边界框和物体类别,同样的,如果想利用自然语言监督图像中的目标那么就需要区域-词语的对应关系。那么该如何从图像-文本对中学习细粒度的区域-词语对应关系?
二、核心想法
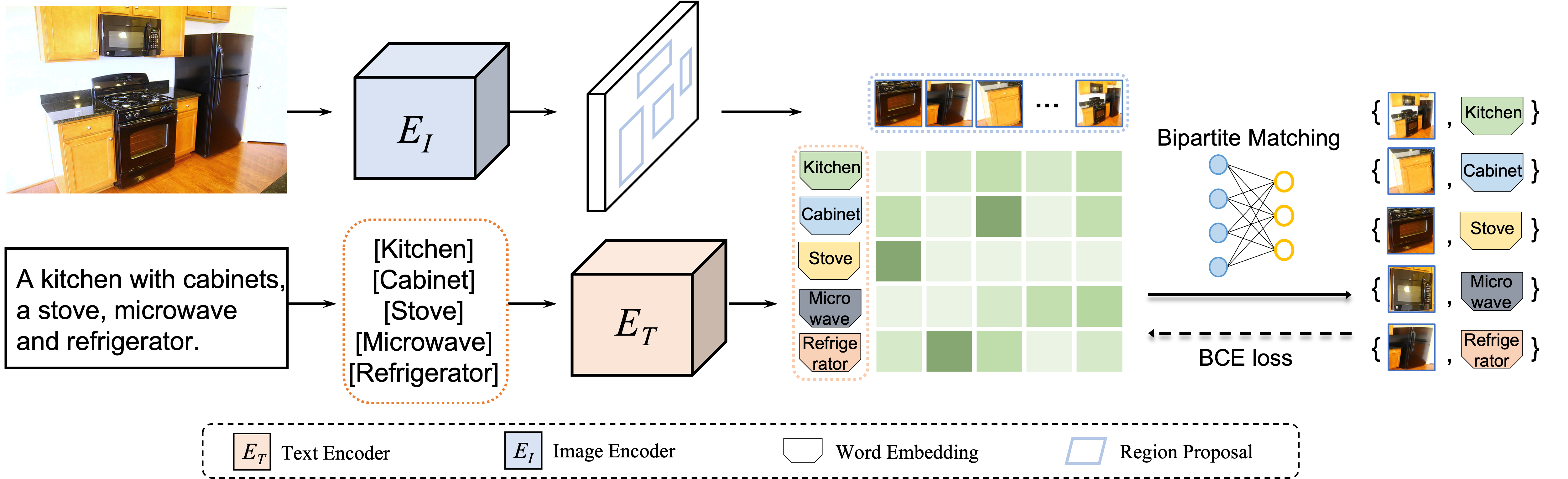
本文的主要思想是,从图像-文本对中提取区域-词语对可以表示为一个集合匹配问题,可以通过找到区域和词语之间具有最小全局匹配成本的二分匹配来有效地解决这个问题。
具体来说,我们将图像中的区域特征视为一个集合,将文本中的词语编码视为另一个集合,并将点积相似度作为区域-词语对齐分数。为了找到最低成本,最优二分匹配将强制每个图像区域在图像-文本对的全局监督下与其对应的词语对齐。通过用最佳区域-词语对齐损失代替目标检测中的分类损失,我们的方法可以帮助将每个图像区域与相应的词语匹配并完成目标检测任务。

针对以上宗旨,本文提出三大贡献。
- 本文提出了一种开放词汇式目标检测方法VLDet,可以直接从图像-文本对数据中学习区域-词语对齐。
- 本文将区域-词语对齐表述为一个集合匹配问题,并使用匈牙利算法有效地解决它。
- 在两个基准数据集 OV-COCO 和 OV-LVIS 上进行的广泛实验证明了VLDet的卓越性能,尤其是在检测未知类别方面。
三、方法
Recap on Bipartite Matching
在介绍我们的方法前先来回顾一下二分图匹配,假设有 X X X 个工人和 Y Y Y 个工作。 每个工人都有他/她有能力完成的某些工作。 每个工作只能接受一个工人,每个工人只能被任命为一个工作。 因为每个工人都有不同的技能,将工人 x x x 分配执行工作 y y y 所需的成本是 d x , y d_{x,y} dx,y ,目标是确定最佳分配方案,使总成本最小化或团队效率最大化。约束条件是如果有更多的工人,确保每个工作分配给一个工人; 否则,确保每个工人都被分配到一份工作。
Learning Object-Language Alignments from Image-Text Pairs
本文将每个图像区域定义为试图找到最合适的“工人”的“工作”,并将每个文本词语定义为找到最有信心“工作”的“工人”。 在这种情况下,本文的方法从全局角度将区域和词语对齐任务转换为集合到集合的二分匹配问题。图像区域 R = [ r 1 , r 2 , . . . , r m ] R=[r_1,r_2,...,r_m] R=[r1,r2,...,rm] 和文本词语 W = [ w 1 , w 2 , . . . , w n ] W=[w_1,w_2,...,w_n] W=[w1,w2,...,wn] 之间的成本定义为对齐分数 S = W R T S = WR^T S=WRT , 然后可以通过匈牙利算法有效地解决二分匹配问题。 匹配后,将得到的区域-词语对作为优化目标,对检测模型的分类分枝通过以交叉熵损失进行优化。
目标词汇表: 本文将目标词汇设置为每个训练批次中图像标题中的所有名词。 从整个训练过程来看,本文的词汇表远大于数据集的标签空间。本文的实验表明,这种设置不仅实现了理想的开放词汇式检测,而且还达到了更好的性能。
Network Architecture
VLDet网络包括三个部分:视觉目标检测器,文本编码器和区域-词语之间的对齐。本文选择了Faster R-CNN作为目标检测模型。 目标检测的第一阶段与Faster R-CNN相同,通过RPN预测前景目标。为了适应开放词汇的设置,VLDet在两个方面修改了检测器的第二阶段:(1)使用所有类共享的定位分支,定位分支预测边界框而不考虑它们的类别。 (2) 使用文本特征替换可训练分类器权重,将检测器转换为开放词汇式检测器。 本文使用固定的预训练语言模型CLIP作为文本编码器。
四、实验
VLDet在OV-COCO和OV-LVIS的未知类上的表现都达到了SoTA,同时表明了从全局角度学习区域-词语对齐的有效性。
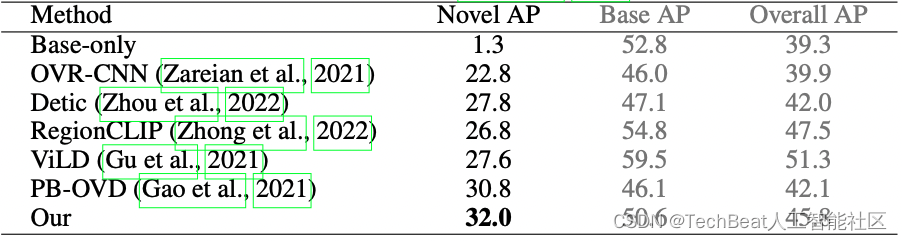
表1. VLDet在OV-COCO基准数据集上的结果。COCO被分为48个已知类和17个未知类,VLDet使用已知类作为检测训练数据和COCO Caption作为图像-文本对训练数据。
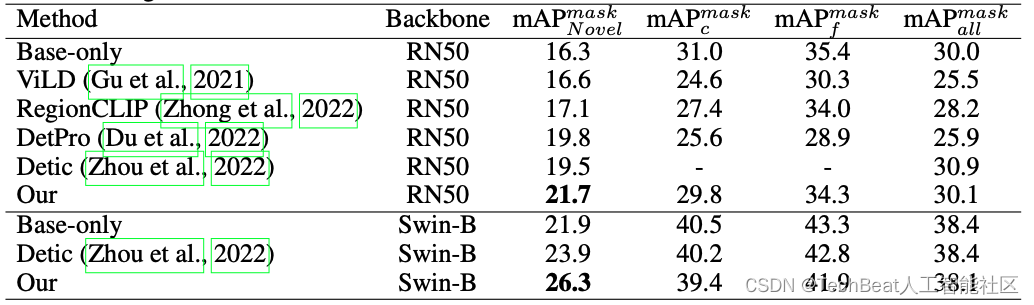
表2. VLDet在OV-LVIS基准数据集上的结果。LVIS被分为866个已知类和337个未知类,VLDet使用已知类作为检测训练数据和CC3M作为图像-文本对训练数据。
One-to-One vs. One-to-Many.
从图像-文本对中提取图像区域-文本词语对的关键是从全局角度优化分配问题。为了进一步研究分配算法的影响,本文考虑了两种全局算法,Hungarian和 Sinkhorn算法,其中前者进行一对一的区域-词语分配,后者提供一个词语-多个区域的分配。 考虑到图像中可能存在同一类别的多个实例,Sinkhorn算法能够为同一个词匹配多个区域,然而同时它也可能引入更多噪声。 从下表中可以观察到一对一分配的表现均优于一对多分配。其中的原因是一对一的分配假设通过为每个单词提供高质量的图像区域来大幅减少错误区域-词语对。

Object Vocabulary Size.
VLDet使用COCO Caption和CC3M中的所有名词并过滤掉低频词,统计共名词词语4764/6250个。我们分析了用不同的词汇量训练我们的模型的效果。我们将目标词汇表替换为 COCO 和 LVIS 数据集中的类别名称,即仅使用文本中的类别名称而不是所有名词。从下表中可以看出,更大的词汇量在 OV-COCO和OV-LVIS的未知类别上分别实现了 1.8% 和 1.5% 的增益,这表明使用大词汇量进行训练可以实现更好的泛化。 换句话说,随着词汇量的增加,模型可以学习更多的目标语言对齐方式,这有利于提高推理过程中的未知类性能。

更多的实现细节和消融实验请查看原文。
五、总结
本文的主要目标是探索开放词汇式的目标检测,希望检测模型以零样本的方式识别任意之前未知的类别。 本文将区域-词语对齐表述为一个集合匹配问题, 并提出了VLDet,模型可以直接从图像-文本对数据中学习区域-词语对齐。 希望本文能够推动 OVOD 的发展方向,并激发更多关于大规模免费图像-文本对数据的工作,从而实现更像人类、开放词汇式的计算机视觉技术。
Illustration by Twin Rizki from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com