Word Embedding
单词表示最简单的是 one-hot

但是它的缺点是
- 矩阵表示过于稀疏,占用空间
- 对相关的词语无法得知它们的含义是相近的。
Word Embedding 解决了上述两个缺点,一个 Word Embedding 直观的例子如下图所示。

每个维度表示一个特征,当然在实际任务中,每个特征可能并不会像例子中的那么明显,是网络自己学习得来的。
Word Embedding 可视化如下图所示
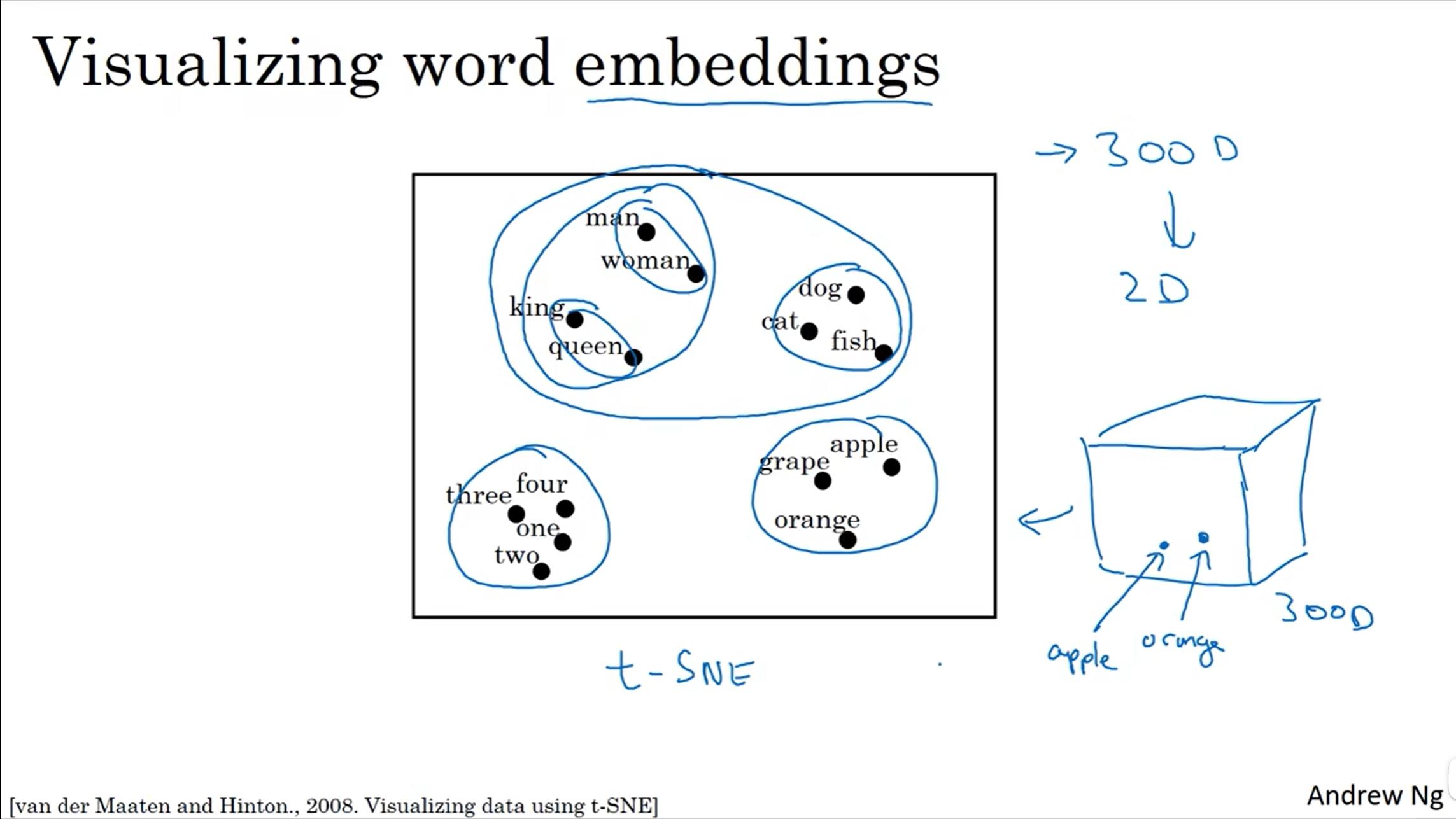
通过 t-SNE 算法将 300 维的词向量映射到二维,方便观察,可以看到含义相近的词语距离更近。从这里也可以看到词嵌入的直观解释,那就是在一个 300 维的空间,每个单词都被嵌入其中,就像上图三维立方体中的每个点,就代表一个单词。这也是嵌入的由来。
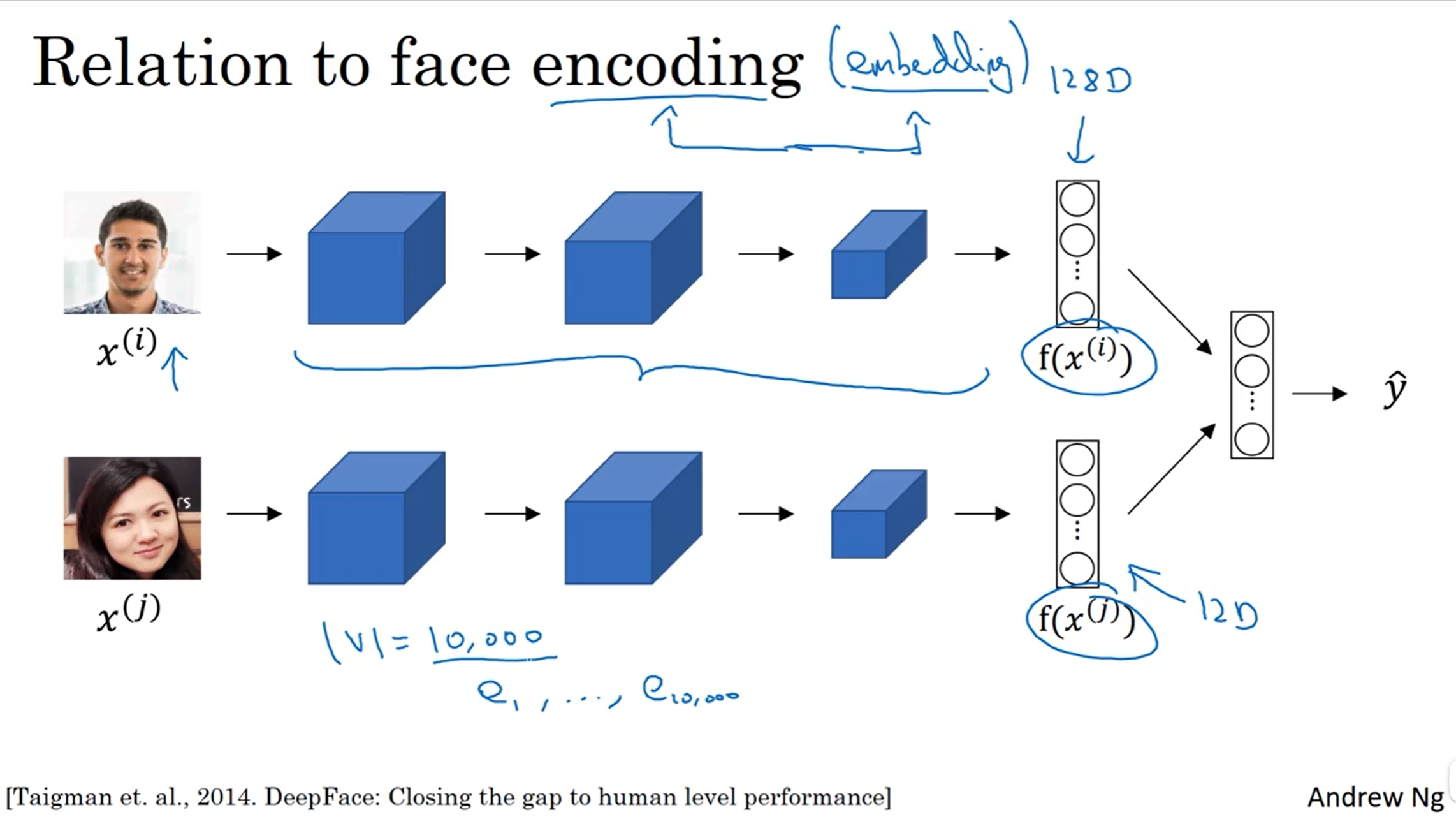
广义 Embedding
在人脸识别领域,一张图片通过卷积网络到一个向量的过程称为编码,这里的 encoding 和 embedding 是一个意思,可以理解为广义的 embedding。
Embedding 在 Pytorch 中实现
import torch
import torch.nn as nn
# an Embedding module containing 10 tensors of size 3
embedding = nn.Embedding(10, 3)
# a batch of 2 samples of 4 indices each
input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
output = embedding(input)
print(output)
tensor([[[ 0.3373, 0.3316, -1.3433],
[ 1.3109, -0.3448, -0.4087],
[ 1.2792, -1.0822, -0.1846],
[-0.8766, 0.5696, -0.1815]],
[[ 1.2792, -1.0822, -0.1846],
[-0.0850, 0.8372, -0.0310],
[ 1.3109, -0.3448, -0.4087],
[ 1.3273, 0.5631, 0.6411]]], grad_fn=<EmbeddingBackward0>)
nn.Embedding 输入参数
- num_embeddings (int) – size of the dictionary of embeddings
- embedding_dim (int) – the size of each embedding vector
相当于把一个标量映射成一个向量。
来看一下 Embedding 层的参数。
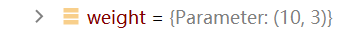
Embedding 的权重是 10*3,和输入参数 size 相同。可以理解为,共有 10 个单词,单词用 0-9 表示,分别乘以 3 个权重,得到词向量。
以 input[0][0] 也就是 1 为例,可以看到对应的权重和输出一致,即1 分别乘以三个权重得到输出。

参考
[双语字幕]吴恩达深度学习deeplearning.ai —— P163 2.1 词汇表征
李宏毅2020机器学习深度学习(完整版)国语 —— P23 Unsupervised Learning - Word Embedding