react diff 算法
我们知道React会维护两个虚拟DOM,那么是如何来比较,如何来判断,做出最优的解呢?这就用到了diff算法
diff算法的作用
计算出Virtual DOM中真正变化的部分,并只针对该部分进行原生DOM操作,而非重新渲染整个页面。
传统diff算法
通过循环递归对节点进行依次对比,算法复杂度达到
O(n^3),n是树的节点数,这个有多可怕呢?——如果要展示1000个节点,得执行上亿次比较。。即便是CPU快能执行30亿条命令,也很难在一秒内计算出差异。
React的diff算法
- 什么是调和?
将Virtual DOM树转换成actual DOM树的最少操作的过程 称为 调和 。
- 什么是React diff算法?
diff算法是调和的具体实现。
diff策略
React用 三大策略 将
O(n^3)杂度 转化为O(n)复杂度
策略一(tree diff):
- Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计
- 同级比较,既然DOM 节点跨层级的移动操作少到可以忽略不计,那么React通过updateDepth 对 Virtual DOM 树进行层级控制,也就是同一层,在对比的过程中,如果发现节点不在了,会完全删除不会对其他地方进行比较,这样只需要对树遍历一次就OK了
策略二(component diff):
- 拥有相同类的两个组件 生成相似的树形结构,
- 拥有不同类的两个组件 生成不同的树形结构。
策略三(element diff):
对于同一层级的一组子节点,通过唯一id区分。
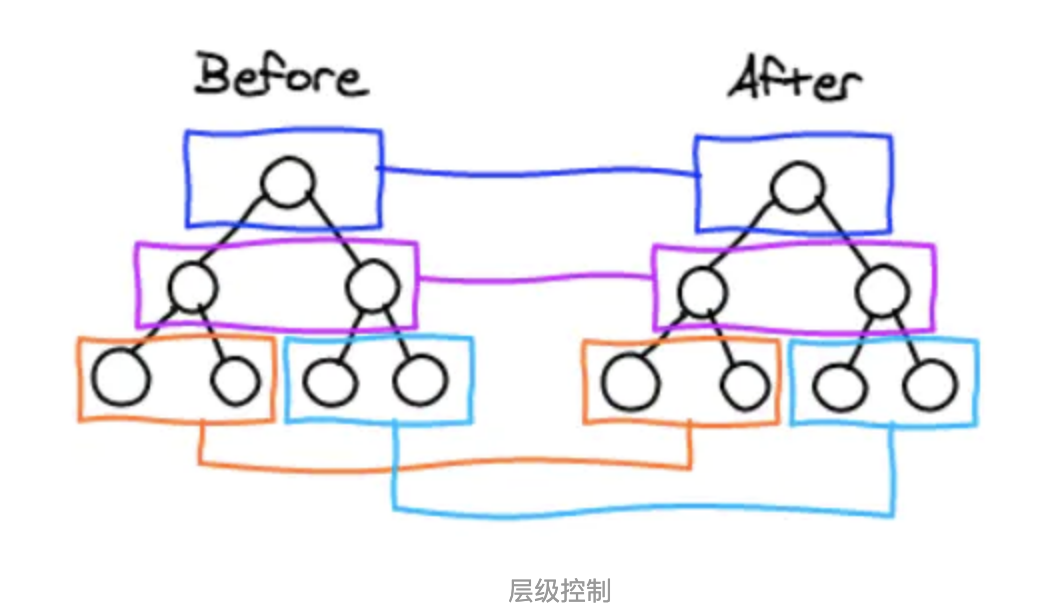
tree diff
- React通过updateDepth对Virtual DOM树进行层级控制。
- 对树分层比较,两棵树 只对同一层次节点 进行比较。如果该节点不存在时,则该节点及其子节点会被完全删除,不会再进一步比较。
- 只需遍历一次,就能完成整棵DOM树的比较。
那么问题来了,如果DOM节点出现了跨层级操作,diff会咋办呢?
答:diff只简单考虑同层级的节点位置变换,如果是跨层级的话,只有创建节点和删除节点的操作。
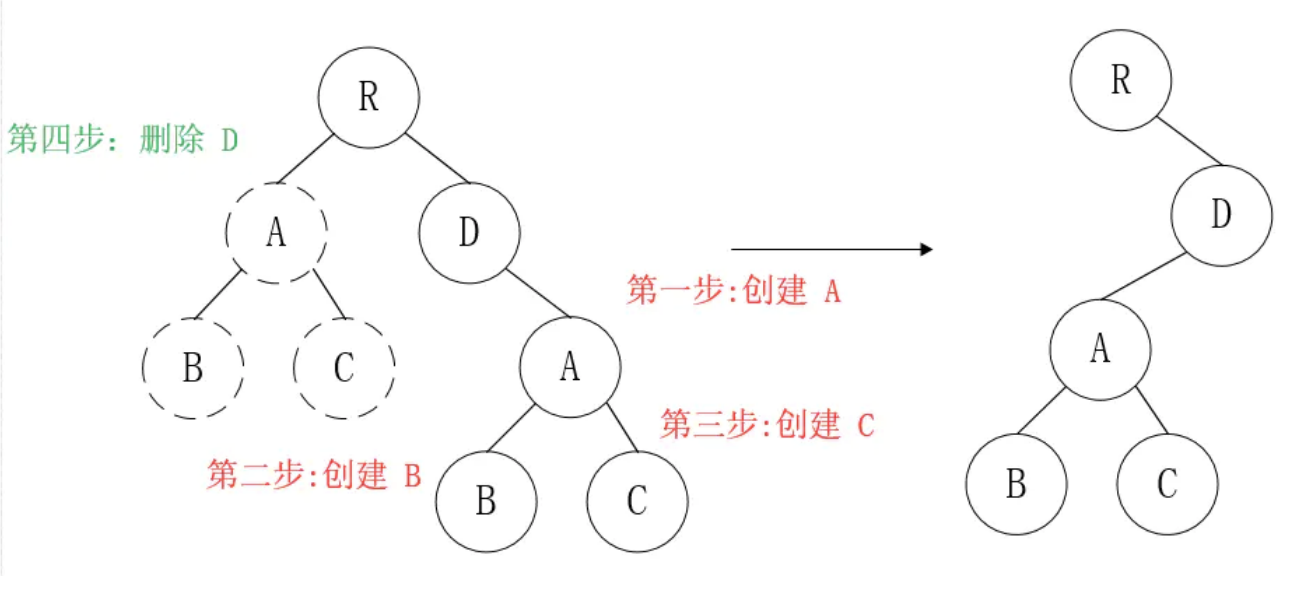
如上图所示,以A为根节点的整棵树会被重新创建,而不是移动,因此 官方建议不要进行DOM节点跨层级操作,可以通过CSS隐藏、显示节点,而不是真正地移除、添加DOM节点
component diff
React对不同的组件间的比较,有三种策略
- 同一类型的两个组件,按原策略(层级比较)继续比较Virtual DOM树即可。
- 同一类型的两个组件,组件A变化为组件B时,可能Virtual DOM没有任何变化,如果知道这点(变换的过程中,Virtual DOM没有改变),可节省大量计算时间,所以 用户 可以通过
shouldComponentUpdate()来判断是否需要 判断计算。 - 不同类型的组件,将一个(将被改变的)组件判断为
dirty component(脏组件),从而替换 整个组件的所有节点。
注意:如果组件D和组件G的结构相似,但是 React判断是 不同类型的组件,则不会比较其结构,而是删除 组件D及其子节点,创建组件G及其子节点。
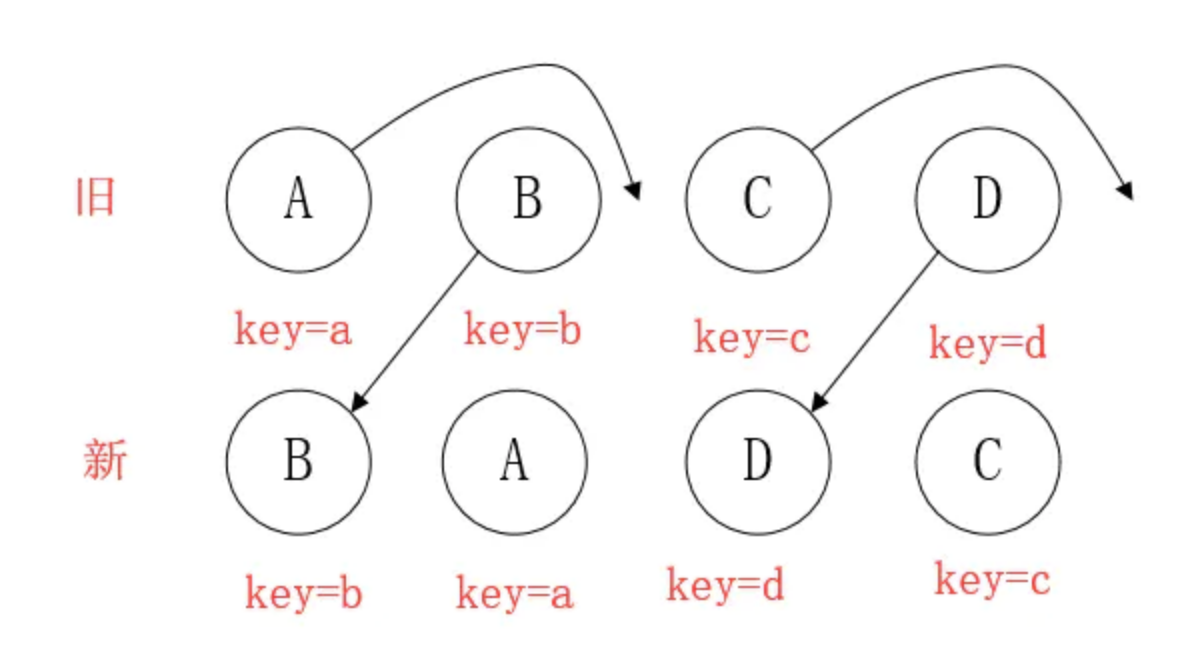
element diff
当节点处于同一层级时,diff提供三种节点操作:删除、插入、移动。
- 插入:组件 C 不在集合(A,B)中,需要插入
- 删除:
- 组件 D 在集合(A,B,D)中,但 D的节点已经更改,不能复用和更新,所以需要删除 旧的 D ,再创建新的。
- 组件 D 之前在 集合(A,B,D)中,但集合变成新的集合(A,B)了,D 就需要被删除。
- 移动:组件D已经在集合(A,B,C,D)里了,且集合更新时,D没有发生更新,只是位置改变,如新集合(A,D,B,C),D在第二个,无须像传统diff,让旧集合的第二个B和新集合的第二个D 比较,并且删除第二个位置的B,再在第二个位置插入D,而是 (对同一层级的同组子节点) 添加唯一key进行区分,移动即可。
diff的不足与待优化的地方
尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,会影响React的渲染性能
react router
import React from 'react'
import { render } from 'react-dom'
import { browserHistory, Router, Route, IndexRoute } from 'react-router'
import App from '../components/App'
import Home from '../components/Home'
import About from '../components/About'
import Features from '../components/Features'
render(
<Router history={browserHistory}> // history 路由
<Route path='/' component={App}>
<IndexRoute component={Home} />
<Route path='about' component={About} />
<Route path='features' component={Features} />
</Route>
</Router>,
document.getElementById('app')
)
render(
<Router history={browserHistory} routes={routes} />,
document.getElementById('app')
)
React Router 提供一个routerWillLeave生命周期钩子,这使得 React组件可以拦截正在发生的跳转,或在离开route前提示用户。routerWillLeave返回值有以下两种:
return false 取消此次跳转
return 返回提示信息,在离开 route 前提示用户进行确认。
什么是状态提升
使用 react 经常会遇到几个组件需要共用状态数据的情况。这种情况下,我们最好将这部分共享的状态提升至他们最近的父组件当中进行管理。我们来看一下具体如何操作吧。
import React from 'react'
class Child_1 extends React.Component{
constructor(props){
super(props)
}
render(){
return (
<div>
<h1>{this.props.value+2}</h1>
</div>
)
}
}
class Child_2 extends React.Component{
constructor(props){
super(props)
}
render(){
return (
<div>
<h1>{this.props.value+1}</h1>
</div>
)
}
}
class Three extends React.Component {
constructor(props){
super(props)
this.state = {
txt:"牛逼"
}
this.handleChange = this.handleChange.bind(this)
}
handleChange(e){
this.setState({
txt:e.target.value
})
}
render(){
return (
<div>
<input type="text" value={this.state.txt} onChange={this.handleChange}/>
<p>{this.state.txt}</p>
<Child_1 value={this.state.txt}/>
<Child_2 value={this.state.txt}/>
</div>
)
}
}
export default Three
对 React context 的理解
在React中,数据传递一般使用props传递数据,维持单向数据流,这样可以让组件之间的关系变得简单且可预测,但是单项数据流在某些场景中并不适用。单纯一对的父子组件传递并无问题,但要是组件之间层层依赖深入,props就需要层层传递显然,这样做太繁琐了。
Context 提供了一种在组件之间共享此类值的方式,而不必显式地通过组件树的逐层传递 props。
可以把context当做是特定一个组件树内共享的store,用来做数据传递。简单说就是,当你不想在组件树中通过逐层传递props或者state的方式来传递数据时,可以使用Context来实现跨层级的组件数据传递。
JS的代码块在执行期间,会创建一个相应的作用域链,这个作用域链记录着运行时JS代码块执行期间所能访问的活动对象,包括变量和函数,JS程序通过作用域链访问到代码块内部或者外部的变量和函数。
假如以JS的作用域链作为类比,React组件提供的Context对象其实就好比一个提供给子组件访问的作用域,而 Context对象的属性可以看成作用域上的活动对象。由于组件 的 Context 由其父节点链上所有组件通 过 getChildContext()返回的Context对象组合而成,所以,组件通过Context是可以访问到其父组件链上所有节点组件提供的Context的属性。
React声明组件有哪几种方法,有什么不同?
React 声明组件的三种方式:
- 函数式定义的
无状态组件 - ES5原生方式
React.createClass定义的组件 - ES6形式的
extends React.Component定义的组件
(1)无状态函数式组件 它是为了创建纯展示组件,这种组件只负责根据传入的props来展示,不涉及到state状态的操作
组件不会被实例化,整体渲染性能得到提升,不能访问this对象,不能访问生命周期的方法
(2)ES5 原生方式 React.createClass // RFC React.createClass会自绑定函数方法,导致不必要的性能开销,增加代码过时的可能性。
(3)E6继承形式 React.Component // RCC 目前极为推荐的创建有状态组件的方式,最终会取代React.createClass形式;相对于 React.createClass可以更好实现代码复用。
无状态组件相对于于后者的区别: 与无状态组件相比,React.createClass和React.Component都是创建有状态的组件,这些组件是要被实例化的,并且可以访问组件的生命周期方法。
React.createClass与React.Component区别:
① 函数this自绑定
- React.createClass创建的组件,其每一个成员函数的this都有React自动绑定,函数中的this会被正确设置。
- React.Component创建的组件,其成员函数不会自动绑定this,需要开发者手动绑定,否则this不能获取当前组件实例对象。
② 组件属性类型propTypes及其默认props属性defaultProps配置不同
- React.createClass在创建组件时,有关组件props的属性类型及组件默认的属性会作为组件实例的属性来配置,其中defaultProps是使用getDefaultProps的方法来获取默认组件属性的
- React.Component在创建组件时配置这两个对应信息时,他们是作为组件类的属性,不是组件实例的属性,也就是所谓的类的静态属性来配置的。
③ 组件初始状态state的配置不同
- React.createClass创建的组件,其状态state是通过getInitialState方法来配置组件相关的状态;
- React.Component创建的组件,其状态state是在constructor中像初始化组件属性一样声明的。
React中constructor和getInitialState的区别?
两者都是用来初始化state的。前者是ES6中的语法,后者是ES5中的语法,新版本的React中已经废弃了该方法。
getInitialState是ES5中的方法,如果使用createClass方法创建一个Component组件,可以自动调用它的getInitialState方法来获取初始化的State对象,
var APP = React.creatClass ({
getInitialState() {
return {
userName: 'hi',
userId: 0
};
}
})
React在ES6的实现中去掉了getInitialState这个hook函数,规定state在constructor中实现,如下:
Class App extends React.Component{
constructor(props){
super(props);
this.state={};
}
}
参考 前端进阶面试题详细解答
React-Router的路由有几种模式?
React-Router 支持使用 hash(对应 HashRouter)和 browser(对应 BrowserRouter) 两种路由规则, react-router-dom 提供了 BrowserRouter 和 HashRouter 两个组件来实现应用的 UI 和 URL 同步:
- BrowserRouter 创建的 URL 格式:xxx.com/path
- HashRouter 创建的 URL 格式:xxx.com/#/path
(1)BrowserRouter
它使用 HTML5 提供的 history API(pushState、replaceState 和 popstate 事件)来保持 UI 和 URL 的同步。由此可以看出,BrowserRouter 是使用 HTML 5 的 history API 来控制路由跳转的:
<BrowserRouter
basename={string}
forceRefresh={bool}
getUserConfirmation={func}
keyLength={number}
/>
其中的属性如下:
- basename 所有路由的基准 URL。basename 的正确格式是前面有一个前导斜杠,但不能有尾部斜杠;
<BrowserRouter basename="/calendar">
<Link to="/today" />
</BrowserRouter>
等同于
<a href="/calendar/today" />
- forceRefresh 如果为 true,在导航的过程中整个页面将会刷新。一般情况下,只有在不支持 HTML5 history API 的浏览器中使用此功能;
- getUserConfirmation 用于确认导航的函数,默认使用 window.confirm。例如,当从 /a 导航至 /b 时,会使用默认的 confirm 函数弹出一个提示,用户点击确定后才进行导航,否则不做任何处理;
// 这是默认的确认函数
const getConfirmation = (message, callback) => {
const allowTransition = window.confirm(message);
callback(allowTransition);
}
<BrowserRouter getUserConfirmation={getConfirmation} />
需要配合
<Prompt>一起使用。
- KeyLength 用来设置 Location.Key 的长度。
(2)HashRouter
使用 URL 的 hash 部分(即 window.location.hash)来保持 UI 和 URL 的同步。由此可以看出,HashRouter 是通过 URL 的 hash 属性来控制路由跳转的:
<HashRouter
basename={string}
getUserConfirmation={func}
hashType={string}
/>
其参数如下:
- basename, getUserConfirmation 和
BrowserRouter功能一样; - hashType window.location.hash 使用的 hash 类型,有如下几种:
- slash - 后面跟一个斜杠,例如 #/ 和 #/sunshine/lollipops;
- noslash - 后面没有斜杠,例如 # 和 #sunshine/lollipops;
- hashbang - Google 风格的 ajax crawlable,例如 #!/ 和 #!/sunshine/lollipops。
React 设计思路,它的理念是什么?
(1)编写简单直观的代码
React最大的价值不是高性能的虚拟DOM、封装的事件机制、服务器端渲染,而是声明式的直观的编码方式。react文档第一条就是声明式,React 使创建交互式 UI 变得轻而易举。为应用的每一个状态设计简洁的视图,当数据改变时 React 能有效地更新并正确地渲染组件。 以声明式编写 UI,可以让代码更加可靠,且方便调试。
(2)简化可复用的组件
React框架里面使用了简化的组件模型,但更彻底地使用了组件化的概念。React将整个UI上的每一个功能模块定义成组件,然后将小的组件通过组合或者嵌套的方式构成更大的组件。React的组件具有如下的特性∶
- 可组合:简单组件可以组合为复杂的组件
- 可重用:每个组件都是独立的,可以被多个组件使用
- 可维护:和组件相关的逻辑和UI都封装在了组件的内部,方便维护
- 可测试:因为组件的独立性,测试组件就变得方便很多。
(3) Virtual DOM
真实页面对应一个 DOM 树。在传统页面的开发模式中,每次需要更新页面时,都要手动操作 DOM 来进行更新。 DOM 操作非常昂贵。在前端开发中,性能消耗最大的就是 DOM 操作,而且这部分代码会让整体项目的代码变得难 以维护。React 把真实 DOM 树转换成 JavaScript 对象树,也就是 Virtual DOM,每次数据更新后,重新计算 Virtual DOM,并和上一次生成的 Virtual DOM 做对比,对发生变化的部分做批量更新。React 也提供了直观的 shouldComponentUpdate 生命周期回调,来减少数据变化后不必要的 Virtual DOM 对比过程,以保证性能。
(4)函数式编程
React 把过去不断重复构建 UI 的过程抽象成了组件,且在给定参数的情况下约定渲染对应的 UI 界面。React 能充分利用很多函数式方法去减少冗余代码。此外,由于它本身就是简单函数,所以易于测试。
(5)一次学习,随处编写
无论现在正在使用什么技术栈,都可以随时引入 React来开发新特性,而不需要重写现有代码。
React 还可以使用 Node 进行服务器渲染,或使用 React Native 开发原生移动应用。因为 React 组件可以映射为对应的原生控件。在输出的时候,是输出 Web DOM,还是 Android 控件,还是 iOS 控件,就由平台本身决定了。所以,react很方便和其他平台集成
React 组件中怎么做事件代理?它的原理是什么?
React基于Virtual DOM实现了一个SyntheticEvent层(合成事件层),定义的事件处理器会接收到一个合成事件对象的实例,它符合W3C标准,且与原生的浏览器事件拥有同样的接口,支持冒泡机制,所有的事件都自动绑定在最外层上。
在React底层,主要对合成事件做了两件事:
- 事件委派: React会把所有的事件绑定到结构的最外层,使用统一的事件监听器,这个事件监听器上维持了一个映射来保存所有组件内部事件监听和处理函数。
- 自动绑定: React组件中,每个方法的上下文都会指向该组件的实例,即自动绑定this为当前组件。
React-Router怎么设置重定向?
使用<Redirect>组件实现路由的重定向:
<Switch>
<Redirect from='/users/:id' to='/users/profile/:id'/>
<Route path='/users/profile/:id' component={Profile}/>
</Switch>
当请求 /users/:id 被重定向去 '/users/profile/:id':
- 属性
from: string:需要匹配的将要被重定向路径。 - 属性
to: string:重定向的 URL 字符串 - 属性
to: object:重定向的 location 对象 - 属性
push: bool:若为真,重定向操作将会把新地址加入到访问历史记录里面,并且无法回退到前面的页面。
setState 是同步异步?为什么?实现原理?
1. setState是同步执行的
setState是同步执行的,但是state并不一定会同步更新
2. setState在React生命周期和合成事件中批量覆盖执行
在React的生命周期钩子和合成事件中,多次执行setState,会批量执行
具体表现为,多次同步执行的setState,会进行合并,类似于Object.assign,相同的key,后面的会覆盖前面的
当遇到多个setState调用时候,会提取单次传递setState的对象,把他们合并在一起形成一个新的
单一对象,并用这个单一的对象去做setState的事情,就像Object.assign的对象合并,后一个
key值会覆盖前面的key值
经过React 处理的事件是不会同步更新 this.state的. 通过 addEventListener || setTimeout/setInterval 的方式处理的则会同步更新。
为了合并setState,我们需要一个队列来保存每次setState的数据,然后在一段时间后执行合并操作和更新state,并清空这个队列,然后渲染组件。
如何将两个或多个组件嵌入到一个组件中?
可以通过以下方式将组件嵌入到一个组件中:
class MyComponent extends React.Component{
render(){
return(
<div>
<h1>Hello</h1>
<Header/>
</div>
);
}
}
class Header extends React.Component{
render(){
return
<h1>Header Component</h1>
};
}
ReactDOM.render(
<MyComponent/>, document.getElementById('content')
);
HOC相比 mixins 有什么优点?
HOC 和 Vue 中的 mixins 作用是一致的,并且在早期 React 也是使用 mixins 的方式。但是在使用 class 的方式创建组件以后,mixins 的方式就不能使用了,并且其实 mixins 也是存在一些问题的,比如:
- 隐含了一些依赖,比如我在组件中写了某个
state并且在mixin中使用了,就这存在了一个依赖关系。万一下次别人要移除它,就得去mixin中查找依赖 - 多个
mixin中可能存在相同命名的函数,同时代码组件中也不能出现相同命名的函数,否则就是重写了,其实我一直觉得命名真的是一件麻烦事。。 - 雪球效应,虽然我一个组件还是使用着同一个
mixin,但是一个mixin会被多个组件使用,可能会存在需求使得mixin修改原本的函数或者新增更多的函数,这样可能就会产生一个维护成本
HOC 解决了这些问题,并且它们达成的效果也是一致的,同时也更加的政治正确(毕竟更加函数式了)。
React Hooks 和生命周期的关系?
函数组件 的本质是函数,没有 state 的概念的,因此不存在生命周期一说,仅仅是一个 render 函数而已。
但是引入 Hooks 之后就变得不同了,它能让组件在不使用 class 的情况下拥有 state,所以就有了生命周期的概念,所谓的生命周期其实就是 useState、 useEffect() 和 useLayoutEffect() 。
即:Hooks 组件(使用了Hooks的函数组件)有生命周期,而函数组件(未使用Hooks的函数组件)是没有生命周期的。
下面是具体的 class 与 Hooks 的生命周期对应关系:
constructor:函数组件不需要构造函数,可以通过调用**useState 来初始化 state**。如果计算的代价比较昂贵,也可以传一个函数给useState。
const [num, UpdateNum] = useState(0)
getDerivedStateFromProps:一般情况下,我们不需要使用它,可以在渲染过程中更新 state,以达到实现getDerivedStateFromProps的目的。
function ScrollView({row}) {
let [isScrollingDown, setIsScrollingDown] = useState(false);
let [prevRow, setPrevRow] = useState(null);
if (row !== prevRow) {
// Row 自上次渲染以来发生过改变。更新 isScrollingDown。
setIsScrollingDown(prevRow !== null && row > prevRow);
setPrevRow(row);
}
return `Scrolling down: ${isScrollingDown}`;
}
React 会立即退出第一次渲染并用更新后的 state 重新运行组件以避免耗费太多性能。
shouldComponentUpdate:可以用**React.memo**包裹一个组件来对它的props进行浅比较
const Button = React.memo((props) => { // 具体的组件});
注意:**React.memo 等效于 **``**PureComponent**,它只浅比较 props。这里也可以使用 useMemo 优化每一个节点。
render:这是函数组件体本身。componentDidMount,componentDidUpdate:useLayoutEffect与它们两的调用阶段是一样的。但是,我们推荐你一开始先用 useEffect,只有当它出问题的时候再尝试使用useLayoutEffect。useEffect可以表达所有这些的组合。
// componentDidMount
useEffect(()=>{
// 需要在 componentDidMount 执行的内容
}, [])
useEffect(() => {
// 在 componentDidMount,以及 count 更改时 componentDidUpdate 执行的内容
document.title = `You clicked ${count} times`;
return () => {
// 需要在 count 更改时 componentDidUpdate(先于 document.title = ... 执行,遵守先清理后更新)
// 以及 componentWillUnmount 执行的内容
} // 当函数中 Cleanup 函数会按照在代码中定义的顺序先后执行,与函数本身的特性无关
}, [count]); // 仅在 count 更改时更新
请记得 React 会等待浏览器完成画面渲染之后才会延迟调用 ,因此会使得额外操作很方便
componentWillUnmount:相当于useEffect里面返回的cleanup函数
// componentDidMount/componentWillUnmount
useEffect(()=>{
// 需要在 componentDidMount 执行的内容
return function cleanup() {
// 需要在 componentWillUnmount 执行的内容
}
}, [])
componentDidCatchandgetDerivedStateFromError:目前还没有这些方法的 Hook 等价写法,但很快会加上。
| class 组件 | Hooks 组件 |
|---|---|
| constructor | useState |
| getDerivedStateFromProps | useState 里面 update 函数 |
| shouldComponentUpdate | useMemo |
| render | 函数本身 |
| componentDidMount | useEffect |
| componentDidUpdate | useEffect |
| componentWillUnmount | useEffect 里面返回的函数 |
| componentDidCatch | 无 |
| getDerivedStateFromError | 无 |
为什么 useState 要使用数组而不是对象
useState 的用法:
const [count, setCount] = useState(0)
可以看到 useState 返回的是一个数组,那么为什么是返回数组而不是返回对象呢?
这里用到了解构赋值,所以先来看一下ES6 的解构赋值:
数组的解构赋值
const foo = [1, 2, 3];
const [one, two, three] = foo;
console.log(one); // 1
console.log(two); // 2
console.log(three); // 3
对象的解构赋值
const user = {
id: 888,
name: "xiaoxin"
};
const { id, name } = user;
console.log(id); // 888
console.log(name); // "xiaoxin"
看完这两个例子,答案应该就出来了:
- 如果 useState 返回的是数组,那么使用者可以对数组中的元素命名,代码看起来也比较干净
- 如果 useState 返回的是对象,在解构对象的时候必须要和 useState 内部实现返回的对象同名,想要使用多次的话,必须得设置别名才能使用返回值
下面来看看如果 useState 返回对象的情况:
// 第一次使用
const { state, setState } = useState(false);
// 第二次使用
const { state: counter, setState: setCounter } = useState(0)
这里可以看到,返回对象的使用方式还是挺麻烦的,更何况实际项目中会使用的更频繁。 总结:useState 返回的是 array 而不是 object 的原因就是为了降低使用的复杂度,返回数组的话可以直接根据顺序解构,而返回对象的话要想使用多次就需要定义别名了。
高阶组件存在的问题
- 静态方法丢失(必须将静态方法做拷贝)
refs属性不能透传(如果你向一个由高阶组件创建的组件的元素添加ref引用,那么ref指向的是最外层容器组件实例的,而不是被包裹的WrappedComponent组件。)- 反向继承不能保证完整的子组件树被解析
React 组件有两种形式,分别是 class 类型和 function 类型(无状态组件)。
我们知道反向继承的渲染劫持可以控制 WrappedComponent 的渲染过程,也就是说这个过程中我们可以对 elements tree、 state、 props 或 render() 的结果做各种操作。
但是如果渲染 elements tree 中包含了 function 类型的组件的话,这时候就不能操作组件的子组件了。
React Hooks在平时开发中需要注意的问题和原因
(1)不要在循环,条件或嵌套函数中调用Hook,必须始终在 React函数的顶层使用Hook
这是因为React需要利用调用顺序来正确更新相应的状态,以及调用相应的钩子函数。一旦在循环或条件分支语句中调用Hook,就容易导致调用顺序的不一致性,从而产生难以预料到的后果。
(2)使用useState时候,使用push,pop,splice等直接更改数组对象的坑
使用push直接更改数组无法获取到新值,应该采用析构方式,但是在class里面不会有这个问题。代码示例:
function Indicatorfilter() {
let [num,setNums] = useState([0,1,2,3])
const test = () => {
// 这里坑是直接采用push去更新num
// setNums(num)是无法更新num的
// 必须使用num = [...num ,1]
num.push(1)
// num = [...num ,1]
setNums(num)
}
return (
<div className='filter'>
<div onClick={test}>测试</div>
<div>
{num.map((item,index) => ( <div key={index}>{item}</div>
))} </div>
</div>
)
}
class Indicatorfilter extends React.Component<any,any>{
constructor(props:any){
super(props)
this.state = {
nums:[1,2,3]
}
this.test = this.test.bind(this)
}
test(){
// class采用同样的方式是没有问题的
this.state.nums.push(1)
this.setState({
nums: this.state.nums
})
}
render(){
let {nums} = this.state
return(
<div>
<div onClick={this.test}>测试</div>
<div>
{nums.map((item:any,index:number) => ( <div key={index}>{item}</div>
))} </div>
</div>
)
}
}
(3)useState设置状态的时候,只有第一次生效,后期需要更新状态,必须通过useEffect
TableDeail是一个公共组件,在调用它的父组件里面,我们通过set改变columns的值,以为传递给TableDeail 的 columns是最新的值,所以tabColumn每次也是最新的值,但是实际tabColumn是最开始的值,不会随着columns的更新而更新:
const TableDeail = ({ columns,}:TableData) => {
const [tabColumn, setTabColumn] = useState(columns)
}
// 正确的做法是通过useEffect改变这个值
const TableDeail = ({ columns,}:TableData) => {
const [tabColumn, setTabColumn] = useState(columns)
useEffect(() =>{setTabColumn(columns)},[columns])
}
(4)善用useCallback
父组件传递给子组件事件句柄时,如果我们没有任何参数变动可能会选用useMemo。但是每一次父组件渲染子组件即使没变化也会跟着渲染一次。
(5)不要滥用useContext
可以使用基于 useContext 封装的状态管理工具。
如何在React中使用innerHTML
增加dangerouslySetInnerHTML属性,并且传入对象的属性名叫_html
function Component(props){
return <div dangerouslySetInnerHTML={{_html:'<span>你好</span>'}}>
</div>
}
react 生命周期
初始化阶段:
- getDefaultProps:获取实例的默认属性
- getInitialState:获取每个实例的初始化状态
- componentWillMount:组件即将被装载、渲染到页面上
- render:组件在这里生成虚拟的 DOM 节点
- componentDidMount:组件真正在被装载之后
运行中状态:
- componentWillReceiveProps:组件将要接收到属性的时候调用
- shouldComponentUpdate:组件接受到新属性或者新状态的时候(可以返回 false,接收数据后不更新,阻止 render 调用,后面的函数不会被继续执行了)
- componentWillUpdate:组件即将更新不能修改属性和状态
- render:组件重新描绘
- componentDidUpdate:组件已经更新
销毁阶段:
- componentWillUnmount:组件即将销毁
shouldComponentUpdate 是做什么的,(react 性能优化是哪个周期函数?)
shouldComponentUpdate 这个方法用来判断是否需要调用 render 方法重新描绘 dom。因为 dom 的描绘非常消耗性能,如果我们能在 shouldComponentUpdate 方法中能够写出更优化的 dom diff 算法,可以极大的提高性能。
在react17 会删除以下三个生命周期
componentWillMount,componentWillReceiveProps , componentWillUpdate
React-Router 4的Switch有什么用?
Switch 通常被用来包裹 Route,用于渲染与路径匹配的第一个子 <Route> 或 <Redirect>,它里面不能放其他元素。
假如不加 <Switch> :
import { Route } from 'react-router-dom'
<Route path="/" component={Home}></Route>
<Route path="/login" component={Login}></Route>
Route 组件的 path 属性用于匹配路径,因为需要匹配 / 到 Home,匹配 /login 到 Login,所以需要两个 Route,但是不能这么写。这样写的话,当 URL 的 path 为 “/login” 时,<Route path="/" />和<Route path="/login" /> 都会被匹配,因此页面会展示 Home 和 Login 两个组件。这时就需要借助 <Switch> 来做到只显示一个匹配组件:
import { Switch, Route} from 'react-router-dom'
<Switch>
<Route path="/" component={Home}></Route>
<Route path="/login" component={Login}></Route>
</Switch>
此时,再访问 “/login” 路径时,却只显示了 Home 组件。这是就用到了exact属性,它的作用就是精确匹配路径,经常与<Switch> 联合使用。只有当 URL 和该 <Route> 的 path 属性完全一致的情况下才能匹配上:
import { Switch, Route} from 'react-router-dom'
<Switch>
<Route exact path="/" component={Home}></Route>
<Route exact path="/login" component={Login}></Route>
</Switch>