目录
数据中对特征的处理
特征工程定义
特征工程意义
安装scikit-learn
数据的特征抽取
字典特征抽取
DictVectorizer语法
文本特征抽取
CountVectorizer语法
TfidfVectorizer语法
数据中对特征的处理
pandas:一个数据读取非常方便以及基础的处理格式的工具
sklearn:对于特征的处理提供了强大的接口
特征工程定义
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的预测准确性
特征工程意义
直接影响预测结果
安装scikit-learn

数据的特征抽取
特征抽取对文本等数据进行特征值化
特征值化是为了计算机更好的去理解数据
字典特征抽取
作用:对字典数据进行特征值化
DictVectorizer语法

from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""字典数据抽取"""
# 实例化
dict = DictVectorizer()
# 调用fit_transform
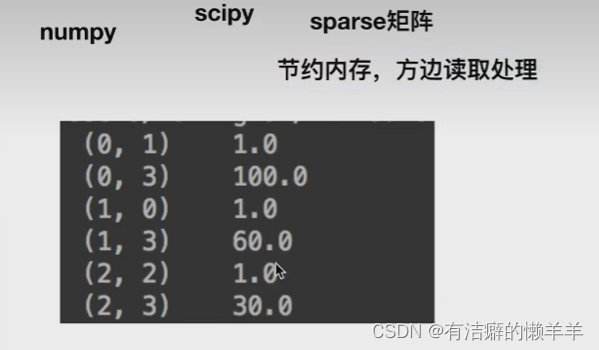
data = dict.fit_transform([{'city':'北京','temperature':100},
{'city':'上海','temperature':60},
{'city':'深圳','temperature':30}])
print(data)
return None
if _name_="main":
dictvec()返回结果:
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""字典数据抽取"""
# 实例化
dict = DictVectorizer(sparse=False)
# 调用fit_transform
data = dict.fit_transform([{'city':'北京','temperature':100},
{'city':'上海','temperature':60},
{'city':'深圳','temperature':30}])
print(data)
return None
if _name_="main":
dictvec()返回结果:
one-hot编码:
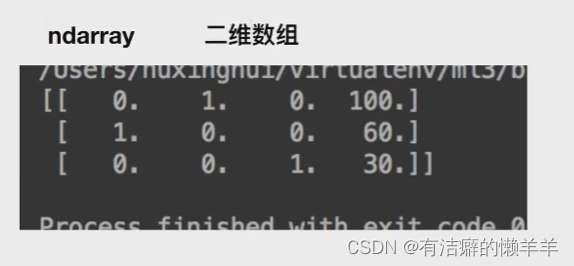
字典数据抽取:把字典中一些类别数据,分别进行转换成特征
数组形式,有类别的这些特征,先要转换成字典数据
文本特征抽取
作用:对文本数据进行特征值化
CountVectorizer语法

from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def dictvec():
"""字典数据抽取"""
# 实例化
dict = DictVectorizer(sparse=False)
# 调用fit_transform
data = dict.fit_transform([{'city':'北京','temperature':100},
{'city':'上海','temperature':60},
{'city':'深圳','temperature':30}])
print(data)
return None
def countvec():
"""对文本进行特征值化"""
# 实例化
cv = CountVectorizer()
# 调用fit_transform
data = cv.fit_transform(["life is short,i like python","life is too long,i dislike python"])
print(cv.get_feature_names())
print(data.toarray())
return None
if _name_="main":
countvec()
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
"""对文本进行特征值化"""
# 实例化
cv = CountVectorizer()
# 调用fit_transform
data = cv.fit_transform(["人生 苦短,我 喜欢 python","人生漫长,不用 python"])
print(cv.get_feature_names())
print(data.toarray())
return None
if _name_="main":
countvec()
一句话便需要先进行分词,空格隔开
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")
con2 =jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇由时,我们是在看它的过去。")
con3 =jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 把列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1,c2,c3
def hanzivec():
"""中文特征值化"""
c1,c2,c3 = cutword()
cv = CountVectorizer()
# 调用fit_transform
data = cv.fit_transform([c1,c2,c3])
print(cv.get_feature_names())
print(data.toarray())
return None
if _name_="main":
hanzivec()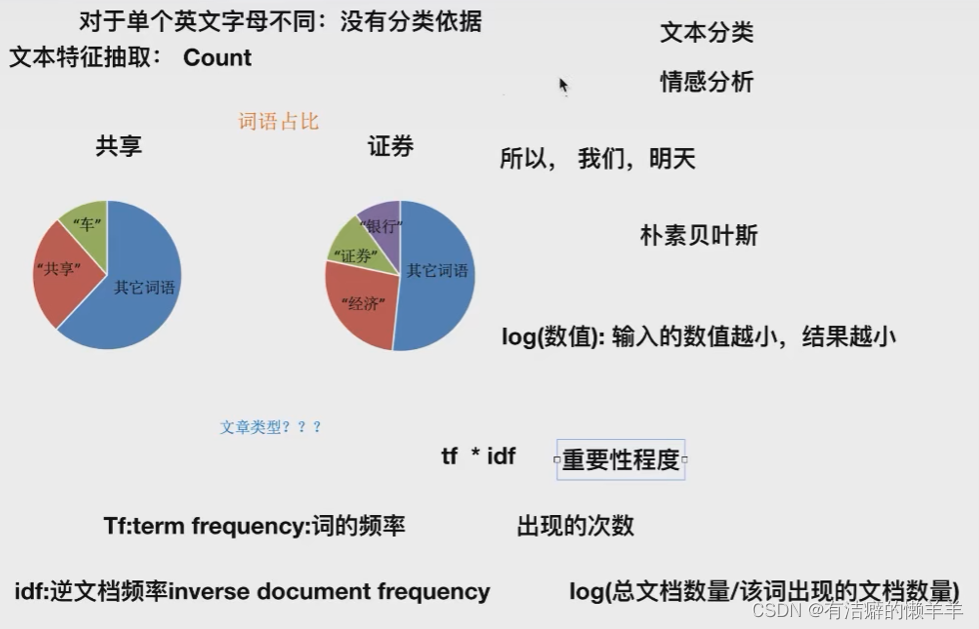
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度
TfidfVectorizer语法

from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import jieba
def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")
con2 =jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇由时,我们是在看它的过去。")
con3 =jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 把列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1,c2,c3
def tfidfvec():
"""中文特征值化"""
c1,c2,c3 = cutword()
tf = TfidfVectorizer()
# 调用fit_transform
data = tf.fit_transform([c1,c2,c3])
print(tf.get_feature_names())
print(data.toarray())
return None
if _name_="main":
tfidfvec()
为什么需要TfidfVectorizer?
分类机器学习算法的重要依据