本次整理的学习笔记的是Hadoop HDFS的架构、高可用与容错机制,供大家参考学习,enjoy~~
一、HDFS的架构
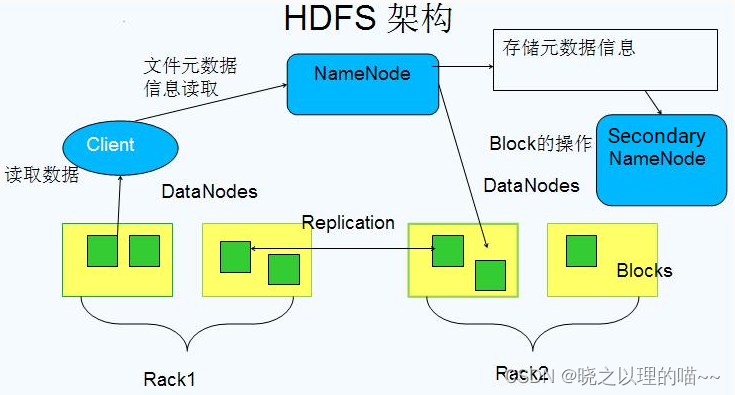
1,NameNode
(1) 存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小
(2)一个Block在NameNode中对应一条记录(一般一个block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以用MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。因此Hadoop建议存储大文件
(3) 数据会定时保存到本地磁盘,但不保存block的位置信息,而是由DataNode注册时上报和运行时维护(NameNode中与DataNode相关的信息并不保存到NameNode的文件系统中,而是NameNode每次重启后,动态重建)
(4)NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性。
2,Secondary NameNode
定时与NameNode进行同步(定期合并文件系统镜像和编辑日志,然后把合并后的传给NameNode,替换其镜像,并清空编辑日志,类似于CheckPoint机制),但NameNode失效后仍需要手工将其设置成主机。
3,DataNode
(1) 保存具体的block数据。
(2)负责数据的读写操作和复制操作。
(3)DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息。
(4)DataNode之间会进行通信,复制数据块,保证数据的冗余性。
4,Block数据块
(1)基本存储单位,一般大小为64M(配置大的块主要是因为:
1)减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;
2)减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;
3)对数据块进行读写,减少建立网络的连接成本)
(2) 一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,那么实际占用的空间为其文件的大小
(3)基本的读写单位,类似于磁盘的页,每次都是读写一个块
(4)每个块都会被复制到多台机器,默认复制3份
(5)HDFS2.x以后的block默认128M
二、HDFS 数据块
1,含义
要把大文件存储在 HDFS上,HDFS 会把大文件分割成小块,即我们通常说的数据块( block ),它是 Hadoop 分布式文件系统最小的存储单元,而且我们没办法决定指定块的存储节点地址,这些 Namenode 会替我们决定。数据块默认大小是 128MB,比操作系统里面的块概念要大很多(操作系统块大小是 4KB ),我们可以根据实际需求修改 HDFS 块大小。文件的所有数据块大小都是一样的,除了最后一个,它可能小于块大小或者刚好等于块大小。文件会被分割成若干个 128MB 的小数据块,再写入HDFS的。

假如需要把一个 518MB 的文本文件 Example.txt 存储到 HDFS,在块大小默认情况下,HDFS 将会创建 5 个数据块,前面4个数据块大小将是 128MB,最后一个是 6MB,而不是 128MB。这样会节省不少存储空间。
2,HDFS 块大小为什么默认是 128MB
HDFS 存储的数据集一般比较大,数据量级一般是 TB 级别或者 PB 级别的。如果像 Linux 系统那样每个块只有 4KB。那么 HDFS 将会存储非常多的数据块,这将导致元数据暴增,NameNode 管理维护这些元数据将非常吃力。且很快会成为集群性能的瓶颈。另一方面,数据块的大小不能太大,不然文件系统处理数据延迟会更加严重。
3,HDFS 数据块的优势
(1)方便管理
由于数据块的固定的,磁盘能够存储多少数据块很容易就可以计算出来。
(2)存储大文件
HDFS 可以存储比单个磁盘容量还大的数据文件,因为文件会被划分成多个 HDFS 数据块,并存储在集群的多个Datanode 磁盘上。
(3)容错性和高可用
数据块很容易在 Datanode 之间复制,以便达到数据的容错性和高可用性。
(4)简单的 Datanode 存储机制
HDFS 数据块的概念简化了 Datanode 的数据存储方式。所有块的元数据都是在 Namenode 维护的。Datanode 不需要关心块的元数据,比如文件权限,存储位置等。
三、HDFS 的高可用性
HDFS的高可用指的是HDFS持续对各类客户端提供读、写服务的能力,因为客户端对HDFS的读、写操作之前都要访问name node服务器,只有从name node获取元数据之后才能继续进行读、写。所以HDFS的高可用的关键在于name node上的元数据持续可用。
在 hadoop 1.x 的 HDFS 框架中只存在一个 namenode 节点,当这个 namenode 节点出现内存溢出、宕机等意外情况之后,整个系统就会停止服务,直到我们重启这个 namenode 节点。为了解决这个问题,在 hadoop2.x 的 HDFS 框架中,实现了 HA 的机制。
在高可用配置下,edit log不再存放在名称节点,而是存放在一个共享存储的地方,这个共享存储由奇数个Journal Node组成,一般是3个节点(JN小集群), 每个JN专门用于存放来自NN的编辑日志,编辑日志由活跃状态的名称节点写入JN小集群。
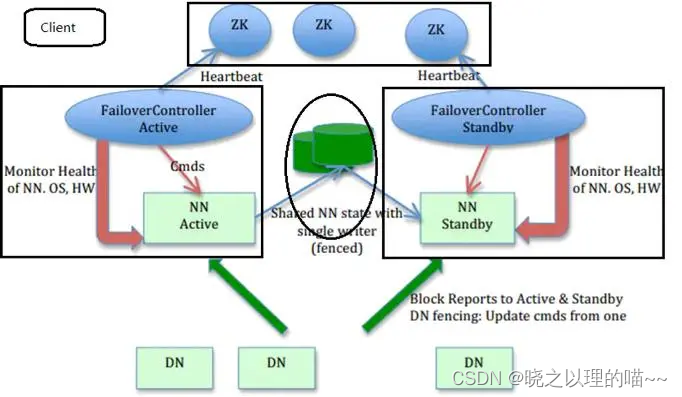
释义:
1,Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
2,主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
3,Zookeeper 集群:为主备切换控制器提供主备选举支持。
4,共享存储系统:共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。Active NameNode 和 Standby NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
可以看出,这里的核心是共享存储的实现,下面为大家介绍一种基于 QJM(Quorum Journal Manager)的默认存储方案。方案合并到 HDFS 的 trunk 之中并且作为默认的共享存储实现。
四、容错机制
HDFS 是具有很好的容错性的分布式存储系统,它利用复制技术实现数据容错能力,数据会被复制多份并存储在集群的不同节点。这样,集群中的某些机器宕机了,数据还可以从其他正常运行的机器获取。如果有一个机器宕机了,HDFS 会在其他可用的机器创建数据的副本,来保证该数据的副本数与集群的副本因子是一致的。
故障类型
我们来看看出现的故障类型。
• 节点失败:即DataNode节点失败。
• 网络故障:无法发送和接收数据。
• 数据损坏:数据在不稳定的网络传输中或在硬盘中存储出错。
1,故障检测机制
针对这三类故障的检测机制是这样的。
2,节点失败检测机制
每个DataNode以固定的周期向NameNode 发送心跳信号,通过这种方法告诉 NameNode 它们在正常工作。如果在一定的时间内 NameNode 没有收到 DataNode 心跳,就认为该 DataNode 宕机了。
3,通信故障检测机制
只要发送了数据,接收方就会返回确认码。如果经过几次重试之后,还是没有收到确认码,发送方会认为主机挂了或网络发生故障。
4,数据错误检测机制
(1)在传输数据的时候,同时会发送总和检验码,当数据存储到硬盘时,总和检验码也会被存储。
(2)所有的 DataNode 都会定期向 NameNode 发送数据块的存储状况。
(3)在发送数据块报告前,会先检查总和校验码是否正确,如果数据存在错误就不发送该数据块的信息。
数据块存储故障:数据存储的故障容错,这块主要是磁盘介质,存储数据可能会出现错乱。在DataNode数据块上存储数据时会计算并存储校验和,当对该数据块进行读操作时会计算数据校验和,如果一场就会转而去读其他DataNode节点的备份数据。
DataNode节点故障主要是通过心跳机制,DataNode会定期通过心跳去NameNode保持联系,Namenode监测到DataNode超时没有心跳后,就会查其元数据,通知其他节点复制失效节点上的数据块到其他服务器上,保证副本数量,磁盘故障的话DataNode也是类似处理,DataNode检测到磁盘故障后,将故障块反馈给namenode进行数据块复制。
以上的内容来源网络,如有侵犯,联系删除哦!