前言: 视频帧生成方法(视频插帧/视频预测)ICCV2017 oral
Video Frame Synthesis using Deep Voxel Flow
引言
当下进行视频帧合成的方法分为两种,第一种是光流法,光流准确的话效果好,光流不准确的话则生成伪影
另一种就是CNN通过卷积合成该像素位置的RGB值,这种方法没有光流好效果好,容易糊,
我们结合这两种方法的优势,用光流法,直接将附近位置的值复制过来,比从无到有的合成RGB要简单得多,同时又用了一个强大的端到端的CNN网络进行学习
我们的方法中间生成了一个 voxel flow layer,是一种3D的时空光流向量,我们的方法还不需要光流值作为监督
方法
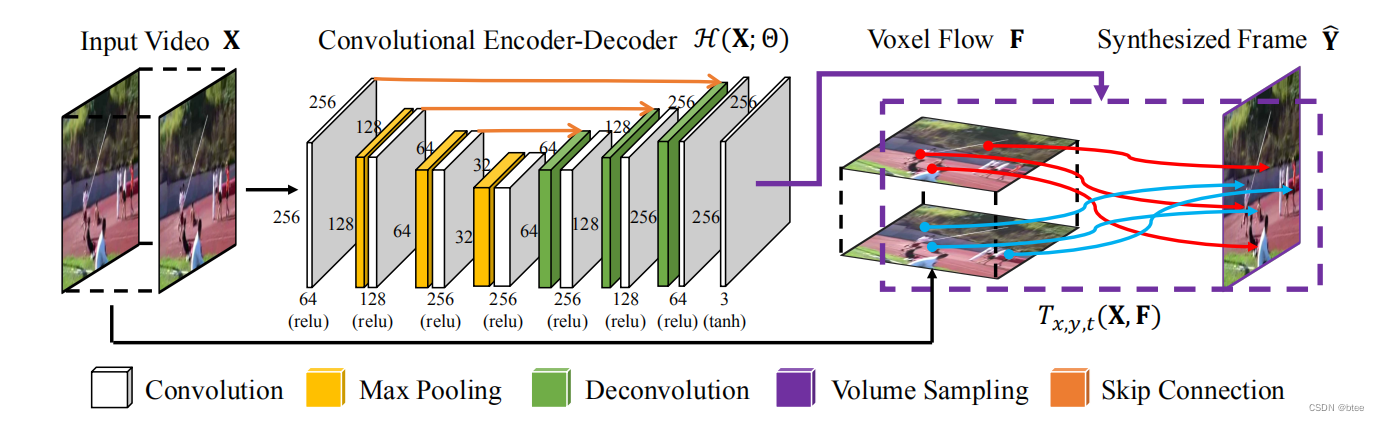
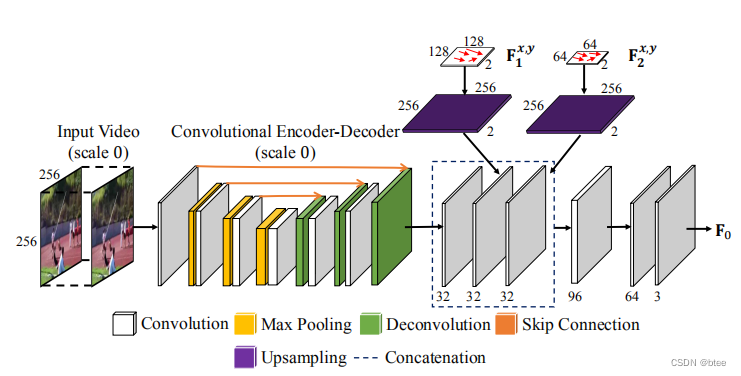
这个图还是比较简单直接的,作者主要是定义了什么是voxel Flow F
The output of H is a 3D voxel flow field F on a 2D grid of integer target pixel locations:
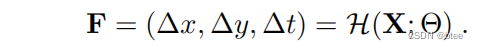
即是一盒在2D网格上的整数像素位置上的3D流量(这里的3D可以看成3个通道,分别记录三个维度上的相对位置)
由于我们假设流是线性的,因此对于中间帧插帧来说,两边向中间的流即是对称的,因此
the absolute coordinates of the corresponding locations in the earlier and later frames as L0 = (x - ∆x, y - ∆y) and L1 = (x + ∆x, y + ∆y), respectively.
利用了中间帧光流后对齐得到的第一帧L0和后一帧L1图像
于是,利用 voxel flow和L0L1 ,可以通过三线性插值得到像素位置转移后的图像(即光流warp操作)
三线性插值具体数学推导如下:
3个维度对应8个整数位置(这是因为求得的光流F(x,y)和∆t是小数,落在两个整数之间,由于时间在0-1之间,因此时间维,即第三维的整数非0即1)
注意,这个括号一个是往上取整和往下取整
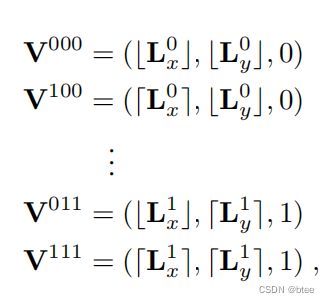
因此,在这8个不同位置上的值,乘上一个权重W
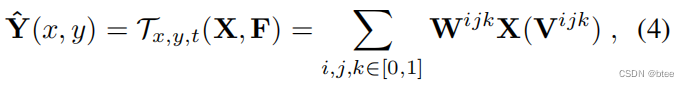
具体的权重如下:
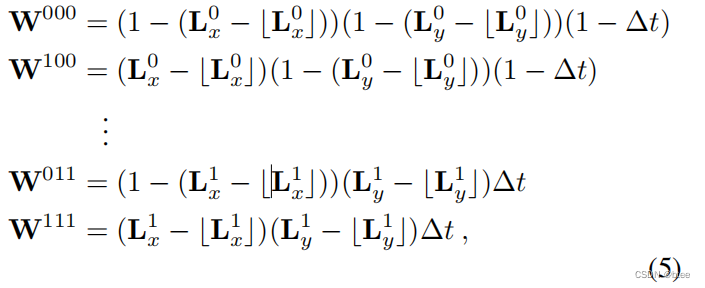
比如:对于000这个位置的x维,则是(1-【某个0-1之间的小数】),y维同样,t维为1-∆t
以此类推…
这个对应于网络里则是光流warp和mask相乘
代码如下(前面的Encoder Decoder网络省略)
flow = x[:, 0:2, :, :]
mask = x[:, 2:3, :, :]
grid_x, grid_y = meshgrid(input_size[0], input_size[1])
with torch.cuda.device(input.get_device()):
grid_x = torch.autograd.Variable(
grid_x.repeat([input.size()[0], 1, 1])).cuda()
grid_y = torch.autograd.Variable(
grid_y.repeat([input.size()[0], 1, 1])).cuda()
flow = 0.5 * flow
if self.syn_type == 'inter':
coor_x_1 = grid_x - flow[:, 0, :, :]
coor_y_1 = grid_y - flow[:, 1, :, :]
coor_x_2 = grid_x + flow[:, 0, :, :]
coor_y_2 = grid_y + flow[:, 1, :, :]
elif self.syn_type == 'extra':
coor_x_1 = grid_x - flow[:, 0, :, :] * 2
coor_y_1 = grid_y - flow[:, 1, :, :] * 2
coor_x_2 = grid_x - flow[:, 0, :, :]
coor_y_2 = grid_y - flow[:, 1, :, :]
else:
raise ValueError('Unknown syn_type ' + self.syn_type)
output_1 = torch.nn.functional.grid_sample(
input[:, 0:3, :, :],
torch.stack([coor_x_1, coor_y_1], dim=3),
padding_mode='border')
output_2 = torch.nn.functional.grid_sample(
input[:, 3:6, :, :],
torch.stack([coor_x_2, coor_y_2], dim=3),
padding_mode='border')
mask = 0.5 * (1.0 + mask) #过的是tanh
mask = mask.repeat([1, 3, 1, 1])
x = mask * output_1 + (1.0 - mask) * output_2
return x
同时作者还介绍了多尺度学习,在不同尺度上学一个voxel Flow,在上采样将不同尺度融合,这样可以处理大的运动
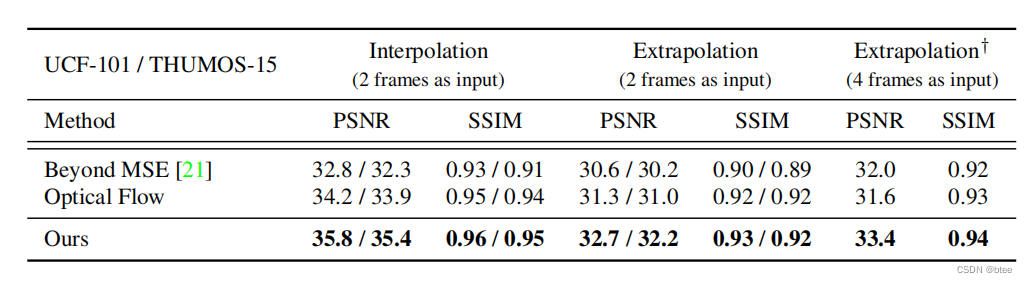
实验
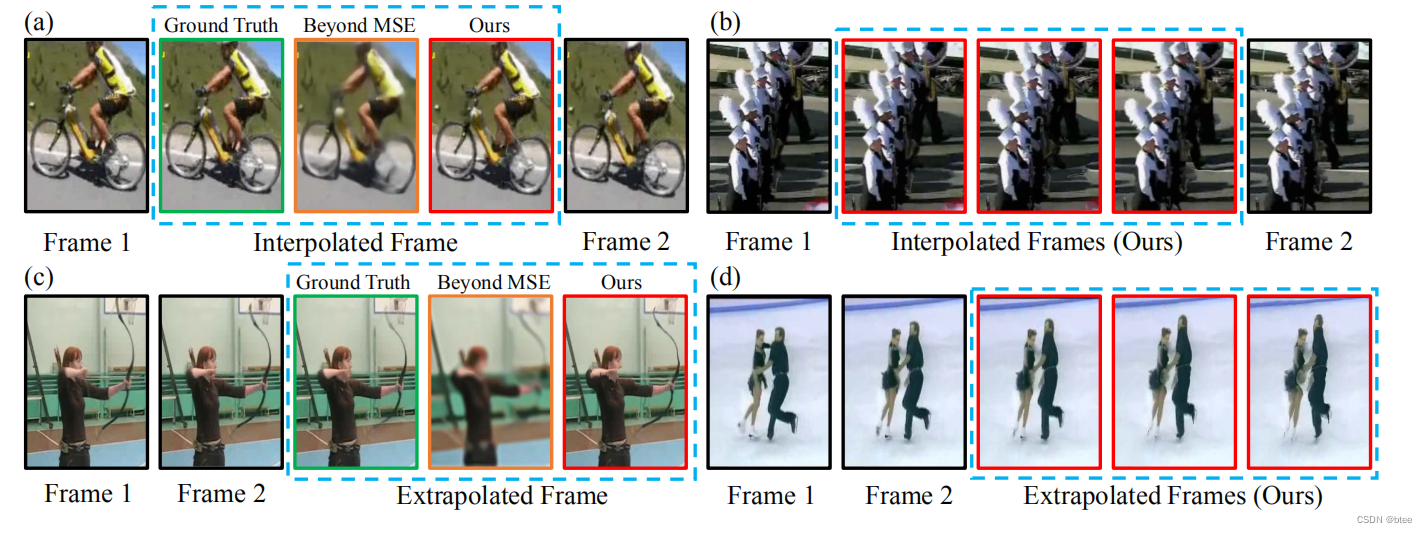
比较早期的工作,几乎没有什么方法可以对比
总结
这篇文章比superslomo还要早,里面的双向光流和Mask思想至今也还在沿用,mutil-scale的方式也用在了image enhancemen领域