01背包问题
现有一容量为w的背包,有3个物品,每个物品重量不同,价值不同,问,怎样装才能价值最大化?
- 明确dp数组含义和下标含义:dp[j]表示当前背包的最大价值。j表示背包容量。
- 递推公式:
dp[j] = Math.max(dp[j] , dp[j - weight[i]] + values[i])。dp[j]就是不放i物品时的最大价值,dp[j - weight[i]] + values[i]就是放i物品时的最大价值。 - 初始化:当背包容量为0,物品最大价值也为0。dp[0] = 0。
- 确定遍历顺序:先遍历物品,后遍历容量。并且倒序遍历背包容量,保证每个物品只被放入一次。
LeetCode
-
leetcode416
把数值问题换算为背包问题。
只有确定了如下四点,才能把01背包问题套到本题上来。
- 背包的体积为sum / 2
- 背包要放入的商品(集合里的元素)重量为 元素的数值,价值也为元素的数值
- 背包如果正好装满,说明找到了总和为 sum / 2 的子集。
- 背包中每一个元素是不可重复放入。
class Solution { public boolean canPartition(int[] nums) { /** dp[j] :元素的数值。(背包最大价值。) 递推公式: dp[j] = Math.max(dp[j] , dp[j - nums[i]] + nums[i]); dp[0] = 0. 遍历:外层遍历nums(物品),内层倒序遍历背包容量。 */ int sum = 0; for(int i : nums){ sum += i; } //不符合条件 if(sum % 2 == 1) return false; int len = sum / 2; int dp [] = new int [len + 1]; dp[0] = 0; for(int i = 0; i < nums.length; i ++){ for(int j = len; j >= nums[i]; j --){ dp[j] = Math.max(dp[j] , dp[j - nums[i]] + nums[i]); } } return dp[len] == len ? true : false; } } -
leetcode1049
class Solution { public int lastStoneWeightII(int[] stones) { //将石头尽量分解为重量相同的两堆,剩下的就是最小的重量。 /** dp[j] 为石头的最小重量 最小容量为 sum / 2 石头重量、价值为stones[i]。 */ int sum = 0; for(int i : stones){ sum += i; } int len = sum / 2; int dp [] = new int [len + 1]; dp[0] = 0; for(int i = 0 ; i < stones.length;i ++){ for(int j = len; j >= stones[i];j --){ dp[j] = Math.max(dp[j] , dp[j - stones[i]] + stones[i]); } } return sum - 2 * dp[len]; } }
第五章:存储引擎(重点)
关于存储引擎的命令
-
查看mysql提供什么存储引擎:
show engines; -
查看默认的存储引擎:
show variables like '%storage_engine%'; #或 SELECT @@default_storage_engine; -
修改默认的存储引擎
SET DEFAULT_STORAGE_ENGINE=MyISAM; -
设置表的存储引擎
ALTER TABLE 表名 ENGINE = 存储引擎名称;
引擎介绍
-
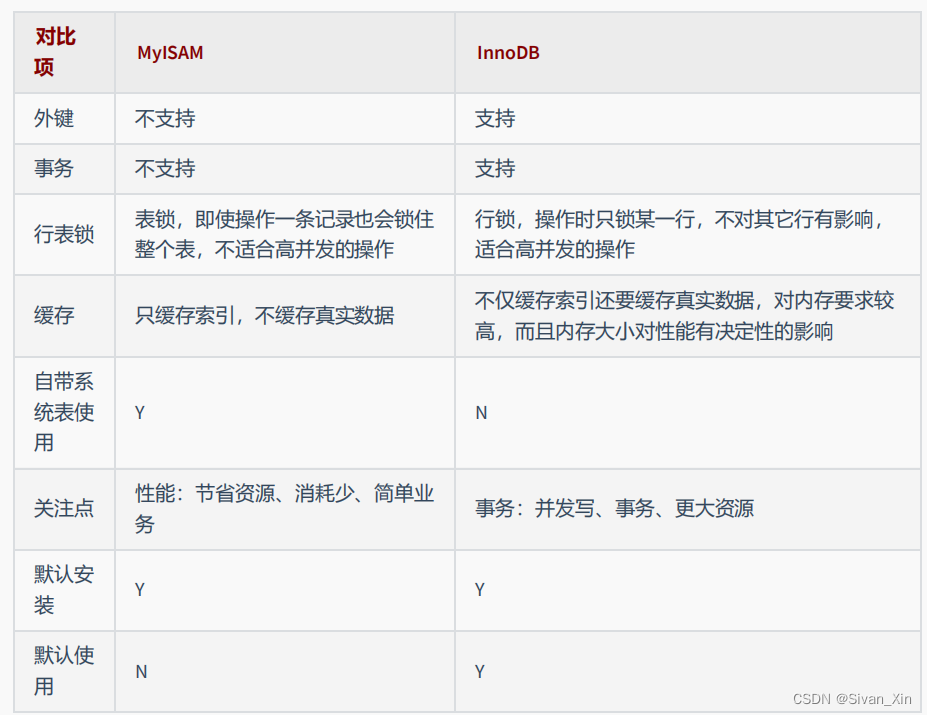
InnoDB引擎:在MySQL5.5版本之后默认使用。支持事务管理,可以确保事务的完整提交(commit)和回滚(rollback)。对比MyISAM,InnoDB写的处理效率差一些(保证事务完整性),不仅缓存索引,还缓存真实数据,对内存要求高。是处理海量数据量的最大性能设计。锁机制是行锁,操作时只锁一行,适合高并发的操作。支持外键。
-
MyISAM引擎:不支持事务、行锁、外键,并且崩溃后无法安全恢复。优点是访问快,对事务完整性没有要求或者以SELECT、INSERT为主(只读或以读为主)的应用可以使用。针对数据统计有额外的常数存储。故而 count(*) 的查询效率很高。
-
数据文件结构:InnoDB中,.frm存储表结构。(MySQL8.0合并到.ibd).ibd存储数据和索引。MyISAM中,表名.frm 存储表结构;表名.MYD 存储数据 (MYData);表名.MYI 存储索引 (MYIndex)
-
InnoDB和MyISAM对比
数据字典总体流程
前端页面定位url:“/dict/findZnodes”,到web-admin(消费端)中的DictController。
DictController调用方法:
@Reference
private DictService dictService;
@GetMapping(value = "findZnodes")
//将返回值转化为JSON
@ResponseBody
public Result findByParentId(@RequestParam(value = "id", defaultValue = "0") Long id) {
List<Map<String,Object>> zNodes = dictService.findZnodes(id);
return Result.ok(zNodes);
}
DictController中使用了dictService.findZnodes(id),在服务端service-house中,DictServiceImpl方法
@Autowired
private DictDao dictDao;
@Override
public List<Map<String,Object>> findZnodes(Long id) {
// 返回数据[{ id:2, isParent:true, name:"随意勾选 2"}]
//根据父节点id获取子节点数据
List<Dict> dictList = dictDao.findListByParentId(id);
//构建ztree数据
List<Map<String,Object>> zNodes = new ArrayList<>();
for(Dict dict : dictList) {
//判断该节点是否是父节点
Integer count = dictDao.countIsParent(dict.getId());
Map<String,Object> map = new HashMap<>();
//获取子节点数据列表
map.put("id", dict.getId());
map.put("isParent", count > 0 ? true : false);
map.put("name", dict.getName());
zNodes.add(map);
};
return zNodes;
}
DictServiceImpl中使用了DictDao接口,使用Mybatisde的语句映射,将DictMapper.xml与DictDao中的方法映射。