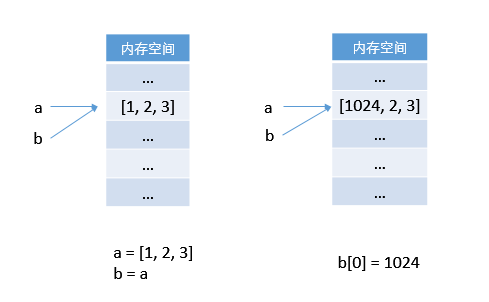
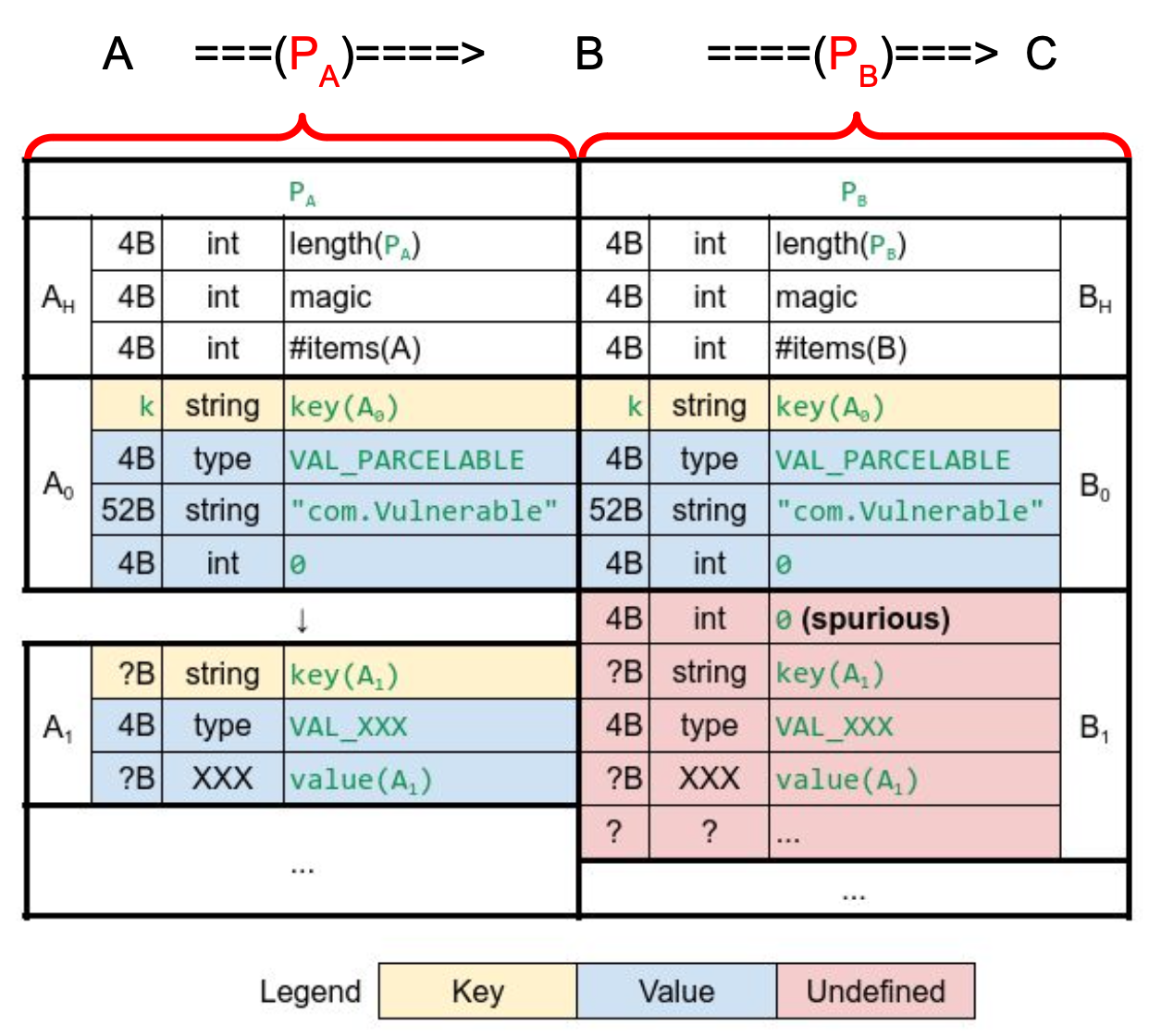
“与众不同”的TOP250详细数据采集,pyecharts世界地图多维可视化展示
前言:
本文描述爬取逗瓣250的电影详细信息,包括对电影名、评分、评论人数、电影名言、导演演员信息、电影年份、电影国家、电影类型等详细爬取;
并且针对爬取的数据使用Numpy、pandas等进行了数据处理、拆分、分组等操作,最后使用pyechatrs对数据进行柱状图、实时排序图、世界地图、饼图等可视化展示。
项目pyecharts可视化展示(部分)世界地图、实时排序图等:
1929至2013年每年发布的电影根据评分排序展示:

电影发布国家统计展示:

爬虫代码(.py文件):
import requests
from lxml import etree
import csv
import time
def get_source(com_url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
res = requests.get(com_url, headers=header)
html = res.content.decode('utf-8')
return html
# 解析数据
def get_data( html):
tree = etree.HTML(html)
divs = tree.xpath('//div[@class="info"]')
# print(divs)
lis_data = []
for div in divs:
# 标题
title = div.xpath('./div[@class="hd"]/a/span[@class="title"]/text()')[0].strip()###['龙猫'] 龙猫
# print(title)
#电源详情1
info1 = div.xpath('./div[@class="bd"]/p/text()[1]')[0].strip()
# print(info1)
#电影详情2
info2 = div.xpath('./div[@class="bd"]/p/text()[2]')[0].strip()
# print(info2)
# 评分
score = div.xpath('./div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0].strip()
# print(score)
# 评价人数
evaluate = div.xpath('./div[@class="bd"]/div[@class="star"]/span[4]/text()')[0].strip()
# print(evaluate)
# 引用
quote = div.xpath('./div[@class="bd"]/p[@class="quote"]/span/text()')
if quote:
quote = quote[0]
else:
quote = ''
lis_data.append([title, score, evaluate, quote, info1, info2, ]) ###[[],[],[],.....]
# print(lis_data)
with open('D:/爬取的内容/豆瓣TOP250/movie_data.csv', 'a+', encoding='utf-8-sig', newline='') as csvFile:
for rows in lis_data:
csv.writer(csvFile).writerow(rows)
with open('D:/爬取的内容/豆瓣TOP250/movie_data.csv', 'a+', encoding='utf-8-sig', newline='') as csvFile:
csv.writer(csvFile).writerow(['title', 'score', 'evaluate', 'quote', 'info1','info2'])
csvFile.close()
for i in range(10):
time.sleep(2)
page = (i) * 25
com_url = 'https://movie.douban.com/top250?start=' + str(page)
h = get_source(com_url)
print('第%d页保存完成' % i)
get_data(h)
数据处理可视化代码(.ipynb文件):
数据处理:
1、需要对评论人数,数值提取处理
2、对info1 进行分割提取,导演
3、对info2 进行分割 提取 电源年份 、 国家、 电源类型
import pandas as pd
df = pd.read_csv("movie_data.csv" , encoding = 'utf-8-sig')
df
df.columns=['电影名','评分','评论人数','名言','info1','info2']
df
pls = []
for v in df['评论人数']:
pls.append(int(v.split('人')[0]))
df['评论数'] =pls
df
dy =[]
for v in df['info1']:
sub1 = v.split('导演:')[1]
# print(sub1[1])
sub2= sub1.split(' ')[1]
# print(sub2)
dy.append(sub2)
len(dy)
df['导演'] = dy
df
time=[]
city=[]
jq=[]
import re
for s in df['info2']:
ls=s.split(' / ')
# print(ls)
sj = re.findall('\d+',ls[0])[0]
# print(sj)
time.append(sj)
city.append(ls[1])
jq.append(ls[2])
if len(ls)!=3:
print(ls)
print(s)
# 复杂情况:
# ['1961(中国大陆) / 1964(中国大陆) / 1978(中国大陆)', '中国大陆', '剧情 动画 奇幻 古装']
# ['1982(中国大陆)', '中国大陆', '剧情 历史']
# '美国 加拿大'
# '剧情 犯罪'
df['电影年份'] = time
df['国家']=city
df['电影类型'] = jq
df
数据处理结果:

pyecharts可视化:
1、评价数最多的电影TOP10

2、评分排名可视化

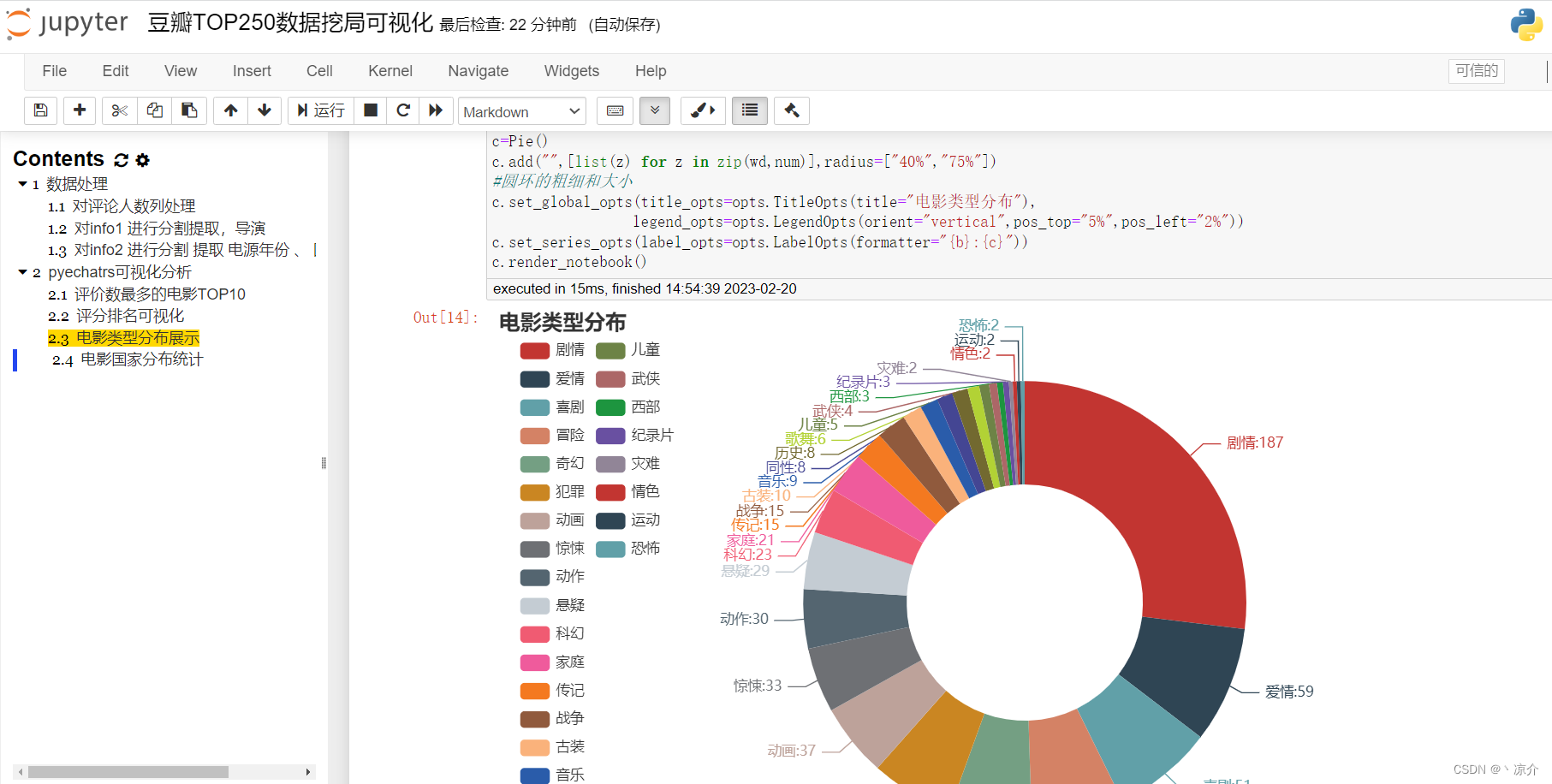
3、 电影类型分布展示

4、电影国家分布统计

源码获取:
网盘链接:
链接:https://pan.baidu.com/s/1F5J33FoX5iVKXLzPeg8z1A?pwd=xx78
提取码:xx78
(求求点个关注呀,您的关注点赞是我持续创作的动力。求求点个关注呀,您的关注点赞是我持续创作的动力。求求点个关注呀,您的关注点赞是我持续创作的动力)