文章目录
- 1.前言
- 2.准备工作
- 3.导出测试
- 3.1.单次查询、全量导出
- 3.2. 多次查询,多个文件,单次写入
- 3.3.多次查询,多个文件,多次写入
- 3.4.多线程导出探索
- 3.5.文件打包成ZIP
- 3.6.响应给客户
- 4.实现代码
- 5.结语
1.前言
最近接到一个需求,需要从服务器中导出大量数据到Excel中,数据量大概为50万行,50列,借助这个机会,就想对使用使用低内存导出大数据量的方案进行探索,总结出一个通用可行性方案,以方便日后随时可以使用,同时也分享一下探索的过程。
2.准备工作
技术栈选型
市面上常用的导出 Excel 的工具有 apache poi, jxls,Alibaba EasyExcel 等,在以往的使用经验以及查询的资料中显示,前面两者对于导出的优化不太好,在大数据量导出时容易OOM,Easy Excel 针对OOM问题做过优化,而且社区活跃,使用比较简单,此处选择EasyExcel。
附:《EasyExcel官方文档》
环境准备
- 客户端:工作使用笔记本电脑,CPU为 8核i5 低压,排除其他应用消耗后的可用内存约为4GB。
- 数据库:本地安装的 MySQL 数据库。
- 服务:新建SpringBoot服务,除需要验证的Excel功能以外,没有其他功能的消耗。
数据准备
在本地 MySQL 数据库中插入 50w 条数据备用。
探索目标
- 能否正常导出Excel文件
- 导出过程中的 CPU、内存等消耗情况
- 各操作步骤的耗时
- 导出的文件大小,文件能否正常操作
3.导出测试
对不同的导出方式进行验证,通过 Java visual VM 来观察导出过程中的CPU与内存使用情况,这里会使用到一个插件Visual GC,用来查看JVM的各分代信息,不太清楚这个插件的同学可以查看这篇文章《垃圾回收算法和垃圾收集器》中的第5点,里面有工作所在位置,以及插件的安装方法。
下面主要导出到本地硬盘(后面会补充响应给用户客户端的验证),展示的是导出过程中的性能相关指标,实现代码会放在后面的第4点中。
3.1.单次查询、全量导出
一次性将数据全部查询出来,放到内存中,再将所有的数据插入的Excel中。
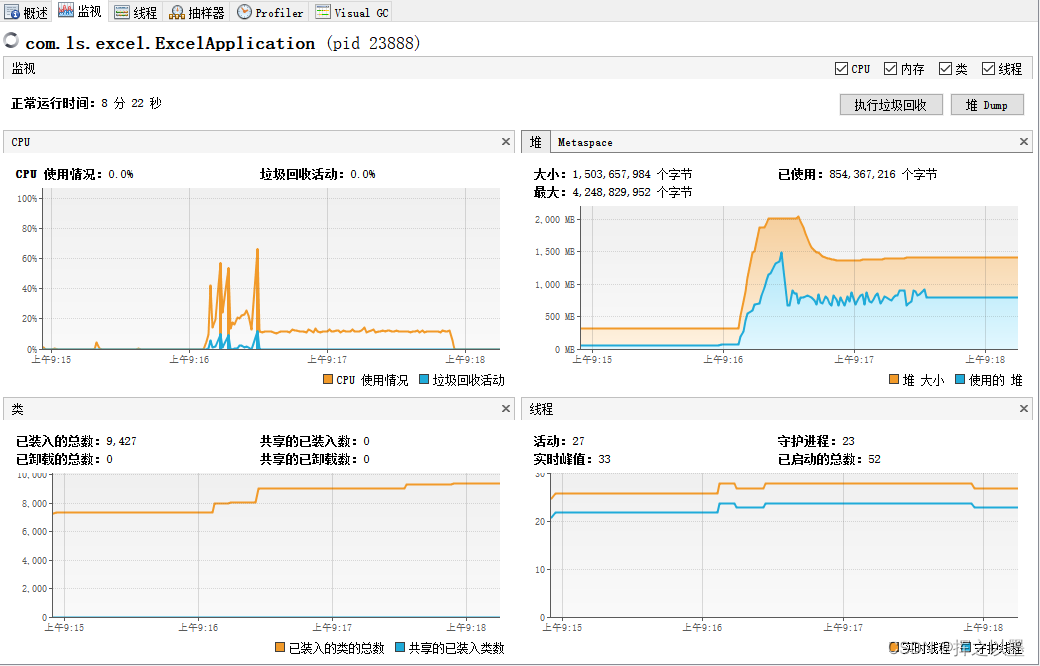
查询耗时:19710 ,约 20 s
导出耗时:87588 ,月 88 s
内存消耗:峰值约为 1.5 GB
CPU消耗:约有 20s 左右的高消耗,峰值约为 65%
文件大小:约 120 MB
通过我的工作电脑打开这个 Excel 文件,大于耗时1分钟,打开后基本上就卡死了,无法操作。
通过输出的性能指标来看,需要针对性的做以下几点优化:
- 减少CPU的消耗
- 减少内存的使用
- 缩小Excel文件的大小
首先,缩小Excel文件的大小可以考虑将文件进行拆分,例如:拆分为每个文件5w数据,生成10个文件,再将10个文件打包成zip进行下载。
其次,减少内存的使用,可以考虑将一次性查询 50w 的数据,修改为分批次查询,每次查询5w条数据,这样与上面的缩小文件大小不谋而合。生成了一个Excel之后,已经插入到Excel文件中的数据就不需要存在与内存中了,此时通过 GC 清理掉,就可以减少内存的消耗。
最后,减少CPU的消耗,目前阶段暂时还不清楚 CPU 的消耗主要是存在与何处,可以先做上面的两个优化,再观察一下效果。
3.2. 多次查询,多个文件,单次写入
由于我在准备数据阶段插入的数据是比较均匀的,所以理论上50w数据占用1.5GB,那么 5w 条数据占用的内存 就是 150MB,为了尽可能的模拟实际使用场景,此处将JVM的堆大小限制为:-Xms256m -Xmx256m ,再次执行导出,结果如下:
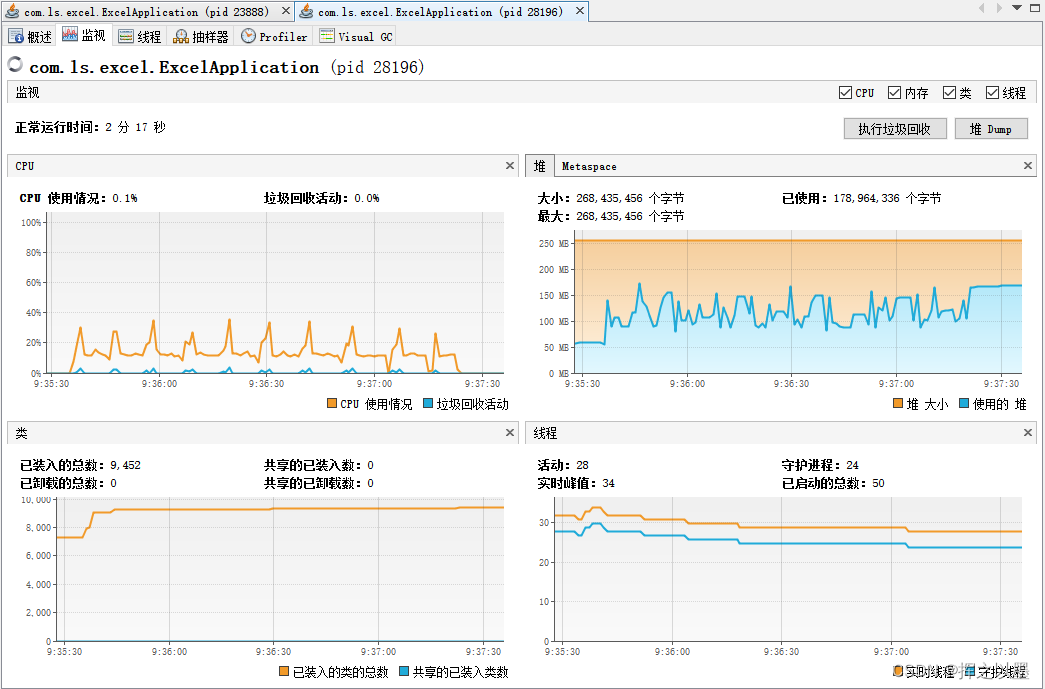
查询+导出耗时:耗时:106525 ,约 107s
内存消耗:峰值约为170 MB
CPU消耗:持续约 2.5 min,峰值约为 35%
优化效果明显,导出时间几乎没有变化,内存峰值下降了88%,CPU峰值下降了46%。
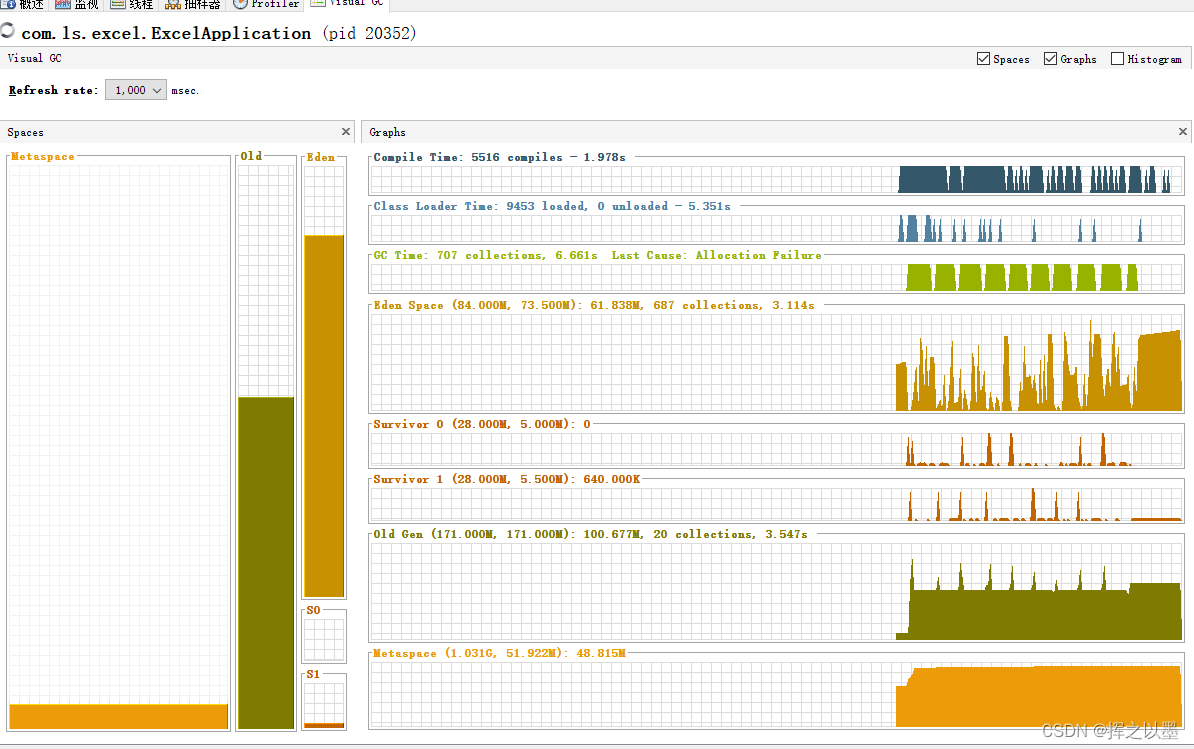
从CPU的角度来看,可以猜测生成Excel时,插入的数据量越小,则CPU的消耗就越小,带着这样的猜想,进一步进行验证。同时也可以注意一下上面第二张图中的老年代 Full GC 的次数,可以和下一个方案做一下对比。
3.3.多次查询,多个文件,多次写入
之所以有这么一个验证,主要是看到了 EasyExcel文档中有这么一个注释:

这里取一个极限值5000,将5w条数据再次拆分为10分,写入Excel的时候分10次写入,再看一下消耗情况。
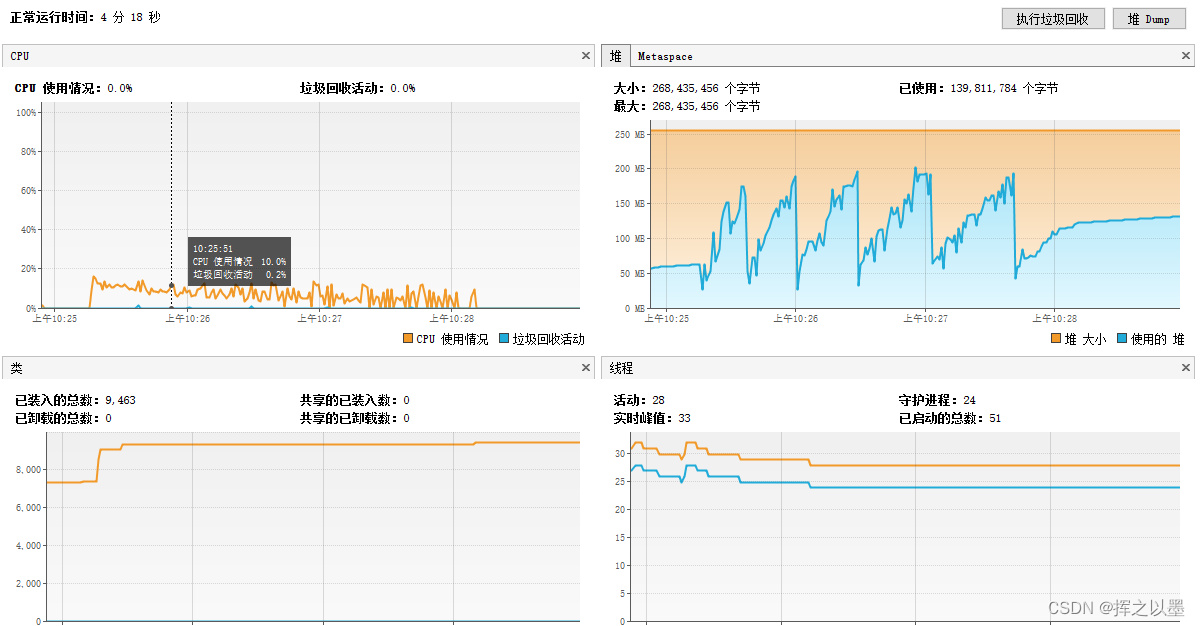
耗时:173848 ms 约 170s
内存消耗:峰值约为190 MB
CPU消耗:持续约 2.5 min,峰值约为 17%
先看 CPU ,CPU 的峰值进一步降低了50%,则我们先前的猜测是正确的。
内存的峰值上虽然多了20MB,但是最小值也也降低到了50MB左右,这里把两张图对比可以可以直观的感受到区别:
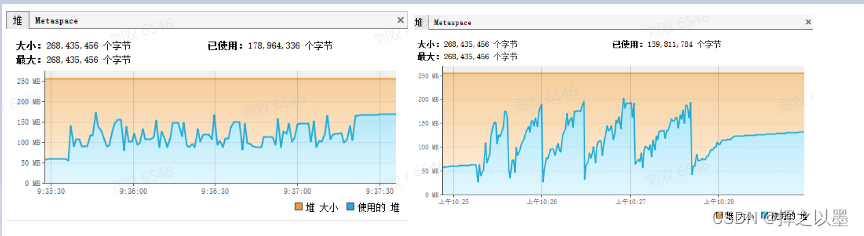
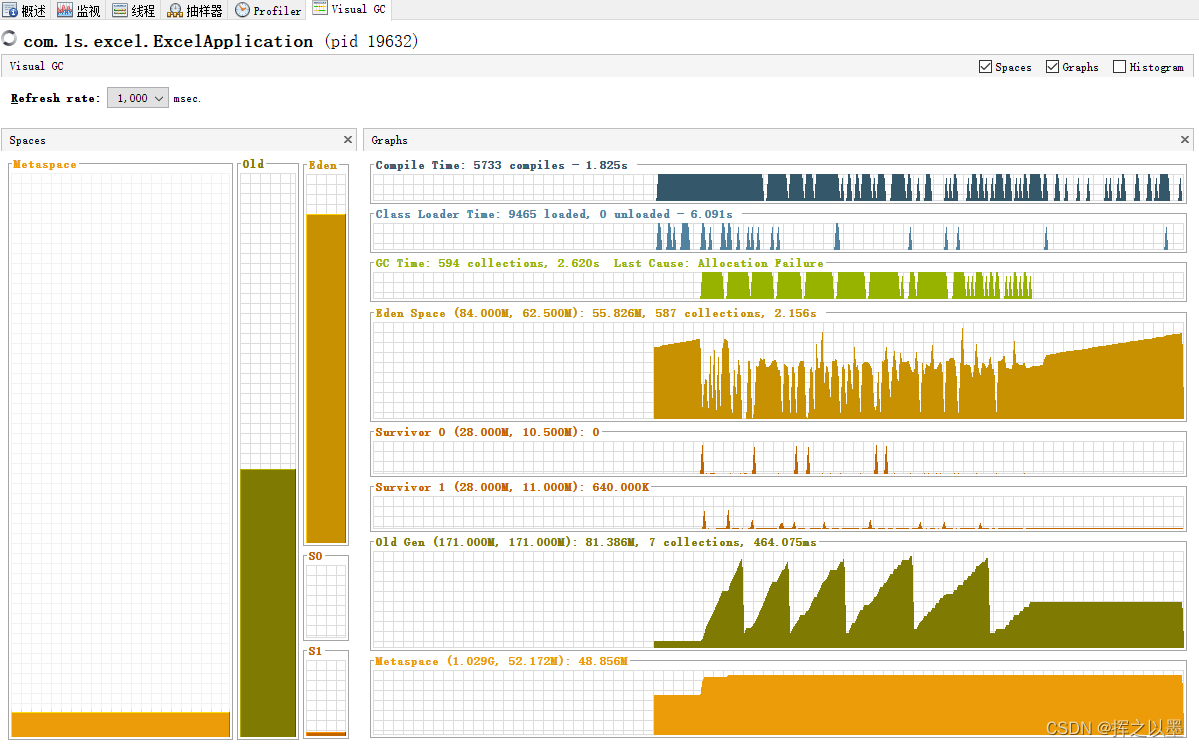
同时再对比一下visual GC中的两个图,Full GC的次数由20次缩小为7次,证明大部分的内存在新生代就已经回收了。
也就是说,当前这种方案是可以承受更低的堆内存限制的,之所以峰值还是会上去,是因为垃圾回收器自动回收垃圾时会有一个阈值,在没有超过这个阈值的时候,垃圾回收器也不会随意的回收内存,毕竟回收内存是会产生停顿时间的。
3.4.多线程导出探索
如果使用多线程并发生成10个文件,理论上速度会更快,但是由于同样的,数据会全部加载到内存中,对于内存的消耗也会大增,抱着不死心的态度,还是验证一下。
将代码修改为多线程之后,执行一下导出:
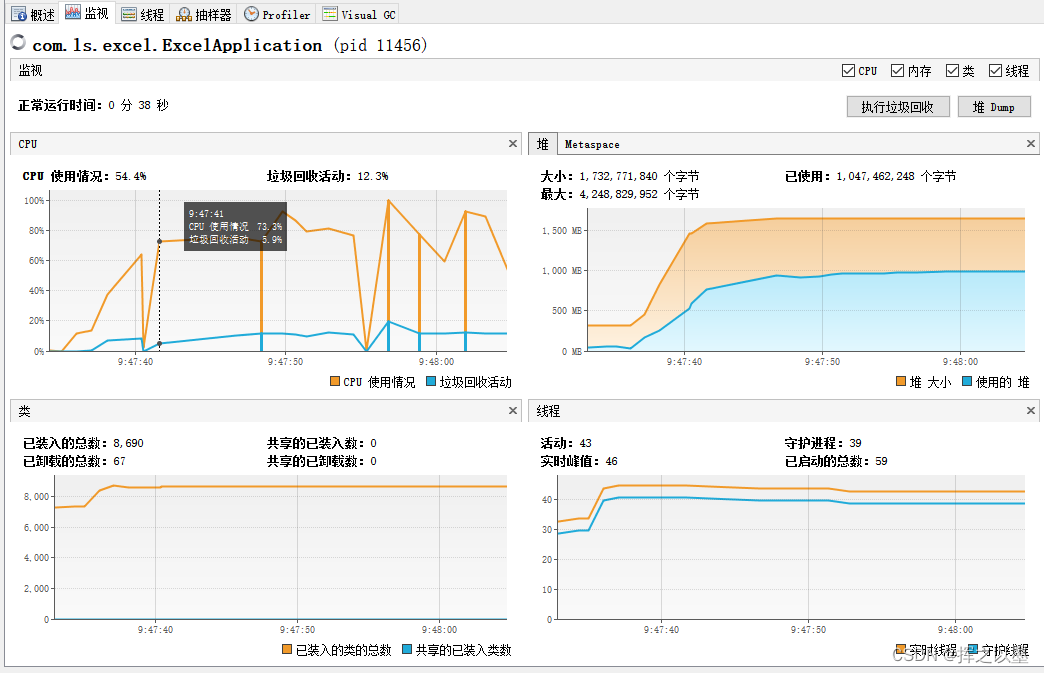
这次CPU的消耗简直不忍直视,我在截完图后,电脑就直接卡死了只能强制重启。不死心的我,换了另一台台式机进行测试,配置为 i79700 8核16线程,这次顺利导出了,耗时约为10s,但是即使是这种配置,CPU的峰值也飙升到了70%左右。
用性能来换时间是可以实现的,但是需求的硬件配置太高,现在服务器又那么贵,实现的时候需要评估功能收益与硬件成本,在业务要求的导出实时性不高的情况下,使用以空间换时间的方式更为合适。
3.5.文件打包成ZIP
响应给客户时,需要将多个文件打包成一个ZIP文件,不然用户就得下载10次,体验极差。
至于压缩方面,Excel本身对数据就已经做了压缩,再将其打包成zip的形式所带来的数据压缩率就很低了,所以几乎不考虑压缩的问题。
这里的打包主要是通过hutool包提供的压缩方式,文件服务器使用的是腾讯云的COS,先测试一下执行时间以及性能消耗。
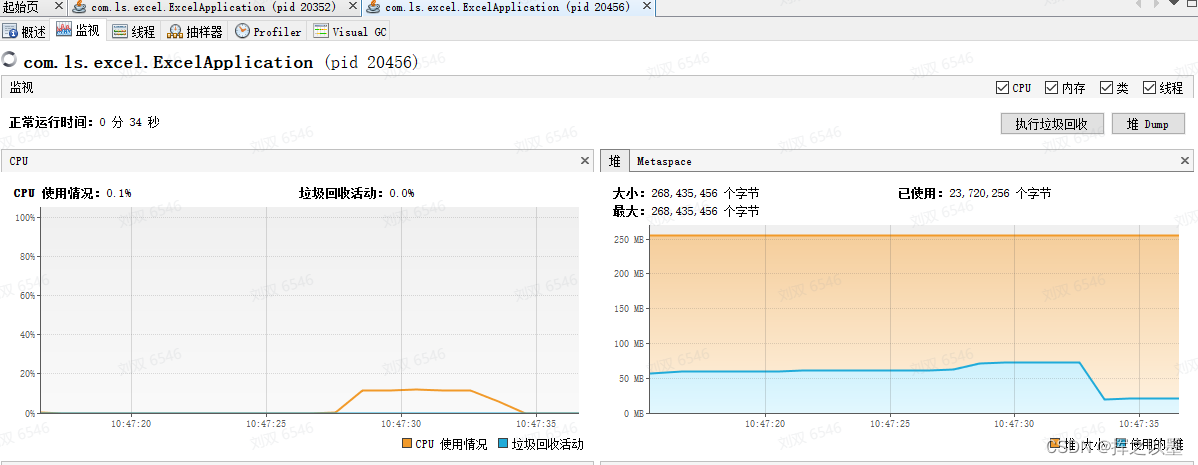
打包耗时:5459
内存和CPU几乎没有消耗
3.6.响应给客户
完成ZIP的打包之后,就需要将文件响应给客户了,有两种形式:
- 通过Response同步响应给用户
- 上传到文件系统,给用户返回一个下载地址
第一种方式,只能做成同步响应的,也就是说,用户在点击下载之后需要在当前页面等待3到5分钟,不能做其他的操作。
第二种方式,可以做成异步响应的,用户在点击下载之后,返回一个“提交成功,正在处理中”的提示,用户就可以做其他事情去了,待上传到文件系统成功之后将下载地址通知给用户即可。
通知的方式多种多样,可以用邮件通知、企业微信群通知、站内信通知,甚至可以做一个下载记录列表将下载地址存入到数据库中。
同时,对于多个用户同时下载的情况,也可以通过队列进行排队,一次只处理1个或两个(需要通过硬件来评估)导出请求。
4.实现代码
引入依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-core</artifactId>
<version>4.6.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.2</version>
</dependency>
我这里使用的ORM框架是mybatis-plus,可以换成任意自己喜欢的
单次查询,全量导出
public void export() {
long t1 = System.currentTimeMillis();
List<MemberInfo> memberInfos = memberInfoMapper.selectList(new QueryWrapper<>());
long t2 = System.currentTimeMillis();
String fileName = "d://excel/simpleWrite" + System.currentTimeMillis() + ".xlsx";
EasyExcel.write(fileName, MemberInfo.class)
.sheet("模板")
.doWrite(() -> memberInfos);
long t3 = System.currentTimeMillis();
System.out.println("查询耗时:" + (t2 - t1));
System.out.println("导出耗时:" + (t3 - t2));
}
多次查询,多个文件,单次写入
public void export2() {
long t1 = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
// 分页去数据库查询数据 这里可以去数据库查询每一页的数据
QueryWrapper<MemberInfo> queryWrapper = new QueryWrapper<>();
queryWrapper.last("limit " + i * 50000 + ",50000");
List<MemberInfo> memberInfos = memberInfoMapper.selectList(queryWrapper);
String fileName = "d://excel/simpleWrite" + "模板" + i + System.currentTimeMillis() + ".xlsx";
try (ExcelWriter excelWriter = EasyExcel.write(fileName, MemberInfo.class).build()) {
WriteSheet writeSheet = EasyExcel.writerSheet("模板").build();
excelWriter.write(memberInfos, writeSheet);
}
}
long t2 = System.currentTimeMillis();
System.out.println("耗时:" + (t2 - t1));
}
多次查询,多个文件,多次写入
public void export4() {
long t1 = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
String fileName = "d://excel/simpleWrite" + "模板" + i + System.currentTimeMillis() + ".xlsx";
try (ExcelWriter excelWriter = EasyExcel.write(fileName, MemberInfo.class).build()) {
WriteSheet writeSheet = EasyExcel.writerSheet("模板").build();
for (int j = 0; j < 10; j++) {
// 分页去数据库查询数据 这里可以去数据库查询每一页的数据
QueryWrapper<MemberInfo> queryWrapper = new QueryWrapper<>();
queryWrapper.last("limit " + (10 * i + j) * 5000 + ",5000");
List<MemberInfo> memberInfos = memberInfoMapper.selectList(queryWrapper);
excelWriter.write(memberInfos, writeSheet);
}
}
}
long t2 = System.currentTimeMillis();
System.out.println("耗时:" + (t2 - t1));
}
打包
public void pack() {
long t1 = System.currentTimeMillis();
ZipUtil.zip("d://excel", "d://zip/导出数据.zip");
long t2 = System.currentTimeMillis();
System.out.println("打包耗时:" + (t2 - t1));
}
多线程探索
public void export3() {
long t1 = System.currentTimeMillis();
CountDownLatch countDownLatch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
int finalI = i;
new Thread(() -> {
String fileName = "d://excel/simpleWrite" + "模板" + finalI + System.currentTimeMillis() + ".xlsx";
try (ExcelWriter excelWriter = EasyExcel.write(fileName, MemberInfo.class).build()) {
QueryWrapper<MemberInfo> queryWrapper = new QueryWrapper<>();
queryWrapper.last("limit " + finalI * 50000 + ",50000");
List<MemberInfo> memberInfos = memberInfoMapper.selectList(queryWrapper);
WriteSheet writeSheet = EasyExcel.writerSheet("模板").build();
excelWriter.write(memberInfos, writeSheet);
countDownLatch.countDown();
}
}).start();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
long t2 = System.currentTimeMillis();
System.out.println("耗时:" + (t2 - t1));
}
上传到文件服务器涉及到公司信息就不放在这里了,我这边使用的是腾讯云的COS,可以替换为你们自己公司所用的文件服务器。
5.结语
从几个方面总结一下低内存导出大数据量的Excel的方法:
- 降低存入到内存中的数据,使用分批次查询、分批次插入数据的方式。
- 尽可能的减少并发,避免使用多线程操作Excel,同时,还可以通过队列做异步和限流,排队处理导出请求。
- 考虑到Excel文件过大无法操作,可以将一个大文件拆分为多个小文件。
以上,是从Demo的角度验证了可行性,实际生产使用还需要考虑到文件的过期、文件的加密等,如果是发布到容器中还需要考虑文件路径无法找到等问题,但是与主题关系不大,这里就不做过多的讨论了,可以实际遇到问题再做分析和考虑。
如果觉得本文有帮助的话,可以帮忙点点赞哦!