1、什么是Kylin
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据。它能在亚秒内查询巨大的表。
2、谁在使用Kylin

3、工作原理
Apache Kylin 的工作原理就是对数据模型做 Cube 预计算,并利用计算的结果加速查询。过程如下:
1.指定数据模型,定义维度和度量。
2.预计算 Cube,计算所有 Cuboid 并将其保存为物化视图。
3.执行查询时,读取 Cuboid,进行加工运算产生查询结果。
由于 Kylin 的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算,并利用预计算的结果来执行查询,因此其速度相比非预计算的查询技术一般要快一个到两个数量级。并且在超大数据集上其优势更明显。当数据集达到千亿乃至万亿级别时,Kylin 的速度甚至可以超越其他非预计算技术 1000 倍以上。
4、技术架构
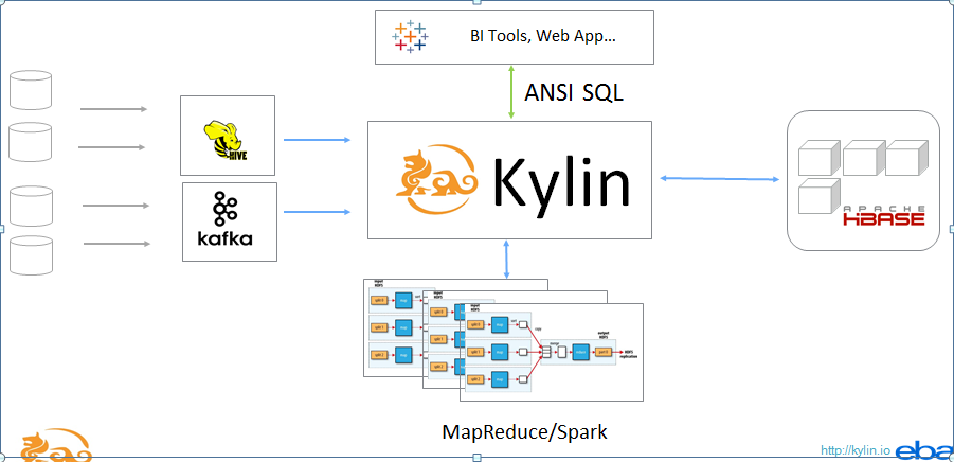
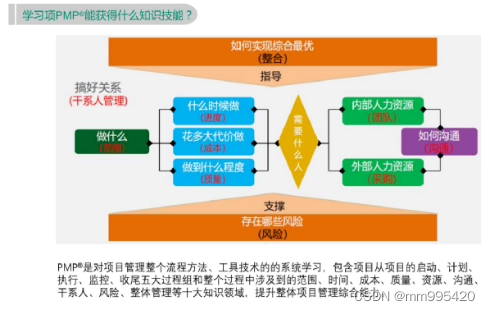
Apache Kylin 系统可以分为在线查询和离线构建两部分,其技术架构如图 1 所示。在线查询主要由上半区组成,离线构建在下半区。
先看离线构建的部分。从图 1 中可以看到,数据源在左侧,目前主要是 Hadoop、Hive、Kafka 和 RDBMS,其中保存着待分析的用户数据。根据元数据定义,下方构建引擎从数据源中抽取数据,并构建 Cube。数据以关系表的形式输入,且必须符合星形模型(Star Schema)或雪花模型(Snowflake Schema)。用户可以选择使用 MapReduce 或 Spark 进行构建。构建后的 Cube 保存在右侧的存储引擎中,目前 HBase 是默认的存储引擎。
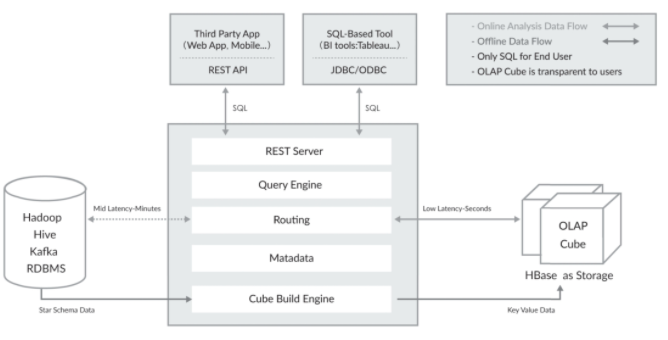
完成离线构建后,用户可以从上方查询系统发送 SQL 来进行查询分析。Kylin 提供了多样的 REST API、JDBC/ODBC 接口。无论从哪个接口进入,最终 SQL 都会来到 REST 服务层,再转交给查询引擎进行处理。这里需要注意的是,SQL 语句是基于数据源的关系模型书写的,而不是 Cube。Kylin 在设计时刻意对查询用户屏蔽了 Cube 的概念,分析师只需要理解简单的关系模型就可以使用 Kylin,没有额外的学习门槛,传统的 SQL 应用也更容易迁移。查询引擎解析 SQL,生成基于关系表的逻辑执行计划,然后将其转译为基于 Cube 的物理执行计划,最后查询预计算生成的 Cube 产生结果。整个过程不访问原始数据源。
5、核心概念
数据仓库(Data Warehouse)是一种信息系统的资料储存理论,此理论强调的是利用某些特殊资料储存方式,让所包含的资料特别有利于分析处理,从而产生有价值的资讯并依此做决策。
OLAP(Online Analytical Process),即联机分析处理,它可以以多维度的方式分析数据,并且能弹性地提供上卷(Roll-up)、下钻(Drill-down)和透视分析(Pivot)等操作,是呈现集成性决策信息的方法,其主要功能在于方便大规模数据分析及统计计算,多用于决策支持系统、商务智能或数据仓库。与之相区别的是联机交易处理(OLTP),联机交易处理侧重于基本的、日常的事务处理,包括数据的增、删、改、查。
OLAP 需要以大量历史数据为基础,配合时间点的差异并对多维度及汇整型的信息进行复杂的分析。
OLAP 需要用户有主观的信息需求定义,因此系统效率较高。
BI(Business Intelligence),即商务智能,是指用现代数据仓库技术、在线分析技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。
维度建模
维度建模用于决策制定,并侧重于业务如何表示和理解数据。基本的维度模型由维度和度量两类对象组成。维度建模尝试以逻辑、可理解的方式呈现数据,以使得数据的访问更加直观。维度设计的重点是简化数据和加快查询。
维度模型是数据仓库的核心。它经过精心设计和优化,可以为数据分析和商业智能(BI),检索并汇总大量的相关数据。在数据仓库中,数据修改仅定期发生,并且是一次性开销,而读取是经常发生的。对于一个数据检索效率比数据处理效率重要得多的数据结构而言,非标准化的维度模型是一个不错的解决方案。
在数据挖掘中有几种常见的多维数据模型,如星形模型(Star Schema)、雪花模型(Snowflake Schema)、事实星座模型(Fact Constellation)等。
事实表和维度表
事实表(Fact Table)是指存储事实记录的表,如系统日志、销售记录等,并且是维度模型中的主表,代表着键和度量的集合。事实表的记录会不断地动态增长,所以它的体积通常远大于其他表,通常事实表占据数据仓库中 90%或更多的空间。
维度表(Dimension Table),也称维表或查找表(Lookup Table),是与事实表相对应的一种表。维度表的目的是将业务含义和上下文添加到数据仓库中的事实表和度量中。维度表是事实表的入口点,维度表实现了数据仓库的业务接口。它们基本上是事实表中的键引用的查找表。它保存了维度的属性值,可以与事实表做关联,相当于将事实表上经常出现的属性抽取、规范出来用一张表进行管理,常见的维度表有:日期表(存储日期对应的 周、月、季度等属性)、地点表(包含国家、省/州、城市等属性)等。使用维度表的好处如下:
减小了事实表的大小;
便于维度的管理和维护,增加、删除和修改维度的属性时,不必对事实表的大量记录进行改动;
维度表可以为多个事实表同时使用,减少重复工作。
维度和度量
维度是人们观察数据的特定角度,是考虑问题时的一类属性。它通常是数据记录的一个特征,如时间、地点等。同时,维度具有层级概念,可能存在细节程度不同的描述方面,如日期、月份、季度、年等。
可以在数学上求和的事实属性称为度量。例如,可以对度量进行总计、平均、以百分比形式使用等。度量是维度模型的核心。通常,在单个查询中检索数千个或数百万个事实行,其中对结果集执行数学方程。
Cube、Cuboid、Cube Segment
Cube(或称 Data Cube),即数据立方体,是一种常用于数据分析与索引的技术,它可以对原始数据建立多维度索引,大大加快数据的查询效率。
Cuboid 特指 Apache Kylin 中在某一种维度组合下所计算的数据。
Cube Segment 指针对源数据中的某一片段计算出来的 Cube 数据。通常,数据仓库中的数据数量会随时间的增长而增长,而 Cube Segment 也是按时间顺序构建的。