实验架构
TCP实施中模块和数据流的排列 :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pmRfy6Va-1676857163260)(null)]
字节流是Lab0。TCP的工作是通过不可靠的数据报网络传输两个字节流(每个方向一个),以便写入连接一侧套接字的字节显示为可在对等端读取的字节,反之亦然。Lab1是StreamReAssemer,在Lab2、3和4中,您将实施TCPReceiver、TCPSender,然后实施 TCPConnection 将它们连接在一起。
-
在Lab1中,您将实现一个流重组器-该模块将字节流的一小部分(称为子串或段)按正确的顺序缝合回连续的字节流。
-
在Lab2中,您将实现TCP中处理入站字节流的部分:
TCPReceiver。这涉及到考虑TCP将如何表示流中每个字节的位置-称为“序列号”。TCPReceiver负责告诉发送者(A)它已经能够成功组装多少入站字节流(这称为“确认”)和(B)发送者现在被允许发送多少字节(“flow控制”)。(B)TCPReceiver负责告诉发送者(A)它已经能够成功组装多少入站字节流(这称为“确认”)和(B)允许发送者现在发送多少字节(“flow control”)。 -
在Lab3中,您将实现TCP中处理出站字节流的部分:
TCPSender。当发送方怀疑其传输的数据段在途中丢失并且从未到达接收方时,它应该如何反应?它应该在什么时候重试并重新传输丢失的数据段? -
在Lab4中,您将结合前面的工作和Lab来创建工作的TCP实现:包含
TCPSender和TCPReceiver的TCPConnection。您将使用它与世界各地的真实服务器进行对话。
您的Push Substring方法将忽略会导致 StreamReAssembly 超出其“容量”的字符串的任何部分:内存使用限制,即允许它存储的最大字节数。这可以防止重新组装器使用无限量的内存,无论TCP发送器决定执行什么操作。我们已经在下面的图片中对此进行了说明。“容量”是两者的上限:
-
重组的
ByteStream中的字节数(如下绿色所示),以及 -
“
unassembled”的子字符串可以使用的最大字节数(以红色显示)
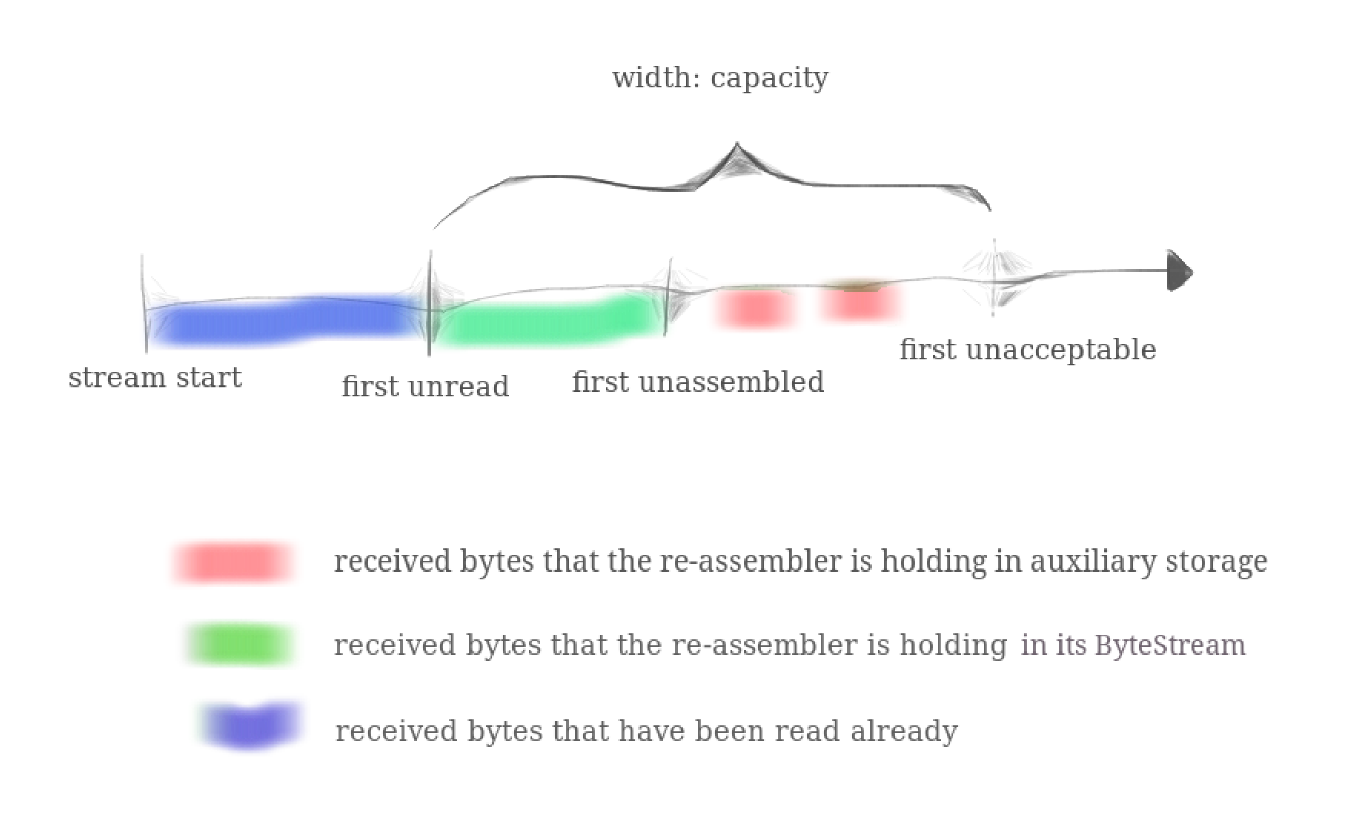
- 红色:
re-assembler保存在辅助存储器中的已接收字节 - 绿色:
re-assembler保存在字节流中的已接收字节数 - 蓝色:已读取的已接收字节数
说明
- 整个数据流中第一个字节的索引是什么?
- 0。
- 我的实现应该有多大的效率?
- 我们还不打算指定一个效率的概念,但请不要建立一个严重影响空间或时间的数据结构——这个数据结构将是你的TCP实现的基础。
- 应该如何处理不一致的子串?
- 你可以假设它们不存在。也就是说,你可以假设有一个唯一的底层字节流,而所有的子串都是它的(精确)片段。
- 我可以使用什么?
- 你可以使用你认为有用的标准库的任何部分。特别是,我们希望你至少要使用一个数据结构。
- 字节什么时候应该被写入流中?
- 越快越好。一个字节不应该出现在流中的唯一情况是,在它之前有一个字节还没有被”push”。
- 子串可能重叠吗?
- 可能。
- 我是否需要向StreamReassembler添加私有成员?
- 是的。由于段可能以任何顺序到达,你的数据结构将不得不记住子串,直到它们准备好被放入流中,也就是说,直到它们之前的所有索引都已填充。
实现思路
1. 要求
在我们所实现的 StreamReassembler 中,有以下几种特性:
- 接收子字符串。这些子字符串中包含了一串字节,以及该字符串在总的数据流中的第一个字节的索引。
- 流的每个字节都有自己唯一的索引,从零开始向上计数。
StreamReassembler中存在一个 ByteStream 用于输出,当StreamReassembler知道了流的下一个字节,它就会将其写入至ByteStream中。
需要注意的是,传入的子串中:
-
子串之间可能相互重复,存在重叠部分
但假设重叠部分数据完全重复。
不存在某些 index 下的数据在某个子串中是一种数据,在另一个子串里又是另一种数据。
重叠部分的处理最为麻烦。
-
可能会传一些已经被装配了的数据
-
如果 ByteStream 已满,则必须暂停装配,将未装配数据暂时保存起来
除了上面的要求以外,容量 Capacity 需要严格限制:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-34kDAJL2-1676857165397)(null)]
为了便于说明,将图中的绿色区域称为 ByteStream,将图中**存放红色区域的内存范围(即 first unassembled - first unacceptable)**称为 Unassembled_strs。
CS144 要求将 ByteStream + Unassembled_strs 的内存占用总和限制在 Reassember 中构造函数传入的 capacity 大小。因此我们在构造 Reassembler 时,需要既将传入的 capacity 参数设置为 ByteStream的缓冲区大小上限,也将其设置为first unassembled - first unacceptable的范围大小,以避免极端情况下的内存使用。
注意:first unassembled - first unacceptable的范围大小,并不等同于存放尚未装配子串的结构体内存大小上限,别混淆了。
Capacity 这个概念很重要,因为它不仅用于限制高内存占用,而且它还会起到流量控制的作用(见 lab2)。
本节实验需要安装 pcap 库和 pcap-dev 库才能正常编译
sudo apt-get install libpcap-dev
在新的 Segment 到来的时候,如果他能和已储存的包 “合并” 的话,我们可以不更改已储存的包,而是把这个新包修剪一下,利用 BufferPlus 修剪前后缀的两个函数去掉它的重复的部分
class StreamBlock {
private:
BufferPlus _buffer{};
size_t _begin_index;
public:
StreamBlock(const int begin, std::string &&str) noexcept
: _buffer(std::move(str)), _begin_index(begin) {};
StreamBlock(const StreamBlock &Other) noexcept
: _buffer(Other._buffer), _begin_index(Other._begin_index) {};
StreamBlock(const int begin, const Buffer &data) noexcept
: _buffer(data), _begin_index(begin) {};
bool operator<(const StreamBlock sb) const { return begin() < sb.begin(); }
inline size_t end() const { return _begin_index + _buffer.starting_offset() + _buffer.size(); }
inline size_t len() const { return _buffer.size(); }
inline size_t begin() const { return _begin_index + _buffer.starting_offset(); }
BufferPlus &buffer() { return _buffer; }
const BufferPlus &buffer() const { return _buffer; }
};
定义一个名为 StreamBlock。
它包含了一个私有成员 _buffer,类型为 BufferPlus,另一个私有成员 _begin_index,类型为 size_t。类的定义中包含了三个构造函数:
- 第一个构造函数接受两个参数:一个整数
begin和一个右值引用类型的std::string对象str。它使用std::move将str移动到_buffer成员中,并将_begin_index初始化为begin。 - 第二个构造函数接受一个参数:另一个
StreamBlock类型的对象Other。它将Other的_buffer和_begin_index成员的值分别赋值给当前对象的_buffer和_begin_index成员。 - 第三个构造函数接受两个参数:一个整数
begin和一个Buffer类型的对象data。它将data的值复制到_buffer成员中,并将_begin_index初始化为begin。
该类还包含了四个公共成员函数:
- 一个重载了小于号
<的运算符,用于比较两个StreamBlock对象的起始位置,返回值为布尔类型。 - 一个返回
StreamBlock对象的结束位置的函数end(),返回值为size_t类型。 - 一个返回
StreamBlock对象的长度的函数len(),返回值为size_t类型。 - 一个返回
StreamBlock对象的起始位置的函数begin(),返回值为size_t类型。
最后,类中还有两个 BufferPlus 类型的成员函数 buffer() 和 buffer() const,用于返回 _buffer 成员。前一个是非 const 成员函数,可以修改 _buffer 成员的值,后一个是 const 成员函数,不允许修改 _buffer 成员的值。
//! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order,
//! possibly overlapping) into an in-order byte stream.
class StreamReassembler {
private:
// Your code here -- add private members as necessary.
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
size_t _first_uass; // index of segment waiting for
size_t _unassembled_bytes;
bool _eof; // whether _eof_ is effecitve
size_t _eof_idx; // where the eof is
std::set<StreamBlock> _blocks;
//! Merge the two blocks "blk" and "new_block"
//! the result will stored in new_block
//! nothing happens if two blocks can't merge
//! return ture if merge happens, false otherwise
//! add "to_add" blocks to set blocks
//! merge all the blocks mergeable
inline void add_block(StreamBlock &new_block);
bool overlap(const StreamBlock &blk, const StreamBlock &new_blk) const;
//! Write the first block to the stream, this block should begin at '_first_uass'
inline void write_to_stream();
//! Check if eof is written to the stream
//! If true, end the stream
inline void EOFcheck();
public:
//! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.
//! \note This capacity limits both the bytes that have been reassembled,
//! and those that have not yet been reassembled.
StreamReassembler(const size_t capacity);
//! \brief Receive a substring and write any newly contiguous bytes into the stream.
//!
//! The StreamReassembler will stay within the memory limits of the `capacity`.
//! Bytes that would exceed the capacity are silently discarded.
//!
//! \param data the substring
//! \param index indicates the index (place in sequence) of the first byte in `data`
//! \param eof the last byte of `data` will be the last byte in the entire stream
void push_substring(const std::string &data, const uint64_t index, const bool eof);
void push_substring(const Buffer &data, const size_t index, const bool eof);
//! \name Access the reassembled byte stream
//!@{
const ByteStream &stream_out() const { return _output; }
ByteStream &stream_out() { return _output; }
//!@}
uint64_t first_unassembled() const;
//! The number of bytes in the substrings stored but not yet reassembled
//!
//! \note If the byte at a particular index has been pushed more than once, it
//! should only be counted once for the purpose of this function.
size_t unassembled_bytes() const;
//! \brief Is the internal state empty (other than the output stream)?
//! \returns `true` if no substrings are waiting to be assembled
bool empty() const;
};
StreamReassembler 的类,用于将一个字节流中的多个子字符串(可能无序、可能重叠)重新组装成有序的字节流。类中包含了一些私有成员和公有成员。
类的私有成员包括:
ByteStream _output:存储重新组装后的有序字节流。size_t _capacity:StreamReassembler可以存储的最大字节数。size_t _first_uass:未组装的第一个字节在原始字节流中的索引。size_t _unassembled_bytes:已接收但未组装的字节数。bool _eof:标记是否已经收到 EOF(文件结束)。size_t _eof_idx:EOF 在原始字节流中的索引。std::set<StreamBlock> _blocks:存储已接收但未组装的数据块。
类的公有成员包括:
StreamReassembler(const size_t capacity):构造函数,创建一个StreamReassembler实例,设置它的最大容量为capacity。void push_substring(const std::string &data, const uint64_t index, const bool eof):将子字符串data添加到StreamReassembler中,并将任何新接收到的连续字节写入到_output中。index表示data中第一个字节在原始字节流中的索引,eof表示data是否包含文件结束符。const ByteStream &stream_out() const和ByteStream &stream_out():获取_output中存储的有序字节流。uint64_t first_unassembled() const:获取未组装的第一个字节在原始字节流中的索引。size_t unassembled_bytes() const:获取已接收但未组装的字节数。bool empty() const:判断StreamReassembler是否为空,即判断是否有待组装的子字符串。
//! \details This function check if eof is written to the stream
inline void StreamReassembler::EOFcheck() {
if (!_eof) {
return;
}
if (static_cast<size_t>(_eof_idx) == _first_uass) {
_output.end_input();
}
}
这是 StreamReassembler 类的成员函数,用于检查文件结束标记是否已写入输出流。该函数首先检查 _eof 是否为 true ,这意味着文件结束标记已写入流。如果 _eof 不为 true,函数立即返回,不做任何操作。
如果 _eof 为 true,该函数将检查流中文件结束标记的索引 _eof_idx 是否等于 _first_uass。 _first_uass 是流中第一个未使用的字节的索引,这意味着在 _first_uass 之前的所有字节都已被输出流使用。如果 _eof_idx 等于 _first_uass,这意味着流中的所有字节,包括文件结束标记,都已被输出流占用。在这种情况下,函数调用 _output 对象的 end_input() 函数,这表明流中没有更多的输入。
//! \details This function write the first block into the stream,
//! the first block should begin at '_first_uass'
inline void StreamReassembler::write_to_stream() {
while (!_blocks.empty()) {
auto block = *_blocks.begin();
if (block.begin() != _first_uass) {
return;
}
size_t bytes_written = _output.write(block.buffer());
if (bytes_written == 0) {
return;
}
_first_uass += bytes_written;
_unassembled_bytes -= bytes_written;
_blocks.erase(move(_blocks.begin()));
// partially written
if (bytes_written != block.len()) {
block.buffer().remove_prefix(move(bytes_written));
_blocks.insert(move(block));
}
}
}
write_to_stream,作用是将数据块写入流中。根据代码中的注释,这个函数写入的是第一个块,即起始位置为 _first_uass 的块。
这个函数首先进入一个 while 循环,只要数据块队列 _blocks 不为空,就会一直循环。然后,它取出 _blocks 队列中的第一个块,如果这个块的起始位置不等于 _first_uass,说明还没有到该块,就直接返回。
如果该块的起始位置等于 _first_uass,则将该块写入流中,并记录已写入的字节数,更新 _first_uass,减少 _unassembled_bytes 的值(表示还未组装的字节数),然后将该块从队列中删除。
如果该块只写入了部分数据,即字节数小于该块的长度,就将该块的缓冲区前缀截去已写入的字节数,并将该块重新插入到队列中。然后,这个函数就继续处理下一个数据块,直到队列为空或者写入的字节数为 0。
//! \details This function add "to_add" blocks to set blocks
// merge all the blocks mergeable
inline void StreamReassembler::add_block(StreamBlock &new_block) {
if (new_block.len() == 0) {
return;
}
vector<StreamBlock> blks_to_add;
blks_to_add.emplace_back(move(new_block));
if (!_blocks.empty()) {
auto nblk = blks_to_add.begin();
auto iter = _blocks.lower_bound(*nblk);
auto prev = iter;
while (iter != _blocks.end() && overlap(*iter, *nblk)) {
if ((*iter).end() >= (*nblk).end()) {
(*nblk).buffer().remove_suffix((*nblk).end() - (*iter).begin());
break;
}
StreamBlock last(*nblk);
(*nblk).buffer().remove_suffix((*nblk).end() - (*iter).begin());
last.buffer().remove_prefix((*iter).end() - (*nblk).begin());
blks_to_add.push_back(move(last));
nblk = blks_to_add.end();
nblk -- ;
iter ++ ;
}
// compare with prevs
// check one previous block is enough
if (prev != _blocks.begin()) {
prev -- ;
nblk = blks_to_add.begin();
if (overlap(*nblk, *prev)) {
(*nblk).buffer().remove_prefix((*prev).end() - (*nblk).begin());
}
}
}
for (auto &blk : blks_to_add) {
if (blk.len() != 0) {
_blocks.emplace(move(blk));
_unassembled_bytes += blk.len();
}
}
}
这段代码是 StreamReassembler 类中的 add_block 函数,用于向一个缓存区 _blocks 中添加新的数据块。这些数据块需要和缓存区中的已有数据块合并,如果新数据块和已有数据块可以合并成一个连续的数据块,则合并它们。如果新数据块和已有数据块不能合并,就将新数据块插入到缓存区 _blocks 中。
具体实现过程如下:
- 如果新数据块的长度为 0,直接返回。
- 如果缓存区
_blocks不为空,则从头开始遍历它,如果有数据块和新数据块可以合并,就将它们合并成一个数据块。如果遍历到一个数据块和新数据块不能合并,就停止遍历。 - 如果新数据块可以和一个已有数据块合并,就将新数据块和该数据块合并。
- 如果新数据块和已有数据块不能合并,就插入新数据块到缓存区
_blocks中。
//! \details This function check if the two blocks have overlap part
bool StreamReassembler::overlap(const StreamBlock &blk, const StreamBlock &new_blk) const {
if (blk.begin() < new_blk.begin()) {
return new_blk.begin() < blk.end();
}
return blk.begin() < new_blk.end();
}
这个函数用于判断两个数据块 (StreamBlock)是否有重叠的部分。重叠的部分指的是两个数据块在数据流中存在相同的字节范围。函数接收两个参数,blk 和 new_blk,分别代表已有的数据块和待添加的新数据块。如果这两个数据块有重叠的部分,则返回 true,否则返回 false。
具体实现中,首先比较 blk 的起始位置和 new_blk 的起始位置,如果 blk 的起始位置在 new_blk 的起始位置之前,那么只需比较 new_blk 的起始位置是否在 blk 的结束位置之前;否则,只需比较 blk 的起始位置是否在 new_blk 的结束位置之前。如果满足这两个条件之一,则说明这两个数据块存在重叠部分,返回 true;否则返回 false。
//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
// the data that have been reassembled
if (index + data.size() < _first_uass) {
return;
}
if (eof && !_eof) {
_eof = true;
_eof_idx = index + data.size();
}
StreamBlock blk(index, move(string(data)));
// if a part of the data have been reassembled
if (index < _first_uass) {
blk.buffer().remove_prefix(_first_uass - index);
}
// if a part of the data out of the capacity
if (index + data.size() > _capacity + _first_uass) {
blk.buffer().remove_suffix(index + data.size() - _capacity - _first_uass);
}
add_block(blk);
write_to_stream();
EOFcheck();
}
这段代码是一个函数,用于处理来自逻辑流的子字符串(即段)数据,该数据可能是乱序的,然后组装任何新的连续的子字符串并按顺序将其写入输出流。该函数的实现分为三个步骤:
- 首先检查输入的数据是否已经在已组装的数据范围内,如果已经在范围内,则直接返回,不做处理。
- 如果输入数据已经包含
EOF标记,将标记设置为true,记录标记的位置,以便后续处理。 - 根据输入数据的索引和内容创建一个
StreamBlock对象。如果输入数据的索引小于已组装数据的范围,将数据前面的部分丢弃;如果输入数据的索引加上数据长度超出了容量,将数据后面的部分丢弃。然后将新的StreamBlock添加到已有的StreamBlock集合中,并检查是否有连续的StreamBlock,将它们合并成一个更大的StreamBlock。接着将可写入的数据写入到输出流中,并检查是否已经写入了EOF标记。
总之,这个函数的作用是将输入数据组装成完整的数据块,然后将这些数据块按顺序写入到输出流中,同时处理 EOF 标记。
完整代码
- stream_reassembler.hh
- stream_reassembler.cc
“stream_reassembler.hh”
#ifndef SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
#define SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
#include "byte_stream.hh"
#include "buffer.hh"
#include <cstdint>
#include <string>
#include <set>
class StreamBlock {
private:
BufferPlus _buffer{};
size_t _begin_index;
public:
StreamBlock(const int begin, std::string &&str) noexcept
: _buffer(std::move(str)), _begin_index(begin) {};
StreamBlock(const StreamBlock &Other) noexcept
: _buffer(Other._buffer), _begin_index(Other._begin_index) {};
StreamBlock(const int begin, const Buffer &data) noexcept
: _buffer(data), _begin_index(begin) {};
bool operator<(const StreamBlock sb) const { return begin() < sb.begin(); }
inline size_t end() const { return _begin_index + _buffer.starting_offset() + _buffer.size(); }
inline size_t len() const { return _buffer.size(); }
inline size_t begin() const { return _begin_index + _buffer.starting_offset(); }
BufferPlus &buffer() { return _buffer; }
const BufferPlus &buffer() const { return _buffer; }
};
//! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order,
//! possibly overlapping) into an in-order byte stream.
class StreamReassembler {
private:
// Your code here -- add private members as necessary.
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
size_t _first_uass; // index of segment waiting for
size_t _unassembled_bytes;
bool _eof; // whether _eof_ is effecitve
size_t _eof_idx; // where the eof is
std::set<StreamBlock> _blocks;
//! Merge the two blocks "blk" and "new_block"
//! the result will stored in new_block
//! nothing happens if two blocks can't merge
//! return ture if merge happens, false otherwise
//! add "to_add" blocks to set blocks
//! merge all the blocks mergeable
inline void add_block(StreamBlock &new_block);
bool overlap(const StreamBlock &blk, const StreamBlock &new_blk) const;
//! Write the first block to the stream, this block should begin at '_first_uass'
inline void write_to_stream();
//! Check if eof is written to the stream
//! If true, end the stream
inline void EOFcheck();
public:
//! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.
//! \note This capacity limits both the bytes that have been reassembled,
//! and those that have not yet been reassembled.
StreamReassembler(const size_t capacity);
//! \brief Receive a substring and write any newly contiguous bytes into the stream.
//!
//! The StreamReassembler will stay within the memory limits of the `capacity`.
//! Bytes that would exceed the capacity are silently discarded.
//!
//! \param data the substring
//! \param index indicates the index (place in sequence) of the first byte in `data`
//! \param eof the last byte of `data` will be the last byte in the entire stream
void push_substring(const std::string &data, const uint64_t index, const bool eof);
void push_substring(const Buffer &data, const size_t index, const bool eof);
//! \name Access the reassembled byte stream
//!@{
const ByteStream &stream_out() const { return _output; }
ByteStream &stream_out() { return _output; }
//!@}
uint64_t first_unassembled() const;
//! The number of bytes in the substrings stored but not yet reassembled
//!
//! \note If the byte at a particular index has been pushed more than once, it
//! should only be counted once for the purpose of this function.
size_t unassembled_bytes() const;
//! \brief Is the internal state empty (other than the output stream)?
//! \returns `true` if no substrings are waiting to be assembled
bool empty() const;
};
#endif // SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
“stream_reassembler.cc”
#include "stream_reassembler.hh"
// Dummy implementation of a stream reassembler.
// For Lab 1, please replace with a real implementation that passes the
// automated checks run by `make check_lab1`.
// You will need to add private members to the class declaration in `stream_reassembler.hh`
template <typename... Targs>
void DUMMY_CODE(Targs &&... /* unused */) {}
using namespace std;
StreamReassembler::StreamReassembler(const size_t capacity)
: _output(capacity)
, _capacity(capacity)
, _first_uass(0)
, _unassembled_bytes(0)
, _eof(false)
, _eof_idx(0)
, _blocks() {}
//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
// the data that have been reassembled
if (index + data.size() < _first_uass) {
return;
}
if (eof && !_eof) {
_eof = true;
_eof_idx = index + data.size();
}
StreamBlock blk(index, move(string(data)));
// if a part of the data have been reassembled
if (index < _first_uass) {
blk.buffer().remove_prefix(_first_uass - index);
}
// if a part of the data out of the capacity
if (index + data.size() > _capacity + _first_uass) {
blk.buffer().remove_suffix(index + data.size() - _capacity - _first_uass);
}
add_block(blk);
write_to_stream();
EOFcheck();
}
void StreamReassembler::push_substring(const Buffer &data, const size_t index, const bool eof) {
// the data that have been reassembled
if (index + data.size() < _first_uass) {
return;
}
if (eof && !_eof) {
_eof = true;
_eof_idx = index + data.size();
}
StreamBlock blk(index, move(data));
// if a part of the data have been reassembled
if (index < _first_uass) {
blk.buffer().remove_prefix(_first_uass - index);
}
// if a part of the data out of the capacity
if (index + data.size() > _capacity + _first_uass) {
blk.buffer().remove_suffix(index + data.size() - _capacity - _first_uass);
}
add_block(blk);
write_to_stream();
EOFcheck();
}
//! \details This function check if eof is written to the stream
inline void StreamReassembler::EOFcheck() {
if (!_eof) {
return;
}
if (static_cast<size_t>(_eof_idx) == _first_uass) {
_output.end_input();
}
}
//! \details This function write the first block into the stream,
//! the first block should begin at '_first_uass'
inline void StreamReassembler::write_to_stream() {
while (!_blocks.empty()) {
auto block = *_blocks.begin();
if (block.begin() != _first_uass) {
return;
}
size_t bytes_written = _output.write(block.buffer());
if (bytes_written == 0) {
return;
}
_first_uass += bytes_written;
_unassembled_bytes -= bytes_written;
_blocks.erase(move(_blocks.begin()));
// partially written
if (bytes_written != block.len()) {
block.buffer().remove_prefix(move(bytes_written));
_blocks.insert(move(block));
}
}
}
//! \details This function add "to_add" blocks to set blocks
// merge all the blocks mergeable
inline void StreamReassembler::add_block(StreamBlock &new_block) {
if (new_block.len() == 0) {
return;
}
vector<StreamBlock> blks_to_add;
blks_to_add.emplace_back(move(new_block));
if (!_blocks.empty()) {
auto nblk = blks_to_add.begin();
auto iter = _blocks.lower_bound(*nblk);
auto prev = iter;
while (iter != _blocks.end() && overlap(*iter, *nblk)) {
if ((*iter).end() >= (*nblk).end()) {
(*nblk).buffer().remove_suffix((*nblk).end() - (*iter).begin());
break;
}
StreamBlock last(*nblk);
(*nblk).buffer().remove_suffix((*nblk).end() - (*iter).begin());
last.buffer().remove_prefix((*iter).end() - (*nblk).begin());
blks_to_add.push_back(move(last));
nblk = blks_to_add.end();
nblk -- ;
iter ++ ;
}
// compare with prevs
// check one previous block is enough
if (prev != _blocks.begin()) {
prev -- ;
nblk = blks_to_add.begin();
if (overlap(*nblk, *prev)) {
(*nblk).buffer().remove_prefix((*prev).end() - (*nblk).begin());
}
}
}
for (auto &blk : blks_to_add) {
if (blk.len() != 0) {
_blocks.emplace(move(blk));
_unassembled_bytes += blk.len();
}
}
}
//! \details This function check if the two blocks have overlap part
bool StreamReassembler::overlap(const StreamBlock &blk, const StreamBlock &new_blk) const {
if (blk.begin() < new_blk.begin()) {
return new_blk.begin() < blk.end();
}
return blk.begin() < new_blk.end();
}
uint64_t StreamReassembler::first_unassembled() const { return _first_uass; }
size_t StreamReassembler::unassembled_bytes() const { return _unassembled_bytes; }
bool StreamReassembler::empty() const { return _unassembled_bytes == 0; }