【并发编程十七】c++实现一个线程池
- 一、线程池原理
- 二、实现重点
- 三、个人理解
- 四、实验
- 简介:
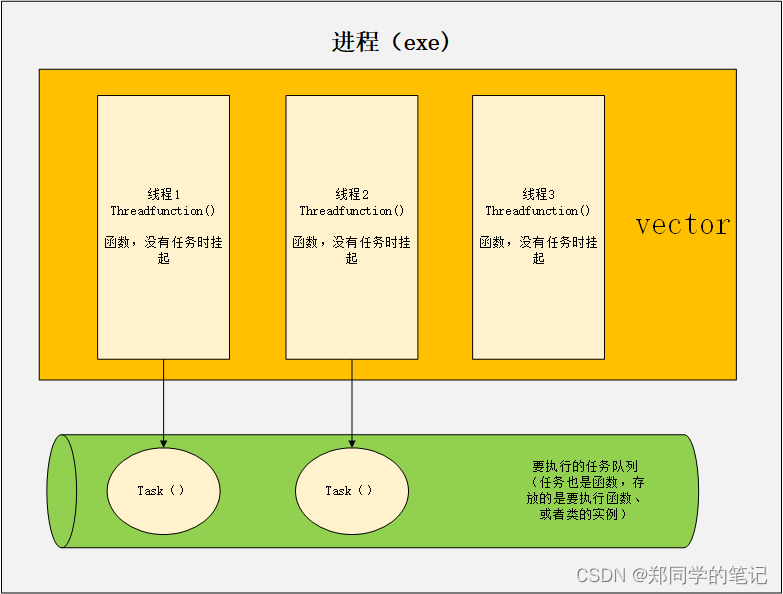
大多数系统上,若因某些任务可以与其他任务并行处理,就分别给他们配备专属的线程,则这种做法不切实际。但是只要有可能,我们还是想充分利用可调配的并发算力。线程池正好可以帮助我们达到目的:讲可同时执行的任务都提交到线程池,再将其放入任务队列中等待;随后,队列中的任务分别由某一工作线程领取并执行,执行完成后,改线程再从任务队列中取出另外一任务来执行,如此循环往复。
一、线程池原理
- 线程池其实只是一组线程。
- 在一般情况下,我们需要异步执行一些任务,这些任务的产生和执行是存在于程序的整个生命周期的。
- 与其让操作系统频繁低为我们创建和销毁线程,不如创建一组在程序生命周期内不会退出的线程。
- 为了不浪费系统的资源,我们的基本要求是当有任务需要执行时,这些线程可以自动拿到任务并执行,在没有任务时这些线程处于阻塞或者睡眠状态。
二、实现重点
- 既然在程序生命周期内会产生很多任务,那么这些任务必须有一个存放的地方,这个地方就是队列,所以不要一提到队列就认为它是1个具体的list,队列也可以是一个全局变量或链表。
- 这在本质尚就是生产者、消费者模式,产生任务的线程是生产者,线程池中的线程是消费者。
- 既然会有多个线程同时操作这个队列,那么根据多线程程序的原则,我们一般需要对这个队列线程加锁。
- 在技术上除了要解决线程池创建、向任务队列中投递任务、从任务队列中取任务并处理的问题,我们还需要做一些善后的工作:线程池的清理、退出线程池中的工作线程、清零任务队列等。
三、个人理解
以下文字可以在理解完毕线程池的代码后再来看下
- 我们可以把一个函数(或者类的方法)绑定给一个单独的线程执行。
- 当然,我们也可以把一个函数绑定给多个线程,每个线程中执行的函数都相同。(数据不同)
- 执行函数相同,而数据不同?绑定任务时,需要传入this,this就是给线程中执行的不同的数据。(因为需要操作不同的数据,所以需要加锁)
- 只不过执行的过程会判断下任务队列中是否由任务,有任务才会执行。
四、实验
- demo
#include <iostream>
#include <atomic>
#include<thread>
#include<condition_variable>
#include<list>
#include<vector>
#include<memory>
#include<functional> // bind头文件
using namespace std;
//线程池要执行的具体的业务
class Task
{
public:
virtual void doWork()
{
cout << "===================== start a work =====================\n";
}
virtual ~Task()
{
cout << "===================== finsh a work =====================\n";
}
};
// 线程池的实现
class threadPool
{
public:
threadPool();
~threadPool();
threadPool(const threadPool& rhs) = delete;
threadPool& operator = (const threadPool& rhs) = delete;
public:
void init(int threadNumber = 4);
void stop();
void addTask(Task* task);
void clear();
//void popTask(task* task);
private:
void threadFunction(); //线程池中要多个线程执行的函数(休眠函数)
private:
vector<shared_ptr<thread>> m_threadVector; //线程池中的存线程的vector
std::list<shared_ptr<Task>> m_taskList; //任务队列
mutex m_mutex; //因为多个线程(函数),同时操作任务队列,所以需要加函数
condition_variable m_cv; //条件变量
bool m_bRunging; //线程池状态
};
threadPool::threadPool() :m_bRunging(false){}
threadPool::~threadPool()
{
clear();
}
void threadPool::init(int threadNum/*=5*/)
{
if (threadNum <= 0)
threadNum = 2;
else if (threadNum > thread::hardware_concurrency())
threadNum = thread::hardware_concurrency();
m_bRunging = true;
for (int i = 0; i < threadNum; i++)
{
shared_ptr<thread> spThread;
//m_threadVector.push_back(thread(&threadPool::threadFunction, this));//如果m_threadVector是vector<thread>,就可以这样绑定。
spThread.reset(new thread(std::bind(&threadPool::threadFunction, this)));
m_threadVector.push_back(spThread);
cout << "add a thread" << endl;
}
}
void threadPool::threadFunction()
{
shared_ptr<Task> spTask;
while (true)
{
{
unique_lock<mutex> guard(m_mutex);
while (m_taskList.empty())
{
if (!m_bRunging)
break;
m_cv.wait(guard);
}
if (!m_bRunging)
break;
spTask = m_taskList.front();
m_taskList.pop_front();
}
/*if (spTask == NULL)
continue;*/
if (spTask)
{
spTask->doWork();
spTask.reset();
cout << "exit thread and threadID=" << this_thread::get_id() << endl;
}
else
{
cout << "spTask is null\n";
}
}
}
void threadPool::stop()
{
m_bRunging = false;
m_cv.notify_all();
for (auto& iter : m_threadVector)
{
if (iter->joinable())
iter->join();
}
}
void threadPool::addTask(Task* task)
{
shared_ptr<Task> spTask;
spTask.reset(task);
{
lock_guard<mutex> guard(mutex);
m_taskList.push_back(spTask);
cout << "add a task.\n";
}
m_cv.notify_one();
}
void threadPool::clear()
{
lock_guard<mutex> guard(m_mutex);
for (auto& iter : m_taskList)
iter.reset();
m_taskList.clear();
}
int main()
{
threadPool m_threadPool;
m_threadPool.init(55);
Task* task = NULL;
for (int i = 0; i < 10; i++)
{
task = new Task();
m_threadPool.addTask(task);
}
this_thread::sleep_for(chrono::milliseconds(1000));
m_threadPool.stop();
}
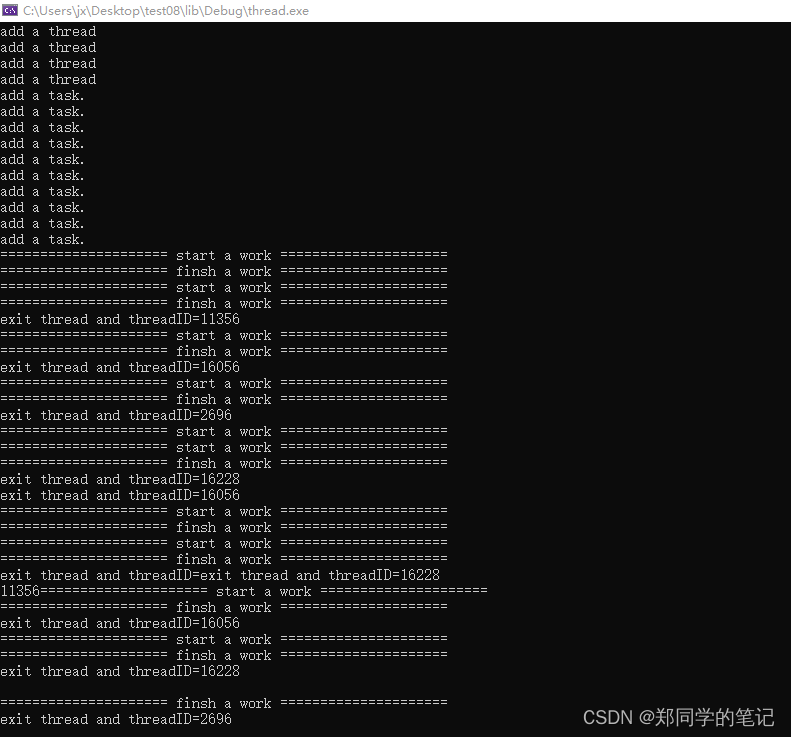
- 输出
参考:
1、《c++并发编程实战(第二版)》安东尼.威廉姆斯 著;吴天明 译;
2、《c++服务器开发精髓》 张远龙 著;