“Natural Language Toolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库。NLTK是一个开源的项目,包含:Python模块,数据集和教程,用于NLP的研究和开发。NLTK由Steven Bird和Edward Loper在宾夕法尼亚大学计算机和信息科学系开发。NLTK包括图形演示和示例数据。其提供的教程解释了工具包支持的语言处理任务背后的基本概念。
一、工具下载
1. 方法1
pip install nltk
直接pip即可,但是现在安装的只是nltk的框架,并不是全部的工具包,每当我们使用某个工具包时,都需要去单独的下载:https://github.com/nltk/nltk_data
注:punkt插件
NOTICE: 下载后塞到:C:\Users\XXXX\AppData\Roaming\nltk_data路径下,没有nltk_data就创建一个,然后将压缩包解压后塞进去就好。
注意:
最后的路径要和官网上的路径一致,不是全都塞入nltk_data路径下,例如:stopwords,先先建立corpora文件夹,再将stopwords解压后放到corpora路径下,即:C:\Users\XXXX\AppData\Roaming\nltk_data\corpora\stopwords
2. 方法2
nltk.download()
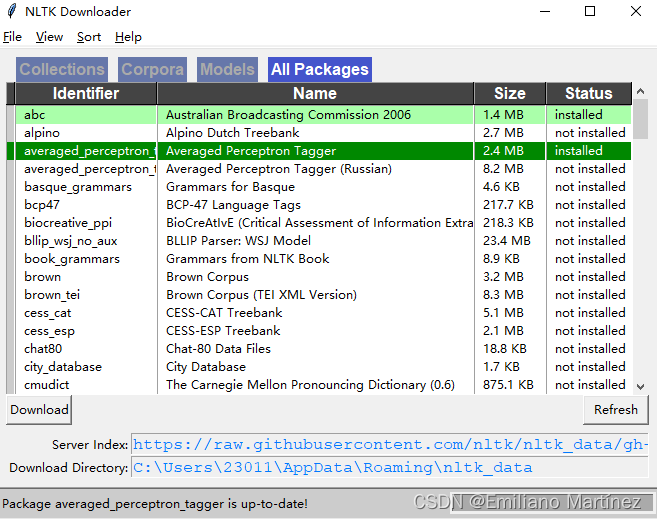
在下图所示的弹窗中,在All Packages中选择需要的工具包,点击左下角的download,等待右下角的红色进度条结束后则安装完成。
二、NLTK应用
1. 基本应用
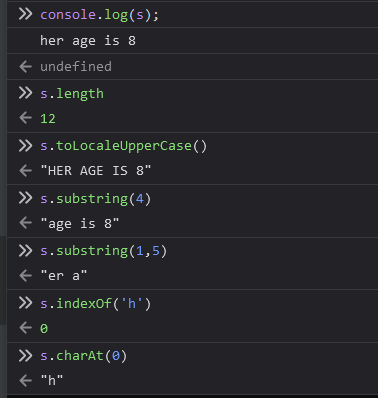
import nltk
from nltk.tokenize import word_tokenize
from nltk.text import Text
str1 = "Today's weather is good, very windy and sunny, we have no classes in the afternoon, we have to play basketball tomorrow."
tokens = word_tokenize(str1)
tokens

将原文转换为小写:👇
tokens = [word.lower() for word in tokens]
tokens[:5]
创建Text对象,方便后续操作:
t = Text(tokens) # 实例化
t.count('good') # OUT: 1
t.index('good') # OUT: 4
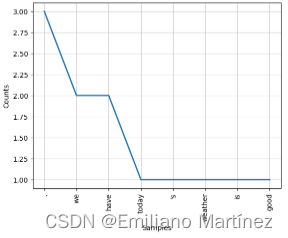
统计出现的词汇的前8个最多的词:👇
t.plot(8)
2. 停用词
from nltk.corpus import stopwords
stopwords.readme().replace('\n',' ')
查看都支持哪些语言的停用词:【没有汉语,扎不扎心~😄】
stopwords.fileids()
查看english的停用词有哪些:
stopwords.raw('english').replace('\n',' ') # 把\n替换一下看着舒服一些
文本预处理:(改小写,去掉重复元素)
str1 = "Today's weather is good, very windy and sunny, we have no classes in the afternoon, we have to play basketball tomorrow."
tokens = word_tokenize(str1)
test_words = [word.lower() for word in tokens]
test_words_set = set(test_words)
test_words_set

查看原文中的单词与停用词表的交集(注:记得指定使用哪种语言的停用词表)👇
test_words_set.intersection(set(stopwords.words('english')))
# OUT: {'and', 'have', 'in', 'is', 'no', 'the', 'to', 'very', 'we'}
过滤掉停用词 (遍历test_words_set中的每个单词,如果不在停用词表中,就留下来)👇
filter = [w for w in test_words_set if (w not in stopwords.words('english'))]
filter

3. 词性标注
(1)基本操作
先安装第三个工具包(averaged~~~)
from nltk import pos_tag
tags = pos_tag(tokens)
tags

(2)分块操作
from nltk.chunk import RegexpParser
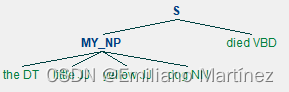
sentence = [('the','DT'),('little','JJ'),('yellow','JJ'),('dog','NN'),('died','VBD')]
grammer = "MY_NP: {<DT>?<JJ>*<NN>}"
cp = nltk.RegexpParser(grammer)
result = cp.parse(sentence)
print(result)
# OUT: (S (MY_NP the/DT little/JJ yellow/JJ dog/NN) died/VBD)
result.draw()
(3)命名实体识别
先安装maxenet_ne_chunke工具包
from nltk import ne_chunk
sentence = "Edison went to Tsinghua University today."
print(ne_chunk(pos_tag(word_tokenize(sentence)))) # 分词,词性,识别

![洛谷P8601[蓝桥杯][2013年第四届真题]剪格子](https://img-blog.csdnimg.cn/img_convert/9b66939be6cf4625bb425f28edf9ca18.png)








![[SSD科普之2] SATA、mSATA、M.2、M.2(NVMe)、PCIE固态硬盘接口详解](https://img-blog.csdnimg.cn/img_convert/b64ffa9ac2b249c8a41c8b4c3e70b1ec.png)