6.7 rdbms 数据
回顾在SparkCore中读取MySQL表的数据通过JdbcRDD来读取的,在SparkSQL模块中提供对应接口,提供三种方式读取数据:
方式一:单分区模式

方式二:多分区模式,可以设置列的名称,作为分区字段及列的值范围和分区数目

方式三:高度自由分区模式,通过设置条件语句设置分区数据及各个分区数据范围

当加载读取RDBMS表的数据量不大时,可以直接使用单分区模式加载;当数据量很多时,考虑使用多分区及自由分区方式加载。
从RDBMS表中读取数据,需要设置连接数据库相关信息,基本属性选项如下:

范例演示:以MySQL数据库为例,加载订单表so数据,首先添加数据库驱动依赖包:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
完整演示代码如下:
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 使用SparkSession从RDBMS 表中读取数据,此处以MySQL数据库为例
*/
object SparkSQLMySQL {
def main(args: Array[String]): Unit = {
// 在SparkSQL中,程序的同一入口为SparkSession实例对象,构建采用是建造者模式
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName("SparkSQLMySQL")
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 连接数据库三要素信息
val url: String = "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=ut
f8&useUnicode=true"
val table: String = "db_shop.so"
// 存储用户和密码等属性
val props: Properties = new Properties()
props.put("driver", "com.mysql.cj.jdbc.Driver")
props.put("user", "root")
props.put("password", "123456")
// TODO: 从MySQL数据库表:销售订单表 so
// def jdbc(url: String, table: String, properties: Properties): DataFrame
val sosDF: DataFrame = spark.read.jdbc(url, table, props)
println(s"Count = ${sosDF.count()}")
sosDF.printSchema()
sosDF.show(10, truncate = false)
// 关闭资源
spark.stop()
}
}
可以使用option方法设置连接数据库信息,而不使用Properties传递,代码如下:
// TODO: 使用option设置参数
val dataframe: DataFrame = spark.read
.format("jdbc")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "db_shop.so")
.load()
dataframe.show(5, truncate = false)
6.8 hive 数据
Spark SQL模块从发展来说,从Apache Hive框架而来,发展历程:Hive(MapReduce)-> Shark (Hive on Spark) -> Spark SQL(SchemaRDD -> DataFrame -> Dataset),所以SparkSQL天然无缝集成Hive,可以加载Hive表数据进行分析。
官方文档:http://spark.apache.org/docs/2.4.5/sql-data-sources-hive-tables.html
spark-shell 集成 Hive
第一步、当编译Spark源码时,需要指定集成Hive,命令如下:

官方文档:http://spark.apache.org/docs/2.4.5/building-spark.html#building-with-hive-and-jdbc-support
第二步、SparkSQL集成Hive本质就是:读取Hive框架元数据MetaStore,此处启动Hive MetaStore服务即可。
-
Hive 元数据MetaStore读取方式:JDBC连接四要素和HiveMetaStore服务

-
启动Hive MetaStore 服务,脚本【metastore-start.sh】内容如下:
#!/bin/sh
HIVE_HOME=/export/server/hive
## 启动服务的时间
DATE_STR=`/bin/date '+%Y%m%d%H%M%S'`
# 日志文件名称(包含存储路径)
HIVE_SERVER2_LOG=${HIVE_HOME}/hivemetastore-${DATE_STR}.log
## 启动服务
/usr/bin/nohup ${HIVE_HOME}/bin/hive --service metastore > ${HIVE_SERVER2_LOG} 2>&1 &
第三步、连接HiveMetaStore服务配置文件hive-site.xml,放于【$SPARK_HOME/conf】目录
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1.itcast.cn:9083</value>
</property>
</configuration>
将hive-site.xml配置发送到集群中所有Spark按照配置目录,此时任意机器启动应用都可以访问Hive表数据。
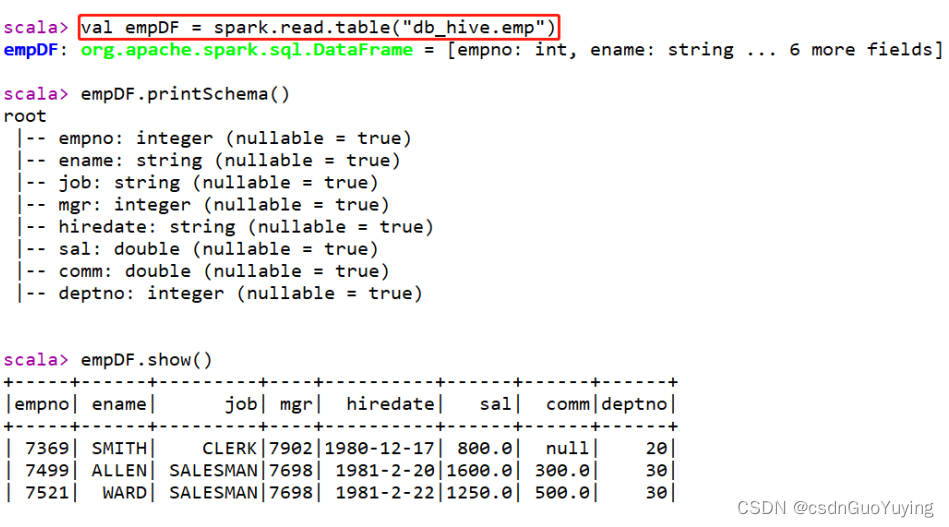
第四步、案例演示,读取Hive中db_hive.emp表数据,分析数据
-
其一、读取表的数据,使用DSL分析
-
其二、直接编写SQL语句
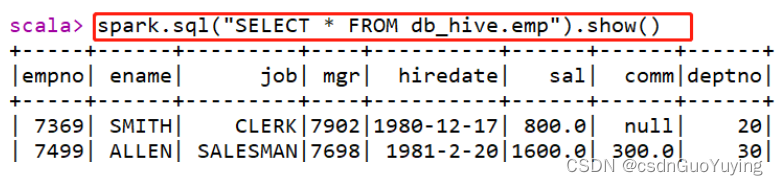
复杂SQL分析语句执行:
spark.sql("select e.ename, e.sal, d.dname from db_hive.emp e join db_hive.dept d on e.deptno = d.dept
no").show()
IDEA 集成 Hive
在IDEA中开发应用,集成Hive,读取表的数据进行分析,构建SparkSession时需要设置HiveMetaStore服务器地址及集成Hive选项,首先添加MAVEN依赖包:
<!-- Spark SQL 与 Hive 集成 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
范例演示代码如下:
import org.apache.spark.sql.SparkSession
/**
* SparkSQL集成Hive,读取Hive表的数据进行分析
*/
object SparkSQLHive {
def main(args: Array[String]): Unit = {
// TODO: 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.config("spark.sql.shuffle.partitions", "4")
// 指定Hive MetaStore服务地址
.config("hive.metastore.uris", "thrift://node1.itcast.cn:9083")
// TODO: 表示集成Hive,读取Hive表的数据
.enableHiveSupport()
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 导入函数库
import org.apache.spark.sql.functions._
// TODO: 读取Hive表的数据
spark.sql(
"""
|SELECT deptno, ROUND(AVG(sal), 2) AS avg_sal FROM db_hive.emp GROUP BY deptno
""".stripMargin)
.show(10, truncate = false)
println("===========================================================")
import org.apache.spark.sql.functions._
spark.read
.table("db_hive.emp")
.groupBy($"deptno")
.agg(round(avg($"sal"), 2).alias("avg_sal"))
.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
运行程序结果如下:


![buu [NPUCTF2020]Classical Cipher 1](https://img-blog.csdnimg.cn/3b5c07fe882942389f81a3ce512be516.png)