前端面试基础知识题
1.如何实现单行/多行文本溢出的省略样式?
在日常开发展示页面,如果一段文本的数量过长,受制于元素宽度的因素,有可能不能完全显示,为了提高用户的使用体验,这个时候就需要我们把溢出的文本显示成省略号。
对于文本的溢出,我们可以分成两种形式:
单行文本溢出
多行文本溢出
实现方式
单行文本溢出省略
理解也很简单,即文本在一行内显示,超出部分以省略号的形式展现
实现方式也很简单,涉及的css属性有:
text-overflow:规定当文本溢出时,显示省略符号来代表被修剪的文本
white-space:设置文字在一行显示,不能换行
overflow:文字长度超出限定宽度,则隐藏超出的内容
overflow设为hidden,普通情况用在块级元素的外层隐藏内部溢出元素,或者配合下面两个属性实现文本溢出省略
white-space:nowrap,作用是设置文本不换行,是overflow:hidden和text-overflow:ellipsis生效的基础
text-overflow属性值有如下:
clip:当对象内文本溢出部分裁切掉
ellipsis:当对象内文本溢出时显示省略标记(…)
text-overflow只有在设置了overflow:hidden和white-space:nowrap才能够生效的
多行文本溢出省略
多行文本溢出的时候,我们可以分为两种情况:
基于高度截断
基于行数截断
基于高度截断
伪元素 + 定位
核心的css代码结构如下:
position: relative:为伪元素绝对定位
overflow: hidden:文本溢出限定的宽度就隐藏内容)
position: absolute:给省略号绝对定位
line-height: 20px:结合元素高度,高度固定的情况下,设定行高, 控制显示行数
height: 40px:设定当前元素高度
::after {} :设置省略号样式
代码如下所示:
<style>
.demo {
position: relative;
line-height: 20px;
height: 40px;
overflow: hidden;
}
.demo::after {
content: "...";
position: absolute;
bottom: 0;
right: 0;
padding: 0 20px 0 10px;
}
</style>
<body>
<div class='demo'>这是一段很长的文本</div>
</body>
实现原理很好理解,就是通过伪元素绝对定位到行尾并遮住文字,再通过 overflow: hidden 隐藏多余文字
这种实现具有以下优点:
兼容性好,对各大主流浏览器有好的支持
响应式截断,根据不同宽度做出调整
一般文本存在英文的时候,可以设置word-break: break-all使一个单词能够在换行时进行拆分
基于行数截断
纯css实现也非常简单,核心的css代码如下:
-webkit-line-clamp: 2:用来限制在一个块元素显示的文本的行数,为了实现该效果,它需要组合其他的WebKit属性)
display: -webkit-box:和1结合使用,将对象作为弹性伸缩盒子模型显示
-webkit-box-orient: vertical:和1结合使用 ,设置或检索伸缩盒对象的子元素的排列方式
overflow: hidden:文本溢出限定的宽度就隐藏内容
text-overflow: ellipsis:多行文本的情况下,用省略号“…”隐藏溢出范围的文本
<style>
p {
width: 400px;
border-radius: 1px solid red;
-webkit-line-clamp: 2;
display: -webkit-box;
-webkit-box-orient: vertical;
overflow: hidden;
text-overflow: ellipsis;
}
</style>
<p>
这是一些文本这是一些文本这是一些文本这是一些文本这是一些文本
这是一些文本这是一些文本这是一些文本这是一些文本这是一些文本
</p >
可以看到,上述使用了webkit的CSS属性扩展,所以兼容浏览器范围是PC端的webkit内核的浏览器,由于移动端大多数是使用webkit,所以移动端常用该形式。
需要注意的是,如果文本为一段很长的英文或者数字,则需要添加word-wrap: break-word属性。
2.flexbox(弹性盒布局模型)是什么,适用什么场景?
Flexible Box 简称 flex,意为”弹性布局”,可以简便、完整、响应式地实现各种页面布局。
采用Flex布局的元素,称为flex容器container。
它的所有子元素自动成为容器成员,称为flex项目item。
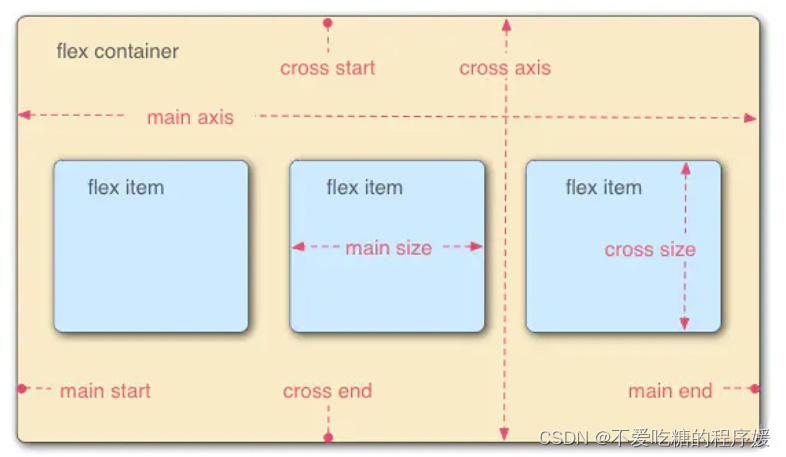
容器中默认存在两条轴,主轴和交叉轴,呈90度关系。项目默认沿主轴排列,通过flex-direction来决定主轴的方向。
每根轴都有起点和终点,这对于元素的对齐非常重要。
属性
关于flex常用的属性,我们可以划分为容器属性和容器成员属性。
容器属性有:
flex-direction
flex-wrap
flex-flow
justify-content
align-items
align-content
关于flex可以看我的csdn的flex弹性盒子教程,里面更详细。
地址:https://blog.csdn.net/weixin_45822171/article/details/114289990
应用场景
实现元素水平垂直方向的居中,以及在两栏三栏自适应布局中,包括现在在移动端、小程序这边的开发,都建议使用flex进行布局。
3.em/px/rem/vh/vw 这些单位有什么区别?
px:绝对单位,页面按精确像素展示
em:相对单位,基准点为父节点字体的大小,如果自身定义了font-size按自身来计算,整个页面内1em不是一个固定的值
rem:相对单位,可理解为root em, 相对根节点html的字体大小来计算
vh、vw:主要用于页面视口大小布局,在页面布局上更加方便简单
4.CSS 垂直居中有哪些实现方式?
可以看我的csdn博客:https://blog.csdn.net/weixin_45822171/article/details/118392923
5.css加载会造成阻塞吗?
先说下结论:
- css加载不会阻塞DOM树的解析
- css加载会阻塞DOM树的渲染
- css加载会阻塞后面js语句的执行
为了避免让用户看到长时间的白屏时间,我们应该尽可能的提高css加载速度,比如可以使用以下几种方法:
- 使用CDN(因为CDN会根据你的网络状况,替你挑选最近的一个具有缓存内容的节点为你提供资源,因此可以减少加载时间)
- 对css进行压缩(可以用很多打包工具,比如webpack,gulp等,也可以通过开启gzip压缩)
- 合理的使用缓存(设置cache-control,expires,以及E-tag都是不错的,不过要注意一个问题,就是文件更新后,你要避免缓存而带来的影响。其中一个解决防范是在文件名字后面加一个版本号)
- 减少http请求数,将多个css文件合并,或者是干脆直接写成内联样式(内联样式的一个缺点就是不能缓存)
原理解析
浏览器渲染的流程如下:
- HTML解析文件,生成DOM Tree,解析CSS文件生成CSSOM Tree
- 将Dom Tree和CSSOM Tree结合,生成Render Tree(渲染树)
- 根据Render Tree渲染绘制,将像素渲染到屏幕上。
从流程我们可以看出来:
- DOM解析和CSS解析是两个并行的进程,所以这也解释了为什么CSS加载不会阻塞DOM的解析。
- 然而,由于Render Tree是依赖于DOM Tree和CSSOM Tree的,所以他必须等待到CSSOM Tree构建完成,也就是CSS资源加载完成(或者CSS资源加载失败)后,才能开始渲染。因此,CSS加载是会阻塞Dom的渲染的。
- 由于js可能会操作之前的Dom节点和css样式,因此浏览器会维持html中css和js的顺序。因此,样式表会在后面的js执行前先加载执行完毕。所以css会阻塞后面js的执行。
6.怎么触发BFC,BFC有什么应用场景?
文档流
在介绍BFC之前,需要先给大家介绍一下文档流。
我们常说的文档流其实分为定位流、浮动流、普通流三种。
绝对定位(Absolute positioning)
如果元素的属性 position 为 absolute 或 fixed,它就是一个绝对定位元素。
在绝对定位布局中,元素会整体脱离普通流,因此绝对定位元素不会对其兄弟元素造成影响,而元素具体的位置由绝对定位的坐标决定。
它的定位相对于它的包含块,相关CSS属性:top、bottom、left、right;
对于 position: absolute,元素定位将相对于上级元素中最近的一个relative、fixed、absolute,如果没有则相对于body;
对于 position:fixed,正常来说是相对于浏览器窗口定位的,但是当元素祖先的 transform 属性非 none 时,会相对于该祖先进行定位。
浮动 (float)
在浮动布局中,元素首先按照普通流的位置出现,然后根据浮动的方向尽可能的向左边或右边偏移,其效果与印刷排版中的文本环绕相似。
普通流 (normal flow)
普通流其实就是指BFC中的FC。FC(Formatting Context),直译过来是格式化上下文,它是页面中的一块渲染区域,有一套渲染规则,决定了其子元素如何布局,以及和其他元素之间的关系和作用。
在普通流中,元素按照其在 HTML 中的先后位置至上而下布局,在这个过程中,行内元素水平排列,直到当行被占满然后换行。块级元素则会被渲染为完整的一个新行。
除非另外指定,否则所有元素默认都是普通流定位,也可以说,普通流中元素的位置由该元素在 HTML 文档中的位置决定。
BFC 概念
先看下MDN上关于BFC的定义:
块格式化上下文(Block Formatting Context,BFC)
是Web页面的可视CSS渲染的一部分,是块盒子的布局过程发生的区域,也是浮动元素与其他元素交互的区域。
具有 BFC 特性的元素可以看作是隔离了的独立容器,容器里面的元素不会在布局上影响到外面的元素,并且 BFC 具有普通容器所没有的一些特性。
通俗一点来讲,可以把 BFC 理解为一个封闭的大箱子,箱子内部的元素无论如何翻江倒海,都不会影响到外部。
除了 BFC,还有:
- IFC(行级格式化上下文)- inline 内联
- GFC(网格布局格式化上下文)- display: grid
- FFC(自适应格式化上下文)- display: flex或display: inline-flex
注意:同一个元素不能同时存在于两个 BFC 中。
BFC的触发方式
MDN上对于BFC的触发条件写的很多,总结一下常见的触发方式有(只需要满足一个条件即可触发 BFC 的特性):
- 根元素,即
- 浮动元素:float 值为 left 、right
- overflow 值不为 visible,即为 auto、scroll、hidden
- display 值为 inline-block、table-cell、table-caption、table、inline-table、flex、inline-flex、grid、 - inline-grid
- 绝对定位元素:position 值为 absolute、fixed
BFC的特性
- BFC 是页面上的一个独立容器,容器里面的子元素不会影响外面的元素。
- BFC 内部的块级盒会在垂直方向上一个接一个排列
- 同一 BFC 下的相邻块级元素可能发生外边距折叠,创建新的 BFC 可以避免外边距折叠
- 每个元素的外边距盒(margin box)的左边与包含块边框盒(border box)的左边相接触(从右向左的格式的话,则相反),即使存在浮动
- 浮动盒的区域不会和 BFC 重叠
- 计算 BFC 的高度时,浮动元素也会参与计算
应用
- 自适应两列布局
- 防止外边距(margin)重叠
- 父子元素的外边距重叠
- 清除浮动解决令父元素高度坍塌的问题
7.为何CSS不支持父选择器?
这个问题的答案和“为何CSS相邻兄弟选择器只支持后面的元素,而不支持前面的兄弟元素?”是一样的。
浏览器解析HTML文档,是从前往后,由外及里的。所以,我们时常会看到页面先出现头部然后主体内容再出现的加载情况。
但是,如果CSS支持了父选择器,那就必须要页面所有子元素加载完毕才能渲染HTML文档,因为所谓“父选择器”,就是后代元素影响祖先元素,如果后代元素还没加载处理,如何影响祖先元素的样式?于是,网页渲染呈现速度就会大大减慢,浏览器会出现长时间的白板。加载多少HTML就可以渲染多少HTML,在网速不是很快的时候,就显得尤为的必要。比方说你现在看的这篇文章,只要文章内容加载出来就可以了,就算后面的广告脚本阻塞了后续HTML文档的加载,我们也是可以阅读和体验。但是,如果支持父选择器,则整个文档不能有阻塞,页面的可访问性则要大大降低。
有人可能会说,要不采取加载到哪里就渲染到哪里的策略?这样子问题更大,因为会出现加载到子元素的时候,父元素本来渲染的样式突然变成了另外一个样式的情况,体验非常不好。
“相邻选择器只能选择后面的元素”也是一样的道理,不可能说后面的HTML加载好了,还会影响前面HTML的样式。
所以,从这一点来讲,CSS支持“父选择器”或者“前兄弟选择器”的可能性要比其他炫酷的CSS特性要低,倒不是技术层面,而是CSS和HTML本身的渲染机制决定的。当然,以后的事情谁都说不准,说不定以后网速都是每秒几个G的,网页加载速度完全就忽略不计,说不定就会支持了。
8.js和css是如何影响DOM树构建的?
先做个总结,然后再进行具体的分析:
CSS不会阻塞DOM的解析,但是会影响JAVAScript的运行,javaSscript会阻止DOM树的解析,最终css(CSSOM)会影响DOM树的渲染,也可以说最终会影响渲染树的生成。
接下来我们先看javascript对DOM树构建和渲染是如何造成影响的,分成三种类型来讲解:
JavaScript脚本在html页面中
<html>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang'
</script>
<div>test</div>
</body>
</html>
两段div中间插入一段JavaScript脚本,这段脚本的解析过程就有点不一样了。
当解析到script脚本标签时,HTML解析器暂停工作,javascript引擎介入,并执行script标签中的这段脚本。
因为这段javascript脚本修改了DOM中第一个div中的内容,所以执行这段脚本之后,div节点内容已经修改为time.geekbang了。脚本执行完成之后,HTML解析器回复解析过程,继续解析后续的内容,直至生成最终的DOM。
html页面中引入javaScript文件
//foo.js
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang'
<html>
<body>
<div>1</div>
<script type="text/javascript" src='foo.js'></script>
<div>test</div>
</body>
</html>
这段代码的功能还是和前面那段代码是一样的,只是把内嵌JavaScript脚本修改成了通过javaScript文件加载。
其整个执行流程还是一样的,执行到JAVAScript标签时,暂停整个DOM的解析,执行javascript代码,不过这里执行javascript时,需要现在在这段代码。这里需要重点关注下载环境,因为javascript文件的下载过程会阻塞DOM解析,而通常下载又是非常耗时的,会受到网络环境、javascript文件大小等因素的影响。
优化机制:
谷歌浏览器做了很多优化,其中一个主要的优化就是预解析操作。当渲染引擎收到字节流之后,会开启一个预解析线程,用来分析HTML文件中包含的JavaScript、CSS等相关文件,解析到相关文件之后,会开启一个预解析线程,用来分析HTML文件中包含的javascprit、css等相关文件、解析到相关文件之后,预解析线程会提前下载这些文件。
再回到 DOM 解析上,我们知道引入 JavaScript 线程会阻塞 DOM,不过也有一些相关的策略来规避,比如使用 CDN 来加速 JavaScript 文件的加载,压缩 JavaScript 文件的体积。
另外,如果 JavaScript 文件中没有操作 DOM 相关代码,就可以将该 JavaScript 脚本设置为异步加载,通过 async 或 defer 来标记代码,使用方式如下所示:
<script async type="text/javascript" src='foo.js'></script>
<script defer type="text/javascript" src='foo.js'></script>
async和defer区别:
async:脚本并行加载,加载完成之后立即执行,执行时机不确定,仍有可能阻塞HTML解析,执行时机在load事件派发之前。
defer:脚本并行加载,等待HTML解析完成之后,按照加载顺序执行脚本,执行时机DOMContentLoaded事件派发之前。
html页面中有css样式
//theme.css
div {color:blue}
<html>
<head>
<style src='theme.css'></style>
</head>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang' // 需要 DOM
div1.style.color = 'red' // 需要 CSSOM
</script>
<div>test</div>
</body>
</html>
该示例中,JavaScript 代码出现了 div1.style.color = ‘red’ 的语句,它是用来操纵 CSSOM 的,所以在执行 JavaScript 之前,需要先解析 JavaScript 语句之上所有的CSS 样式。所以如果代码里引用了外部的 CSS 文件,那么在执行 JavaScript 之前,还需要等待外部的 CSS 文件下载完成,并解析生成 CSSOM 对象之后,才能执行 JavaScript 脚本。
而 JavaScript 引擎在解析 JavaScript 之前,是不知道 JavaScript 是否操纵了 CSSOM的,所以渲染引擎在遇到 JavaScript 脚本时,不管该脚本是否操纵了 CSSOM,都会执行CSS 文件下载,解析操作,再执行 JavaScript 脚本。所以说 JavaScript 脚本是依赖样式表的,这又多了一个阻塞过程。
总结:通过上面三点的分析,我们知道了 JavaScript 会阻塞 DOM 生成,而样式文件又会阻塞js的执行。
9.Js 动画与 CSS 动画区别及相应实现
- CSS3 的动画的优点
在性能上会稍微好一些,浏览器会对 CSS3 的动画做一些优化
代码相对简单
- 缺点
在动画控制上不够灵活
兼容性不好
JavaScript 的动画正好弥补了这两个缺点,控制能力很强,可以单帧的控制、变换,同时写得好完全可以兼容 IE6,并且功能强大。对于一些复杂控制的动画,使用 javascript 会比较靠谱。而在实现一些小的交互动效的时候,就多考虑考虑 CSS 吧。
10.html和css中的图片加载与渲染规则是什么样的?
Web浏览器先会把获取到的HTML代码解析成一个DOM树,HTML中的每个标签都是DOM树中的一个节点,包括display: none隐藏的标签,还有JavaScript动态添加的元素等。浏览器会获取到所有样式,并会把所有样式解析成样式规则,在解析的过程中会去掉浏览器不能识别的样式。
浏览器将会把DOM树和样式规则组合在一起(DOM元素和样式规则匹配)后将会合建一个渲染树(Render Tree),渲染树类似于DOM树,但两者别还是很大的:渲染树能识别样式,渲染树中每个节点(NODE)都有自己的样式,而且渲染树不包含隐藏的节点(比如display:none的节点,还有内的一些节点),因为这些节点不会用于渲染,也不会影响节点的渲染,因此不会包含到渲染树中。一旦渲染树构建完毕后,浏览器就可以根据渲染树来绘制页面了。
简单的归纳就是浏览器渲染Web页面大约会经过六个过程:
- 解析HTML,构成DOM树
- 解析加载的样式,构建样式规则树
- 加载JavaScript,执行JavaScript代码
- DOM树和样式规则树进行匹配,构成渲染树
- 计算元素位置进行页面布局
- 绘制页面,最终在浏览器中呈现
是不是会感觉这个和我们图像加载渲染没啥关系一样,事实并非如此,因为img、picture或者background-image都是DOM树或样式规则中的一部分,那么咱们套用进来,图片加载和渲染的时机有可能是下面这样:
- 解析HTML时,如果遇到img或picture标签,将会加载图片
- 解析加载的样式,遇到background-image时,并不会加载图片,而会构建样式规则树
- 加载JavaScript,执行JavaScript代码,如果代码中有创建img元素之类,会添加到DOM树中;如查有 - 添加background-image规则,将会添加到样式规则树中
- DOM树和样式规则匹配时构建渲染树,如果DOM树节点匹配到样式规则中的backgorund-image,则会加载背景图片
- 计算元素(图片)位置进行布局
- 开始渲染图片,浏览器将呈现渲染出来的图片
上面套用浏览器渲染页面的机制,但图片加载与渲染还是有一定的规则。因为,页面中不是所有的(或picture)元素引入的图片和background-image引入的背景图片都会加载的。那么就引发出新问题了,什么时候会真正的加载,加载规则又是什么?
先概括一点:
Web页面中不是所有的图片都会加载和渲染!
根据前面介绍的浏览器加载和渲染机制,我们可以归纳为:
- 、和设置background-image的元素遇到display:none时,图片会加载但不会渲染
- 、和设置background-image的元素祖先元素设置display:none时,background-image不会渲染也不会加载,而img和picture引入的图片不会渲染但会加载
- 、和background-image引入相同路径相同图片文件名时,图片只会加载一次
- 样式文件中background-image引入的图片,如果匹配不到DOM元素,图片不会加载
- 伪类引入的background-image,比如:hover,只有当伪类被触发时,图片才会加载



![[acwing周赛复盘] 第 91 场周赛20230218](https://img-blog.csdnimg.cn/45a4d035871f4f81b2e3e4acc2f583b0.png)