bottleneck(瓶颈): a point where resource contention is highest
throughput(吞吐量): the amount of work that can be completed in a specified time.
response time (响应时间): the time to complete a specified workload
2.1 Gathering Database Statistics Using the Automatic Workload Repository(AWR)
Automatic Workload Repository (AWR) automates database statistics gathering by collecting, processing, and maintaining performance statistics for database problem detection and self-tuning purposes.
the database gathers statistics every hour and creates an AWR snapshot, which is a set of data for a specific time that is used for performance comparisons.
The following initialization parameters are relevant for AWR:
- STATISTICS_LEVEL
- CONTROL_MANAGEMENT_PACK_ACCESS
The database statistics collected and processed by AWR include:
2.1.1 Time Model Statistics
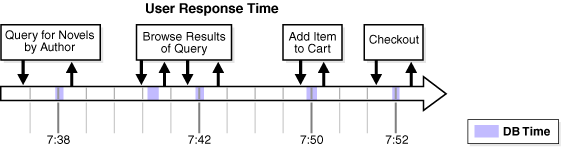
Time model statistics measure the time spent in the database by operation type. The most important time model statistic is database time (DB time). DB time represents the total time spent in database calls by foreground sessions, and is an indicator of the total instance workload.

A session is a logical entity in the database instance memory that represents the state of a current user login to a database.Database time is calculated by aggregating the CPU time and wait time of all active sessions (sessions that are not idle).

The objective of database tuning is to reduce DB time. In this way, you can improve the overall response time of user transactions in the application.
2.1.2 Wait Event Statistics
Wait events are incremented by a session to indicate that the session had to wait for an event to complete before being able to continue processing. When a session has to wait while processing a user request, the database records the wait by using one of a set of predefined wait events. The events are then grouped into wait classes, such as User I/O and Network. Wait event data reveals symptoms of problems that might be affecting performance, such as latch, buffer, or I/O contention.
2.1.3 Session and System Statistics
A large number of cumulative database statistics are available on a system and session level. Some of these statistics are collected by AWR.
2.1.4 Active Session History Statistics
The Active Session History (ASH) statistics are samples of session activity in the database. The database samples active sessions every second and stores them in a circular buffer in the System Global Area (SGA).
2.1.5 High-Load SQL Statistics
SQL statements that are consuming the most resources produce the highest load on the system, based on criteria such as elapsed time and CPU time.
2.2 Using the Oracle Performance Method
Performance tuning using the Oracle performance method is driven by identifying and eliminating bottlenecks in the database, and by developing efficient SQL statements. Database tuning is performed in two phases: proactively and reactively.
In the proactive tuning phase, you must perform tuning tasks as part of your daily database maintenance routine, such as reviewing ADDM analysis and findings, monitoring the real-time performance of the database, and responding to alerts.
In the reactive tuning phase, you must respond to issues reported by users, such as performance problems that may occur for only a short duration of time, or performance degradation to the database over a period of time.
SQL tuning is an iterative process to identify, tune, and improve the efficiency of high-load SQL statements.
To improve database performance, you must apply these principles iteratively.
2.2.1 Preparing the Database for Tuning
To prepare the database for tuning:
- Get feedback from users.
Determine the scope of the performance project and subsequent performance goals, and determine performance goals for the future. This process is key for future capacity planning.
2. Check the operating systems of all systems involved with user performance.
Check for hardware or operating system resources that are fully utilized. List any overused resources for possible later analysis. In addition, ensure that all hardware is functioning properly.
3.Ensure that the STATISTICS_LEVEL initialization parameter is set to TYPICAL (default) or ALL to enable the automatic performance tuning features of Oracle Database, including AWR and ADDM.
4.Ensure that the CONTROL_MANAGEMENT_PACK_ACCESS initialization parameter is set to DIAGNOSTIC+TUNING (default) or DIAGNOSTIC to enable ADDM.
2.2.2 Tuning the Database Proactively
To tune the database proactively:
- Review the ADDM findings
- Implement the ADDM recommendations
- Monitor performance problems with the database in real time
- Respond to performance-related alerts
-
Validate that any changes have produced the desired effect, and verify that the users experience performance improvements.
2.2.3 Tuning the Database Reactively
This section lists and describes the steps required to tune the database based on user feedback. This tuning procedure is considered reactive. Perform this procedure periodically when performance problems are reported by the users.
To tune the database reactively:
- Run ADDM manually to diagnose current and historical database performance when performance problems are reported by the users
- Resolve transient performance problems.(ASH reports enable you to analyze trainsient performance problems with the database that are short-lived and do not appear in the ADDM analysis)
- Resolve performance degradation over time
-
Validate that the changes made have produced the desired effect, and verify that the users experience performance improvements.
-
Repeat these steps until your performance goals are met or become impossible to achieve due to other constraints.
2.2.4 Tuning SQL Statements
This section lists and describes the steps required to identify, tune, and optimize high-load SQL statements.
To tune SQL statements:
- Identify high-load SQL statements
- Tune high-load SQL statements
- Optimize data access paths(creating the proper set of materialized views, materialized view logs, and indexes for a given workload by using SQL Access Advisor)
- Analyze the SQL performance impact of SQL tuning and other system changes by using SQL Performance Analyzer.
-
Repeat these steps until all high-load SQL statements are tuned for greatest efficiency.
2.3 Common Performance Problems Found in Databases
consult the appropriate section that addresses these problems:
- CPU bottlenecks
Performance problems caused by CPU bottlenecks are diagnosed by ADDM,you can also identify CPU bottlenecks by using the Performance page in Cloud Control
- Undersized memory structures
Are the Oracle memory structures such as the System Global Area (SGA), Program Global Area (PGA), and buffer cache adequately sized? Performance problems caused by undersized memory structures are diagnosed by ADDM.You can also identify memory usage issues by using the Performance page in Cloud Control
- I/O capacity issues
Is the I/O subsystem performing as expected? Performance problems caused by I/O capacity issues are diagnosed by ADDM.You can also identify disk I/O issues by using the Performance page in Cloud Control
- Suboptimal use of Oracle Database by the application
Problems such as establishing new database connections repeatedly, excessive SQL parsing, and high levels of contention for a small amount of data (also known as application-level block contention) can degrade the application performance significantly. Performance problems caused by suboptimal use of Oracle Database by the application are diagnosed by ADDM.You can also monitor top activity in various dimensions—including SQL, session, services, modules, and actions—by using the Performance page in Cloud Control.
- Concurrency issues
A high degree of concurrent activities might result in contention for shared resources that can manifest in the form of locks or waits for buffer cache. Performance problems caused by concurrency issues are diagnosed by ADDM.You can also identify concurrency issues by using Top Sessions in Cloud Control
- Database configuration issues
For example, is there evidence of incorrect sizing of log files, archiving issues, too many checkpoints, or suboptimal parameter settings? Performance problems caused by database configuration issues are diagnosed by ADDM.
- Short-lived performance problems
Depending on the interval between snapshots taken by AWR, performance problems that have a short duration may not be captured by ADDM. You can identify short-lived performance problems by using the Active Session History report.
- Degradation of database performance over time
You can generate an AWR Compare Periods report to compare the period when the performance was poor to a period when the performance is stable to identify configuration settings, workload profile, and statistics that are different between these two time periods. This technique helps you identify the cause of the performance degradation
- Inefficient or high-load SQL statements
Performance problems caused by high-load SQL statements are diagnosed by ADDM.You can also identify high-load SQL statements by using Top SQL in Cloud Control.You can tune the high-load SQL statements using SQL Tuning Advisor
- Object contention
Are any database objects the source of bottlenecks because they are continuously accessed?Performance problems caused by object contention are diagnosed by ADDM.You can also optimize the data access path to these objects using SQL Access Advisor.
- Unexpected performance regression after tuning SQL statements
Tuning SQL statements may cause changes to their execution plans, resulting in a significant impact on SQL performance. In some cases, the changes may result in the improvement of SQL performance. In other cases, the changes may cause SQL statements to regress, resulting in a degradation of SQL performance.
Before making changes on a production system, you can analyze the impact of SQL tuning on a test system by using SQL Performance Analyzer. This feature enables you to forecast the impact of system changes on a SQL workload by:
-
Measuring the performance before and after the change
-
Generating a report that describes the change in performance
-
Identifying the SQL statements that regressed or improved
-
Providing tuning recommendations for each SQL statement that regressed
-
Enabling you to implement the tuning recommendations when appropriate