CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
ICLR 2023已经放榜,但是今天我们先来回顾一下去年的ICLR 2022!
ICLR 2022将于2022年 4 月 25 日星期一至 4 月 29 日星期五在线举行(连续第三年!)。它是机器学习研究领域规模最大、最受欢迎的会议之一,它汇集了超过 1000 篇论文、19 个研讨会和 8 个特邀报告。主题涵盖 ML 理论、强化学习 (RL)、计算机视觉 (CV) )、自然语言处理 (NLP)、神经科学等等。如果我们想要对这一庞大的内容阵容有所了解,就必须进行挑选,我们已经根于现有信息,挑选出10篇最能激起我们兴趣的论文。事不宜迟,快来看看吧!
6.Exploring the Limits of Large Scale Pre-training
标题: 探索大规模预训练的极限
作者:Samira Abnar、Mostafa Dehghani、Behnam Neyshabur、Hanie Sedghi
文章链接:https://openreview.net/forum?id=V3C8p78sDa
作者的 TL;DR
我们对具有广泛下游任务的图像识别中的小样本和迁移学习的大规模预训练的局限性进行了系统研究。对具有广泛下游任务的图像识别中的小样本和迁移学习的大规模预训练的局限性进行了系统研究。
关键见解
“As we increase the upstream accuracy, the performance of downstream tasks saturates”研究了上游 (US) 任务(例如大规模 ImageNet 标签)的预训练性能如何转移到下游 (DS) 性能(例如鲸鱼检测)。然后对很多架构和规模做这个实验:很多意思是很多:“在 Vision Transformers、MLP-Mixers 和 ResNets 上进行了 4800 次实验,参数数量从一千万到一百亿不等,在最大规模的可用图像数据上进行了训练”。因此,有趣的图代表了上游性能(美国,预训练)和下游性能(DS,结束任务)之间的关联。几乎全面,它最终会饱和。尽管如此,看到计算机视觉体系结构之间的差异还是非常有趣的!
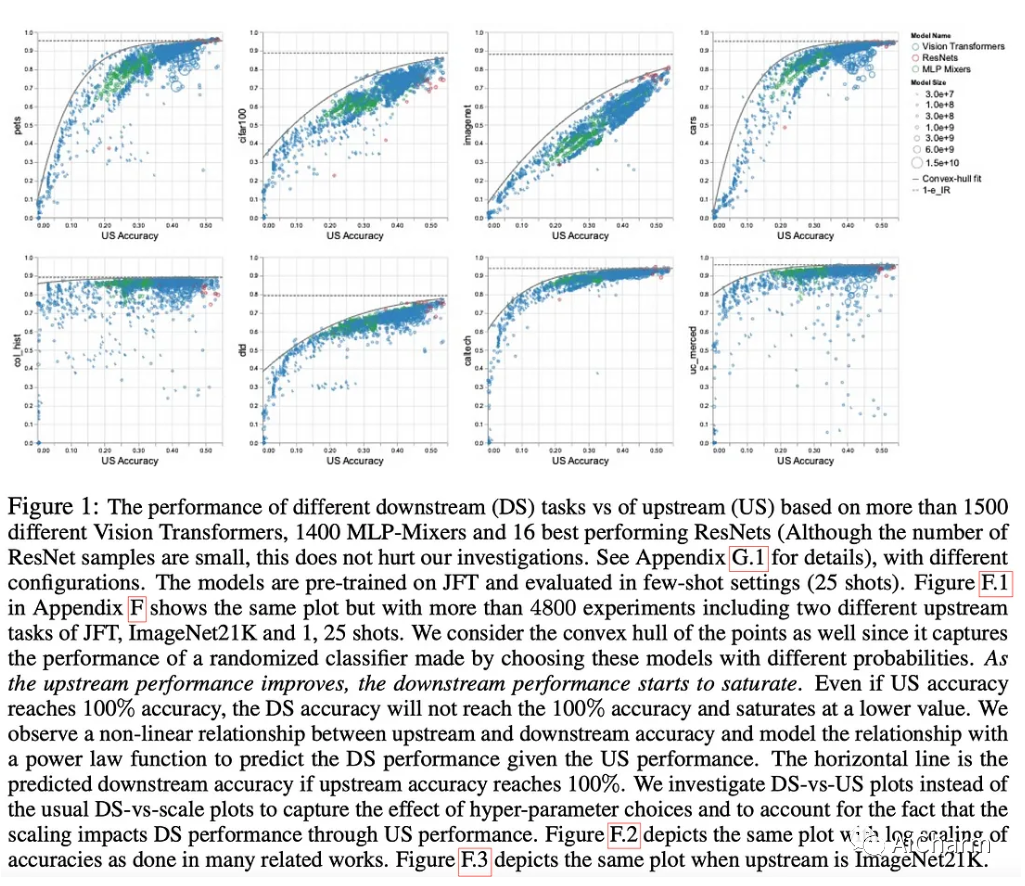
作者声称,他们的观察总体上似乎对上游数据的大小或训练镜头的数量以及架构选择等选择具有稳健性。他们还探讨了超参数选择的影响:是否有一些超参数对美国非常好但不能很好地转化为 DS?是的!他们在第 4 节中深入研究了这一现象,发现例如,权重衰减是一个特别显着的超参数,它对 US 和 DS 性能的影响不同。在没有人真正从头开始训练模型而是选择预训练模型来引导其应用的情况下,这项研究是关键。这篇论文的内容远远超过几段可以概括的内容,如果您想深入了解,绝对值得一读!
7. Language modeling via stochastic processes
标题: 通过随机过程进行语言建模
作者:Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto
文章链接:https://openreview.net/forum?id=pMQwKL1yctf
作者的 TL;DR
我们介绍了一种通过潜在随机过程隐式计划的语言模型。现代大型生成语言模型非常擅长编写短文本,但当它们生成长文本时,往往会失去全局连贯性,事情就不再有意义了。本文提出了一种缓解这种情况的方法
关键见解
典型语言模型 (LM) 仅在令牌粒度级别生成文本,这严重偏向模型学习短程交互而不是远程交互,这正是实现连贯全局所需的技能叙述。这项工作建议在较粗略的句子层次上对语言进行建模,作为一个随机过程,引导 LM 生成在全球范围内保持一致。所提出的模型称为时间控制,它将句子表示建模为潜在空间中的布朗运动。对于训练,给定两个开始和结束锚句,通过使锚句内的正句子落入潜在空间中锚句表示的“布朗桥”内,然后使用负样本来设置对比损失被推出(图 1)。我之前也不知道布朗桥是什么:起点和终点位置固定的布朗(摇晃)轨迹。为了进行推理,通过从潜在空间中的布朗过程中采样生成句子级别的计划,然后以该高级计划为条件生成标记级别的语言(图 2)。
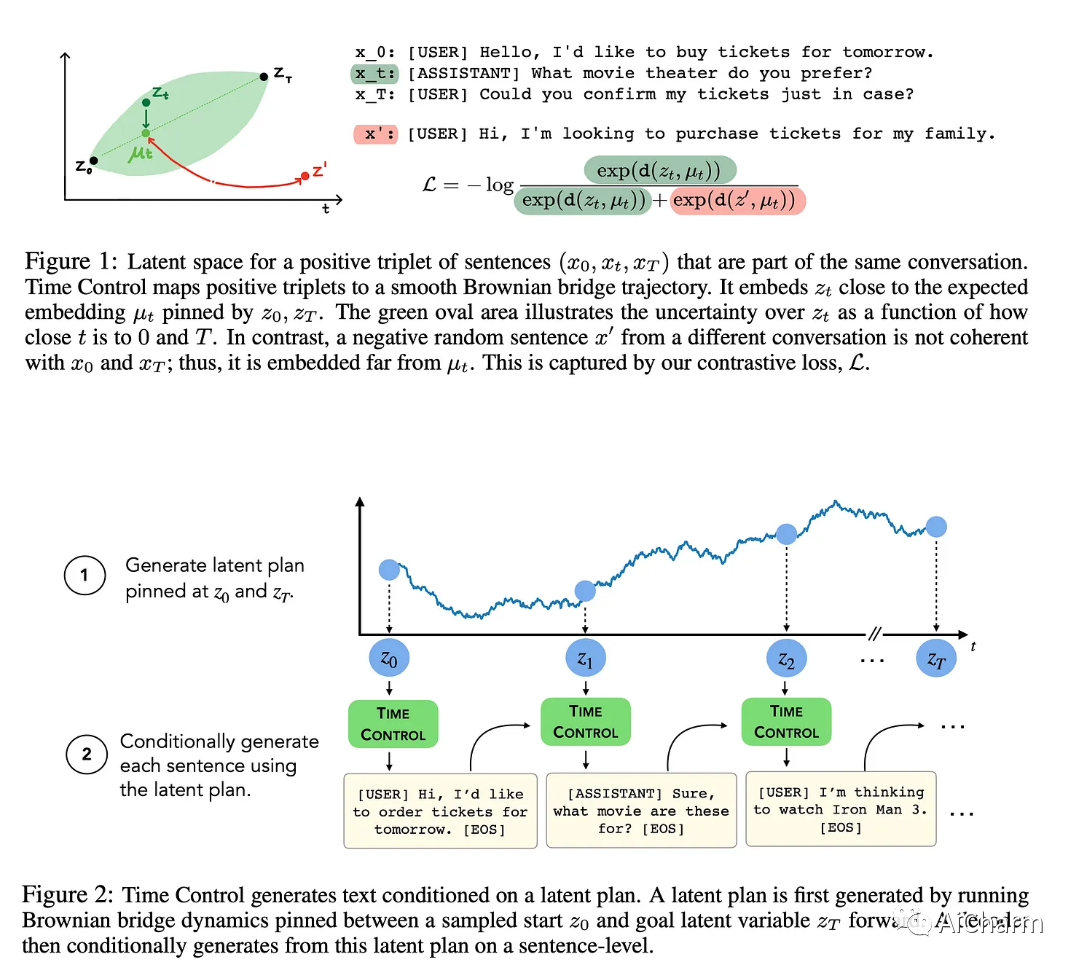
结果非常有趣,尤其是在话语连贯性准确性方面,时间控制是其中的亮点。这项工作提出了一个有前途的方向,可以让 LM 克服经典限制,而无需进入万亿参数尺度体系。
8. Coordination Among Neural Modules Through Shared Global Workspace
标题: 通过共享的全局工作空间协调神经模块
作者:Anirudh Goyal、Aniket Didolkar、Alex Lamb、Kartikeya Badola
文章链接:https://openreview.net/forum?id=XzTtHjgPDsT
作者的 TL;DR
不同专家之间的交流使用共享工作空间,允许更高阶的交互。受大脑启发的模块化神经架构正在兴起;尽管他们在流行的计算机视觉或自然语言处理基准测试中缺乏成功,但他们在稳健性、域外泛化甚至学习因果机制方面都显示出可喜的成果。
关键见解
全球工作空间理论 (GWT) 是一种拟议的认知架构,用于解释人类有意识和无意识思维过程的表现方式。它的核心假设之一是存在一个所有专业模块都可以访问的共享工作区,从而实现其他孤立模块之间的一致性。本文概念化了一种神经网络架构,其中一组输入由专家神经网络处理,然后写入共享工作区——一组向量——然后再次广播给专家。这听起来可能比实际情况更奇特。例如,想象一个处理输入序列的 Transformer,您可以将位置操作概念化为专家。共享工作区对允许在共享全局工作区中更新多少更新的隐藏状态施加了一个条件,施加了一定程度的稀疏性,这已被证明可以提高稳健性和域外泛化。
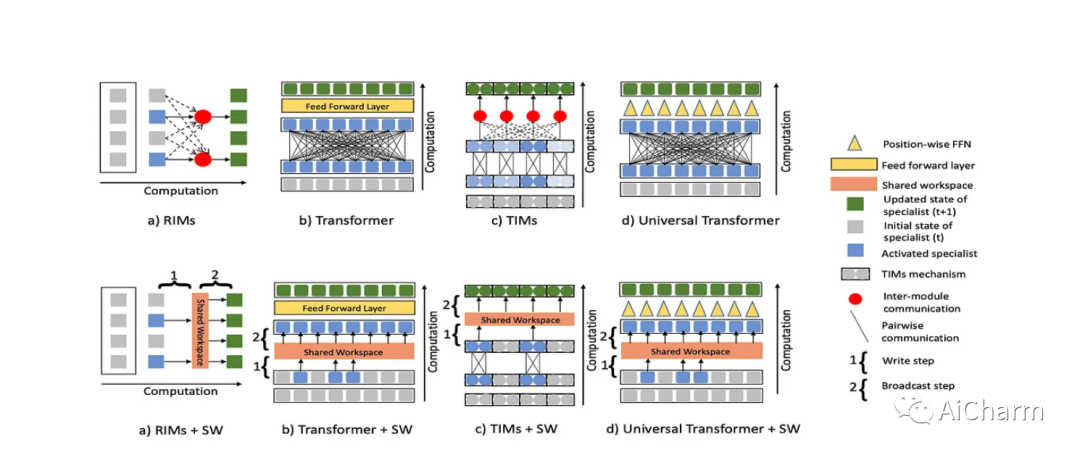
与这类作品一样,它们在不太流行的任务和评估模式上表现良好,但在域内评估方面不会优于单体网络,因此它们不会成为许多头条新闻。不过,这是一个非常有趣的工作线,值得关注。
9. Learning Fast, Learning Slow: A General Continual Learning Method based on Complementary Learning System
标题: 学快,学慢:一种基于互补学习系统的通用持续学习方法
作者:Elahe Arani、Fahad Sarfraz 和 Bahram Zonooz
文章链接:https://openreview.net/forum?id=uxxFrDwrE7Y
作者的 TL;DR
一种双重记忆体验重播方法,旨在模仿快速学习和慢速学习机制之间的相互作用,以在 DNN 中实现有效的 CL。丹尼尔·卡尼曼 (Daniel Kahneman) 推广的人类思维模式的二分法——快和慢——是人类思维方式的核心。本文从这个想法中汲取灵感,构建了一个利用快速和慢速学习来改进持续学习的架构。
关键见解
持续学习是一种让模型通过将其暴露于新数据或与动态环境交互来逐渐扩展其知识的方法。举个例子,考虑一个模型,它最初只学习用 0 到 7 的数字对图像进行分类,然后被教导识别数字 8 和 9,而不会忘记前面的数字。目标是能够利用现有知识更有效地学习新事物,就像人类一样。为此,本文提出了一种针对 2 个时间尺度的记忆体验重放系统:长时间和短时间。主要创新之一是语义记忆的使用:两个神经网络代表可塑性和稳定模型。为了实现快速和短期学习,稳定模型由快速模型的指数移动平均值组成:这使得两个模型具有一致的权重,但稳定模型的演化比塑料模型更慢、更平滑,塑料模型对变化更敏感最新数据。该技术已用于其他设置,例如 BYOL⁵ 等对比学习。储存库充当情景记忆,保留数据流样本,从而减轻灾难性遗忘。
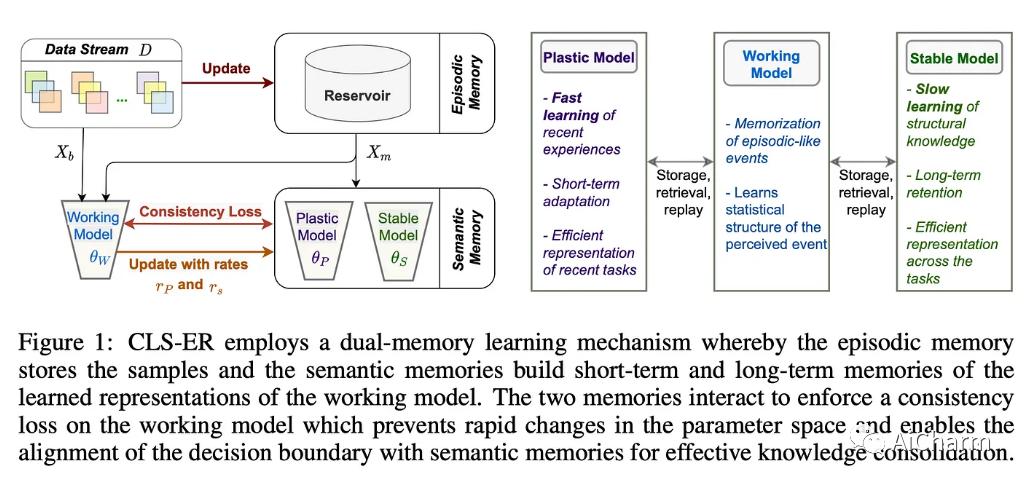
实验在 3 个任务上表现出色:
-
类增量学习:在分类设置中逐渐添加新类。
-
域增量学习:在不添加新类的情况下引入数据的分布变化。
-
一般增量学习:将模型暴露给新类实例和数据的快速分布,例如 MNIST 分类任务中的旋转数字。
10. Autonomous Reinforcement Learning: Formalism and Benchmarking
标题: 自主强化学习:形式主义和基准测试
作者:Archit Sharma、Kelvin Xu、Nikhil Sardana、Abhishek Gupta
文章链接:https://openreview.net/forum?id=nkaba3ND7B5
作者的 TL;DR
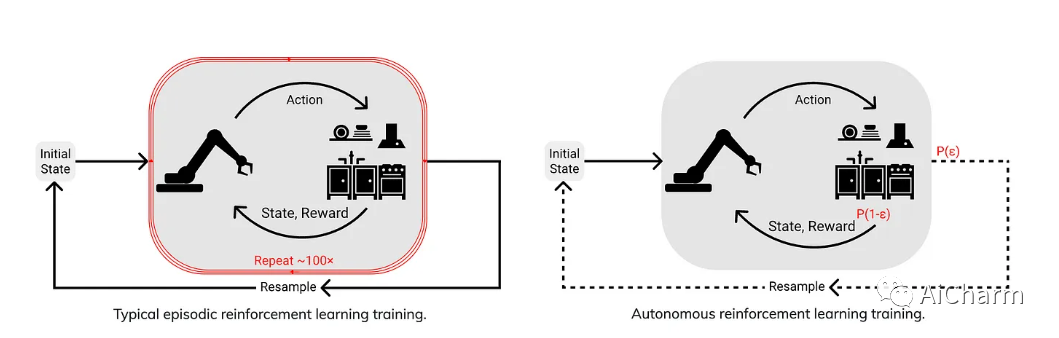
大多数 RL 基准测试都是偶发的:代理通过在每次代理失败时完全重新启动的环境中执行任务来学习。人类很少在这种情况下学习:当我们重新尝试做某事时,环境不会重新启动!如果机器人注定要出现在现实世界中,为什么我们仍然在情景基准测试中评估大多数 RL 算法?
关键见解
这项工作提出了一个专注于非情景强化学习的基准,作者将其称为自主强化学习环境 (EARL),希望它与现实世界相似。从技术上讲,EARL 是良好的旧 RL 的一个子集,其中环境随着代理与其交互而不断发展,而不是在每一集结束时重置。然而,这在实践中很少完成,因此这项工作通过建立形式主义(例如,学习代理、环境、奖励、政策评估、干预等概念的定义和数学公式)奠定了基础。您可以在他们的项目页面上找到这项工作的概述,并且已经开始使用基准通过从 GitHub 克隆基准存储库来评估您的算法。
更多Ai资讯:公主号AiCharm