RAID
- DSL : Domain Spesic Language 专用领域语言
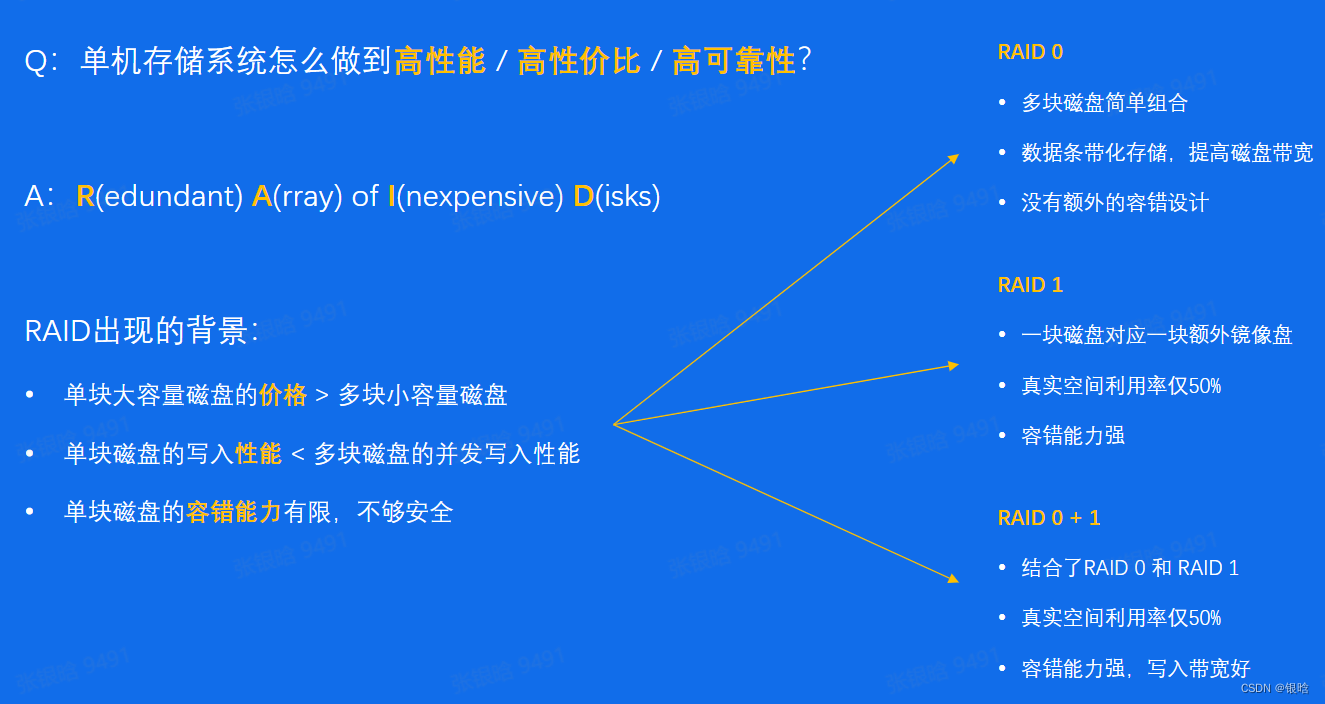
单机存储
- 一切皆Key-Value
本地文件系统
- 一切皆文件

Ceph - 分布式存储
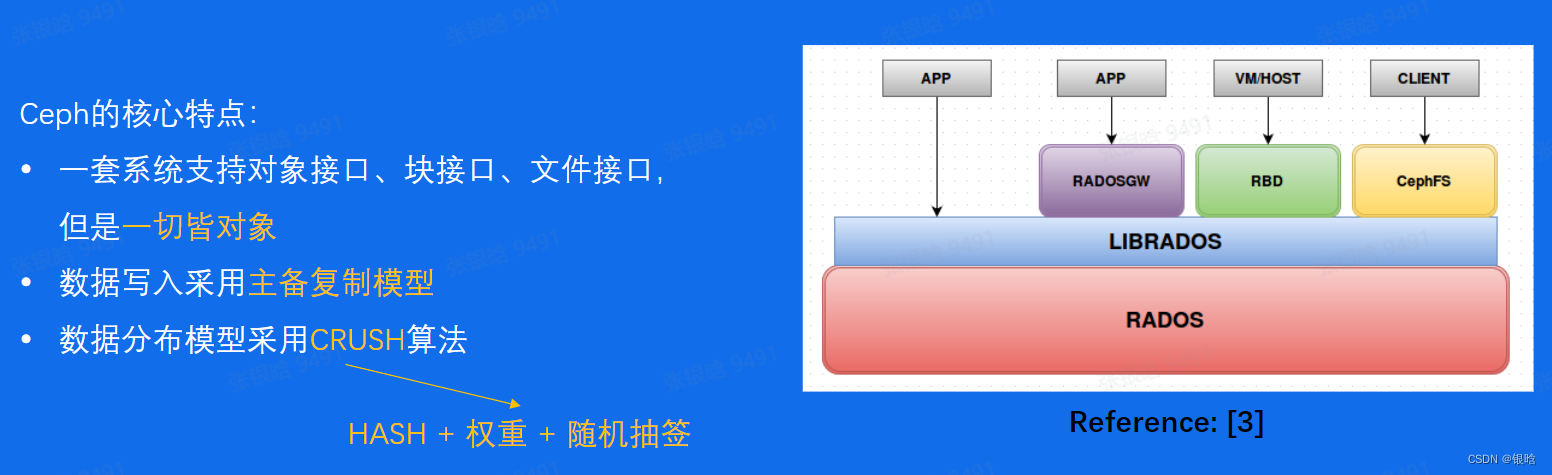
关系型数据库通用组件
- Query Engine :解析query,生成查询计划
- Txn Manager :事务并发管理
- Lock Manager :锁相关的策略
- Storage Manager :组织内存 / 磁盘数据结构
- Replication :主从同步
- 内存结构: B-Tree 、B±Tree 、LRU List
- 磁盘数据结构:WriteAheadLog(ReadLog)、Page
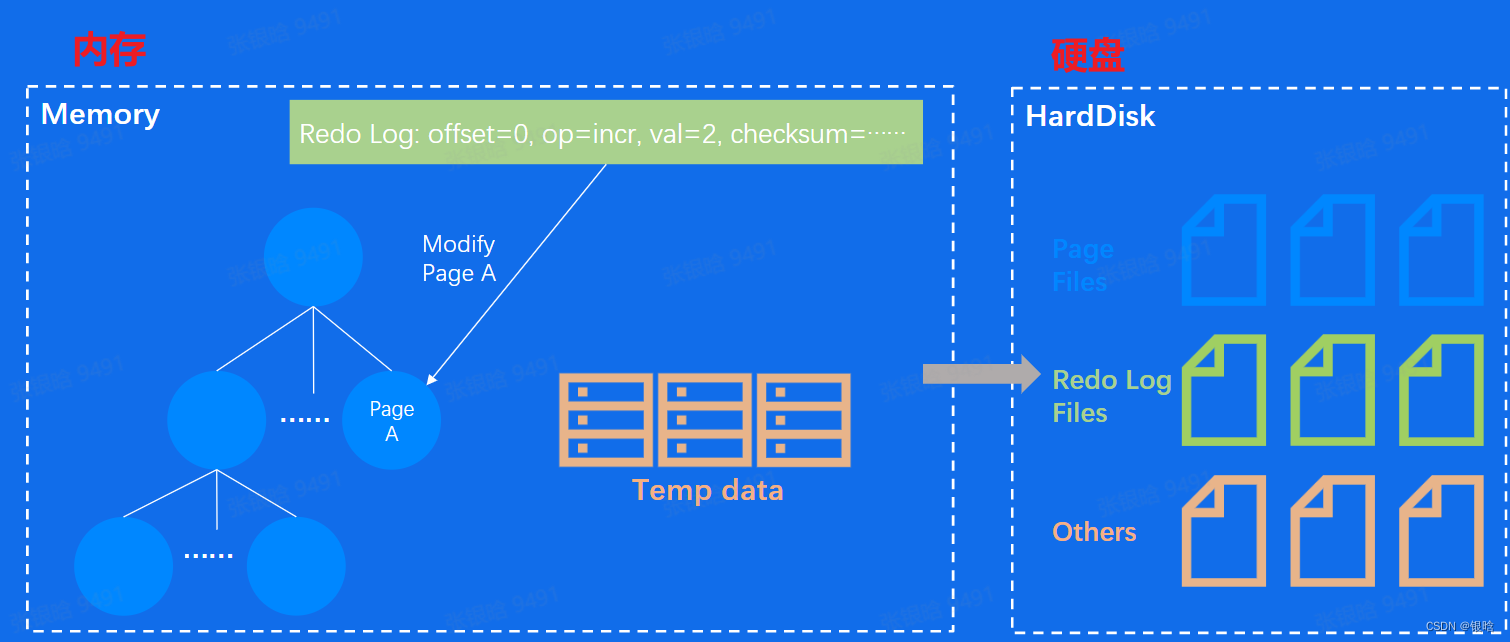
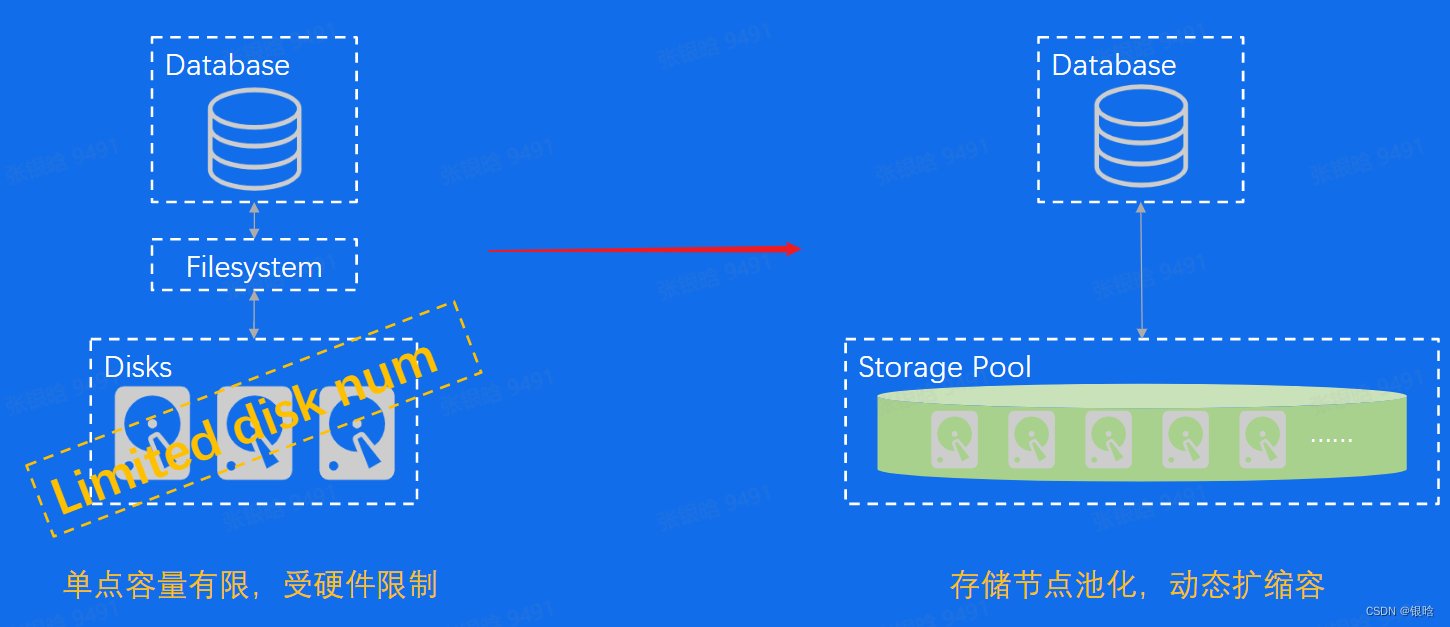
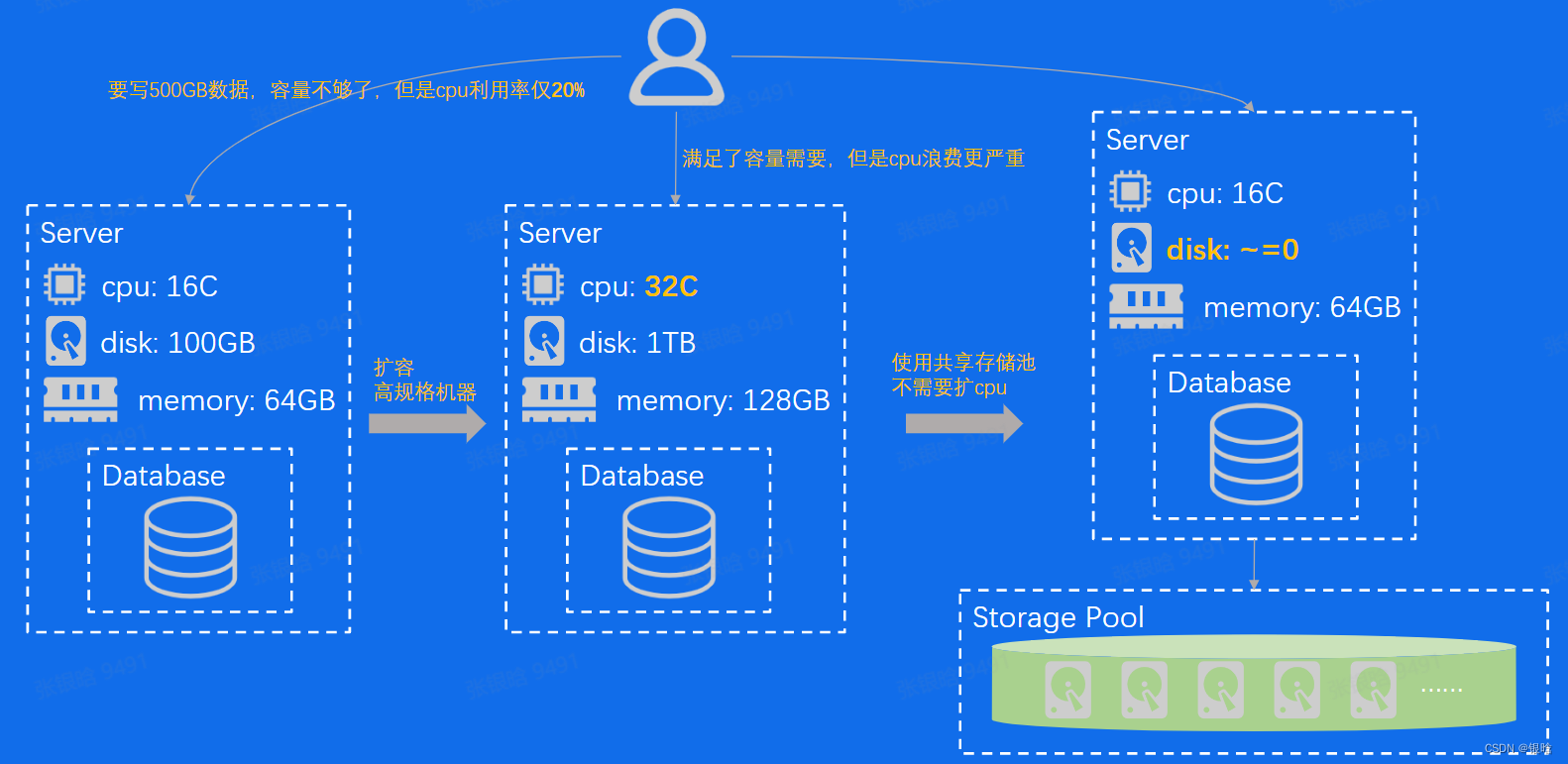
分布式存储之容量问题
分布式存储之弹性问题
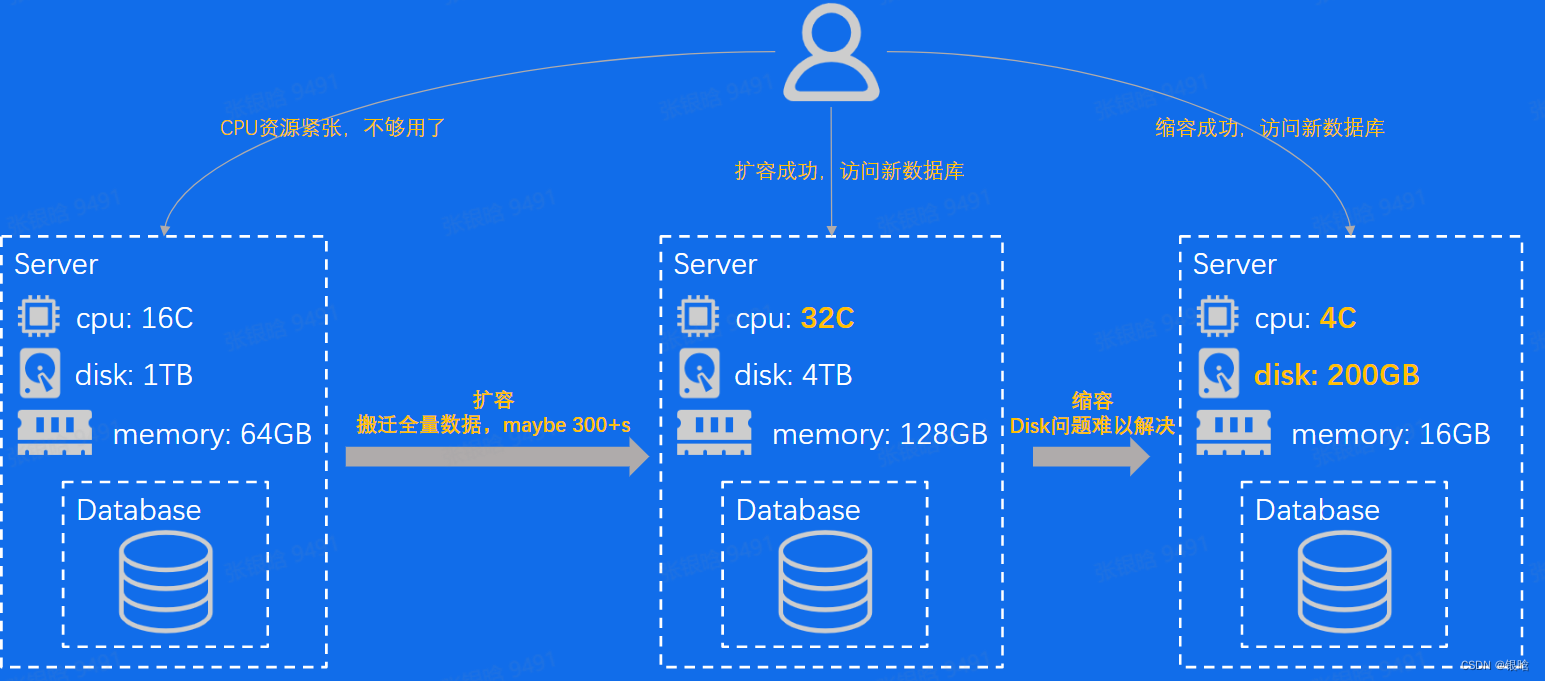
- 性价比优化:
SQL
一条SQL的一生:
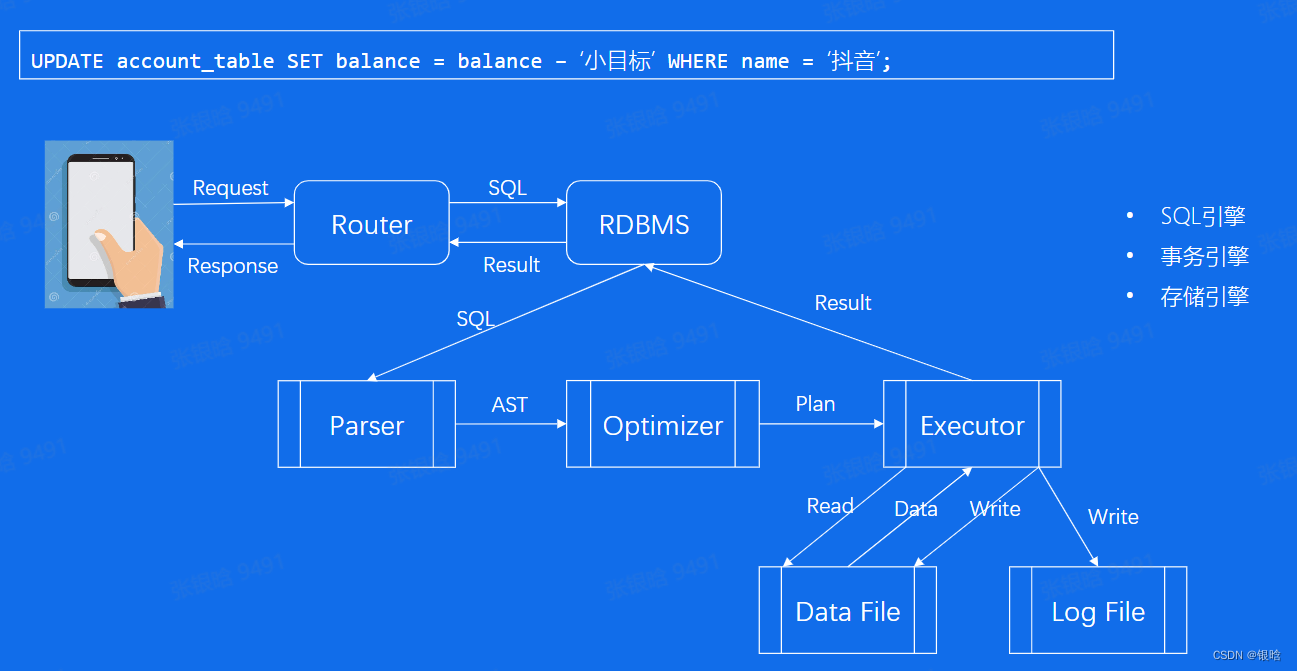
- 查询解析 : 将文本解析成结构化数据,即AST
- 查询优化: 优化器,根据AST生成最优的执行计划
- 查询执行
- 事务引擎:处理事务ACID
- 存储引擎:内存中的数据缓存文件、日志文件等
SQL引擎 – 规则引擎
词法分析 -> 语法分析 -> 语义分析

Optimizer
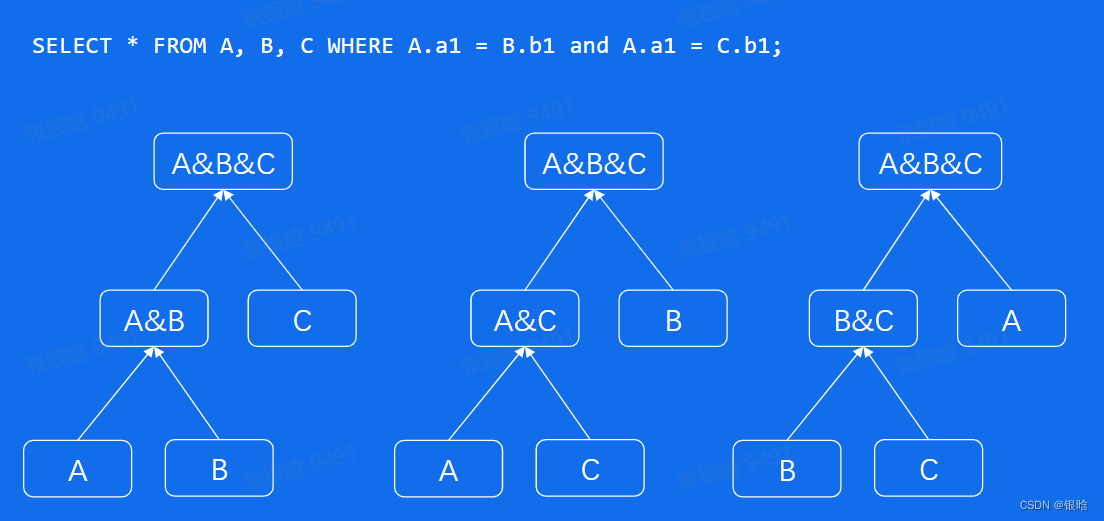
条件化简 & 表连接优化 & Scan优化

代价优化
火山引擎
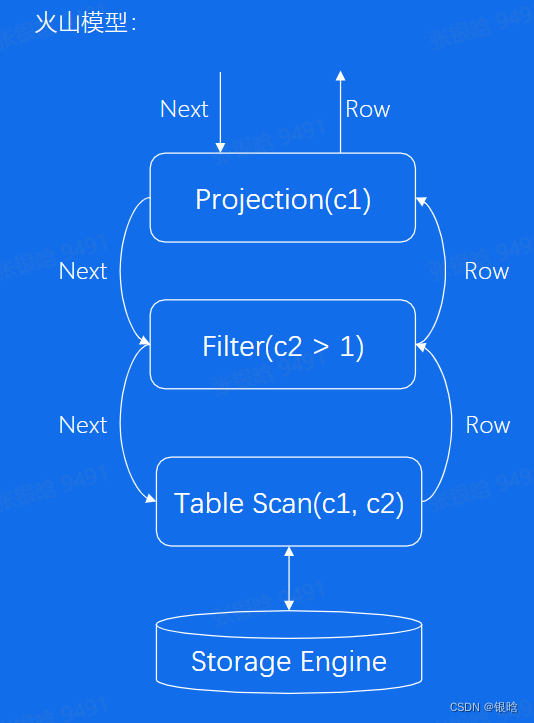
梯次链式调用:解耦
一层一层的解析计数,计数返回递归返回
每个算子独立计算,相互之间没有耦合,逻辑结构简单
每一条数据要调用多个函数,CPU开销很大
-
把Row优化成Batch, 批量计算
-
把执行函数封装到一个函数里面
InnoDB
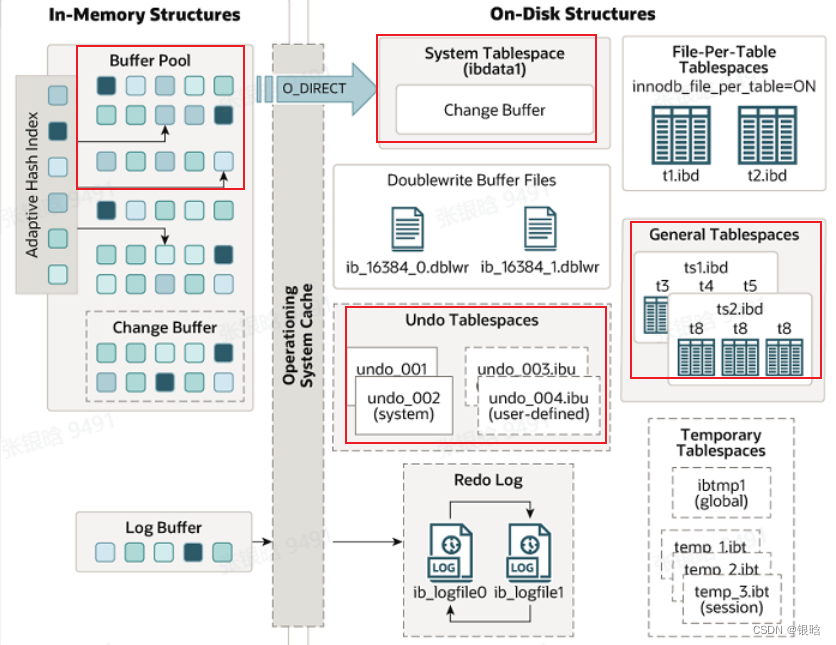
-
mysql中每个chunk的大小一般为128M,每个block对应一个page,一个chunk下面有8192个block
-
避免内存碎片化
-
分成多个instance,可以有效避免并发冲突
-
hash:
page id % instance num 得到它属于哪个instance -
通过page id 去找 block
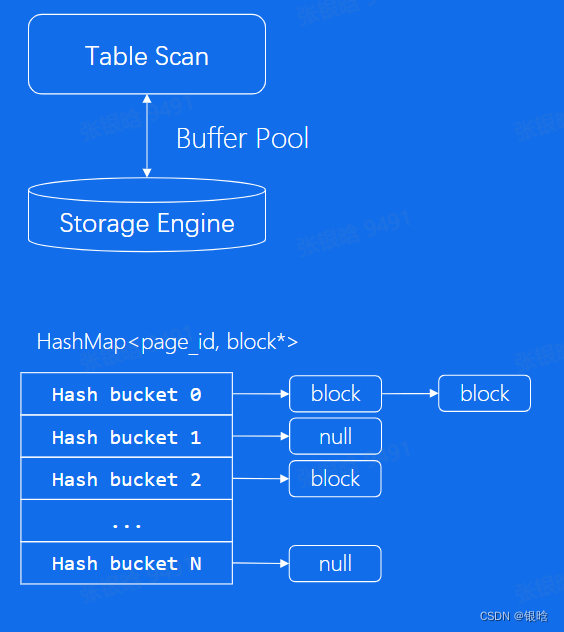
LRU算法:把最近最常用的数据保留下来
-
缺陷:
扫描100G的表,而我们的buffer pool只有1G,因为扫描全表的数据量大,需要淘汰的缓存页多,导致在淘汰过程中,很有可能把需要的缓存页给淘汰了,新数据是低频的 -
解决:
冷热分离- LRU链表分为两部分,一部分冷数据(刚从磁盘读进来的数据),一部分热数据(经常访问的数据)。
- 从磁盘读取的数据先放到冷数据表的头部,如果它1s后被访问,此页数据移动到热数据表的头部;否则不动
- 淘汰时,先淘汰冷数据区
Page
- 一个page大概16Kb左右
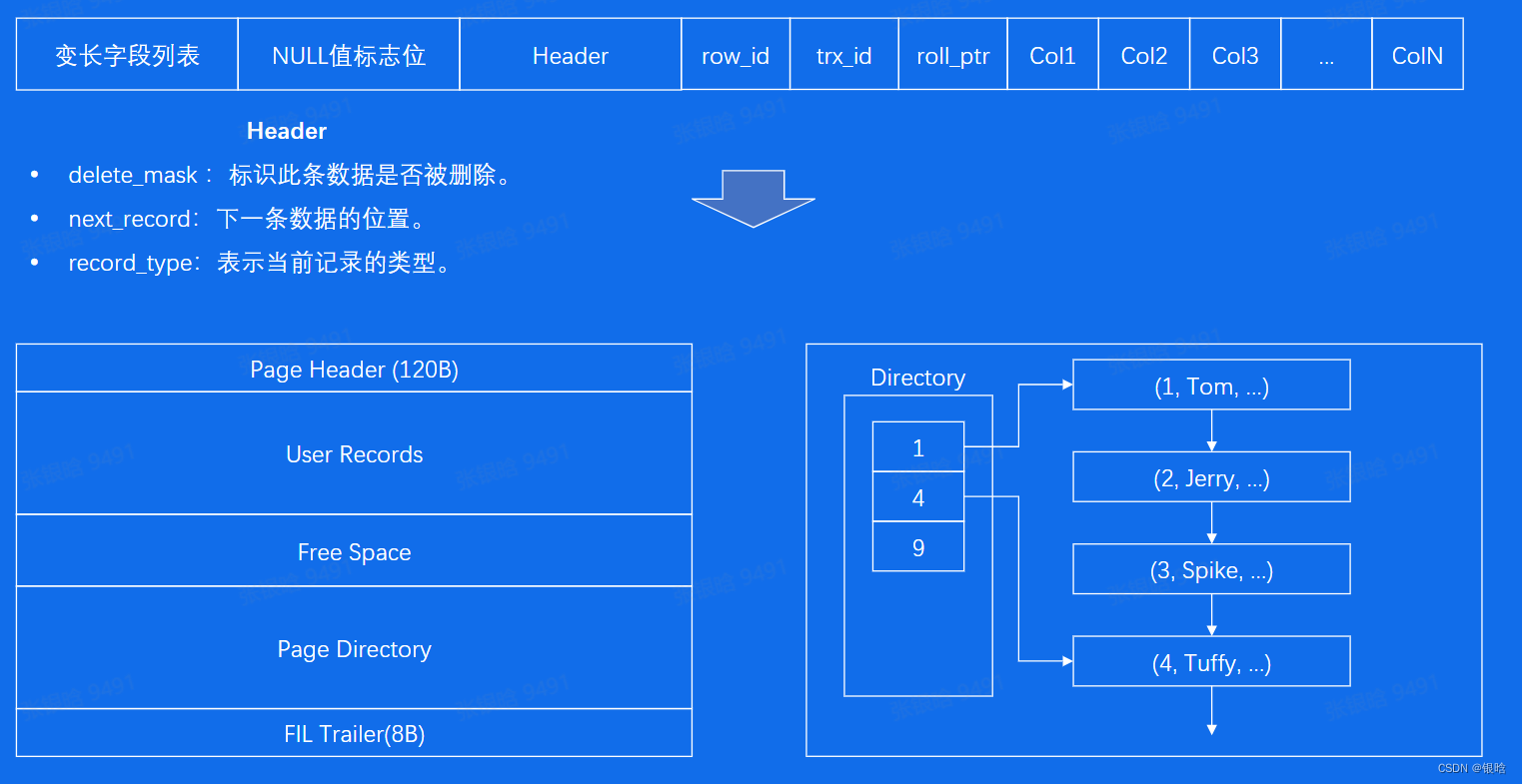
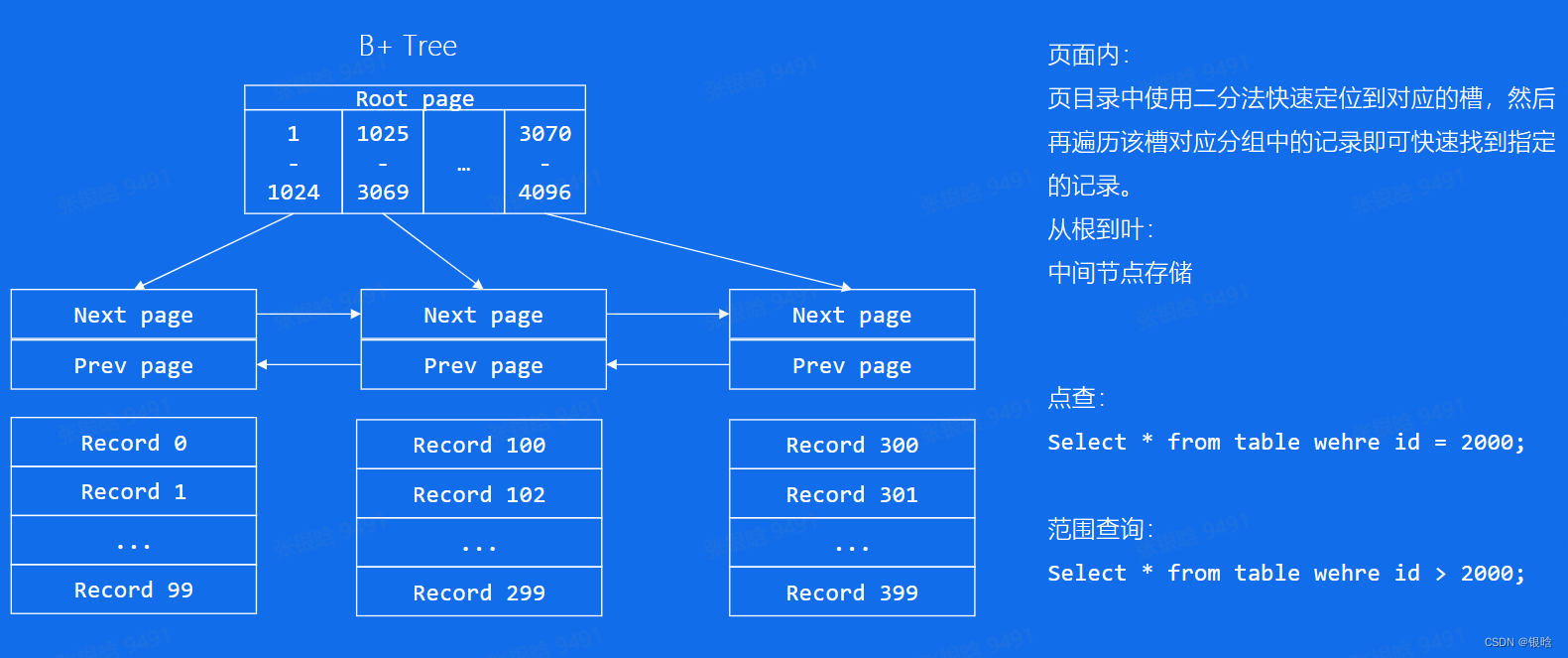
B+树索引
数据库的回滚 - Undo

-
undo是逻辑日志,记录的是数据的增量变化,保证事务的原子性和事务并发控制。
- 可以适用于多版本控制MVCC,解决读写冲突和一致性的问题
-
MVCC的作用:
- 读写互不阻塞
- 降低死锁概率
- 实现一致性读
-
Undo Log 在MVCC的作用
- 每个事务有一个单增的事务ID
- DB_ROLL_PTR 将数据行的所有快照记录通过链表的结构串联起来
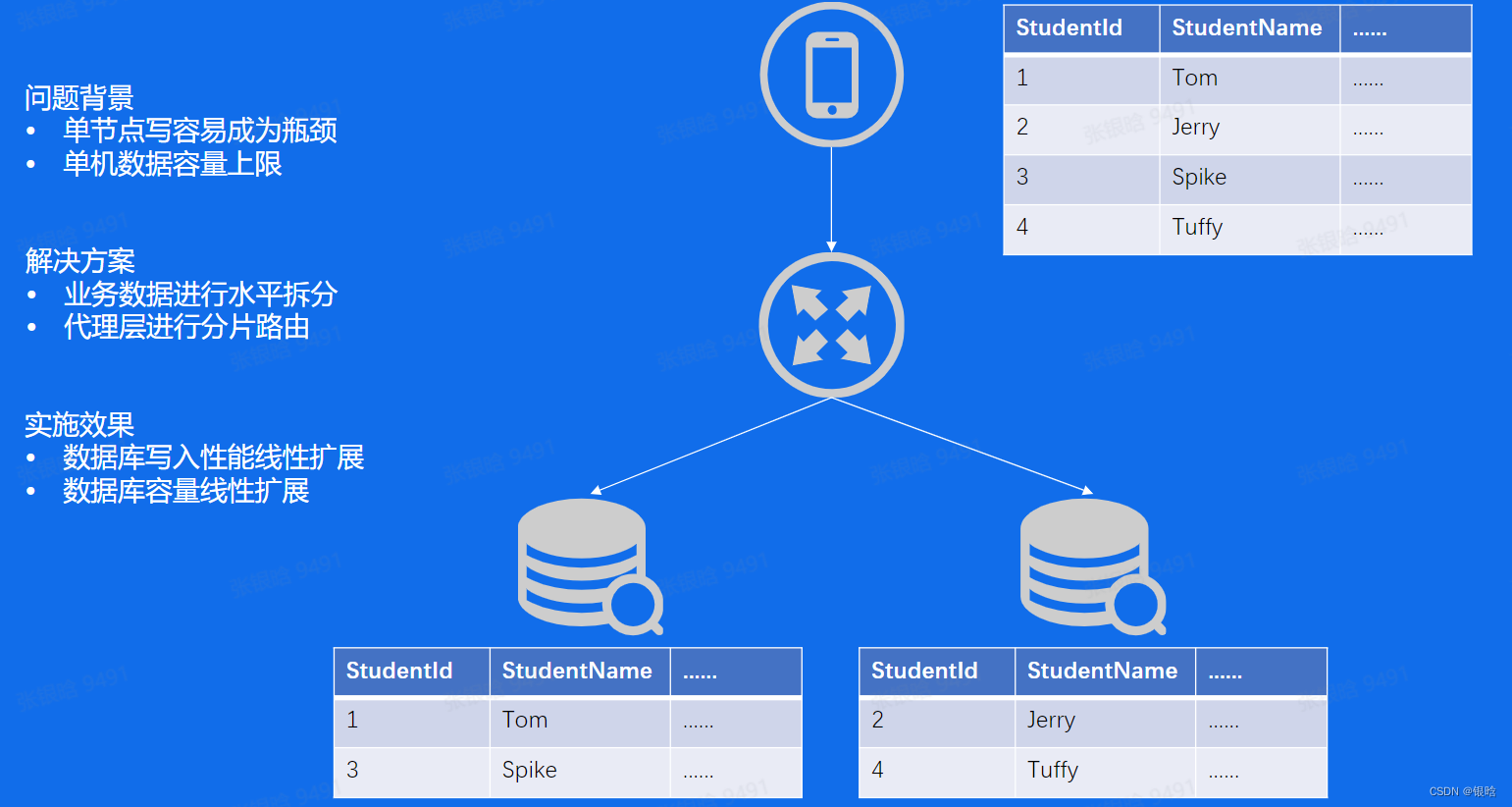
Sharding - 分库分表
- 解决大流量问题
- 业务层进行水平拆分(Hash拆分)
流量突增 - 扩容
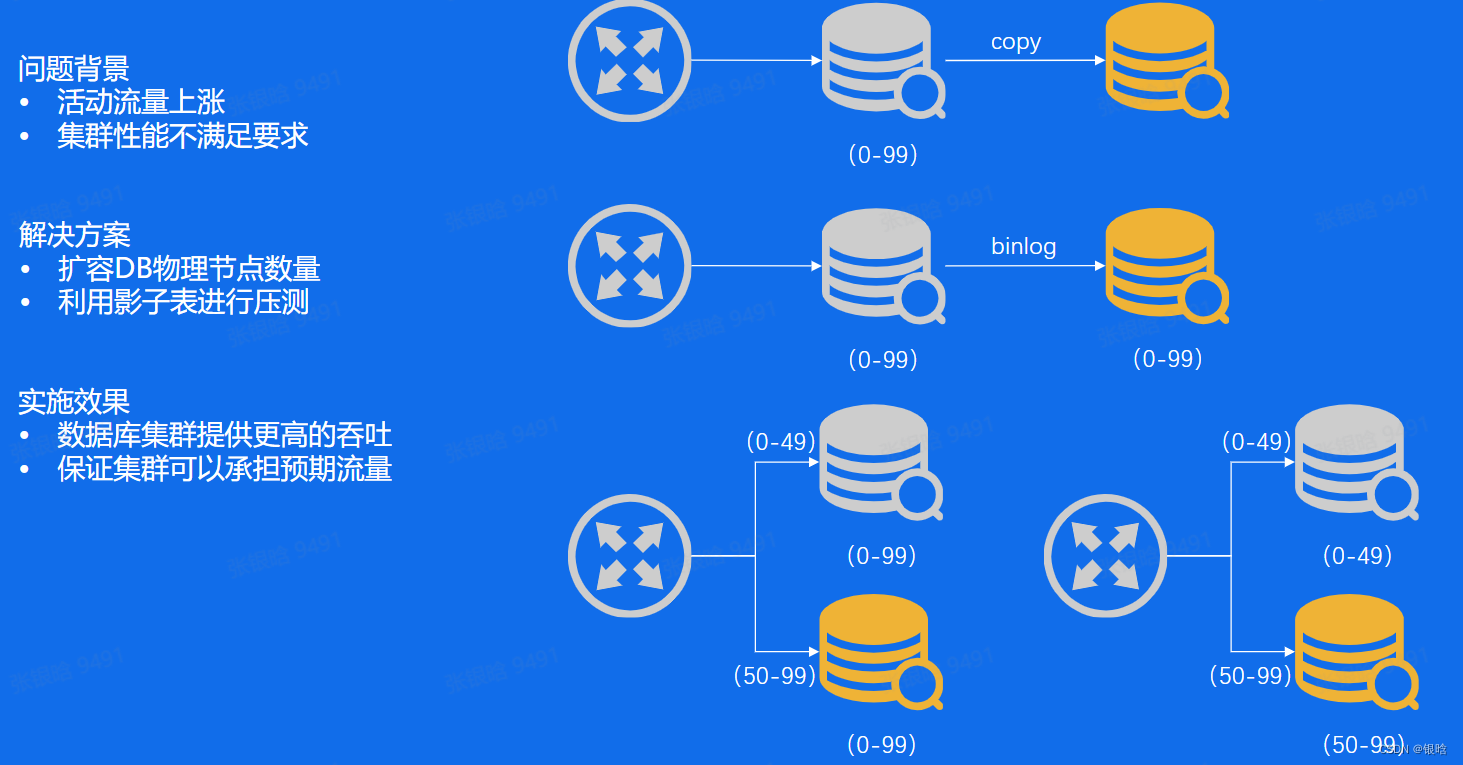
流量突增 - 代理池
- 连接太多了,Proxy就相当于连接的缓存

高可用 & 稳定性
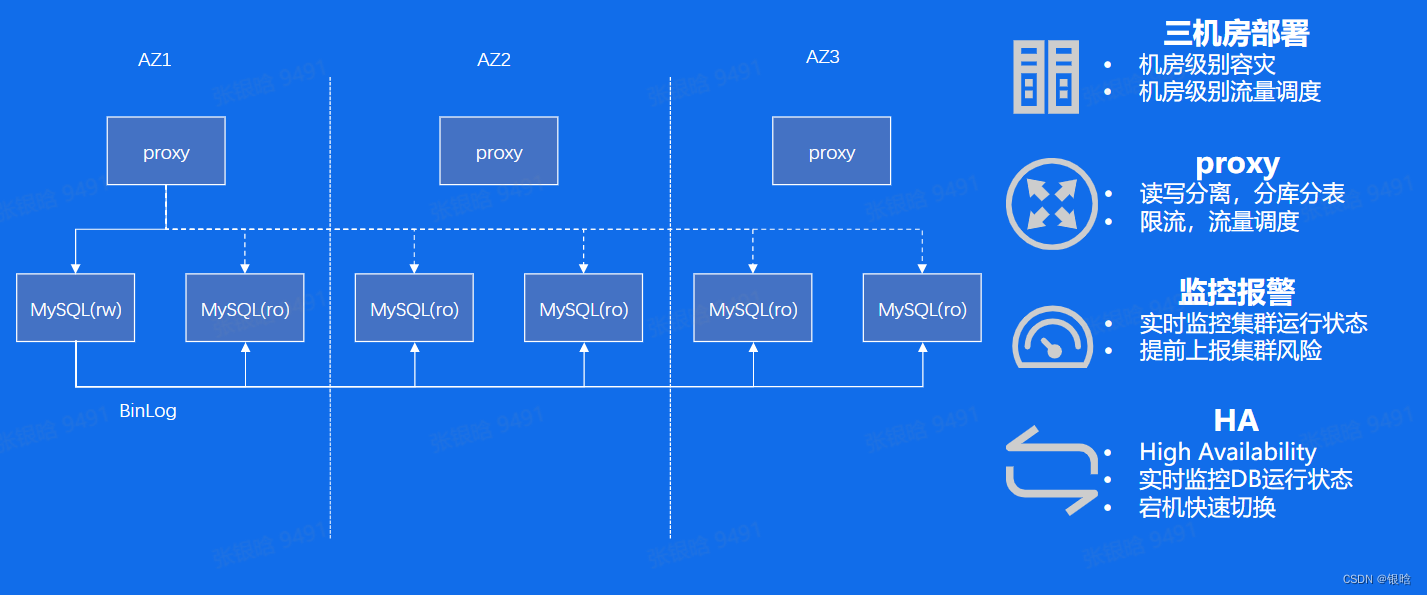
- Binlog :是mysql用来记录数据结构变更以及表数据修改的二进制日志,只会记录了表的变更操作,但是不会记录select和show这种查询操作
- 数据恢复: 误删数据之后可以勇敢binilog来恢复数据
- 主从复制:主库把binlog传给从库,读取binlog然后写数据,就能保证数据一致性
- 审计:对二进制日志进行分析,判断是否对数据库进行注入功击
列式存储
数据存储要考虑一下问题:
并发处理
建立索引表
行存、列存、行列混合
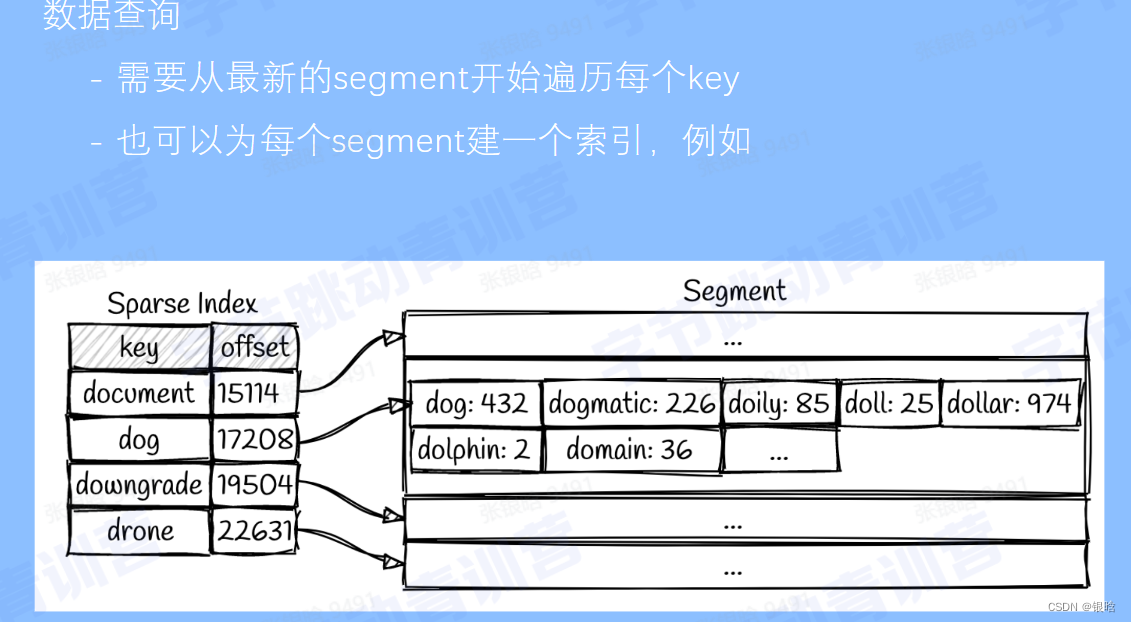
数据查询:
读多写少
读少写多
分析型查询
点查模式
数据压缩
LZ4: 压缩重复项
- 向前5个,重复4项

Run-length encoding:
- 重复数据直接压缩

差值encoding:

延迟物化
将列数据转换为可以被计算或者输出的行数据或者内存数据结果的过程,物化后的数据通常可以被用来做数据过滤
- 推迟物化的发生
- 直接在压缩列上做计算
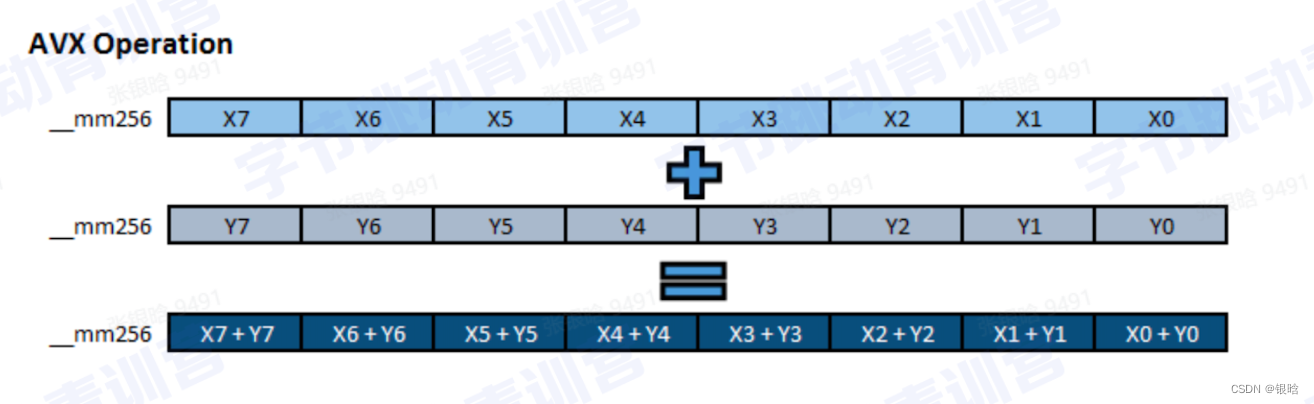
向量化
SIMD:现代化多核CPU,一条指令执行多条数据(批处理)
用SIMD指令完成的代码设计和执行的逻辑就叫做向量化
索引表
- B tree :数据写入有序,叶子左小右大
- B + tree: 叶子节点索引维护,key二分查找
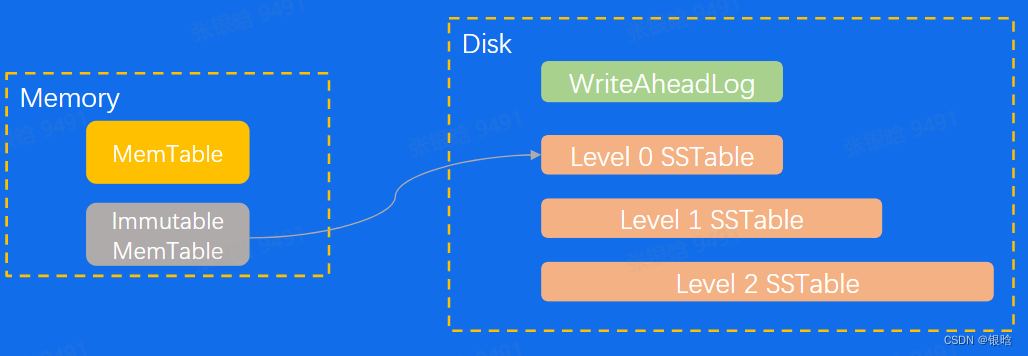
- LSM-tree: Log structrual tree 大吞吐量写入场景的数据结构
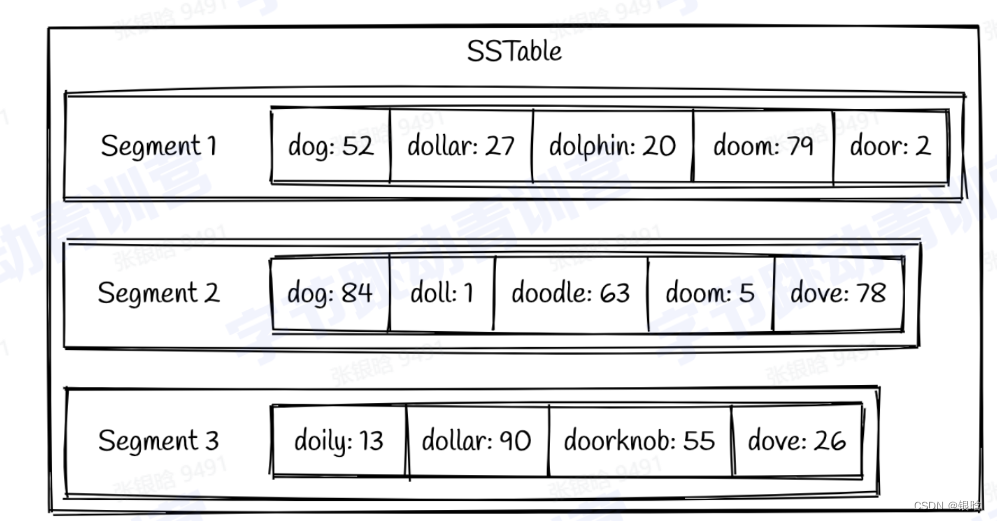
SSTable
- key顺序存储,成为segment
- 单表多个segement
- segemnt写入磁盘不可更改,新加的数据只能生成新segement
Mentable
- 在内存中的数据保存在memtable中,大多数实现都是一颗Binary search tree
- 当memtable存储的数据到达一定的阈值的时候,就会按顺序写入到磁盘