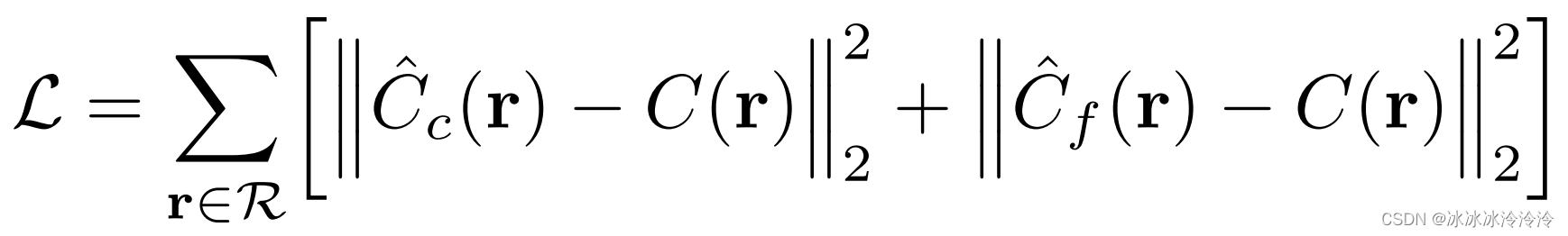题目描述
分析:
字符串 hash 小试牛刀
我们在之前模拟散列时,设置的哈希函数为将一个元素(element, e)输入哈希函数中,输出是一个整数,而那时的
e
e
e 为一个有范围的整数。现在我们考虑更复杂的情形,
e
e
e 为一个字符串,为了区分,记为
E
E
E,字符串哈希函数就是将一个字符串
E
E
E 映射为一个整数,使得该整数可以尽可能地代表一个字符串
E
E
E。
假设字符串
E
E
E 由大写字母
A
−
Z
A-Z
A−Z 和小写字母
a
−
z
a-z
a−z 构成,在这个基础上,我们可以对字母进行编码:
A
−
Z
A-Z
A−Z 为
1
−
26
1-26
1−26,
a
−
z
a-z
a−z 为
27
−
52
27-52
27−52,这样就把大小写字母对应到了五十三进制中。接着,按照将五十三进制转换为十进制的思路,由进制转换的结论可知,在进制转换中,得到的十进制是唯一的,由此便可将字符串映射成整数的需求。这里转换成的整数最大为
5
3
l
e
n
g
t
h
−
1
53^{length}-1
53length−1(进制转换的基本性质),
l
e
n
g
t
h
length
length 为字符串的长度。实现代码如下:
// 哈希函数 h() 本质即为进制转化
int h(char* E)
{
int ans = 0;
for (int i = 0; E[i]; i ++)
{
if (E[i] >= 'A' && E[i] <= 'Z') ans = ans * 53 + (E[i] - 'A');
else if (E[i] >= 'a' && E[i] <= 'z') ans = ans * 53 + (E[i] - 'a') + 26;
}
return ans;
}
假设字符串为"BCDE",进行哈希映射后得到的整数为 5 ∗ 5 3 0 + 4 ∗ 5 3 1 + 3 ∗ 5 3 2 + 2 ∗ 5 3 3 5*53^0+4*53^1+3*53^2+2*53^3 5∗530+4∗531+3∗532+2∗533。从代码和样例中可以看出为什么我们在之前将 A − Z A-Z A−Z 设为 1 − 26 1-26 1−26 而不是 0 − 25 0-25 0−25,这是因为如果 “A” 为 0 0 0,那么 “AA”、“AAA” 都为 0 0 0 了。
字符串 hash 进阶
对于上面的分析,我们可以总结出一个更系统的式子:
S
[
i
]
=
S
[
i
−
1
]
∗
p
+
E
[
i
]
S[i]=S[i-1]*p+E[i]
S[i]=S[i−1]∗p+E[i]
其中
p
p
p 为我们所采取的进制,
E
[
i
]
E[i]
E[i] 表示字符串的第
i
i
i 位是什么,
S
[
i
]
S[i]
S[i] 表示字符串的前
i
i
i 个字符的子串的 hash 值。这样,当
i
i
i 取遍
1
−
l
e
n
g
t
h
1-length
1−length 后,
S
[
l
e
n
g
t
h
]
S[length]
S[length] 就是整个字符串的哈希值,而其他位置保存了部分字串的 hash 值。注意这里没有了
c
o
n
v
e
r
t
(
)
convert()
convert() 函数,因为我们打算直接是用字符串字符的 ASCII 码 ,因此
p
p
p 进制的选择就扑朔迷离了。
在转换过程中,字符串与整数是一一对应的,但由于没有适当的处理,当字符串字符较长时,产生的数会非常大,没办法用一般的数据类型存储。因此,按照之前对哈希的理解,要进行取模,即:
S
[
i
]
=
(
S
[
i
−
1
]
∗
p
+
E
[
i
]
)
%
k
S[i]=(S[i-1]*p+E[i])\%k
S[i]=(S[i−1]∗p+E[i])%k
通过这种方式可以把字符串转换成范围上能接受的整数。但这可能又产生另外的问题,也就是 hash值产生冲突。而根据y总的经验值,
p
p
p 取
133
133
133 或
13331
13331
13331,
k
k
k 取
2
64
2^{64}
264,在
99.99
%
99.99\%
99.99% 的情况下是不会产生冲突的。因此这和普通哈希是有区别的,普通哈希是可以处理冲突的,而字符串哈希是不考虑冲突的(无法解决?)
子串的 hash值
考虑求解子串的 hash值,也就是求解
S
[
l
.
.
.
r
]
S[l...r]
S[l...r]。由于上面介绍的取模运算在括号最外层,而我们接下来需要考虑括号内的问题,所以先暂时把取模运算放在一边,简化讨论。即:
S
[
i
]
=
(
S
[
i
−
1
]
∗
p
+
E
[
i
]
)
S[i]=(S[i-1]*p+E[i])
S[i]=(S[i−1]∗p+E[i])
子串的 hash值,
S
[
l
.
.
.
r
]
S[l...r]
S[l...r] 实际上等于把字符串
E
[
l
.
.
.
r
]
E[l...r]
E[l...r] 从
p
p
p 进制转换为十进制,也就是如下式子所表示的:
S
[
l
.
.
.
r
]
=
E
[
l
]
∗
p
r
−
l
+
E
[
l
+
1
]
∗
p
r
−
l
−
1
+
.
.
.
+
E
[
r
]
∗
p
0
S[l...r]=E[l]*p^{r-l}+E[l+1]*p^{r-l-1}+...+E[r]*p^0
S[l...r]=E[l]∗pr−l+E[l+1]∗pr−l−1+...+E[r]∗p0
看到这个式子有没有觉得头大呢?没关系,这是很正常的,因为它有许多的参数需要理清,先看一个实例:

上面的
S
[
l
.
.
.
r
]
S[l...r]
S[l...r] 的公式可以通过
S
[
j
]
S[j]
S[j] 推导出:
S
[
r
]
=
S
[
r
−
1
]
∗
p
+
E
[
r
]
S[r]=S[r-1]*p+E[r]
S[r]=S[r−1]∗p+E[r]
=
(
S
[
r
−
2
]
∗
p
+
E
[
r
−
1
]
)
∗
p
+
E
[
r
]
\qquad =(S[r-2]*p+E[r-1])*p+E[r]
=(S[r−2]∗p+E[r−1])∗p+E[r]
=
S
[
r
−
2
]
∗
p
2
+
E
[
r
−
1
]
∗
p
+
E
[
r
]
\qquad =S[r-2]*p^2+E[r-1]*p+E[r]
=S[r−2]∗p2+E[r−1]∗p+E[r]
=
.
.
.
\qquad = ...
=...
=
S
[
l
−
1
]
∗
p
r
−
l
+
1
+
E
[
l
]
∗
p
r
−
l
+
.
.
.
+
E
[
r
]
∗
p
0
\qquad = S[l-1]*p^{r-l+1}+E[l]*p^{r-l}+...+E[r]*p^0
=S[l−1]∗pr−l+1+E[l]∗pr−l+...+E[r]∗p0
=
S
[
l
−
1
]
∗
p
r
−
l
+
1
+
S
[
l
.
.
.
r
]
\qquad = S[l-1]*p^{r-l+1}+S[l...r]
=S[l−1]∗pr−l+1+S[l...r]
移项可以得到:
S
[
l
.
.
.
r
]
=
S
[
r
]
−
S
[
l
−
1
]
∗
p
r
−
l
+
1
S[l...r]=S[r]-S[l-1]*p^{r-l+1}
S[l...r]=S[r]−S[l−1]∗pr−l+1
于是就得到了子串
E
[
i
.
.
.
j
]
E[i...j]
E[i...j] 的 hash值
S
[
i
.
.
.
j
]
S[i...j]
S[i...j],加上原来的取模操作可以得到:
S
[
l
.
.
.
r
]
=
(
S
[
r
]
−
S
[
l
−
1
]
∗
p
r
−
l
+
1
)
%
k
S[l...r]=(S[r]-S[l-1]*p^{r-l+1})\%k
S[l...r]=(S[r]−S[l−1]∗pr−l+1)%k
由于C++有 unsigned long long(ULL) 类型表示范围为
[
0
,
2
64
−
1
]
[0,2^{64}-1]
[0,264−1],因此当需要对
2
64
2^{64}
264 取模时,可以用 ULL 类型存储该数,当出现溢出时就相当于进行了取模运算。
代码(C++)
#include <iostream>
using namespace std;
typedef unsigned long long ULL;
const int N = 100010, P = 131;
char E[N];
// POW 数组进行提前打表操作,i 中记录了 p^i
ULL H[N], POW[N];
//返回值为 ULL,相当于进行了取模运算
ULL subhash(int l, int r)
{
// P 的 r-l+1 次幂,存储在对应下标中
return H[r] - H[l - 1] * POW[r - l + 1];
}
int main()
{
int n, m;
// 对于字符串 E,从下标为 1 的位置读入
scanf("%d%d%s", &n, &m, E + 1);
POW[0] = 1;
for (int i = 1; i <= n; i ++)
{
// H[i] 表示字符串前 i 个字符的子串 hash值
H[i] = H[i - 1] * P + E[i];
// 打表幂运算
POW[i] = POW[i - 1] * P;
}
while (m --)
{
int l1, r1, l2, r2;
scanf("%d%d%d%d", &l1, &r1, &l2, &r2);
if (subhash(l1, r1) == subhash(l2, r2)) puts("Yes");
else puts("No");
}
return 0;
}