前言
好吧,现在已经2023年了,对于这本书(第二版)来说可能有点老了,这本书不是很难理解,但也不是很适合新手读,当然,这本书并不是百宝书 📕 ,它更注重于编程的规范与思路、用户的体验、实战演练,并且我在这本书中学到了不少东西,我决定将这些知识分享出来
所以我接下来将分享以下话题的相关点:
- 规范
- 平稳退化(向后兼容)
- 渐进增强
- 着重于用户的体验
- 模块化思想
- 根据需求对原生DOM对象的二次封装
规范
对于编程规范来说,这本书真的让人受益匪浅,在进入DOM学习之前,我对初入DOM的新手同志说一段话:JavaScript和DOM并没有强制的关系,而是使用JavaScript去操作DOM,意思就是DOM对象是浏览器运行时提供的,你可以使用其他浏览器支持的语言去操作DOM对象,同时JavaScript在其他运行时中是不能去操作DOM对象的(因为根本没有DOM对象)比如Node.js,所以这个界限在初入学习DOM时是我们必须要知道的
结构层、样式层、行为层尽量分离
这个规范观点很有趣,也是我在这本书中学到的,之前我只是如同行尸走肉一般的去这样书写,不明白为什么,原来这也是一种规范,同时避免了不必要的报错,我们尽量的去将结构层、样式层、行为层进行分离:
接下来我举一个例子:
// 比如我在HTML超文本语言中去使用行内式JavaScript
<a href="javascript:;">点我</a>
// 我们可能经常去使用伪协议操作a元素,为了让他禁止默认跳转行为
javascript: '伪协议会让我们通过一个链接去调用JavaScript函数,然后里面什么也没有书写,也就是执行了一段空的JavaScript代码并且通过执行JavaScript而拦截了链接默认跳转行为
通过javascript: '伪协议从而调用JavaScript代码的做法是不好的,我们应该尽量做到结构层与行为层的分离
当然还有内嵌式的事件处理函数,我相信大家也不会去这样写,因为不仅没有做到规范,我们程序员自己的也很费劲
<a href="#" onclick="alert('这样做是不好的行为')">点我</a>
有时候这本书令我很’不适’
为什么这样说呢?因为它真的规范的不得了,这本书比较老,所以它对与IE的兼容以及不开启JavaScript功能的用户还是比较关注的
只要有假设的思想,那么它一定会进行一个对象检测,就像这样:
function test() {
if (!document.getElementsByTagName) return false
const links = document.getElementsByTagName("a")
if (links.length !== 0) {
// 执行相对应语句
}
}
test()
所以坚持看完之后,我感觉整个人都升华了,太规范了
平稳退化
平稳退化在本书讲述的时候大多数是基于兼容IE来讲的,因为IE不支持的对象属性有点太多了,如果你的用户刚好用的就是IE,那么你必须要做好万全的准备,也就是所说的平稳退化,如果秉承了平稳退化的原则,那么哪怕在任何浏览器中打开你的网页都不会报错
平稳退化不仅仅适用于JavaScript操作DOM对象来说,它也适用于结构层的显示,我的意思是平稳退化是一种思想,而不是具体的相对的概念,有些内容是不必要的,我们在HTML架构中只是去书写一些必要的信息,那些通过JavaScript创建的元素(不必要信息)如果用户浏览器不支持DOM或者用户压根就关闭了JavaScript功能,它们就不能够呈现,这些内容必须是充分不必要条件,如果不支持,那么不显示的同时也不会报错或者影响用户阅读信息
还有不得不说的一点就是对象检测技术,上面的话题我们提到过了,就是在执行代码之前进行一个 if 判断,判断是否存在该元素、对象或者属性,如果存在该元素、对象或者属性,那么继续执行,如果不存在该元素、对象或者属性,那么 return false 跳出执行
在不支持该对象的情况下,我们退而求其次的呈现出不是那么好的效果,或者说不显示次要内容的情况下不会让网页报错导致不可控的情况
渐进增强
平稳退化、渐进增强这俩点是这本书的绝招
渐进增强基本上说的是围绕一个基本中心点来展开的拓展
也就是说我们需要编写一个所有浏览器都支持的基础版本,这个基础版本可能没有那么的好,但是基本的重要内容都以尽量最好的形式展现出来,在这个基础上我们去编写一些炫酷的、更有趣的并且会增加体验的内容,这些内容会在高版本浏览器中呈现,低版本浏览器则只会显示基本内容,这些不支持的属性,我们会使用上面提到的平稳退化来进行一个兼容与拦截报错
用户体验
我想这是最重要的环节,因为我们的网页最终都是要呈现给用户的,所以我们要以用户体验为中心,在渐进增强的基础上使用平稳退化技术,那么这就是一个较为完美的网页了
这并不容易,我们的用户可能在浏览网页时受到很多的阻碍
- 比如用户的视力不是很好,那么我们在编写HTML属性(比如title、alt…)以及使用DOM创建一些节点元素的时候,就要格外的注意信息的呈现,当然这对网络爬虫也是非常友好的,这很利于SEO,关于SEO的优化,本书没有提到很多
- 或者浏览器版本很低,甚至那时候有的浏览器连DOM都不支持,不过现在应该没有这种情况了,如果一款浏览器在现在还不支持DOM,那么它连出头之日都没有
- 再或者用户关闭了JavaScript功能,那么一些内容就不能呈现在网页中了,这就是我们为什么不把重要内容使用DOM创建出来
- …还有很多的情况,我们需要在每一个开发场景之下,尽量的去预见一些可能会发生的情况,并且在这之前采取一些必要的措施,当然一个程序不可能是绝对完美的,我们也不可能去预见所有的未知错误,我们需要不断的迭代与尽量做好预见措施
模块化思想的强化
这本书讲到的编程思想至少对我来说是受益匪浅的,其中模块化编程更是贯穿了整本书,作者为了我们便于阅读,将每一个功能存放于不同的JavaScript文件中,当然我说的不是这个模块化,我只是顺带提一嘴该书作者的良苦用心,这种一个功能一个JavaScript文件的做法是不提倡的,也是非常不利于用户的,因为100个功能存放在100个JavaScript文件中意味着用户要发起至少100次请求,这很滑稽
作者将每一个功能都封装在了一个函数中,然后在必要的时候去调用该方法,至少在本书中,我没有见到过作者声明全局变量(除了一个个封装完美、等待被调用的函数或者方法),至少这对于我们后期的维护非常友好,并且可以进行复用,避免命名冲突引起的不必要错误,等等…
基于原生DOM对象的二次封装
本书作者为我们提供了四个最基本的封装案例(甚至更多我没有细心发现),至少我觉得这够了,当我们去实现一个功能的时候没有对应的方法可以使用,我们为什么不去基于可用的方法去封装一个全局共享功能函数?
- 封装全局共享 onload 事件
function addLoadEvent(func) {
let oldOnload = window.onload
if (typeof window.onload !== "function") {
window.onload = func
} else {
oldOnload()
func()
}
}
- 基于insertBefore封装一个insertAfter函数用来添加节点到指定节点之后
// 添加节点元素到某一个指定节点元素之后
function insertAfter(newElement, targetElement) {
let parent = targetElement.parentNode
if (parent.lastChild === targetElement) {
parent.appendChild(newElement)
} else {
parent.insertBefore(newElement, targetElement.nextSibling)
}
}
- 基于className方法封装一个addClass函数用来添加类名
function addClass(ele, val) {
if (!ele.className) ele.className = val
ele.className = `${ele.className} ${val}`
}
好吧,我想大家现在都会去使用 element.classList.add() ,这个方法我们可能不会去使用,但是这个思想是值得我们去学习的
- 动画函数的封装
// 请给到动画元素绝对定位属性以及父元素的一个相对定位属性
function moveAnimation(ele, finalX, finalY, interval) {
// 关闭上一次定时器
if (ele.movement) {
clearTimeout(ele.movement)
}
// 预见措施
if (!ele.style.left) {
ele.style.left = "0px"
}
if (!ele.style.top) {
ele.style.top = "0px"
}
let xpos = parseInt(ele.style.left)
let ypos = parseInt(ele.style.top)
let dist
if (xpos === finalX && ypos === finalY) {
return true
}
if (xpos < finalX) {
dist = Math.ceil((finalX - xpos) / 10)
xpos += dist
}
if (xpos > finalX) {
dist = Math.ceil((xpos - finalX) / 10)
xpos -= dist
}
if (ypos < finalY) {
dist = Math.ceil((finalY - ypos) / 10)
ypos += dist
}
if (ypos > finalY) {
dist = Math.ceil((ypos - finalY) / 10)
ypos -= dist
}
ele.style.left = `${xpos}px`
ele.style.top = `${ypos}px`
let repeat = [ele, finalX, finalY, interval]
ele.movement = setTimeout(() => {
moveAnimation(...repeat)
}, interval)
}
结束补充
这本书对于浏览器历史战争与W3C的出现,ECMAScript规范的出现等等都有所提及,顺着历史线一直到今天,一直发展到这个地步真的是非常令人激动,对于前几章 – 作者照顾新手为JavaScript语言进行了一个简短的知识快速概括
如果在当年,这本书应该也是叱诧风云的杰作,对于现在来说,的确有些老了,廉颇老矣-常能饭否,我一直在强调这本书值得我们去学习的是它的一个思想
可能浏览器嗅探技术我们不会再使用到,但是对于对象检测技术我们还是需要去学习这个思想,对于什么地方可能会出现错误,什么地方可能获取不到元素或者数据?
在第六章第四节作者提到了:不要做太多假设,我对此的理解是不要做太多没有必要的假设,这会造成一个代码冗余,我们应该以全局来观细节
在之前我会将document.body与document.querySelector('body')这俩个属性混谈为DOM对象,这样称呼好像也未尝不可,不过准确来说,document.body是DOM-HTML的属性,而document.querySelector('body')是DOM Core的属性(比如我们还有document.src , onclcik),onclcik是DOM-HTML的属性,那我们使用DOM Core该怎么去触发事件处理函数?
– 没错,当然是去使用方法监听了addEventListener(),在本书也有提及到attachEvent(),不过这是一个非标准的方法监听函数,前些年还在用来兼容IE
并且作者在书中提到:函数在行为方面应该是一个自给自足的脚本,我很认同
对于节点树这个概念,大家可以自行搜索查阅相关概念,当你拥有节点树这个概念之后,我相信解决DOM问题会更加的得心应手(这也是我们必须要知道的)
最后提一个点,作者在书中不止一次提到了结构化程序设计的一条原则:函数应该只有一个入口和出口,同时作者又不止一次违反了这条原则,所以在实际工作中,我们应该去根据具体情况来选择具体的处理方案,做一些取舍,有时候失也可以是得
对于其他一些必要知识的补充
说到必要知识补充,我第一个就要推荐DOM事件流与事件对象-event,在我们处理DOM时这些是必须要知道的
DOM事件流
事件流描述的是从页面中接收事件的顺序,事件发生时会在元素节点之间按照特定的顺序传播
DOM事件流分为三个阶段:
- 捕获阶段
- 当前目标阶段
- 冒泡阶段
假如我们在body元素中创建了一个div元素,并且为它绑定了一个事件,那么它的事件流就是这样的:
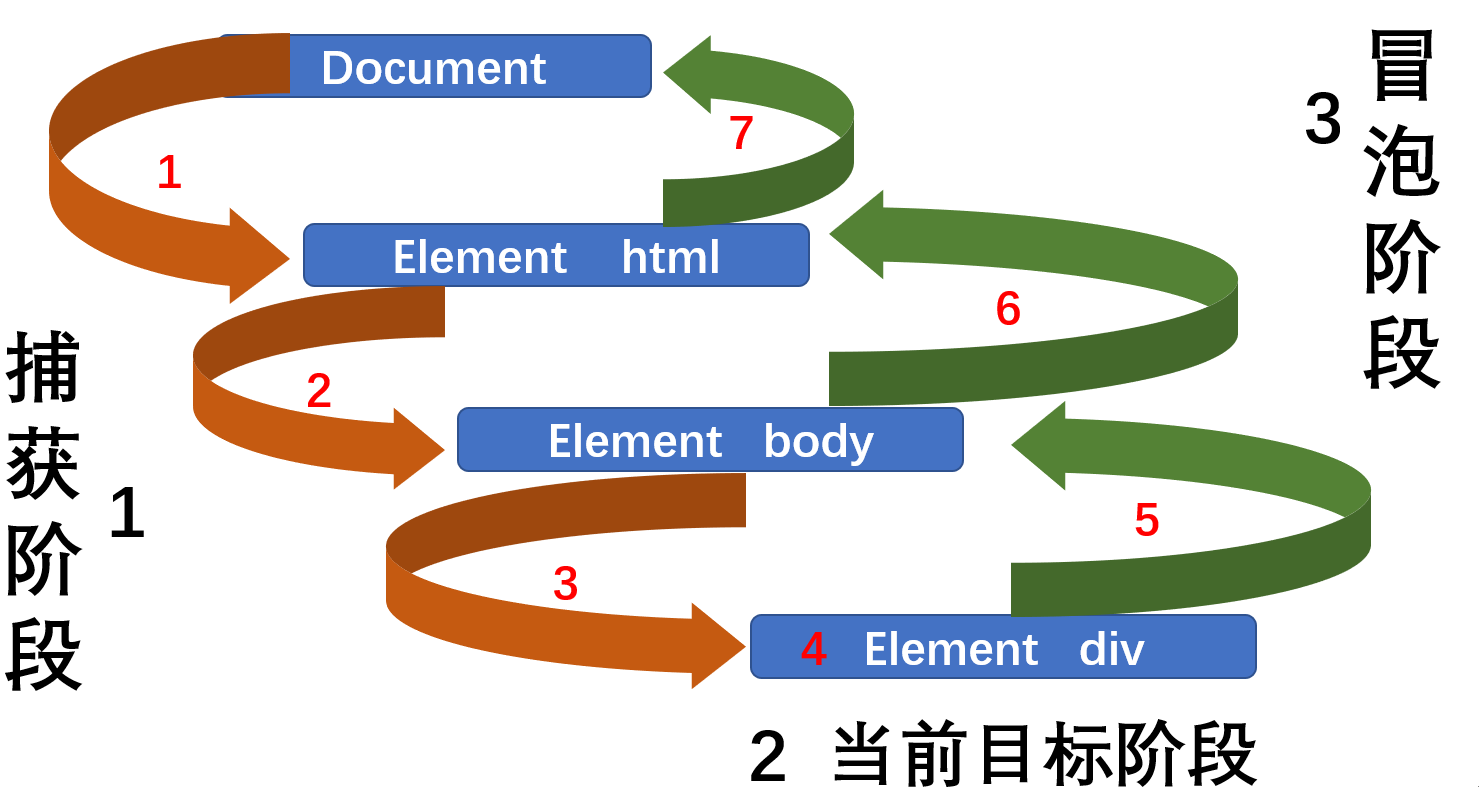
JavaScript只能执行捕获或冒泡其中的一个阶段
DOM-HTML的onclick属性和attachEvent()方法只能得到冒泡阶段,而addEventListener()方法可以设置执行哪个阶段
addEventListener(type,listener[,useCapture])
第三个参数如果为true,那么会在事件捕获阶段调用事件处理程序 – 默认false在事件冒泡阶段调用事件处理程序
事件对象(event)
当我们创建了一个事件时,事件对象会被自动创建出来,事件对象是我们事件一系列相关数据的集合,它和事件相关,如果我们创建了一个onclick事件,那么这个事件的事件对象就是与点击事件相关的一系列信息
element.addEventListener('click',(event)=>{})
比如我们想要阻止链接的默认跳转行为,我们可以使用事件对象中的preventDefault()方法:
a.addEventListener('click',(event)=>{
event.preventDefault()
})
// tips:低版本浏览器使用:event.returnValue
// 或者万能阻止行为:return false
// 上述提到的事件冒泡我们也可以使用stopPropagation进行拦截
事件委托
当一组元素需要注册事件的时候,我们不一定要一个一个的去注册事件(我不是说手动一个一个创建,我是说我们使用循环遍历为每一个元素绑定事件),这样性能不太高
我们为什么不去利用事件冒泡来处理这个场景问题呢?我们只把一个事件绑定到这些元素的父节点上,这样的话只操作一次DOM不就可以了吗?
实践出真知:
const ul = document.quselector('.testUL')
ul.addEventListener('click',(e)=>{
e.target.style.backgroundColor = 'green'
})
我觉得这很酷!当然这和事件对象离不开,事件对象很好玩
对于BOM的补充
这本书注重于DOM,所以对于浏览器对象模型BOM的阐述并不是很多
我总结了几个比较常用的:
- location对象
…属性
- location.href :获取当前网页URL地址
- location.host :返回主机域名
- location.port :返回端口号
- location.pathname :返回路径
- location.search :返回参数
- location.hash :返回哈希值(片段)
…方法
- location.assgin() :重定向页面(使用href属性也可以达到相同的效果)
- location.replace() :替换当前页并且不记录历史(不能后退页面)
- location.reload(true) :重载页面
- navigator对象
- navigstor.userAgent.match(用户打开网页所使用的设备名称1 | 用户打开网页所使用的设备名称2…)
这不禁让我想到了浏览器嗅探
- history对象
- back() :后退页面
- forward() :前进页面
- go(number/-number) :后退前进都可以
结束语
还是开头的那句话,这本书使我受益匪浅,也许它比较老,也许它不够全,但它很有趣,这就够了
这本书作者的结束语很棒:接下来路在何方,这个问题只能你自己来回答(翻译)
我们不能止步于此,这并不是DOM的全部,无论是当下还是未来,至少我们应该再去看看offset(元素偏移量)、client(元素相对视口信息)、scroll(滚动事件的专属事件对象)、touch(移动端触摸事件)、本地存储…
好吧,我压根没有打算说完这些,这个工作估计需要很长时间…
声明:我并没有任何好处去推荐该书,这只是一个读者对于这本书的一个观后感