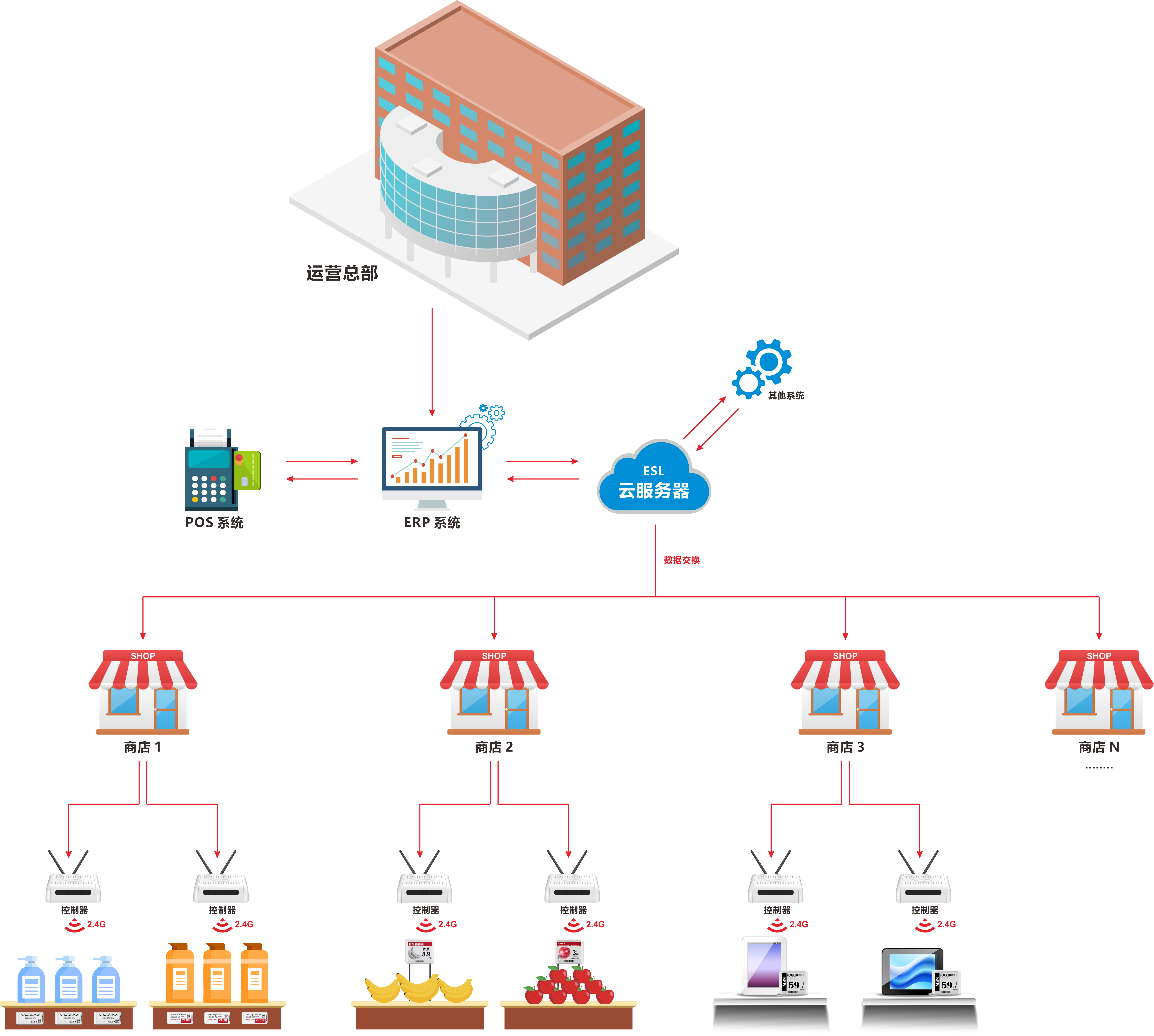
上一篇《数据结构与算法(一):概述》中介绍了数据结构的一些基本概念,并分别举例说明了算法的时间复杂度和空间复杂度的求解方法。这一篇主要介绍线性表。
一、基本概念
线性表是具有零个或多个数据元素的有限序列。线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的。
线性表的基本特征:
- 第一个数据元素没有前驱元素;
- 最后一个数据元素没有后继元素;
- 其余每个数据元素只有一个前驱元素和一个后继元素。
抽象数据类型:
线性表一般包括插入、删除、查找等基本操作。其基于泛型的API接口代码如下:
public interface List<E> {
//线性表的大小
int size();
//判断线性表是否为空
boolean isEmpty();
void clear();
//添加新元素
void add(E element);
//在指定位置添加新元素
void add(int index, E element);
//删除元素
E delete(int index);
//获取元素
E get(int index);
}
线性表按物理存储结构的不同可分为顺序表(顺序存储)和链表(链式存储):
- 顺序表(存储结构连续,数组实现)
- 链表(存储结构上不连续,逻辑上连续)
二、顺序表
顺序表是在计算机内存中以数组的形式保存的线性表,是指用一组地址连续的存储单元依次存储数据元素的线性结构。线性表采用顺序存储的方式存储就称之为顺序表。
其插入删除操作如图所示:
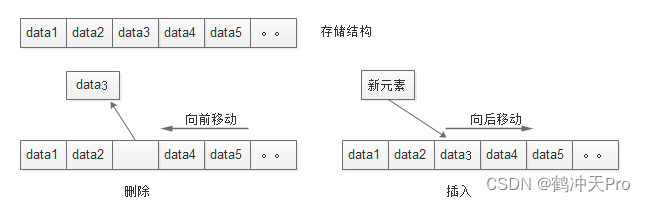
注意:
- 插入操作:移动元素时,要从后往前操作,不能从前往后操作,不然元素会被覆盖。
- 删除操作:移动元素时,要从前往后操作。
代码如下:
import java.util.*;
public class SequenceList<E> implements List<E>, Iterable<E> {
private static final int DEFAULT_CAPACITY = 10;
private int size;
private E[] elements;
@SuppressWarnings("unchecked")
public SequenceList() {
size = 0;
elements = (E[])new Object[DEFAULT_CAPACITY];
}
public int size() { return size;}
public boolean isEmpty(){ return size == 0;}
@SuppressWarnings("unchecked")
public void clear(){
size = 0;
elements = (E[])new Object[DEFAULT_CAPACITY];
}
public void add(E element){
add(size, element);
}
//在index插入element
public void add(int index, E element){
if(size >= elements.length) {
throw new RuntimeException("顺序表已满,无法添加");
}
if(index < 0 || index > size) {
throw new IndexOutOfBoundsException("参数输入错误");
}
for(int i=size; i>index; i--) {
elements[i] = elements[i - 1];
}
elements[index] = element;
size++;
}
//删除元素
public E delete(int index){
if(isEmpty()) {
throw new RuntimeException("顺序表为空,无法删除");
}
if(index < 0 || index >= size) {
throw new IndexOutOfBoundsException("参数输入错误");
}
E result = elements[index];
for(int i=index; i<size - 1; i++) {
elements[i] = elements[i + 1];
}
size--;
elements[size] = null; //避免对象游离
return result;
}
public E get(int index){
if(index < 0 || index >= size) {
throw new IndexOutOfBoundsException("参数输入错误");
}
return elements[index];
}
@Override
public Iterator<E> iterator() {
return new Iterator<E>() {
int num = 0;
@Override
public E next() {
return elements[num++];
}
@Override
public boolean hasNext() {
return num < size;
}
};
}
public static void main(String[] args) {
SequenceList<Integer> sl = new SequenceList<Integer>();
for(int i=0;i<10;i++) {
sl.add(i);
}
System.out.println("删除1位置元素:"+sl.delete(1));
sl.add(0,15);
for(int i=0;i<sl.size();i++) {
System.out.print(sl.get(i)+" ");
}
}
}
这里需要注意,由于java中不能直接创建泛型数组,所以在顺序表的构造函数中先创建了一个Object的数组,然后将它强转为泛型数组并使用@SuppressWarnings(“unchecked”)消除未受检的警告。若对这点还有什么疑问可以参考我的学习笔记 Effective java笔记(四),泛型 中第25、26条。另外在进行删除操作时应避免对象游离。
在java中,数组一旦创建其大小不能改变,所以在上面的实现中,为了尽可能的不浪费内存必须事先准确的预估顺序表的容量。但现实应用中由于存在很多不确定因素,这往往是不切实际的。这时可使用动态调整数组大小的方法来解决这个问题。代码如下:
private void resize(int num){
@SuppressWarnings("unchecked")
E[] temp = (E[]) new Object[num];
for(int i=0; i<size; i++) {
temp[i] = elements[i];
}
elements = temp;
}
然后在插入和删除操作中分别加入判断语句,来调用这个方法
//在index插入element
public void add(int index, E element){
//当顺序表满时,容量加倍
if(size >= elements.length) {
// throw new RuntimeException("顺序表已满,无法添加");
resize(elements.length*2);
}
if(index < 0 || index > size) {
throw new IndexOutOfBoundsException("参数输入错误");
}
....
}
//删除元素
public E delete(int index){
....
elements[size] = null;
//当元素数量小于容量的1/4时,容量减半
if(size>0 && size <= elements.length/4) {
resize(elements.length/2);
}
return result;
}
**注意:**在删除操作中检查条件为「顺序表的大小是否小于容量的 1/4」,而不是1/2。这样可以避免在1/2这个零界点处反复进行插入删除操作时,数组进行频繁复制。
顺序表效率分析:
- 顺序表插入和删除一个元素,最好情况下其时间复杂度(这个元素在最后一个位置)为O(1),最坏情况下其时间复杂度为O(n)。
- 顺序表支持随机访问,读取一个元素的时间复杂度为O(1)。
顺序表的优缺点:
- 优点:支持随机访问
- 缺点:插入和删除操作需要移动大量的元素,造成存储空间的碎片。
顺序表适合元素个数变化不大,且更多是读取数据的场合。
三、链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点组成,每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
链表根据构造方式的不同可以分为:
- 单向链表
- 单向循环链表
- 双向链表
1、单向链表
单链表有带头结点和不带头结点两种结构,其结构如下
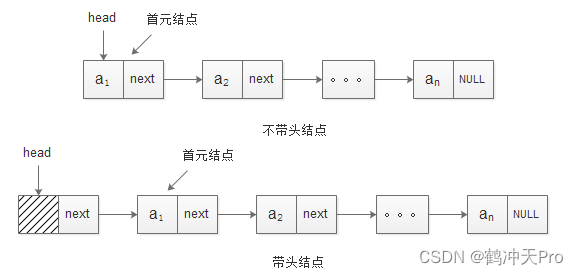
在带头结点的单链表中,其第一个结点被称作头结点。第一个存放数据元素的结点称作首元结点,头结点指向首元结点。头结点是为了操作的统一与方便而设立的,其一般不放数据(也可存放链表的长度、用做监视哨等)。此结点不能计入链表长度值。
带头结点的单链表的优点:
- 在链表第一个位置上进行的操作(插入、删除)和其它位置上的操作一致,无须进行特殊处理;
- 无论链表是否为空,head一定不为空,这使得空表和非空表的处理一致。
由于带头结点的链表更容易操作,这里仅实现带头结点的单链表
带头结点的链表插入与删除示意图:
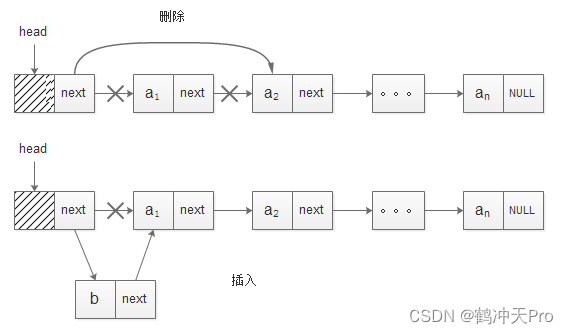
代码如下:
import java.util.*;
public class LinkedList<E> implements List<E>, Iterable<E>{
private Node head;
private int size;
private class Node {
E element;
Node next;
}
LinkedList() {
head = new Node();
}
@Override public int size() { return size;}
@Override public boolean isEmpty() { return size==0;}
@Override public void clear() {
head = new Node();
size = 0;
}
@Override public void add(E element) {
add(0, element);
}
@Override public void add(int index, E element) {
if(index < 0 || index > size)
throw new IndexOutOfBoundsException("参数输入错误");
Node current = location(index);
Node newNode = new Node();
newNode.element = element;
Node node = current.next;
current.next = newNode;
newNode.next = node;
size++;
}
//找到第index个结点前的结点
private Node location(int index){
Node current = head;
for(int i=0; i<index; i++) {
current = current.next;
}
return current;
}
@Override public E get(int index) {
if(index < 0 || index >= size)
throw new IndexOutOfBoundsException("参数输入错误");
return location(index + 1).element;
}
//删除第index个元素
@Override public E delete(int index) {
if(index < 0 || index >= size)
throw new IndexOutOfBoundsException("参数输入错误");
Node current = location(index);
E element = current.next.element;
current.next = current.next.next;
size--;
return element;
}
@Override
public Iterator<E> iterator() {
return new Iterator<E>() {
Node current = head;
@Override
public E next() {
current = current.next;
return current.element;
}
@Override
public boolean hasNext() {
return current.next != null;
}
};
}
public static void main(String[] args) throws Exception{
LinkedList<Integer> list = new LinkedList<Integer>();
for(int i=0;i<10;i++) {
list.add(i);
}
System.out.println("删除0位置元素:"+list.delete(0));
list.add(0,15);
for (Integer ele : list ) {
System.out.print(ele + " ");
}
}
}
单链表效率分析:
在单链表上插入和删除数据时,首先需要找出插入或删除元素的位置。对于单链表其查找操作的时间复杂度为 O(n),所以
链表插入和删除操作的时间复杂度均为 O(n)
链表读取操作的时间复杂度为 O(n)
单链表优缺点:
优点:不需要预先给出数据元素的最大个数,单链表插入和删除操作不需要移动数据元素
缺点:不支持随机读取,读取操作的时间复杂度为 O(n)。
2、单向循环链表
将单链表中终端结点的指针指向头结点,使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表。
对于循环链表,为了使空链表与非空链表处理一致,通常设一个头结点。如下图:

循环链表和单链表的主要差异在于链表结束的判断条件不同,单链表为current.next是否为空,而循环链表为current.next不等于头结点。对于循环链表的增删改查操作与单链表基本相同,仅仅需要将链表结束的条件变成current.next != head即可,这里就不在给出了。
在单链表中,我们有了头结点时,对于最后一个结点的访问需要 O(n)的时间,因为我们需要将单链表全部遍历一次。哪有没有可能用 O(1)的时间访问到终端结点呢?当然可以,我们只需改造一下单链表,使用指向终端结点的尾指针来表示循环链表,这时访问开始结点(不是头结点)和终端结点的操作都为 O(1)。它们的访问操作分别为end.next.next和end,其中end为指向终端结点的引用。这个设计对两个循环链表的合并特别有用,可以避免遍历链表的时间消耗。如:
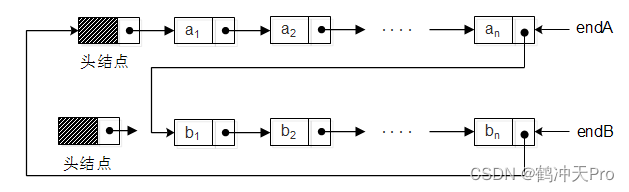
合并两个循环链表的代码:
public Node merge(Node endA, Node endB) {
Node headA = endA.next; //保存A表的头结点
endA.next = endB.next.next;
endB.next = headA;
return endB;
}
3、双向链表
双向链表是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。使得两个指针域一个指向其前驱结点,一个指向其后继结点。
双向链表的结点表示:
private class Node {
E element;
Node prior; //指向前驱
Node next;
}
对于双向链表,其空和非空结构如下图:
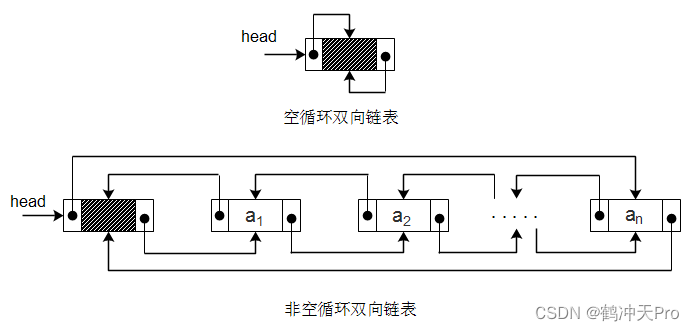
双向链表是单链表扩展出来的结构,它可以反向遍历、查找元素,它的很多操作和单链表相同,比如求长度size()、查找元素get()。这些操作只涉及一个方向的指针即可。插入和删除操作时,需要更改两个指针变量。
插入操作:注意操作顺序
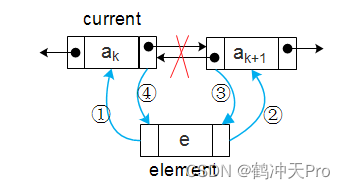
在current后插入element的代码为:
element.prior = current;
element.next = current.next;
current.next.prior = element;
current.next = element;
删除操作相对比较简单,删除current结点的代码为:
current.prior.next = current.next;
current.next.prior = current.prior;
current = null;
双向链表相对于单链表来说占用了更多的空间,但由于其良好的对称性,使得能够方便的访问某个结点的前后结点,提高了算法的时间性能。是用空间换时间的一个典型应用。
4、静态链表
用数组描述的链表叫静态链表,它是那些没有指针和引用的语言,如Basic、Fortran等,实现链表的方式。由于现在的高级程序语言,一般都拥有指针或引用,可以使用更灵活的指针或引用来实现动态链表,所以对于静态链表仅掌握其算法思想即可。
静态链表的思想:
-
让数组的每个元素有两个数据域data和cur组成,其中data用来存放数据元素,cur用来存放元素的后继在数组中的下标。我们把cur称为游标。
-
通常把数组中未被使用的位置称为备用链表,而数组的第一个位置(下标为0的位置)的cur存放备用链表的第一个结点的下标;数组的最后一个位置的cur则存放第一个有元素的位置的下标,相当于链表的头结点作用。
静态链表状态图:

代码如下:
import java.util.*;
public class StaticList<E> implements List<E>, Iterable<E> {
private static final int DEFAULT_CAPACITY = 100;
private int size;
private Node[] nodes;
private class Node {
E element;
int cur;
}
public StaticList() {
initList();
}
@SuppressWarnings("unchecked")
private void initList() {
size = 0;
//注意这句,不能直接new Node[DEFAULT_CAPACITY],java不允许创建泛型数组
nodes = new StaticList.Node[DEFAULT_CAPACITY];
for(int i=0; i<nodes.length; i++) {
nodes[i] = new Node();
nodes[i].cur = i + 1;
}
nodes[nodes.length - 1].cur = 0;
}
public int size() { return size;}
public boolean isEmpty(){ return size == 0;}
public void clear(){
initList();
}
public void add(E element){
add(0, element);
}
//在index插入element
public void add(int index, E element){
if(index < 0 || index > size) {
throw new IndexOutOfBoundsException("参数输入错误");
}
Node prior = location(index);
int newCur = malloc();
if(newCur == 0) {
throw new RuntimeException("顺序表已满,无法添加");
}
nodes[newCur].element = element;
nodes[newCur].cur = prior.cur;
prior.cur = newCur;
size++;
}
//找到第index个结点前的结点
private Node location(int index){
Node prior = nodes[nodes.length - 1];
for(int i=0; i<index; i++) {
prior = nodes[prior.cur];
}
return prior;
}
//分配空间,若备用链表非空,返回分配的结点的下标,否则返回0
private int malloc() {
int i = nodes[0].cur;
if(i != 0) {
nodes[0].cur = nodes[i].cur; //备用链表的下一个位置
}
return i;
}
//将下标为k的空闲结点回收到备用链表
private void free(int index) {
nodes[index].cur = nodes[0].cur;
nodes[0].cur = index;
}
//删除元素
public E delete(int index){
if(isEmpty()) {
throw new RuntimeException("顺序表为空,无法删除");
}
if(index < 0 || index >= size) {
throw new IndexOutOfBoundsException("参数输入错误");
}
Node prior = location(index);
int temp = prior.cur; //要删除元素的下标
prior.cur = nodes[temp].cur;
E result = nodes[temp].element;
nodes[temp].element = null;
size--;
free(temp);
return result;
}
public E get(int index){
if(index < 0 || index >= size) {
throw new IndexOutOfBoundsException("参数输入错误");
}
return location(index + 1).element;
}
@Override
public Iterator<E> iterator() {
return new Iterator<E>() {
int temp = nodes[nodes.length - 1].cur;
@Override
public E next(){
E result = nodes[temp].element;
temp = nodes[temp].cur;
return result;
}
@Override
public boolean hasNext() {
return temp != 0;
}
};
}
//测试
public static void main(String[] args){
StaticList<Integer> sl = new StaticList<Integer>();
for(int i=0;i<10;i++) {
sl.add(i);
}
System.out.println("删除1位置元素:"+sl.delete(1));
sl.add(1,15);
for(int i=0;i<sl.size();i++) {
System.out.print(sl.get(i)+" ");
}
}
}
为了实现数组空间的循环利用,静态链表将所有未被使用过的及已经被删除的元素空间用游标链成一个备用的链表。每当插入时就从备用链表上取第一个结点作为待插入的新结点,删除时将结点回收到备用链表中。上面代码中的malloc()和free()方法分别对应了这两种操作。静态链表的插入和删除等操作和单链表类似,仅需注意结点的cur为一个int变量,具体操作可以参考上面的代码。
另外需要注意:静态链表初始化时需要创建一个内部类泛型数组StaticList.Node[ ],我们都知道,java中不能创建泛型数组,一种解决方案是先创建一个Object类型的数组,然后再强转为需要的类型。如:
nodes = (Node[])new Object[DEFAULT_CAPACITY];
但是在上面的代码中,使用这种方法运行时会报ClassCastException,解决方法是
nodes = new StaticList.Node[DEFAULT_CAPACITY];
这样就可以解决这个问题,剩下一个未受检的警告使用@SuppressWarnings(“unchecked”)注解消除即可。
静态链表有优缺点:
-
优点:插入删除操作时,只需要修改游标,无需移动元素
-
缺点:需要事先预估链表的容量;不能随机读取元素;需要人为的管理数组的分配(类似于管理内存分配),失去了java语言的优点。
总的来说,静态链表是为没有指针的语言设计的一种实现链表的方法,尽管可能用不上,但掌握其设计思想还是很有必要的。
总结一下,这节主要介绍了线性表两种不同结构(顺序存储结构和链式存储结构)的实现方法,它们是其他数据结构的基础,也是现在企业面试中最常考的数据结构类型之一。