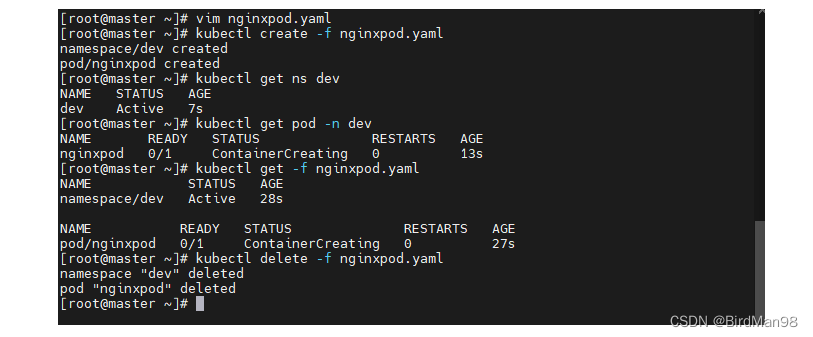
数学公式表示学习:
大约耗时:2 hours
在做了一些工作后重读论文:MathBERT: A Pre-Trained Model for Mathematical Formula Understanding
这是本篇论文最重要的idea:Current pre-trained models neglect the structural
features and the semantic correspondence between
formula and its context.(其中很fancy的一点是注重每个数学公式的strctural features,即关注数学公式的结构)
用三个下游任务验证,并且效果很好:

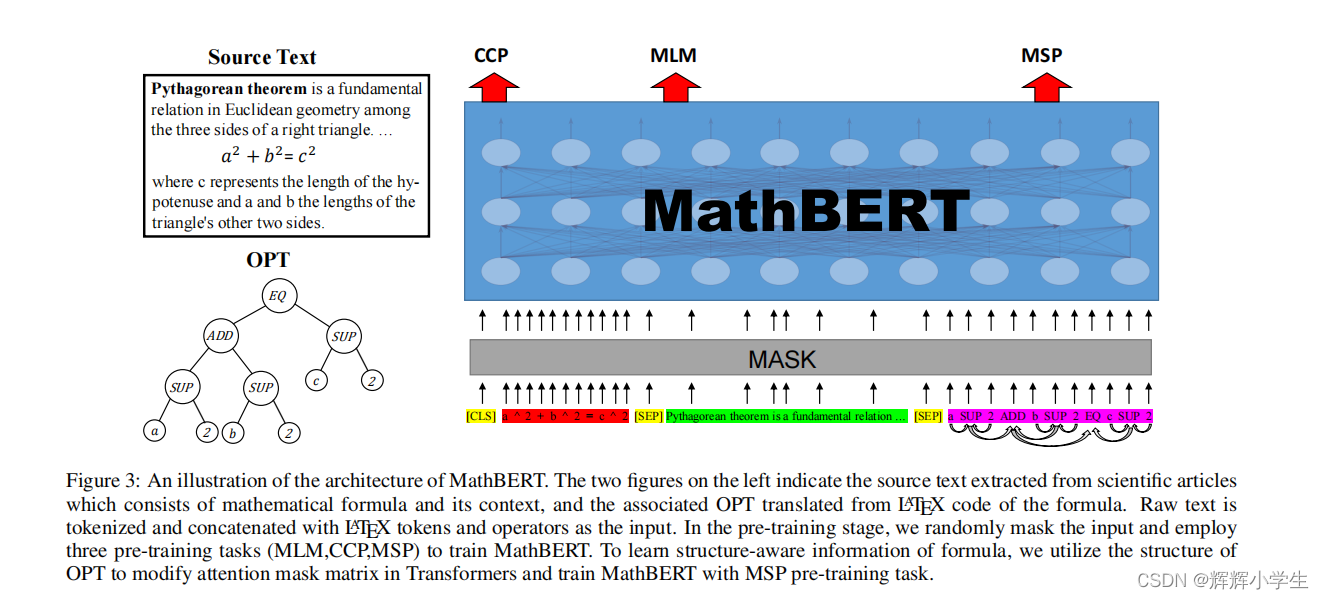
mathematical information
retrieval
formula topic classifification
formula
headline generation
三个
预训练任务:
Masked Language Modeling (MLM) :text representations
模仿BERT的MLM,其中三个字段即公式latex、context、OPT的信息可以互补。
Context Corre
spondence Prediction (CCP):
latentrelationshipbetweenformula and
context
模仿BERT的NSP,二分类任务。
Masked Substructure Prediction (MSP):
semantic-levelstructureofformula
预训练任务数据集:
We build a large dataset containing more than 8.7 million formula-context pairs which are extracted from
scientifific articles published on arXiv.org
1
and train Math
BERT on it.
Arxiv bulk data available from Amazon S3
2
is the complete set of arxiv documents which contains source
TEX fifiles and processed PDF fifiles. “
\
begin
{
equation
}
. . .
\
end
{
equation
}
” is used as the matching pattern to extract
single-line display formulas from L
A
TEX source in these TEX
files.
toolkit L
A
TEX tokenizer in
im2markup to tokenize separately formulas
OPT translator in TangentS
4
to convert L
ATEX codes into OPTs
模型的backbone:
An enhanced multi-layer bidirectional Transformer [Vaswani
et al.
, 2017] is built as the backbone of MathBERT, which is
modifified from vanilla BERT.
MathBERT的输入:
we concatenate the for
mula LA
TEX tokens, context and operators together as the input
of MathBERT.
attention 机制的细节:
the attention mechanism in Trans
former is modifified based on the structure of OPT to enhance
its ability of capturing structural information
具体的细节看原文,这里上个图
architecture:
思政知识图谱:
大约耗时3~5hours
我们要理清当前的任务:
1.爬取彰显政治精神的case:爬取的网站?学习爬虫?
2.对case的分类:学学学
3.对case的挂载:学学学
学习爬虫:
将一段文本打上NER的标签的方法:人工;百度打标;(jieba、hanNLP准确率不太行)
MRE:
今天开了分享会,没时间做这个了,只能路上想想idea
自学:
回家看看花书,芜湖





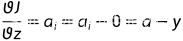
![buu [UTCTF2020]basic-crypto 1](https://img-blog.csdnimg.cn/6011adb31fbd4c42ada2ccc3f5e37ae8.png)