浅析OkHttp3
这篇文章主要用来回顾Okhttp3源码中,同步异步请求的区别、拦截器的责任链模式、连接池管理以及探讨socket通信到底在哪里实现。
列出的代码可能删掉了非核心部分的展示,如果有异议请查看源码
连接池涉及知识:可能根据 IP 地址集合,尝试进行子网合并/构造超网,这部分请大家回顾计算机网络的构造超网进行复习。
1.基本使用
使用OkHttp来发送网络请求,一般我们会通过同步请求和异步请求两种方式:
OkHttpClient okhttpClient = new OkHttpClient();
//拼接请求
Request request = new Request.Builder()
.url("http://xxx.xxx.xxx")
.get()//发送get请求
//.post(requestBody)//发送post请求
.build();
//创建请求实体Call
Call call = okHttpClient.newCall(request);
//发起同步请求,阻塞等待返回的response
Response response = call.execute();
//发送异步请求,通过接口回调来获取数据
call.enqueue(new Callback(){
@Override
public void onFailure(Call call,IOException e){
//e.getMessage()
}
@Override
public void onResponse(Call call,Response response) throws IOException{
//处理返回的响应体response
//response.body()
}
});
同步请求,将会阻塞等待返回的response。异步请求,将会通过接口回调来获得返回的数据。这也是最经典的获取返回数据的两个方式:同步return返回,以及异步回调返回。
首先我们关注到请求实体,请求实体实现了 Call 接口,Call 接口中定义了一些请求实体会用到的方法:
public interface Call extends Cloneable {
//获取请求实体中的Request对象
Request request();
//发起同步请求
Response execute() throws IOException;
//发起异步请求
void enqueue(Callback var1);
//取消请求
void cancel();
//是否被执行了(子类实现用到了synchronized,我们认为标志是临界区,不希望在多线程场景中产生歧义)
boolean isExecuted();
//是否被取消了(子类的调用链中,也用到了synchronized)
boolean isCanceled();
//返回一个AsyncTimeout对象实例,它的timedOut()方法可以调用到transmitter的cancel()方法
//简言:可以用于超时取消
Timeout timeout();
//这里是浅拷贝
Call clone();
//让外界能够以此规范来产生出一个Call请求实体
public interface Factory {
Call newCall(Request var1);
}
}
在它的实现类RealCall和AsyncCall中,isExecuted()和 isCanceled()都被加以了 synchronized 修饰,因为 executed 和 canceled 在多线程场景下,可能会被多个线程使用,认为是临界区数据,使用 synchronized 修饰是希望这两个变量对所有线程保持可见性以及互斥性。
我们接下来来看一下 Call 接口的具体实现类,并对比他们的区别
2. RealCall 和 AsyncCall
我们发现,虽然异步任务也命名为Call结尾,但它并没有实现 Call 接口,而是实现了 Runnable 接口。这里的设计思想涉及到【非静态内部类】的使用,它可以调用外部类的方法。我们来看一下哪些方法是RealCall和AsyncCall所共用的。
先来看一下两个类的结构:
final class RealCall implements Call {
//这部分代码很多,而且不论是同步还是异步,处理逻辑是一模一样的!
Response getResponseWithInterceptorChain(){
//...
}
public Response execute(){
//外部类RealCall可以调用它
this.getResponseWithInterceptorChain();
}
final class AsyncCall extends NamedRunnable{
protected void execute(){
//内部类AsyncCall也可以调用它
RealCall.this.getResponseWithInterceptorChain();
}
}
}
我们发现有一个方法 getResponseWithInterceptorChain() 被他们共用了。
我们需要认识到,AsyncCall 实现了 Runnable 接口,所以它执行的逻辑需要放在 run() 方法中执行,我们可以把代码解耦,将对线程的命名和请求执行逻辑分离开来:
- 具体执行逻辑写在 execute() 方法中
- run() 除了调用 execute() 还要对线程进行命名
AsyncCall 继承的 NamedRunnable 的 run() 方法就做了上述的逻辑解耦,让代码更清晰:
public abstract class NamedRunnable implements Runnable {
//...
public final void run() {
String oldName = Thread.currentThread().getName();
Thread.currentThread().setName(this.name);
try {
this.execute();
} finally {
Thread.currentThread().setName(oldName);
}
}
//可以理解为这是一个模板方法设计模式,将具体的execute()逻辑让子类实现,自己只负责对线程命名
protected abstract void execute();
}
我们注意到这里的命名很有意思,先把线程旧的名字保留,在执行 execute() 期间,线程的名字是 this.name,执行结束后,线程的名字又变成了原先的名字。
不难理解,在线程复用的场景里,我们不希望对借用的线程产生影响,“原物归还”是一个好习惯,所以在试用期间,我们改了名字,但是当前线程执行完这个任务后,名字需要改回去。避免别人无法通过原先的名字找到它!
他们还有什么区别呢?从设计他们的初衷来看,希望 RealCall 用来执行同步请求,AsyncCall 要用来执行异步请求,所以 AsyncCall 中自然就有提交任务到线程池的步骤,而 RealCall 只有同步执行的步骤。
我们先来看一下 RealCall 的 execute() 方法,执行同步任务。
3. Response response = call.execute() 执行同步任务
由 okhttpclient.newCall() 创建出来的,是RealCall对象,如果你想要的执行同步任务,调用它的 execute() 方法即可。
我们来看一下 RealCall 提交同步任务的步骤:
final class RealCall implements Call{
public Response execute() throws IOException{
//临界区标志修改,需要加锁
synchronized(this){
this.executed = true;
}
this.transmitter.timeoutEnter();
this.transmitter.callStart();
Response var1;
try {
//1. 将同步请求记录在runningSyncCalls集合中,外界可以通过 runningSyncCalls 获取到当前有多少同步任务被提交
this.client.dispatcher().executed(this);
//2. 直接在当前线程环境下,执行网络请求
var1 = this.getResponseWithInterceptorChain();
} finally {
//3. 执行完毕后,将同步请求从记录中移除
this.client.dispatcher().finished(this);
}
return var1;
}
}
在通过 getResponseWithInterceptorChain() 进行拦截器处理和网络请求之前,记录在 runningSyncCalls 队列中,执行完成之后,不论是否有异常,都将它从该记录队列中移除。我们只需要注意到,getReponseWithInterceptorChian() 在 RealCall.execute() 中,是在当前调用者所在的线程环境下发起的,所以是同步请求,具体 getResponseWithInterceptorChain() 到底做了什么我们后面分析。
4. call.enqueue( callback ) 提交异步任务
由 okhttpclient.newCall() 创建出来的,是RealCall对象,如果你想要的执行同步任务,调用它的 execute() 方法即可,如果你想要的执行异步任务,调用它的 enqueue() 方法,RealCall 内部会帮你把任务转变为 AsyncCall,提交为异步任务:
Call realCall = okhttpClient.newCall(request);//将request封装在RealCall对象中
realCall.enqueue(new Callback(){...});//发起异步请求
为了解耦,我们将异步任务的执行逻辑写在了 AsyncCall 这个内部类中,而 request 仍然封装在 RealCall 这个外部类中。AsyncCall 需要 request 的时候直接在外部类拿就好,代码很简洁,结构很清晰。我们只需要让 AsyncCall 来执行异步任务请求的逻辑就好了:
//RealCall.java
public void enqueue(Callback callback) {
//修改临界区资源需要加锁
synchronized(this) {
this.executed = true;
}
this.transmitter.callStart();
//避免破坏RealCall的结构,新加的Callback回调对象,写在了 AsyncCall 里面,让AsyncCall去管理
AsyncCall asyncCall = new RealCall.AsyncCall(callback);
this.client.dispatcher().enqueue(asyncCall);
}
我们知道框架总是不断更新的,在更新的过程中,需要增加功能,要符合对拓展开放,对修改关闭的设计原则。我猜测 OkHttp 是后来添加的异步任务请求的功能,但是原先的 RealCall 已经实现好了,而异步请求 AsyncCall 的逻辑可以复用很多 RealCall 的逻辑,所以将 AsyncCall 设计为了内部类,和外部类共享成员变量!异步需要的回调接口,也不直接设计为 RealCall 的成员变量,因为要避免对原有代码的破坏,所以写在了 AsyncCall 中!
RealCall 创建好一个 AsyncCall 实例后,就交给调度器去发起异步请求,我们先要注意到 AsyncCall 实现了 Runnable,然后我们看一下 dispatcher.enqueue() 做了什么:
//Dispatcher.java
void enqueue(AsyncCall call) {
synchronized(this) {
//1. 将AsyncCall 放入异步请求准备队列中
this.readyAsyncCalls.add(call);
}
//2. 尝试将准备队列中的AsyncCall拿去执行
this.promoteAndExecute();
}
Dispatcher 首先将 AsyncCall 放入异步请求队列 readyAsyncCalls 中,然后看看是否满足异步请求条件,如果满足就可以尝试发起异步请求!我们来看一下 promoteAndExecute() 中做了什么:
//Dispatcher.java
private boolean promoteAndExecute() {
//1. 这个集合存了从 readyAsyncCalls 准备队列中取出来可以执行的 AsyncCall 异步任务
List<AsyncCall> executableCalls = new ArrayList();
boolean isRunning;
AsyncCall asyncCall;
//需要注意,runningAsyncCalls类似的这些队列也是临界区资源,也需要上锁使用
synchronized(this) {
Iterator i = this.readyAsyncCalls.iterator();
while(true) {
if (i.hasNext()) {
asyncCall = (AsyncCall)i.next();
//2. OkHttp3默认并发数为64,所以 runningAsyncCalls 当前可以执行异步任务的队列长度设置为 64
if (this.runningAsyncCalls.size() < this.maxRequests) {
//3. 只要还在并发数要求内,就把它取出来,准备执行!
//放到 executableCalls 中,用于发起执行
executableCalls.add(asyncCall);
//4.记录到 runningAsyncCalls 中,用于记录!
this.runningAsyncCalls.add(asyncCall);
}
}
//当前是否有异步请求被取出,如果有,认为okhttp为运行状态
isRunning = this.runningCallsCount() > 0;
break;
}
}
int i = 0;
//不涉及临界区资源操作的代码,放到临界区之外来执行,不占用锁资源!
for(int size = executableCalls.size(); i < size; ++i) {
asyncCall = (AsyncCall)executableCalls.get(i);
//由此发起AsyncCall的异步任务!!!
asyncCall.executeOn(this.executorService());
}
return isRunning;
}
想要执行异步任务,需要满足并发数小于64。并发数由 runningAsyncCalls 队列提供,它记录了从 readyAsyncCalls 队列中取出来被执行的任务,所以这条“记录”是个临界区资源,使用需要上锁。
其次,临界区代码不应该太多,执行时间尽量要短,所以synchronized修饰的代码块中,只有让 AsyncCall 在集合中转移,并没有进行实际的执行工作。执行工作放到了同步代码块之后执行!我们注意发起异步任务的代码是:
asyncCall.executeOn(this.executorService());
看变量名字,我们可以猜到,Dispatcher将线程池的引用交给了AsyncCall,希望 AsyncCall 的异步任务在提供的线程池中执行。具体如何执行,让 asyncCall.executeOn() 方法来执行。我们回到 AsyncCall 对象中,来看看是如何发起异步任务的:
//RealCall.AsyncCall
void executeOn(ExecutorService executorService) {
assert !Thread.holdsLock(RealCall.this.client.dispatcher());
//传入了一个线程池对象
boolean success = false;
try {
//AsyncCall实现了Runnable接口,其run()方法调用了AsyncCall.execute()方法,即具体进行网络请求的逻辑
executorService.execute(this);
success = true;
} catch (RejectedExecutionException var8) {
//发生错误的回调
this.responseCallback.onFailure(RealCall.this, ioException);
} finally {
if (!success) {
//失败的后续处理
RealCall.this.client.dispatcher().finished(this);
}
}
}
我们记得,AsyncCall实现了Runnable接口,其run()方法调用了AsyncCall.execute()方法,即具体进行网络请求的逻辑。设计者通过 executorService.execute(this) 将 runnable 实例提交给线程池去执行!
当线程池调度到当前AsyncCall的时候,执行其execute()方法。和 RealCall 一样,都叫做 execute() 方法,区别是 AsyncCall 的 execute() 方法在内部的线程池中执行!而 RealCall 的 execute() 方法则是在调用者的线程中同步执行。
我们来看 AsyncCall 的 execute() 方法
protected void execute() {
try {
//发起网络请求,阻塞等待response处理并返回
Response response = RealCall.this.getResponseWithInterceptorChain();
//将response回调出去
this.responseCallback.onResponse(RealCall.this, response);
} catch (IOException var8) {
//发生异常的回调
this.responseCallback.onFailure(RealCall.this, var8);
} catch (Throwable var9) {
//如果发生了异常,将这个异步任务取消
RealCall.this.cancel();
} finally {
//执行结束后,将asyncCall从runningAsyncCalls记录队列中剔除,对外表示并发数/任务数 -1
RealCall.this.client.dispatcher().finished(this);
}
}
AsyncCall 的 execute() 方法执行在内部的线程池中!首先通过 getResponseWithInterceptorChain() 发起网络请求,并获得Response响应,通过callback将response回调出去。任务如果出错,调用 call.cancel() 来告知上层任务失败并取消,最后将 asyncCall从runningAsyncCalls记录队列中剔除,对外表示当前并发数/任务数减少了。
和 RealCall 中的 runningSyncCalls 的设计一样,是临界区资源,其用途之一,就是记录当前任务数。至于为什么不仅用一个变量来记录我还没深入探究,我猜测应该这个队列还有其他用途,大家可以参考其他博客分享。
探讨完 RealCall 和 AsyncCall 发起同步或者异步任务的逻辑之后,我们重点关注一下 getResponseWithInterceptorChain() 到底是如何发起网络请求的:
5. getResponseWithInterceptorChain() 真正发起socket通信
代码和逻辑比较多,这里我先说一下大概逻辑:
- 首先把用户设计的拦截器,以及OkHttp内部实现的拦截器进行一个汇总
- 通过责任链的设计模式,逐个对 request 进行处理
- 其中,有两个拦截器比较重要:
- ConnectInterceptor 拦截器用于维护socket连接池
- CallServerInterceptor 拦截器用于发送处理后的request请求,并接收返回的response。
责任链的逻辑我画了一张图,大概是这样子的:
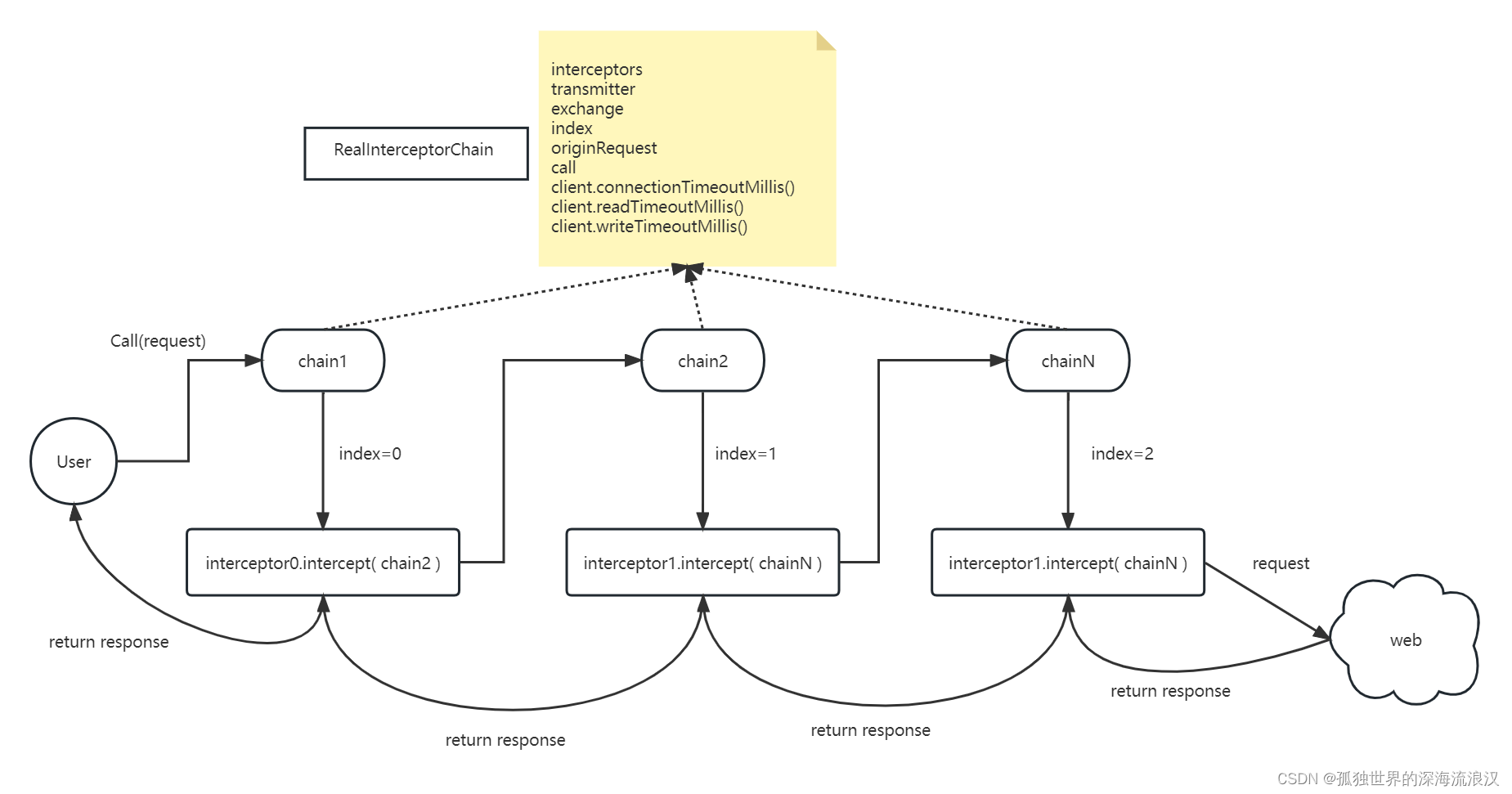
我来解释一下:过程中,所有 RealInterceptorChain实例都引用着相同的数据,包括 interceptors 集合,call实例,OkHttpClient中设置的超时时间等。唯一变化的是 index。chain.proceed() 方法通过 index 来判断当前轮到拦截器集合中的哪一个来执行 intercept(next) 方法。这里的next是下一个chain实例,注意它的 index+1 。也就是下个 chain实例将会调用下标为 index+1 的拦截器去执行相关操作。
我们回到代码:
//RealCall.java
Response getResponseWithInterceptorChain() throws IOException {
//所有拦截器的集合
List<Intetceptor> interceptors = new ArrayList<>();
//RealInterceptorChain责任链的主导者,只需要注意到传入了拦截器集合,以及当前目标拦截器的下标,以及一些基本设置。
Interceptor.Chain chain = new RealInterceptorChain(interceptors,transmitter,null,0,request,call.this,client.connectTimeoutMillis(),client.readTimeoutMillis(),client.writeTimeoutMillis());
//发起调用,chain将会逐个地调用拦截器,进行request的处理
Response response = chain.proceed(request);
}
getResponseWithInterceptorChain() 是整个责任链调度的起点,它整合了所有拦截器,放在 interceptors 集合中。并初始化了一个 index=0 的 RealInterceptorChain。chain将会通过 proceed() 来调用当前拦截器的intercept()方法:
//RealInterceptorChain.java
public Response proceed(Request,Transmitter transmitter,Exchange exchange){
//...
//新的一个chain,注意index为 index+1,说明下一个调用的拦截器的下标相对当前的,是+1的
RealInterceptorChain next = new RealInterceptorChain(interceptors, transmitter, exchange,index + 1, request, call, connectTimeout, readTimeout, writeTimeout);
//获得当前拦截器
Interceptor interceptor = interceptors.get(index);
//调用当前拦截器的intercept() 方法
Response response = interceptor.intercept(next);
}
看到拦截器中责任链调用部分的代码:
//ConnectInterceptor.java
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
//拦截器对request做一些处理,然后再交给下一层的chain
return realChain.proceed(request, transmitter, exchange);
}
intercept()传入的chain的index是当前拦截器index+1的值。拦截器先对request做一些自己的处理,然后让index=index+1的chain去继续调用下一个拦截器。
我们发现,chain不仅仅用来寻找当前是哪个拦截器要执行,还保存了被之前拦截器处理过的 request对象,以及一些新的变量,例如ConnectionInterceptor拦截器还会创建一个 exchange 交给 chain来保管。
所以 chain 的主要任务就是数据托管,按顺序让interceptor来处理数据。
等到最后一个 interceptor 处理完request之后,就会请求网络,得到 response,再通过逐层的 return 返回,从 getResponseWithInterceptorChain() 中返回!
我们理解了 RealInterceptorChain 的作用,以及 Interceptors 被责任链式地调用过程。我们重点关注一下 Okhttp 对连接池的优化,以及对 socket 请求发起的执行逻辑:
6. RealConnectionPool 连接池
首先我们来关注一下 Socket 连接池。我们知道,socket 是基于 TCP 协议的网络请求工具,建立连接和释放连接,分别需要三次握手和四次挥手,这是比较耗时的。通过维持 socekt 的连接,我们可以增大通信时间的占比,从而让建立连接的时间忽略不计,达到性能的优化。
RealConnectionPool 维护了 socket 连接池。Exchange中的ExchangeFinder维护了RealConnectionPool连接池,RealConnection对象中就有socket实例。
我们来看一下 ConnectionInterceptor是如何获取socekt连接的:
作为拦截器,ConnectionInterceptor 在对 reqeuest 进行处理的同时,获取了一个Exchange对象:
public final class ConnectInterceptor implements Interceptor {
public final OkHttpClient client;
public ConnectInterceptor(OkHttpClient client) {
this.client = client;
}
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
Transmitter transmitter = realChain.transmitter();
boolean doExtensiveHealthChecks = !request.method().equals("GET");
//获得了一个 exchange,可以通过这个对象操作socekt
Exchange exchange = transmitter.newExchange(chain, doExtensiveHealthChecks);
return realChain.proceed(request, transmitter, exchange);
}
}
通过 transmitter.newExchange() 来获取一个exchange:
- 通过ExchangeFinder获取一个 ExchangeCodec
- 将这个ExchangeCodec连同其他信息一同包装在 Exchange 实例中
//Transmitter.java
Exchange newExchange(Interceptor.Chain chain, boolean doExtensiveHealthChecks) {
//通过ExchangeFinder获取到一个 ExchangeCodec
ExchangeCodec codec = exchangeFinder.find(client, chain, doExtensiveHealthChecks);
Exchange result = new Exchange(this, call, eventListener, exchangeFinder, codec);
return result;
}
我们注意到 ExchangeFinder 的成员变量中有 RealConnectionPool,明白了,连接池的管理是 ExchangeFinder 来做的,它维护着连接池,如果外界需要使用连接,它将可用的连接通过 ExchangeCodec 对象发挥出去,提供外界使用。而具体的连接逻辑等,都写在内部。对外人来说,具体实现就是黑盒,外界只要知道,拿到了 exchange,就说明可以通过这个叫做“exchange”的工具去进行网络请求。
final class ExchangeFinder {
private final RealConnectionPool connectionPool;
//1. 从 chain 中获取用户设置的数据
public ExchangeCodec find(
OkHttpClient client, Interceptor.Chain chain, boolean doExtensiveHealthChecks) {
//从 chain 中获取到用户的设置
int connectTimeout = chain.connectTimeoutMillis();
int readTimeout = chain.readTimeoutMillis();
int writeTimeout = chain.writeTimeoutMillis();
int pingIntervalMillis = client.pingIntervalMillis();
boolean connectionRetryEnabled = client.retryOnConnectionFailure();
//2. 通过这些设置去寻找合适的连接
try {
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,writeTimeout, pingIntervalMillis, connectionRetryEnabled, doExtensiveHealthChecks);
//如果找到了,包装在ExchangeCodec中,返回出去
return resultConnection.newCodec(client, chain);
} catch (RouteException e) {
trackFailure();
throw e;
} catch (IOException e) {
trackFailure();
throw new RouteException(e);
}
}
//2.通过用户的设置,去寻找合适的连接
private RealConnection findHealthyConnection(...) throws IOException {
while (true) {
RealConnection candidate = findConnection(connectTimeout, readTimeout, writeTimeout,pingIntervalMillis, connectionRetryEnabled);
//将合适的连接交出去
return candidate;
}
}
}
可以看到,ExchangeFinder通过逐层的检验,最后需要通过 findConnection,将RealConnection 以 ExchangeCodec的方式返回出去,再由transmitter包装进 Exchange 对象返回给用户使用。findConnection() 是最核心的获取连接的逻辑,代码很长,我们来看看核心。
先来看前半段:
- 首先尝试获取 transmitter 中当前使用的已连接的 connection
- 然后尝试从realConnectionPool 连接池中,取一个已连接的 connection
- 如果前两步成功取到了一个已连接的connection,就可以返回出去复用了!
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout, int pingIntervalMillis, boolean connectionRetryEnabled) throws IOException {
boolean foundPooledConnection = false;
RealConnection result = null;
Route selectedRoute = null;
RealConnection releasedConnection;
Socket toClose;
synchronized (connectionPool) {
//1. 先尝试获取 transmitter 中已连接的 connection
if (transmitter.connection != null) {
// We had an already-allocated connection and it's good.
result = transmitter.connection;
releasedConnection = null;
}
//如果没有已连接的connection
if (result == null) {
//2. 尝试从连接池中,获取一个已连接的 connection,由于传入的router路由集合是空,所以只有可能获取到那些http2条件下可以多路复用的链接!
if (connectionPool.transmitterAcquirePooledConnection(address, transmitter, null, false)) {
result = transmitter.connection;
}
}
}
//如果我们已经获取到了可复用的 connection,就直接返回,交给上层使用
if (result != null) {
return result;
}
}
再来看后半段:
private RealConnection findConnection(){
//如果已经取到了可复用的已连接的 connection,上面就返回出去了
//到这里说明没有可用的链接,我们就需要开始建立连接了:
// 如果我们需要路由选择,就获取一个(阻塞从routeSelector中获取)
boolean newRouteSelection = false;
if (selectedRoute == null && (routeSelection == null || !routeSelection.hasNext())) {
newRouteSelection = true;
routeSelection = routeSelector.next();
}
List<Route> routes = null;
synchronized (connectionPool) {
//如果需要路由选择,
if (newRouteSelection) {
//1. 现在我们已经有了一组IP地址,请再次尝试从池中获取连接。由于连接合并,这可能匹配。如果连接池中的 connection符合这个路由匹配,就可以使用!
routes = routeSelection.getAll();
if (connectionPool.transmitterAcquirePooledConnection(
address, transmitter, routes, false)) {
foundPooledConnection = true;
result = transmitter.connection;
}
}
//如果连接池中没有获取到可以路由合并(超网聚合)的连接connection
if (!foundPooledConnection) {
if (selectedRoute == null) {
selectedRoute = routeSelection.next();
}
//2. 那么就主动创建一个新的链接,引用交给result
result = new RealConnection(connectionPool, selectedRoute);
connectingConnection = result;
}
}
//如果从连接池中获取到了可以路由合并的连接connection
if (foundPooledConnection) {
eventListener.connectionAcquired(call, result);
//将这个connection返回出去
return result;
}
//到这里,说明连接池中无论如何也获取不到可以用的 connection 了。
//那么我们就需要让刚创建的 result,这个 RealConnection 去进行一个建立连接:TCP三次握手,会阻塞在这里,直到链接完成
result.connect(connectTimeout, readTimeout, writeTimeout, pingIntervalMillis,
connectionRetryEnabled, call, eventListener);
//连接完成后,将路由添加到连接池中,以备查询和复用
connectionPool.routeDatabase.connected(result.route());
//到这里,连接池中一定存在一个可用的已连接的connection 了!
Socket socket = null;
synchronized (connectionPool) {
connectingConnection = null;
//最后一次尝试连接合并,只有当我们尝试多个并发连接到同一主机时才会发生连接合并。
if (connectionPool.transmitterAcquirePooledConnection(address, transmitter, routes, true)) {
//我们尝试链接合并失败了,我们要关闭我们创建的链接,并返回连接池
result.noNewExchanges = true;
socket = result.socket();
result = transmitter.connection;
//在这个情况下,我们有可能获得一个立即不健康的合并连接。在这种情况下,我们将 重试 刚才成功连接的路由。
nextRouteToTry = selectedRoute;
} else {
//如果我们成功获取到了刚刚建立好的链接,将它放到复用池中!
connectionPool.put(result);
transmitter.acquireConnectionNoEvents(result);
}
}
//上面的判断说明,如果这里socket不为空,说明刚创建的socket连接是一个不健康的合并连接,我们要把它给关了!
closeQuietly(socket);
eventListener.connectionAcquired(call, result);
//返回连接池(如果成功了,连接池中就有刚建立好的链接,如果失败了,池中就没有,需要再次去尝试)
return result;
}
简单来说 ExchangeFinder 管理着连接池,如果有可复用的连接 RealConnection,或者可以合并连接的RealConnection,都是可以的。如果没有就要通过 TCP+TLS 握手,进行连接的建立。这里的TCP握手是阻塞的。中间过程代码太繁杂,大家可以一路点进去,发现中间配置好了 InetSocketAdress,以及 connectTimeout,然后调用到 socket.connect(address,connectTimeout); 进行socekt连接!
连接建立完成后,提交到连接池的路由数据库中。然后再次尝试从连接池中获取可用的连接。
7. CallServerInterceptor
最后我们看到 CallServerInterceptor 这个拦截器对 request的处理,是真正地进行网络请求!利用的是之前 ConnectionInterceptor 中获取到的可用的socket 连接。
//CallServerInterceptor.java
public Response intercept(Chain chain){
RealInterceptorChain realChain = (RealInterceptorChain) chain;
//拿到了从ConnectionInterceptor中拿到的可用的连接,它被装在了Exchange实例中
Exchange exchange = realChain.exchange();
//被之前的拦截器处理好的,即将用来发送的request
Request request = realChain.request();
//将request的头写入outputstream
exchange.writeRequestHeaders(request);
//如果有请求体,写入bufferedRequestBody,然后再写入connection,然后发送
request.body.writeTo(bufferedRequestBody);
//获得返回内容,生成一个ResponseBuilder
responseBuilder= exchange.readReponseHeaders();
//获得请求体
responseBody = exchange.openResponseBody(response);
//将response拼装好后,返回
return response;
}
发送请求头后,如果收到了100 Continue:
- 客户端应当继续发送请求。这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应.服务器必须在请求完成后向客户端发送一个最终响应。HTTP/1.1 可用
接收到响应后,如果收到了 100 Continue,同上,说明服务端可能还有数据要发过来,比如除了已经发送的header以外,还要发送body。
如果收到了 code = 101 Switching Protocal 协议切换:
- 服务器已经理解了客户端的请求,并将通过Upgrade消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到 在Upgrade消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。例如:切换到新的HTTP版本比旧版本更有优势,或者切换到一个实时且同步的协议以传送利用此类特性的资源。HTTP/1.1 可用。
如果收到了code=204或者code=205:
204 No Content: 状态码204表示请求已经执行成功,但没有内容205 Reset Content表示服务器成功地处理了客户端的请求,要求客户端重置它发送请求时的文档视图。这个响应码跟204 No Content类似,也不返回任何内容





![buu [UTCTF2020]basic-crypto 1](https://img-blog.csdnimg.cn/6011adb31fbd4c42ada2ccc3f5e37ae8.png)