|
|
central cache 设计及实现
central cache 也是一个哈希桶结构, 而且它的哈希桶的映射关系跟 thread cache 是一样的, 不同的是 central cache 每个哈希桶位置上挂的是 SpanList 双向链表结构, 而且每个哈希桶下面的 span 中的大块内存被按映射关系切成了一个个小的内存块对象挂在 span 的自由链表中.
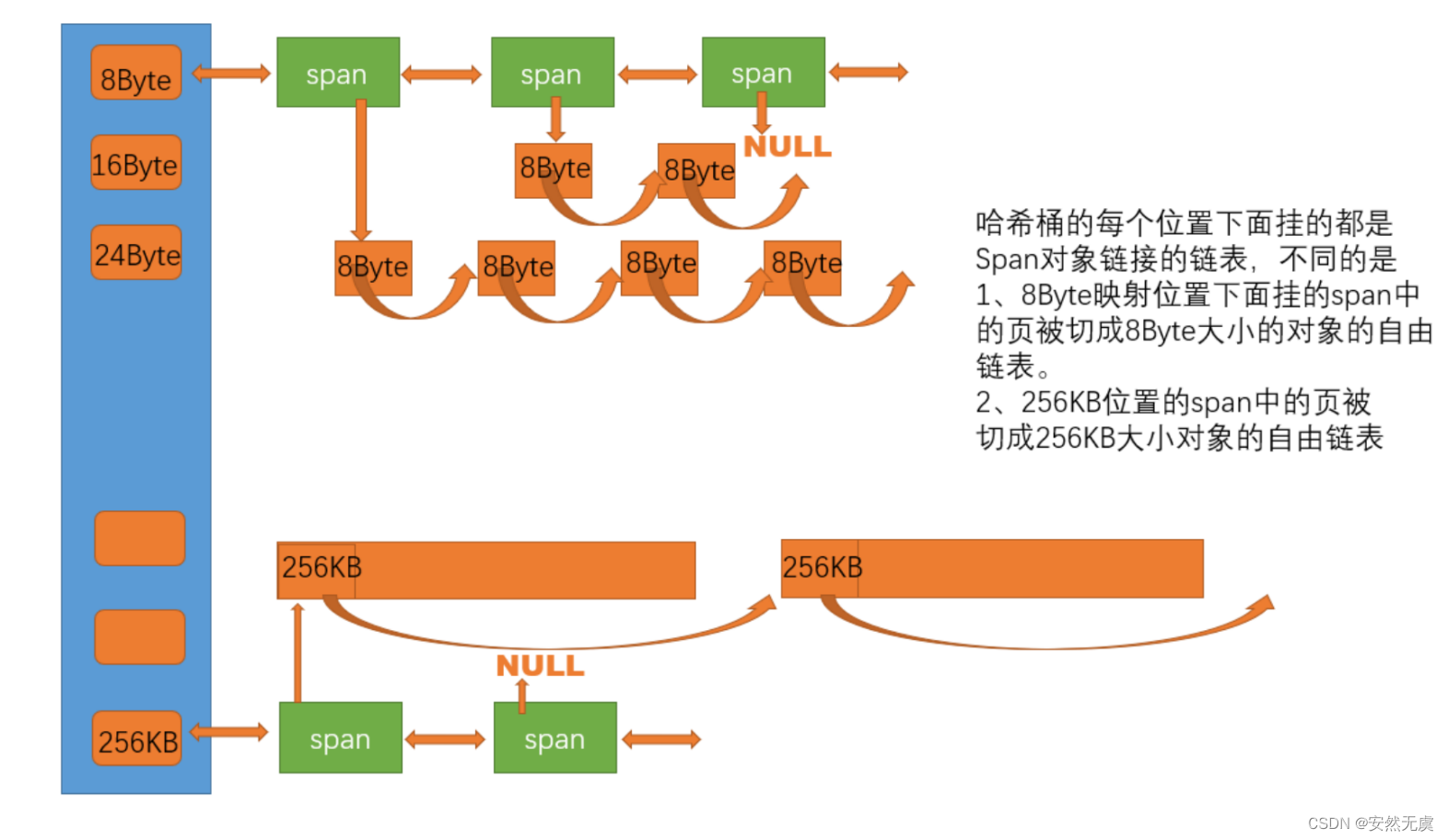
当 thread cache 中没有内存时, 就会批量地向 central cache 申请一些内存对象, 这里的批量获取内存对象采用慢开始反馈调节算法, central cache 也有一个哈希映射的 SpanList, SpanList 中挂着 span, span 是管理以页为单位的大块内存, 从 span 中取出对象给 thread cache, 这个过程是需要加锁的, 因为可能多个 thread cache 同时访问 central cache 映射的同一个 SpanList, 不过 central cache 使用的是桶锁, 这样就尽可能做到了提高效率.
当 central cache 映射的 SpanList 中的所有 span 都没有内存以后, 则需要向 page cache 申请一个新的 span 对象, 拿到 span 以后将其管理的内存按照特定大小切好作为自由链表链接到一起, 然后从 span 中取出对象给 thread cache.
thread cache与central cache的不同:
thread cache 与 central cache 的不同之处主要有两点, 第一点在于每个线程通过 TLS 都获取自己专属的 thread cache, 也就是说每个线程都有一个 thread cache, 所以线程从 thread cache 里面申请内存是不需要加锁的, 这样就有效地避免了锁竞争的问题. 但是central cache 在全局只有一份, 也就是说每个 thread cache 向同一个 central cache 申请内存, 所以 central cache 是需要加锁的.
但是 central cache 在加锁时并不是将其全部锁上, central cache在加锁时用的是桶锁, 也就是说每个桶都有一个锁, 此时只有当多个线程同时访问 central cache 的同一个桶时才会存在锁竞争, 如果是多个线程同时访问 central cache 的不同桶就不会存在锁竞争.
第二个不同点在于 thread cache 每个桶中挂的是切好的小块内存的自由链表, 而 central cache 每个桶中挂的是一个个 span, span 是管理以页为单位的大块内存, 而且每个桶里面的若干个 span 是按照双向链表的形式链接起来的, 并且每个 span 里面还有一个自由链表, 根据其所在的位置这些 span 被切成了对应的大小.
span的定义
span 是管理以页为单位的大块内存.
// Span 管理一个以页为单位的大块内存
struct Span
{
PAGE_ID _pageId = 0; // 大块内存起始页的页号
size_t _n = 0; // 页的数量
Span* _prev = nullptr; // 双向链表的结构
Span* _next = nullptr;
void* _freeList = nullptr; // 切好的小块内存的自由链表
};
- _pageId: 对于 span 管理的以页为单位的大块内存, 我们需要知道这块内存具体在什么位置, 方便后面的 page cache 进行前后页的合并, 因此在 span 的定义中要有大块内存起始页的页号.
- _n: 每个 span 管理的页数都是不一样的, 它受到很多因素的影响, 所以在 span 的定义中要记录页的数量.
- _prev, _next: 之所以采用的是带头双向循环链表, 是为了很方便的将需要从 page cache 中移除的 span 移除出去, 如若采用的是单链表, 那么在删除时需要保留当前节点的前一个节点.
- _freeList: 每个 span 管理的大块内存, 都会被切成相应大小的内存对象挂到当前 span 的自由链表中, 比如16Byte哈希桶中的span, 会被切成一个个16Byte大小的内存对象挂到当前 span 的自由链表中, 因此在 span 结构中还需要存储切好的小块内存的自由链表.
其中还需要注意的是大块内存起始页的页号, 它在 32位平台和64位平台 是不一样的, 假设一个页的大小是 8KB 的话, 在32位平台, 有 2^32 / 2^13 = 2^19 个页, 4字节数据类型可以存的下, 但是在64位平台, 有 2^ 64 / 2 ^ 13 = 2 ^ 51 个页, 这个时候4字节数据类型就存不下了, 需要 long long 这种8个字节的数据类型.
所以要有如下定义:
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#endif
还有一个小细节需要注意的是, 关于_WIN32宏 和 _WIN64宏 的差异, _WIN32宏 在32位和64位程序都有定义,且总是定义的, 但是 _WIN64宏 只有在64位程序下才有定义. 所以为了区分当前程序是32位还是64位, 需要将 _WIN64 放在前面.
SpanList的定义
SpanList 是一个带头双向循环链表的结构.
// 带头双向循环循环链表
class SpanList
{
public:
SpanList()
{
_head = new Span;
_head->_prev = _head;
_head->_next = _head;
}
// 随机插入
void Insert(Span* pos, Span* newSpan)
{
assert(pos);
assert(newSpan);
Span* prev = pos->_prev;
prev->_next = newSpan;
newSpan->_prev = prev;
newSpan->_next = pos;
pos->_prev = newSpan;
}
// 随机删除
void Erase(Span* pos)
{
assert(pos);
assert(pos != _head);
Span* prev = pos->_prev;
Span* next = pos->_next;
prev->_next = next;
next->_prev = prev;
}
private:
Span* _head = nullptr;
public:
std::mutex _mtx; // 桶锁
};
因为我们之前在数据结构中学过这个, 所以就显得很简单了.
对了, 还需要注意的是, 从双向链表中删除的 span 会还给 page cache, 所以不需要进行 delete 操作.
Central Cache代码框架
线程通过 TLS 来实现每个线程都有一个自己专属的 thread cache, 但是 central cache 和 page cache 全局只有一个, 对于这种只能创建一个对象的类, 我们将其封装成单例模式.
// 单例模式:饿汉模式
class CentralCache
{
public:
// 提供一个全局访问点
static CentralCache* GetInstance()
{
return &_sInst;
}
// 从中心缓存获取一定数量的对象给thread cache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t byte_size);
// 从SpanList或者page cache获取一个非空的Span
Span* GetOneSpan(SpanList& list, size_t byte_size);
private:
SpanList _spanList[NFREELISTS]; // 按照对齐方式映射 - 这点与thread cache很相似
private:
CentralCache() // 构造函数私有
{}
CentralCache(const CentralCache&) = delete; // 防止拷贝
static CentralCache _sInst;
};
因为要保证CentralCache类只能实例化出一个对象, 所以要将其构造函数私有化以及防止拷贝.
CentralCache类当中还需要有一个CentralCache类型的静态的成员变量, 当程序运行起来后我们就立马创建该对象, 并且在此后的程序中就只有这一个单例.
CentralCache CentralCache::_sInst;
慢开始反馈调节算法
thread cache 一次向 central cache 批量多少个内存对象合适呢, 这个问题值得我们思考, 因为一次给少了, 需要多次申请, 这样效率就低了, 但是如果一次给多了, 又会导致浪费.
所以这里想了一个折中的办法, 采用慢启动反馈调节算法, 也就是说, 对于小对象一次批量上限高, 对于大对象一次批量上限低.
//thread cache 一次从中心缓存获取多少个内存对象
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
// [2, 512], 一次批量获取多少个对象的(慢启动)上限值
// 小对象一次批量上限高
// 大对象一次批量上限低
size_t num = MAX_BYTES / size;
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
}
也就是说, 虽然小对象一次批量给的多, 但是不会超过512个, 大对象一次批量给的少, 但是不会低于2个, 所以一次批量给的对象个数控制在2~512个之间.
不过即使申请的是小对象, 一次性给出512个也是很多的, 所以我们可以在 FreeList 结构中增加一个叫做 _maxSize 的成员变量, 该变量的初始值设置为1, 并且提供一个成员函数用于获取这个变量. 也就是说, 现在 thread cache 中的每个自由链表都会有一个自己的_maxSize.
//管理切分好的小对象的自由链表
class FreeList
{
public:
size_t& MaxSize()
{
return _maxSize;
}
private:
void* _freeList = nullptr; //自由链表
size_t _maxSize = 1;
};
这样下来当 thread cache 申请对象时, 我们会比较 _maxSize 和慢开始反馈调节算法计算出来的值, 取其中的较小值作为本次申请对象的个数. 此外, 如果本次采用的是 _maxSize 的值, 那么还会将 thread cache 中该自由链表的 _maxSize 的值加一.
所以, thread cache 第一次向 central cache 申请某大小的对象时, 申请到的都是一个, 但是该自由链表中的 _maxSize 增加了,所以下一次 thread cache 再向 central cache 申请同样大小的对象时, 最终就会申请到两个, 直到该自由链表中_maxSize的值增长到超过慢开始反馈调节算法计算出的值后就不会继续增长了, 此后申请到的对象个数就是计算出的个数.
从中心缓存获取对象
thread cache 向 central cache 获取内存对象时, 都是通过慢开始反馈调节算法计算出需要申请对象的个数, 然后再向 central cache 申请.
如果申请到的对象只有一个, 直接返回即可, 如果申请到的对象有多个, 那么需要在返回第一个对象之前, 需要将除第一个对象之外的所有对象头插到 thread cache 对应的哈希桶的自由链表中.
//从中心缓存获取对象
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
// 慢开始反馈调节算法
// 1. 最开始不会一次向central cache要太多, 因为可能用不完
// 2. 如果你不断有这个size大小的内存需求, 那么batchNum就会不断增长, 直至上限
// 3. size越大,一次向central cache要的batchNum就越小
// 4. size越小,一次向central cache要的batchNum就越大
size_t batchNum = std::min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (_freeLists[index].MaxSize() == batchNum)
_freeLists[index].MaxSize() += 1;
void* start = nullptr;
void* end = nullptr;
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
assert(actualNum > 0);
if (actualNum == 1) // 申请到的对象只有一个, 直接返回即可
{
assert(start == end);
return start;
}
else // 申请到的对象有多个, 还需要将剩下的对象挂到thread cache对应的哈希桶中
{
_freeLists[index].PushRange(NextObj(start), end);
return start;
}
}
从中心缓存获取一定数量的对象
我们需要从 central cache 中获取 batchNum 个指定大小的对象, 这些对象肯定是从 central cache 中指定的哈希桶中的 span 里面取出来的, 由于这 batchNum 个对象是链接在一起的, 所以我们只需要知道其头和尾即可, 故而这里采用输出型参数.
// 从中心缓存获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t byte_size)
{
size_t index = SizeClass::Index(byte_size);
_spanList[index]._mtx.lock();
// 从SpanList或者page cache获取一个非空的span
Span* span = GetOneSpan(_spanList[index], byte_size);
assert(span);
assert(span->_freeList);
// 从span中获取batchNum个内存对象
// 如果不够batchNum个, 有多少拿多少
start = span->_freeList;
end = start;
size_t i = 0;
size_t actualNum = 1;
while (i < batchNum - 1 && NextObj(end) != nullptr)
{
end = NextObj(end);
i++;
actualNum++;
}
span->_freeList = NextObj(end);
NextObj(end) = nullptr; //将取出的一段链表的表尾置空
_spanList[index]._mtx.unlock();
return actualNum;
}
因为 central cache 是被所有线程共享的, 所以当我们访问 central cache 的哈希桶时, 先对其进行加锁, 等到获得内存对象后, 再对其进行解锁.
首先我们要从 central cache 的对应位置的哈希桶中获取一个非空的 span, 然后从这个非空的 span 里面取出 batchNum 个内存对象即可, 如果没有 batchNum 个, 那么就有多少取多少.
需要说明的是, 虽然我们实际申请到的对象个数可能会比 batchNum 小, 但是没有关系. 因为本身 thread cache 的就是向 central cache 申请一个对象, 这里之所以要一次申请多个对象, 是因为这样一来下次线程再申请相同大小的对象时就可以直接在 thread cache 里面获取了, 而不用再向 central cache 申请对象, 因为向 central cache 申请对象可能会有加锁解锁问题.
头插一段范围的对象到自由链表
前面我们说到, 如果从 central cache 中申请到的对象不止一个, 除了第一个对象被返回外, 其余所有对象全部被头插进 thread cache 对应位置的自由链表中.
// 管理切分好的小块内存的自由链表
class FreeList
{
public:
// 头插一段范围的内存对象
void PushRange(void* start, void* end)
{
assert(start);
assert(end);
NextObj(end) = _freeList;
_freeList = start;
}
private:
void* _freeList = nullptr;
size_t _maxSize = 1;
};

![[Datawhale][CS224W]图机器学习(三)](https://img-blog.csdnimg.cn/img_convert/1067417632d770c55e3a3875738bf4d5.jpeg)