😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享Java相关知识。
🎉🎉个人主页🎉🎉 : 南瓜籽的主页
✨✨座右铭✨✨ : 坚持到底,决不放弃,是成功的保证,只要你不放弃,你就有机会,只要放弃的人,他肯定是不会成功的人。
🍎🍎插入数据🍎🍎
如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。
方案一:
批量插入数据
Insert into tb_user values(1,'Tom'),(2,'Cat'),(3,'Jerry');
方案二:
手动控制事务
start transaction;
insert into tb_user values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_user values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_user values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;
方案三:
主键顺序插入,性能要高于乱序插入。
主键乱序插入 : 3 1 5 2
主键顺序插入 : 1 2 3 5
🍎🍎大批量插入数据🍎🍎
如果一次性需要插入大批量数据(比如:
几百万的记录),使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。
操作方法如下:
-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql.sql' into table tb_user fields
terminated by ',' lines terminated by '\n' ;
🍉🍉主键优化🍉🍉
🍉🍉数据组织方式🍉🍉
在
InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)。
行数据,都是存储在聚集索引 (默认为主键索引)的叶子节点上的。
在InnoDB引擎中,数据行是记录在逻辑结构 page 页中的,而每一个页的大小是固定的,默认16K。
那也就意味着, 一个页中所存储的行也是有限的,如果插入的数据行row在该页存储不小,将会存储到下一个页中,页与页之间会通过指针连接。
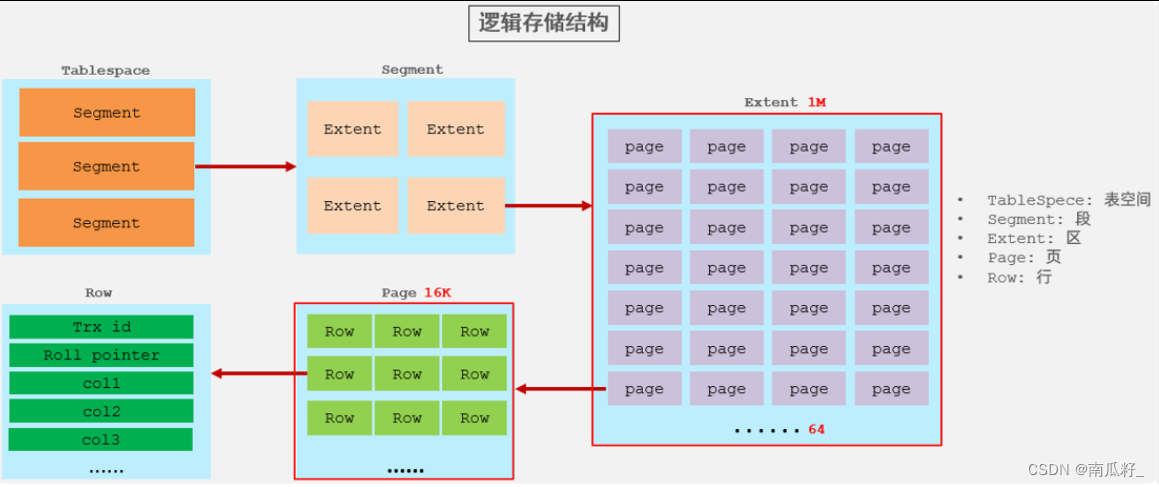
🍉🍉页分裂🍉🍉
页可以为空,也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据过大,会行溢出),根据主键排列。
1. 主键顺序插入效果

1. 主键乱序插入效果
一 : 第一、二页已经写满了数据
二 : 我们的需求是再插入一条主键为50的数据,
1、MySQL 进行判断发现一、二页已经满了。
2、此时会开辟一个新的页 3# page,但是并不会直接将50存入3#页,而是会将1#页后一半的数据,移动到3#页,然后在3#页,插入50。3、 移动数据,并插入id为50的数据之后,那么此时,这三个页之间的数据顺序是有问题的。 1#的下一个页,应该是3#, 3#的下一个页是2#。 所以,此时,需要重新设置链表指针


tips: 上述的这种现象,称之为 “页分裂”,是比较耗费性能的操作。
🍉🍉页合并🍉🍉
当我们对已有数据进行删除时,具体的效果如下:
1、当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。
2、当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。
删除数据,并将页合并之后,再次插入新的数据21,则直接插入3#页
tips: MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。


- 为表设置MERGE_THRESHOLD
CREATE TABLE table1 (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(32) NOT NULL,
) COMMENT='MERGE_THRESHOLD=45';
- 为单个索引设置MERGE_THRESHOLD
CREATE INDEX idx_id ON table1 (id) COMMENT 'MERGE_THRESHOLD=40';
🍉🍉索引设计原则🍉🍉
1. 满足业务需求的情况下,尽量降低主键的长度。
2. 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
3. 尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
4. 业务操作时,避免对主键的修改。
🍓🍓ORDER BY优化🍓🍓
MySQL的排序,有两种方式:
- Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sortbuffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
- Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
- 总结对于以上的两种排序方式,
Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index。
ORDER BY优化原则:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
- 尽量使用覆盖索引。
- 多字段排序, 一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
- 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
🍇🍇GROUP BY优化🍇🍇
在分组操作中,我们需要通过以下两点进行优化,以提升性能:
- 在分组操作时,可以通过索引来提高效率。
- 分组操作时,索引的使用也是满足最左前缀法则的。
🍒🍒LIMIT优化🍒🍒
优化思路: 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
explain select * from tb_user t , (select id from tb_user order by id
limit 2000000,10) a where t.id = a.id;
🍍🍍COUNT优化🍍🍍
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高; 但是如果是带条件的count,MyISAM也慢。
- InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
主要的优化思路:自己计数(可以借助于redis这样的数据库进行,但是如果是带条件的count又比较麻烦了)
🍍🍍COUNT用法🍍🍍
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是NULL,累计值就加 1,否则不加,最后返回累计值。
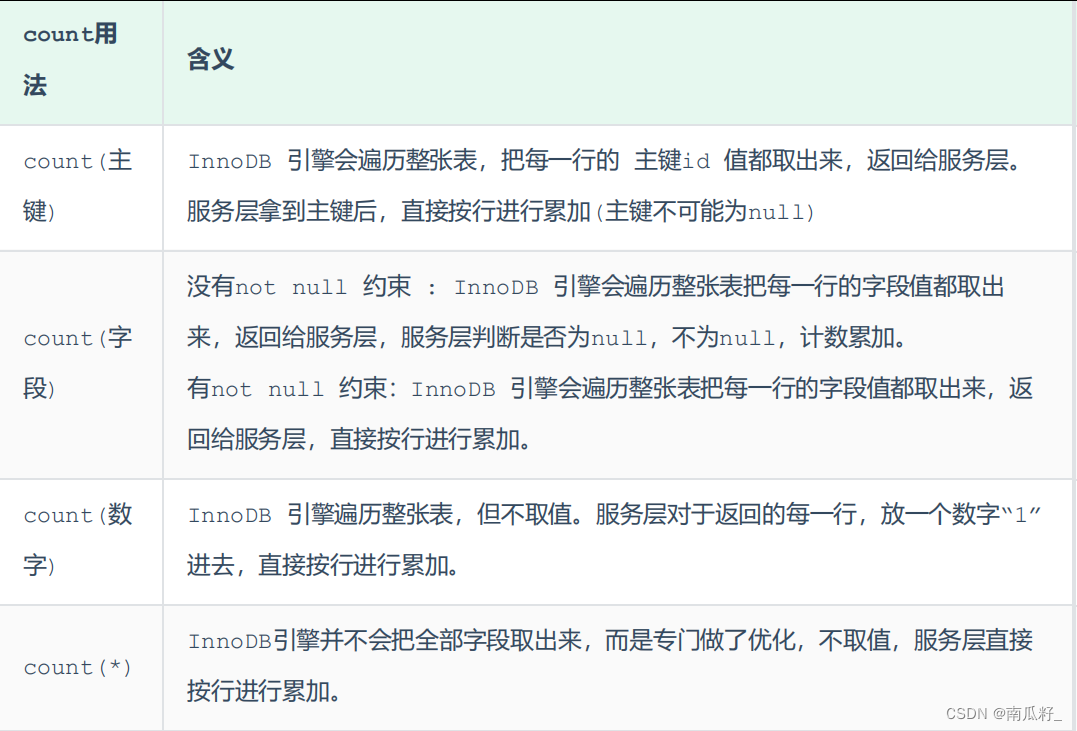
效率从小到大排序: count(字段) < count(主键 id) < count(1) ≈ count(*)
🍊🍊UPDATE优化🍊🍊
我们主要需要注意一下update语句执行时的
注意事项。
update tb_user set name = '张三' where id = 1 ;
当我们在执行删除的SQL语句时,会锁定id为1这一行的数据(where关键字所起的作用),然后事务提交之后,行锁释放。
但是当我们在执行如下SQL时。
update tb_user set name = '王五' where name = '李四' ;
注意: 此时 name 字段是没有索引的,此时可以理解为索引失效,所以当执行上述SQL时,会将行锁升级为表锁,导致该update语句的性能大大降低!!!
InnoDB存储引擎的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁升级为表锁