分享一下最近我JS逆向的心得。
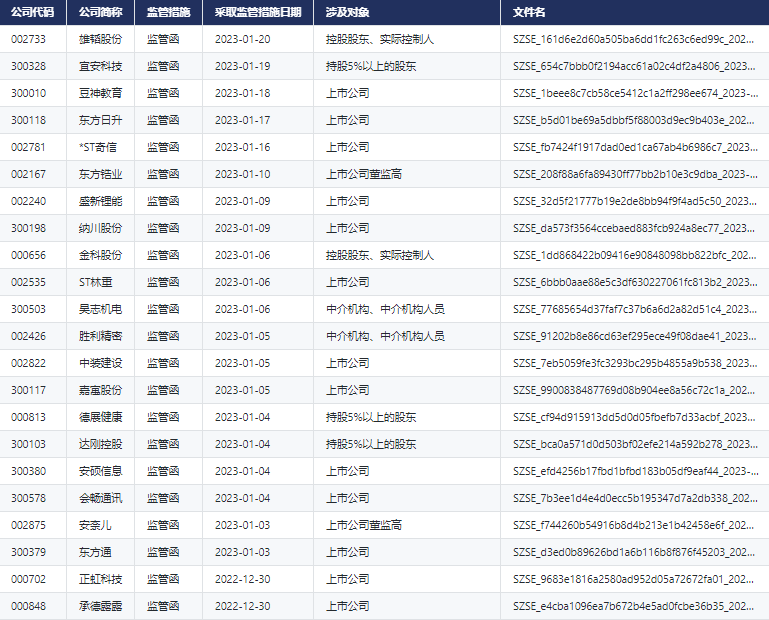
我最近使用Python爬取某个网站某个链接,cookie必须加入qgqp_b_id参数才能获取数据。
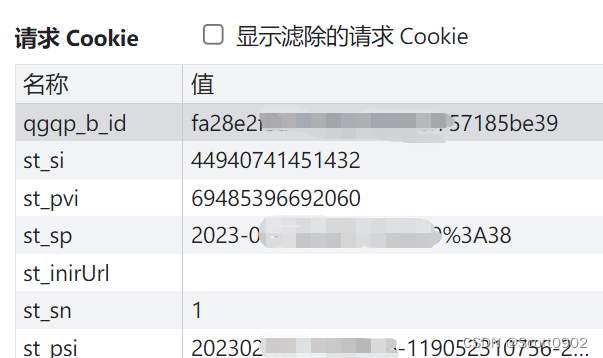
这个参数是一个32位字符串,通过浏览器的开发者工具分析网页源代码,了解到这个qgqp_b_id变量不是服务器返回给客户端的,而是前端JS的某段代码运算出来的。经过一段时间设断点、单步跟踪、反复调试(在此省略一万字),发现这个变量源自bid变量,bid又是哪里算出来的?
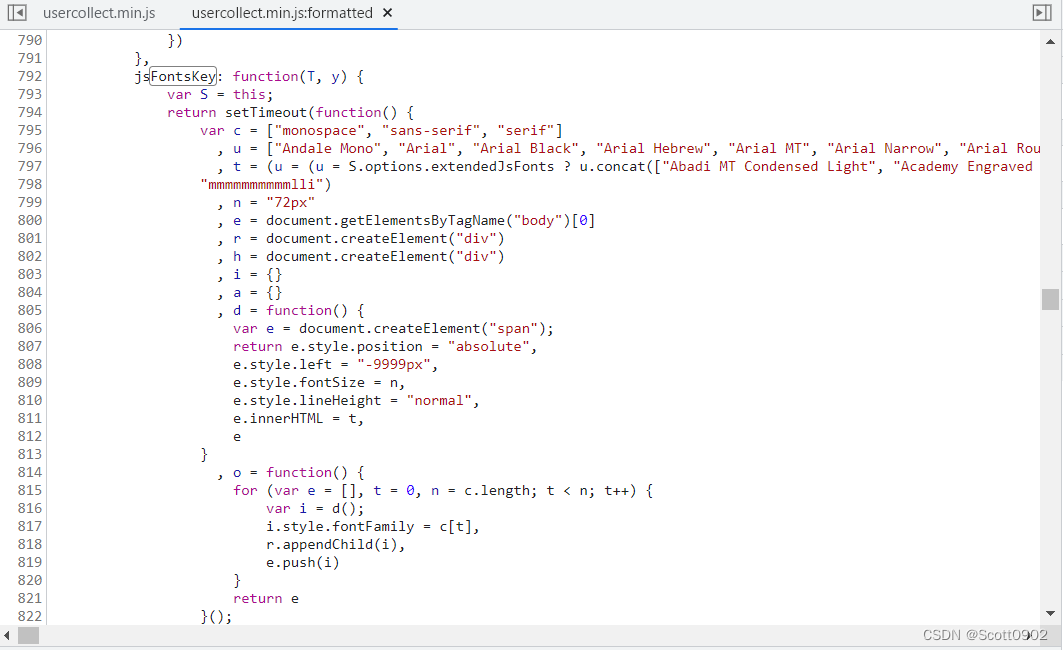
起初以为32位字符串是MD5的算法,但随着深入逆向分析JS代码(在jQuery.js、usercollect.min.js、require.min.js、main.js等多个JS代码里跳来跳去),终于在usercollect.min.js找到了一段x64hash128的加密算法:
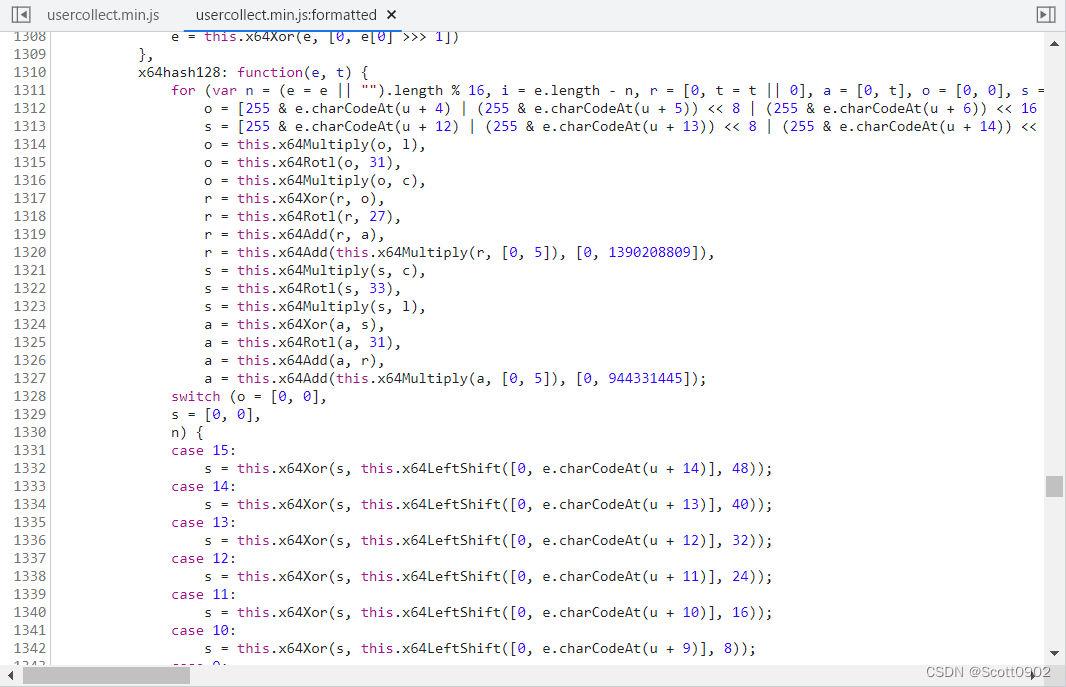
然后在这个JS代码里再查找x64hash128可以找到是把变量 r 进行加密运算:
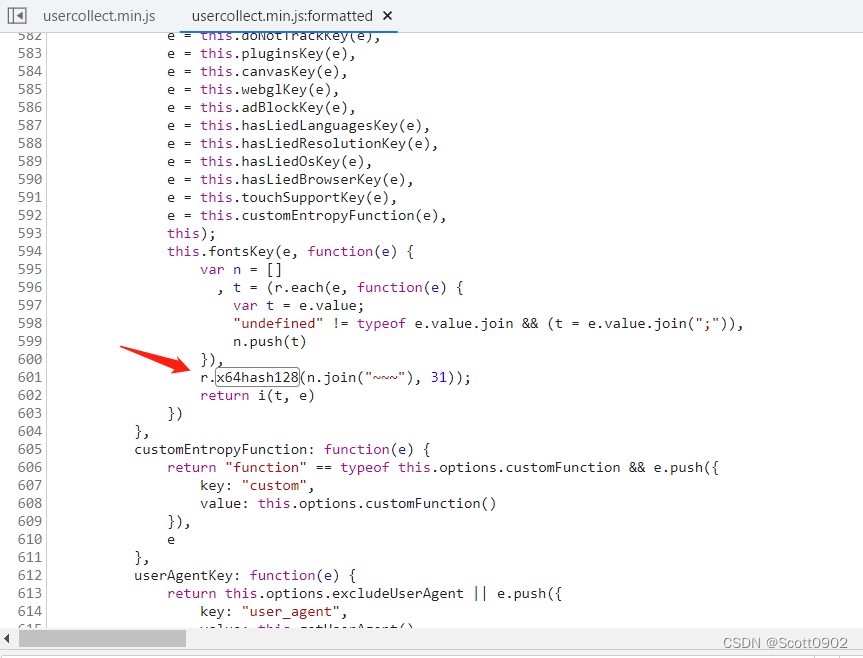
再往上找变量r,r = e, e是一大堆JS代码,在获取当前操作环境的参数,如user-agent、系统语言、显示色深、屏幕像素比、屏幕分辨率等,这些信息都以~~~符号串联起来。
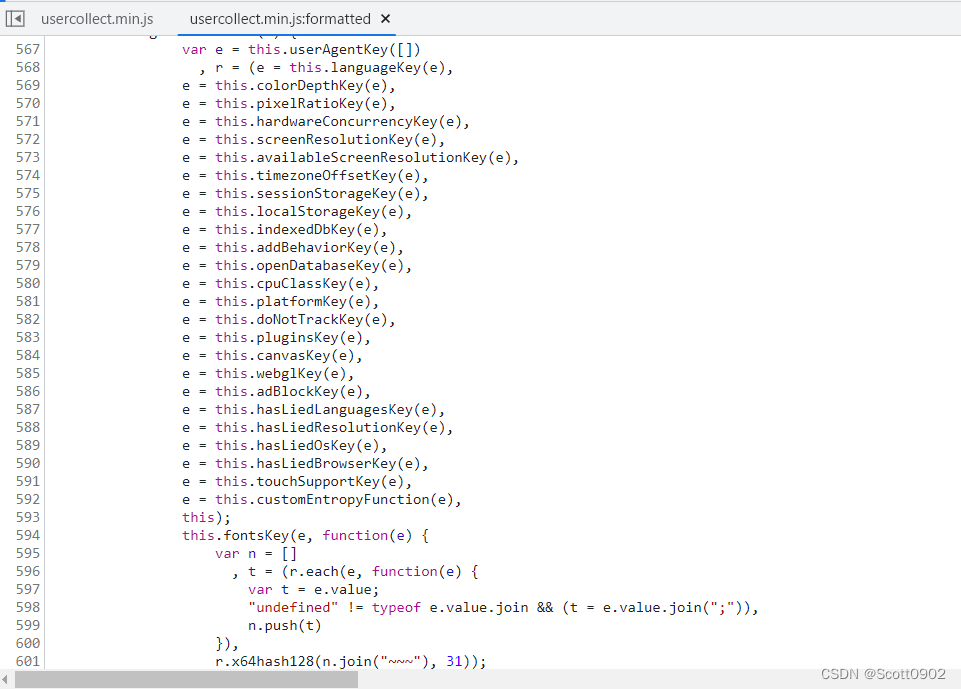
得出的字符串很长很长,其中占比最多的是canvasKey(e)和webglKey(e)这两个函数生成的字符串。查找canvasKey(e),发现里面有个笑脸符号,嘿嘿,非常有意思:
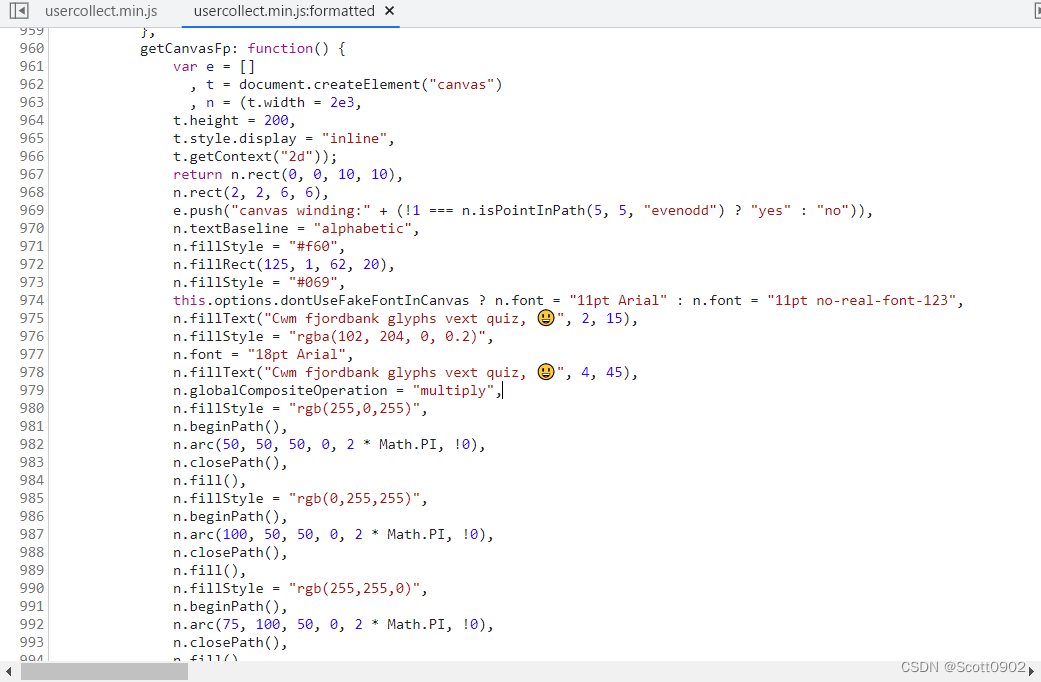
这段canvasKey(e)函数生成的是base64加密的字符串。我把它进行base64解密,得出的是一个PNG图片。

再看另一个函数webglKey(e),也是生成一个图片然后转base64密文。图片如下:
哈哈,为了层层加密,居然还要代码画个图然后转成密文再来进一步加密,作为JS小白的我真是活久见了。
这还没完,上面说了 r = e,e的最后一个元素通过fontskey (e)函数获取字体名称列表,它是u这个字体名称列表中筛选出当前系统中存在的字体名称,组成一串字体名称。
bid变量正是由系统环境信息、加上两个实时生成的图片转base64密文、再加上字体名称列表,撮合起来,然后进行x64hash128()加密运算。
x64hash128()加密运算还调用x64Add、x64Multiply、x64Xor、x64Rotl等子函数综合计算……问你怕未!
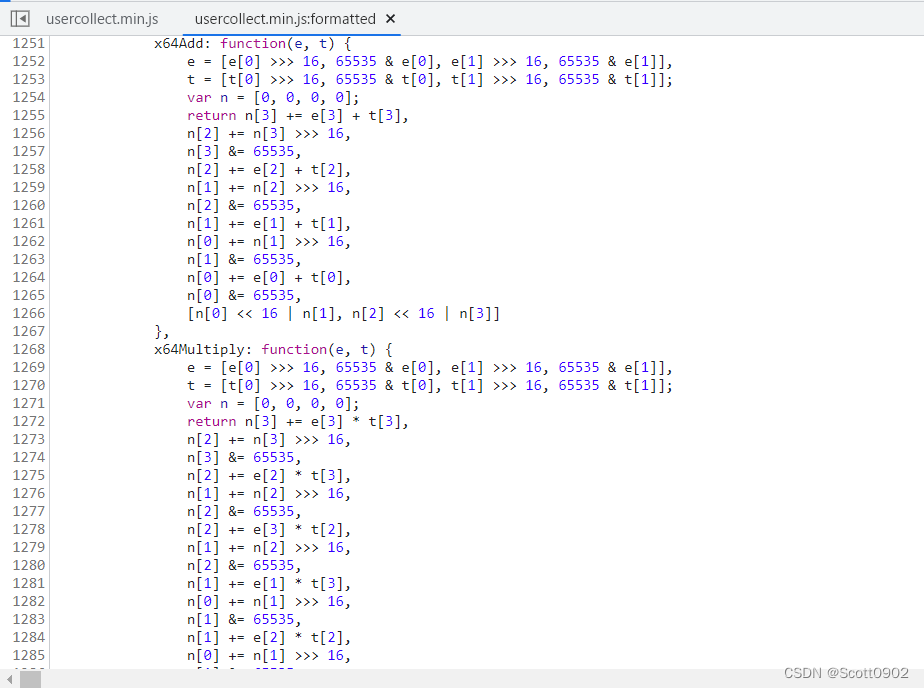
看罢,令我倒吸一口凉气。如果要把它们这么多代码转换成Python代码,相信已劝退了99%的人。我也没有对其逐个转换。
在后来的调试中,我尝试把qgqp_b_id参数随便改了个字符,然后requests.get()。嘿!返回的status_code是200!可以连接成功!
我又尝试把qgqp_b_id的值乱改一通,比如:qgqp_b_id = '9527-3547-709394'(广东人你懂的)。居然也连接成功!
这说明什么?
逆向JS分析了一大轮,一顿操作猛如虎,这些加密代码原来是混淆代码,就是用来吓唬小白的,所谓加密算出来的变量,服务器那边根本不校验,随便编造一个变量都能蒙混过关!真系混吉!
还说明了为什么某些网站加载需要那么长时间,即使是高配置电脑,加载含有大量JS代码的网页所花的时间,跟十几年前低配电脑加载少量JS代码的时间相比,好像差不了多少。现在的网站为了提高安全性,JS代码设计得越来越复杂,运行JS代码消耗了大部分加载时间。
最后我得知,这波信息采集叫做fingerprint2用户指纹,可以参考下面文章了解一下:
fingerprint2生成的用户指纹重复踩坑 - 掘金